HBase进化 | 从NoSQL到NewSQL,凤凰涅槃成就Phoenix
Posted HBase技术社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase进化 | 从NoSQL到NewSQL,凤凰涅槃成就Phoenix相关的知识,希望对你有一定的参考价值。
一.背景概述
近些年来,数据爆炸或者大数据成为IT行业发展的高频词汇,传统单机数据库处理数据能力的瓶颈成为摆在IT工程师面前十分常见且亟待解决的问题。单机硬件存储容量和计算力的增长远远赶不上数据的增长。在单机软件中,数据库是数据相关处理技术的集大成者,集合了数据存储、数据实时读写、在线事务和数据分析等技术,并通过主备、多活等方案保证了可靠性。但是,在实际业务场景中,我们往往并没有同时用到所有数据库提供的能力,这也为我们解决业务中实际遇到的大数据难题提供了解决思路。
当前的大数据系统大多是通过分布式原理,重点解决某个方面或者某些方面的困境和难题,比如HDFS解决了大数据存储的问题,MapReduce解决了大数据量复杂分析和计算的难题,HBase解决了实时读写的问题。下面笔者将介绍HBase从解决实时读写问题出发,逐步进化,从NoSQL发展到NewSQL的过程和最新进展。
图1 NoSQL到NewSQL
单纯从解决大数据实时读写问题角度,最初的HBase系统可以去掉很多传统数据库无关的功能,比如事务,SQL表达与分析等,重点关注于分布式系统的扩展性,容错性,分布式缓存的设计,读写性能的优化以及毛刺的减少等方面。这也就是NoSQL最初的含义,解决大数据的实时存取的核心问题是第一位的,提供简单的Get,Put,Scan接口就可以解决用户的燃眉之急。通过第一阶段的努力,HBase成为了优秀的大数据实时存取引擎,传统数据库的容量问题解决了,HDFS实时性不够的问题也解决了。
走过了从无到有的第一阶段,我们需要让HBase更强大,更好用,门槛更低,让HBase帮助更多的用户解决他们遇到的实际问题。众所周知,SQL是数据处理领域的语言标准,简单,好用,表达力强,用户使用广泛。HBase很有必要回过头来支持SQL,包括语言表达的支持和相关的数据处理方式和能力的支持。当然,HBase SQL的实现和发展跟传统单机数据库有很多不同,便于区别,我们称之为NewSQL。这也是社区Phoenix项目的初衷,如果说HBase是功能强大的存储引擎,那么支持NewSQL之后,就变成了新一代的大飞机。
接下来,第二章将介绍Phoenix项目是如何让HBase从NoSQL成长为NewSQL的;第三章介绍Phoenix在阿里云的实践,增强和典型案例;第四章总结全文以及展望Phoenix未来的发展。
二.方案与实现
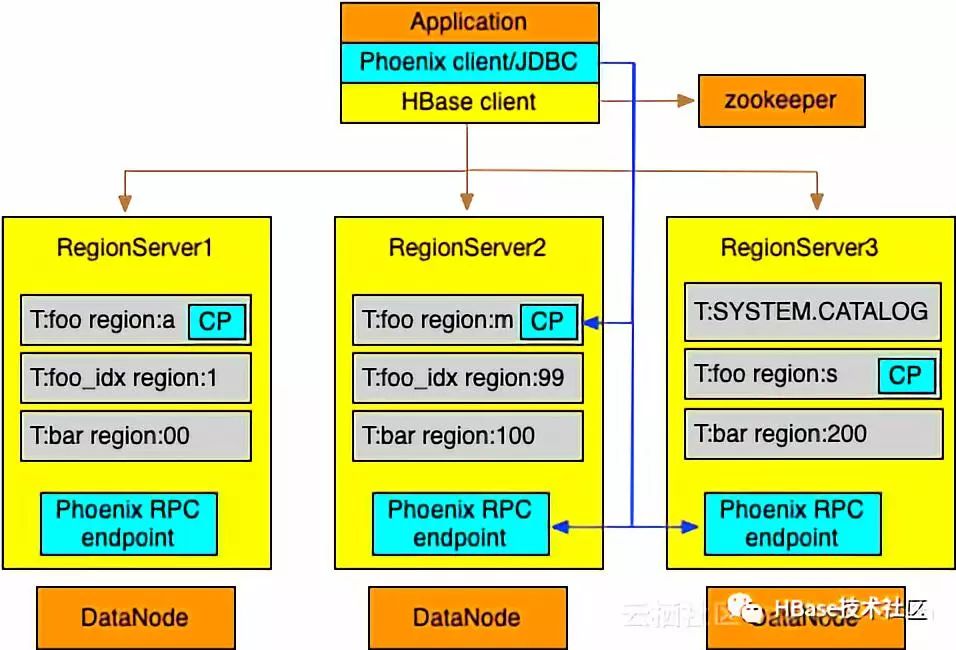
图2 Phoenix架构
系统整体架构如图2所示,其中黄色部分是HBase的组件,蓝色部分是Phoenix,我们可以看出Phoenix跟HBase是紧密结合的。Phoenix首先要能通过SQL暴露HBase的能力,然后再通过一系列功能和特性增强HBase能力,并且还要做到足够易用。下面我分别从基于HBase的SQL,SQL执行与优化以使用接口三个方面介绍Phoenix已经做到的事情。
2.1 基于HBase的SQL
让HBase支持SQL,我们首先能想到的是,把SQL语言翻译成HBase API,并且HBase本身的功能特性必须得能通过SQL暴露出来。Phoenix SQL语法即SQL-92标准语法+方言。Phoenix支持标准语法的绝大部分特性,包括:标准类型;聚合,连接,in,排序以及子查询等查询语法;create,drop,delete等数据操作语法,这些操作在底层都会转变为HBase API。
此外,HBase的某些特性也能通过SQL方言的形式表达,比如:
HBase的列簇,可以把相关的列放到一起,以减少IO,优化读性能,在创建Phoenix表的时候直接写成”cf.col”即可,Phoenix会自动创建cf列簇,如果不指定,则放在默认列簇中;
Phoenix将insert和update合并成upsert关键字,来对应HBase的Put概念;
HBase为了避免在表初始时只有一个Region带来数据热点,支持预分区,Phoenix支持在建表的时候通过split on关键字来表达。
HBase支持动态列的特性在Phoenix中也得以保留,存入数据的时候直接声明新的字段即可使用。
由于充分结合,Phoenix天然继承了HBase所拥有的高并发,大容量,实时存取等特性。
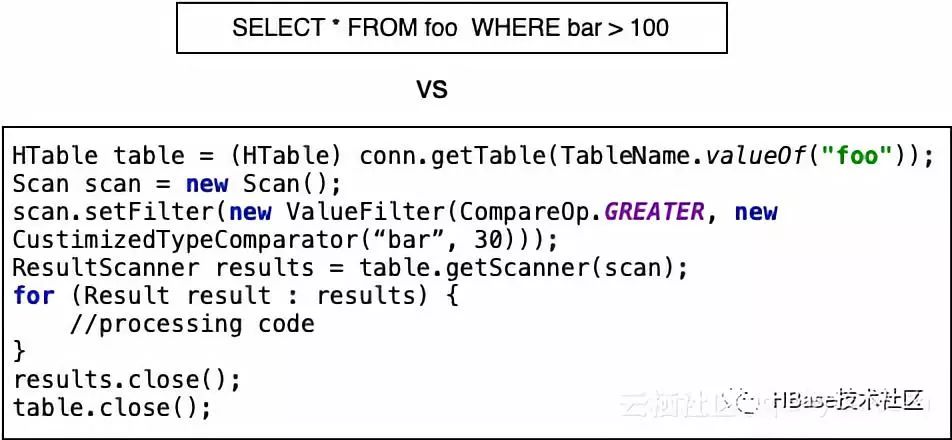
图3 SQL vs HBase API
从图3中可以看出,有了SQL,用户无需编写繁琐的java代码,大大简化了代码逻辑,传统数据库用户可以快速上手,原有基于传统数据库的代码逻辑,只需要少量修改即可运行起来。
2.2 SQL查询优化
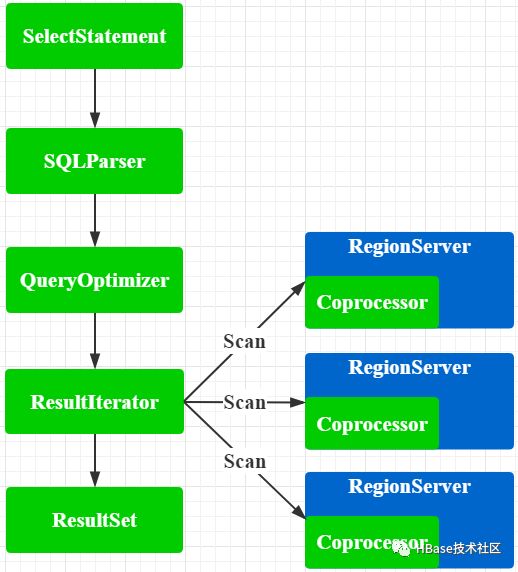
图4 Phoenix SQL执行流程
在很多场景下仅拥有实时存取的特性是不够的,大数据在线原地分析也是自然而然的需求,Phoenix基于HBase拥有的高效缓存和LSM索引,可以做到对PB级数据做操作型分析的毫秒级或秒级返回。Phoenix SQL的整体执行流程如图4所示,用户输入的查询语句首先经过SQLParser解析为执行计划,然后经过QueryOptimizer的优化,选取最优的执行计划,执行计划最终会转变为HBase的Scan,RegionServer端的协处理器会作用于该Scan,做本地过滤和聚合,然后把结果返回到客户端做汇总聚合形成最终结果,并通过ResultSet的形式返回给用户。其中主要使用到的策略有:无需数据传输的算子原地计算;实时同步的二级索引;热点数据自动打散;以及基于代价和规则的执行计划优化等。后面笔者介绍前三个最具有Phoenix特色的策略。
在没有Phoenix之前,用户如果需要分析HBase数据,只能从HBase拖出去或者绕过HBase直接读取HDFS上面的HFile的方式进行,前者浪费了大量的网络IO,后者用不到HBase本身做的大量缓存和索引优化。Phoenix使用HBase的协处理器机制,直接在RegionServer上执行算子逻辑,然后将算子的结果返回即可,也就是大数据中的“Move Operator to Data”理念。比如,用户执行“select count(*) from mytable where mytime > timestamp’2018-11-11 00:00:00’”,在实际执行中,会先找到符合过滤条件的region,然后在RegionServer本地计算count,最后再对各个Region上的结果进行汇总。
索引是传统数据库中常见的技术,HBase表中可以指定主键,对主键使用LSM算法构建索引。Phoenix中,用户在创建表的时候,可以指定索引列,可以是单列,也可以是组合列。很多时候仅有主键索引是不够的,特别是对于列特别多的宽表,为此,Phoenix提供二级索引功能,用户能够对表中非主键的列添加索引,并可以加入其它相关列到索引表中,如果某个查询涉及到的列全部在索引表中,直接查询索引表即可,无需访问原数据表。索引表跟原表做到实时同步更新,以保证数据一致性。
索引示例如图5所示,创建索引的时候通过“on”关键字指定索引表的主键,实际HBase表中会使用BA来作为联合主键;“include”关键字指定加入到索引表的其他列。当执行“select c from data_table where b > xx ”时,Phoenix直接查询索引表即可,否者需要返回原表查找。
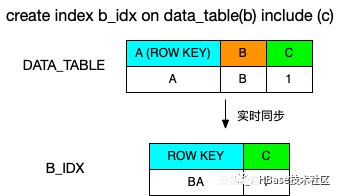
图5 Phoenix二级索引
当数据的访问比较集中,比如物联网场景中需要对最新的的监控数据做查询分析,而这部分数据往往会集中分布在某个RegionServer上,那么就会形成热点,性能也会大大折扣。此时需要能够把数据打散到不同的RegionServer上来解决,加盐就是这样一个技术。加盐的过程本质上是对原有的主键加上一个字节的前缀,如下面公式所示:
new_row_key = (++index % BUCKETS_NUMBER) + original_key
其中,BUCKETS_NUMBER为桶的个数。主键的分布决定了数据的分布,把主键打散也就意味着数据打散。具体使用时,一般建议桶的数目等于RegionServer的数目。
2.3 使用接口
Phoenix提供JDBC的方式访问,并支持重客户端和轻客户端两种方式,重客户端的JDBC串前缀是“jdbc:phoenix:”,轻客户端的JDBC串前缀为“jdbc:phoenix:thin:”。重客户端中,Phoenix初执行在HBase协处理器之外的逻辑均运行在客户端,这样可以带来最优的性能,但也带来了客户端的复杂性。轻客户端则将上诉逻辑运行在单独不熟的QueryServer中,客户端仅有很薄的JDBC协议转换。轻客户端除支持Java语言外,也支持Python、Go、C#等多种语言。
三.实践案例
阿里云HBase产品中集成Phoenix功能已经有一年多的时间了,阿里云HBase团队对Phoenix在稳定性和性能方面做了一系列的改进优化,并积极反馈回社区,团队的瑾谦同学也成长为了Phoenix社区的Commiter。Phoenix的用户既有来自于新型大数据业务,如物联网、互联网金融以及新零售等;也有来自传统行业,比如游戏、养殖业和运输业等。Phoenix数据既有来在线实时业务,也有从单机数据库同步进来。下面,笔者以物联网场景为例,说明Phoenix如何在实际业务中解决用户难题。
在物联网场景下,大量传感器会把实时监测到的数据上传到云平台,经过一定的预处理后实时写入到Phoenix中,管控平台从Phoenix中直接在线查询和分析数据,如生成报表,监控异常等。该场景会用到Phoenix的一下特性:
对实时写入的并发和TPS要求很高,甚至可以达到百万级。
数据量比较大,一般在TB到PB级别,且需要根据业务增长动态扩容。
有动态列的需求,比如根据业务调整,动态添加监控指标。
在线查询,甚至是毫秒级查询要求。
维度比较多,需要用到二级索引,以加速在线查询。
频繁查询最近一段时间的数据,会造成热点,可以使用加盐的特性。
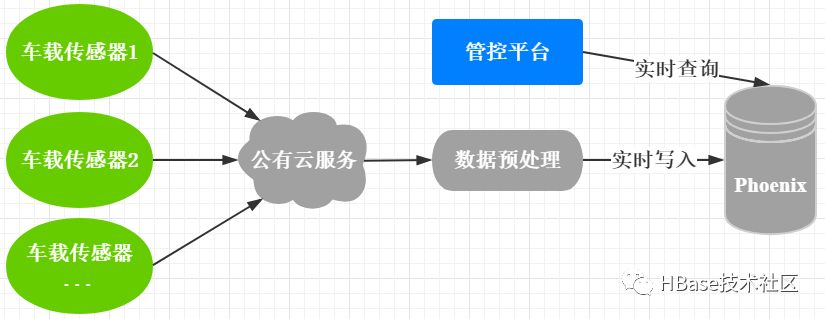
图6 Phoenix在物联网的应用
四.总结与展望
开源的HDFS、MapReduce和HBase来源于Google的三篇论文,但最终驱动的还是大数据场景下的实际需求。Phoenix的出现也是需求驱动的必然结果,它继承了HBase的各种特性,如高并发,水平扩展,实时读写等,并在其基础上实现了一套SQL引擎,增加了如语法解析、二级索引、查询优化以及JDBC等功能和特性,完成了NoSQL到NewSQL的转变。
阿里云HBase团队和社区对Phoenix后续还会根据实际需求做进一步的进化,包括稳定性的进一步加强;执行计划和运行时的进一步优化;轻客户端在易用性支持上的持续完善;实时交易场景中事务的支持以及跟Spark的深度集成等等。笔者非常希望对HBase和Phoenix感兴趣的读者朋友可以参与到社区里面,共同推动技术的发展,满足更多的场景需求。
以上是关于HBase进化 | 从NoSQL到NewSQL,凤凰涅槃成就Phoenix的主要内容,如果未能解决你的问题,请参考以下文章