Hbase周边生态梳理
Posted HBase技术社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hbase周边生态梳理相关的知识,希望对你有一定的参考价值。
大数据前几年各种概念争论很多,NoSQL/NewSQL,CAP/BASE概念一堆堆的,现在这股热潮被AI接过去了。大数据真正落地到车联网,分控,各种数据分析等等具体场景。
概念很高大上,搞得久了就会发现,大部分都还是数据仓库的衍伸,所以我们称呼这个为“新数仓”,我准备写一系列相关的文章,有没有同学愿意一起来的?请联系我。前面有一些相关文章,大家可以看看:
本文简单梳理下其中一个应用比较广的HBASE的生态,可能不全,有更多的请大家留言。具体HBASE的基本原理扫描大家可以自行百度下,另外,要系统掌握HBASE,推荐看下《HBASE权威指南》。
Kerberos
什么是Kerberos?
Kerberos is a network authentication protocol. It is designed to provide strong authentication for client/server applications by using secret-key cryptography.
简单地说,Kerberos是一种认证机制,通过密钥系统为客户端/服务器应用程序提供强大的认证服务。
Kerberos存在的意义
在Hadoop1.0.0或者CDH3 版本之前,并不存在安全认证一说。默认集群内所有的节点都是可靠的,值得信赖的。用户与HDFS或者M/R进行交互时并不需要进行验证。导致存在恶意用户伪装成真正的用户或者服务器入侵到hadoop集群上,恶意的提交作业,修改JobTracker状态,篡改HDFS上的数据,伪装成NameNode 或者TaskTracker接受任务等。尽管在版本0.16以后, HDFS增加了文件和目录的权限,但是并没有强认证的保障,这些权限只能对偶然的数据丢失起保护作用。恶意的用户可以轻易的伪装成其他用户来篡改权限,致使权限设置形同虚设,不能够对Hadoop集群起到安全保障。
在Hadoop1.0.0或者CDH3版本后,加入了Kerberos认证机制。使得集群中的节点就是它们所宣称的,是信赖的。Kerberos可以将认证的密钥在集群部署时事先放到可靠的节点上。集群运行时,集群内的节点使用密钥得到认证。只有被认证过节点才能正常使用。企图冒充的节点由于没有事先得到的密钥信息,无法与集群内部的节点通信。防止了恶意的使用或篡改Hadoop集群的问题,确保了Hadoop集群的可靠安全。
Kerberos的工作原理
· Client向KDC发送自己的身份信息,完成认证,获取TGT(ticket-granting ticket)
· Client利用之前获得的TGT向KDC请求其他Service的Ticket,从而通过其他Service的身份鉴别
① Client将之前获得的TGT和要请求的服务信息发送给KDC
② KDC生成用于访问该服务的Session Ticket发给Client。 Session Ticket使用KDC与Service之间的密钥加密
③ Client将刚才收到的Ticket转发到Service。由于Client不知道KDC与Service之间的密钥,所以它无法篡改Ticket中的信息
④ Service 收到Ticket后利用它与KDC之间的密钥将Ticket中的信息解密出来,验证Client的身份。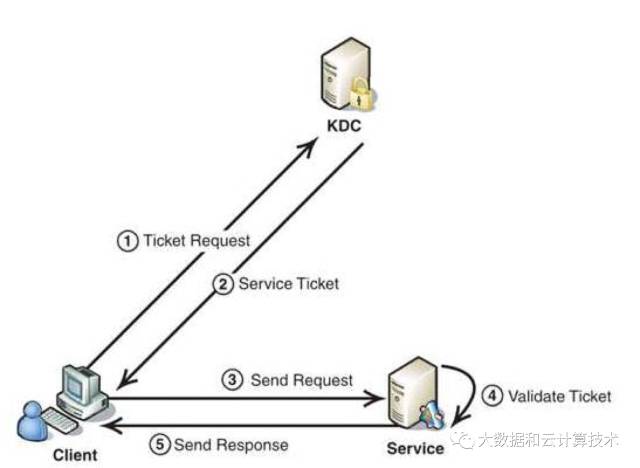
Phoenix
Phoenix最早是saleforce的一个开源项目,后来成为Apache基金的顶级项目。
Phoenix是构建在HBase上的一个SQL层,能让我们用标准的JDBC APIs而不是HBase客户端APIs来创建表,插入数据和对HBase数据进行查询。
put the SQL back in NoSQL
Phoenix完全使用Java编写,作为HBase内嵌的JDBC驱动。Phoenix查询引擎会将SQL查询转换为一个或多个HBase扫描,并编排执行以生成标准的JDBC结果集。直接使用HBase API、协同处理器与自定义过滤器,对于简单查询来说,其性能量级是毫秒,对于百万级别的行数来说,其性能量级是秒。
HBase的查询工具有很多,如:Hive、Tez、Impala、Spark SQL、Phoenix等。
Phoenix通过以下方式使我们可以少写代码,并且性能比我们自己写代码更好:
· 将SQL编译成原生的HBase scans。
· 确定scan关键字的最佳开始和结束
· 让scan并行执行
· ...
多维查询kylin
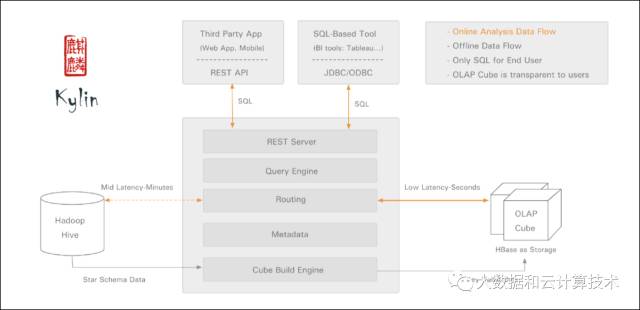
Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。
Kylin相当于给HBASE提供了一个多为查询的SQL能力。
时序列数据库OpenTSDB
OpenTSDB ,可以认为是一个时系列数据(库),它基于HBase存储数据,充分发挥了HBase的分布式列存储特性,支持数百万每秒的读写,它的特点就是容易扩展,灵活的tag机制。
其最主要的部件就是TSD了,这是接收数据并存储到HBase处理的核心所在。而带有C(collector)标志的Server,则是数据采集源,将数据发给 TSD服务。
地理数据处理套件GeoMesa
GeoMesa 是由locationtech开源的一套地理大数据处理工具套件。其可在分布式计算系统上进行大规模的地理空间查询和分析。使用GeoMesa开源帮助用户管理、使用来自于物联网、社交媒体、手机应用的海量的时空(spatio-temporal)数据。
GeoMesa支持将海量的时空数据存储到Accumulo,HBase,Google Bigtable和Cassandra数据库中,并提供高效的索引来读取、查询这些数据。并支持通过指定空间条件(距离和范围)来快速查询。另外GeoMesa还基于Apache Kafka提供了时空数据的近实时流处理功能。
通过和GIS Server(GeoServer)的整合, GeoMesa 提供了通过标准OGC接口(WMS/WFS)访问数据的能力,通过这些接口,用户可以方便对GeoMesa处理的数据进行展示和分析,比如查询、直方图、时间序列分析等。
为什么选择GeoMesa
能够存储和处理海量时空数据
支持实时性强、需要快速读写的数据
支持spark分析
支持水平扩展
通过GeoServer提供地图服务,并支持Common Query Language (CQL)
http://www.geomesa.org/
授权
GeoMesa使用Apache License Version 2.0协议。
http://apache.org/licenses/LICENSE-2.0.html
图数据库JanusGraph
Titan在停止更新了很长一段时间后,fork出了JanusGraph继续开源发展。JanusGraph是一个图形数据库引擎。JanusGraph本身专注于紧凑的图形序列化、丰富的图形数据建模和高效的查询执行。此外,JanusGraph利用Hadoop进行图形分析和批处理图处理。JanusGraph实现了健壮的模块化接口,用于数据持久性、数据索引和客户端访问。JanusGraph的模块化体系结构允许它与广泛的存储、索引和客户端技术进行互操作;它还简化了扩展JanusGraph以支持新用户的过程。
在JanusGraph和磁盘之间,有一个或多个存储和索引适配器。JanusGraph以以下适配器为标准,但是JanusGraph的模块化体系结构支持第三方适配器
JanusGraph 体系结构
1、JanusGraph的应用分为批处理(OLAP)和流式计算(OLTP)
2、批处理(OLAP),常用在大数据平台使用Spark、Giraph、Hadoop工具使用
3、流式计算(OLTP),使用TinkerPop中的Traversal(遍历)工具使用
4、数据可以存储到Cassandra、Hbase、BerkeleyDB中
5、外部查询索引存储到ElasticSearch、Solr、Lucene中
写在最后:本文主要简单总结下Hbase周边配合生态,提供SQL接口,多维查询能力,以及用于车联网,时序,地理数据处理等。后面持续写写新数仓相关文章,以飨读者。
以上是关于Hbase周边生态梳理的主要内容,如果未能解决你的问题,请参考以下文章