HBase实战 | 排查HBase堆外内存溢出
Posted HBase技术社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase实战 | 排查HBase堆外内存溢出相关的知识,希望对你有一定的参考价值。
一.溢出现象
单台服务器刚发布时 java 进程占用3g,以一天5%左右的速度增长,一定时间过后进程占用接近90%,触发服务器报警,而此时 Old 区占用在 50%,未触发 CMS GC,而导致堆外内存溢出。
异常堆栈:
top 命令查看进程占用:
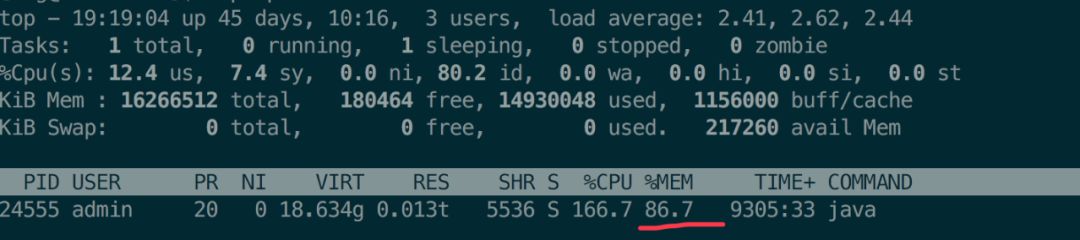
机器为 8核16G,JVM配置如下:
-Xms8g -Xmx8g -Xmn3g -Xss512k
-XX:MetaspaceSize=256m
-XX:MaxMetaspaceSize=512m
-XX:+UseConcMarkSweepGC
-XX:+DisableExplicitGC
-XX:-UseGCOverheadLimit
-XX:+UseCMSInitiatingOccupancyOnly
-XX:CMSInitiatingOccupancyFraction=70
-XX:+CMSParallelRemarkEnabled
-XX:+UseFastAccessorMethods
二.排查过程&原理分析
1.初步分析
根据异常堆栈,可以看出是 hbase.write() 分配直接内存导致的堆外内存溢出。而直接内存分配空间不足时,会调用 System.gc(),由于 JVM 参数配置了 -XX:+DisableExplicitGC 禁用了 System.gc(),且 Old 区占用才50%,未达到 CMS GC 阈值,因此抛出堆外内存溢出。
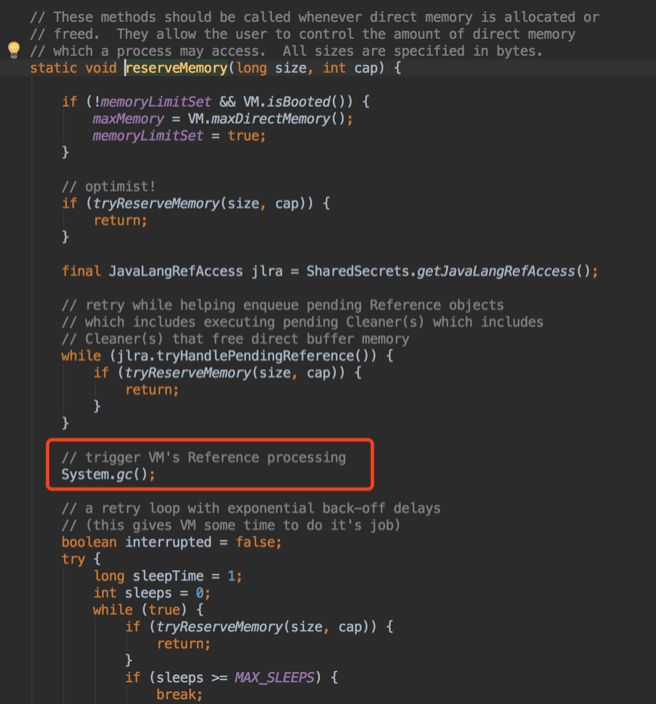
粗略的堆外内存计算方式:
JVM 未设置直接内存大小参数 -XX:MaxDirectMemorySize, 则 CMS GC堆外内存为:Old 区 - 1个 Survivor 区, 即 8G - 314M = 7.8G。
2.压测主要接口
因为不能用线上机器做实验,且不能确定是否有其他因素导致溢出。于是在性能环境使用 Jmeter 压测应用主要接口,并观察堆外内存占用。
压测后发现堆外内存占用平稳,未出现溢出现象。
3.释放 HBase Client 资源
此时将目光放到异常堆栈上,并查看系统封装的 hbase client ,发现使用完 HTable 后未调用 close() 释放资源,于是加上 close() 代码,并上线观察。但仍然出现溢出现象。
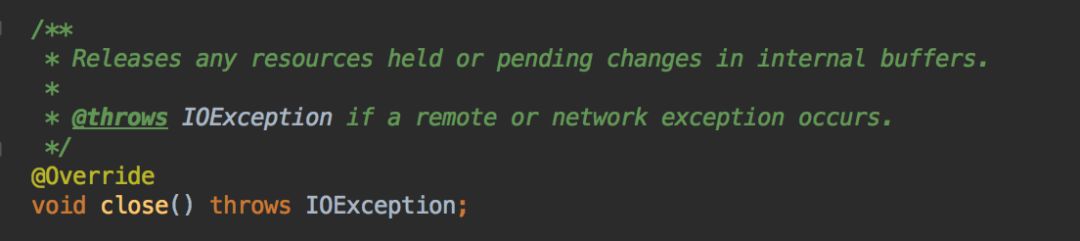
4.压测特定功能
虽然不是 HBase Client 使用的问题,但还是有相同的堆栈,说明 HBase 肯定有问题。
查找资料,发现 HBase 官方的 issue 列表里有一个堆外内存溢出的 case (hbase direct memory leak issue)。发现如果使用 JDK 的 HeapByteBuffer,在网络IO时,由于用户空间不能直接访问内核空间,因此会复制一个临时的 DirectByteBuffer 对象进行IO,且用 ThreadLocal 缓存该对象。如果使用多线程进行大数据量的网络IO,则可能导致内存溢出。
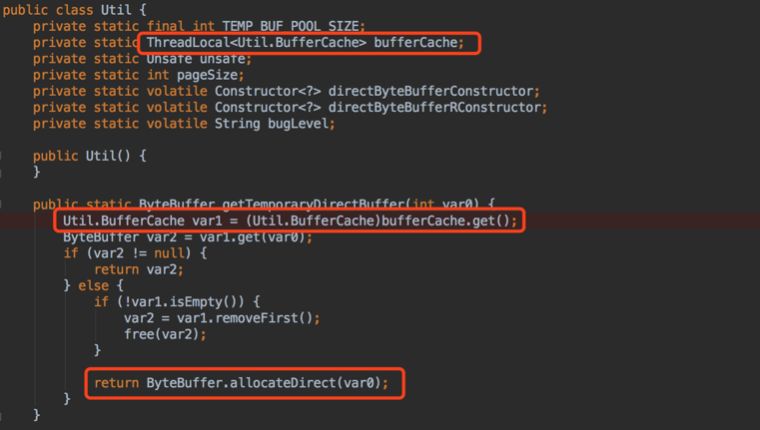
于是查看 HBase 源码,发现确实使用的是 HeapByteBuffer,使用 jVisualVM 查看 dump 文件中 java.nio.DirectByteBuffer 类的 GC Roots,发现是 HConnection 线程对象,而该对象在项目初始化时创建,并一直存活:

于是单独压测这两个接口,一次性读写10M左右的数据,并使用 gperftools 观察堆外内存占用。运行半小时出现溢出现象,观察 gperftools 文件,使用 malloc 分配堆外内存达到了 7900M:
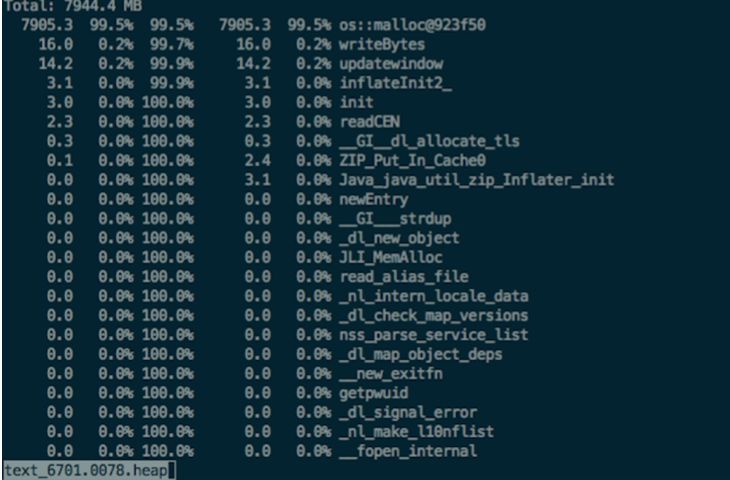
至此复现堆外内存溢出的现象,确实是 HBase 读写导致的。
5.升级 HBase Client 至 2.1.0
找到了泄露的点,那么解决方案就出来了:
不使用 HeapByteBuffer 或复用 DirectByteBuffer : 升级 HBase Client 至 2.x,默认使用 Netty
限制 JDK 缓存的堆外内存大小:JDK 升级至 JDK 9
考虑改动成本,将 HBase Client 版本升级至 2.1.0,线上运行一段时间,系统稳定,无溢出现象。
6.主要是哪里申请的堆外内存呢?
虽然已经解决了这个问题,但还有几个疑问:
压测脚本是使用 HBase 同时读写,那么到底是读,还是写造成的泄露?还是两者都有泄露?
HBase 读、写的溢出对应的是源码底层的哪一段,或是哪几段逻辑呢?
带着这些疑问,查看了一下 HBase Client 读写的源码。
1) HBase 写的源码
主要分为获取 HTable、mutate、flushCommits 三个部分:

获取 HTable 会创建一个默认线程数256的线程池,并且创建一个新的 HTable 对象:

mutate 操作会将待写入的数据放到一个本地的 writeAsyncBuffer 缓存起来:
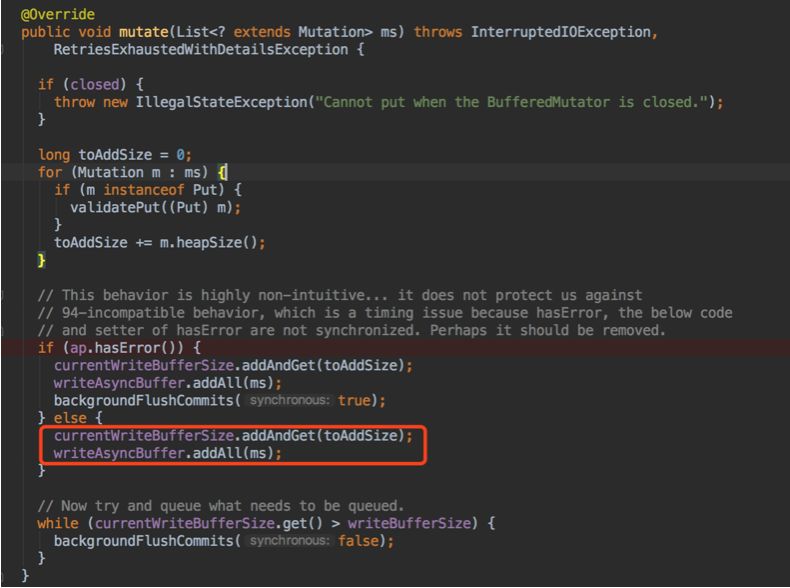
flushCommits 操作将 writeAsyncBuffer 中的数据写入到 HBase。这个过程中,HBase 把写入任务 SingleServerRequestRunnable 线程提交给线程池完成,调用方 wait 结果:

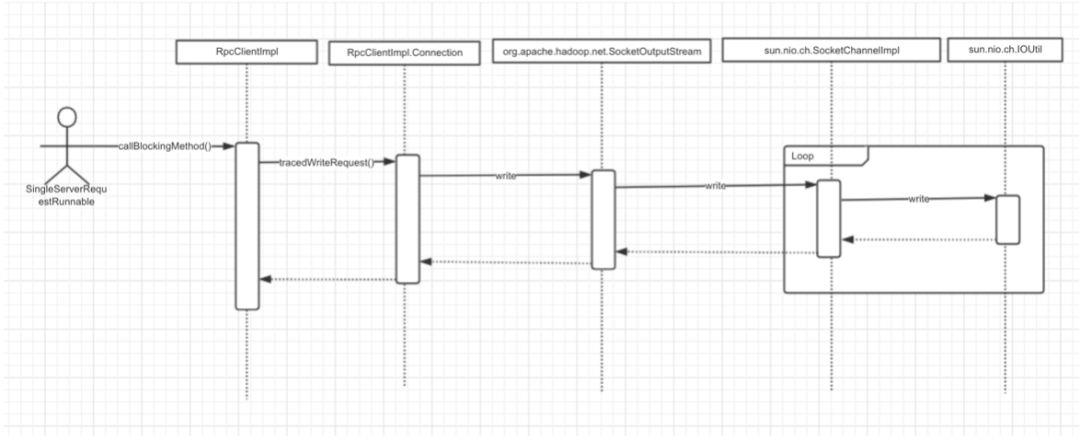
在 SingleServerRequestRunnable 线程中,调用 MultiServerCallable#call 方法,默认的 rpc实现类为 RpcClientImpl(tracedWriteRequest 中会调用 setupiostreams 方法建立连接),数据通过 HeapByteBuffer,经由 nio 的 SocketChannelImpl 写入,并循环调用 IOUtil.write() 方法,分配临时的堆外内存,造成泄露,整体流程为:
由于传入的 totalSize 为写入数据的大小(10M),因此 IOUtil.write() 申请的 DirectByteBuffer 大小为传入大小(此处 HeapByteBuffer 的 limit 为 10338890,10M左右):
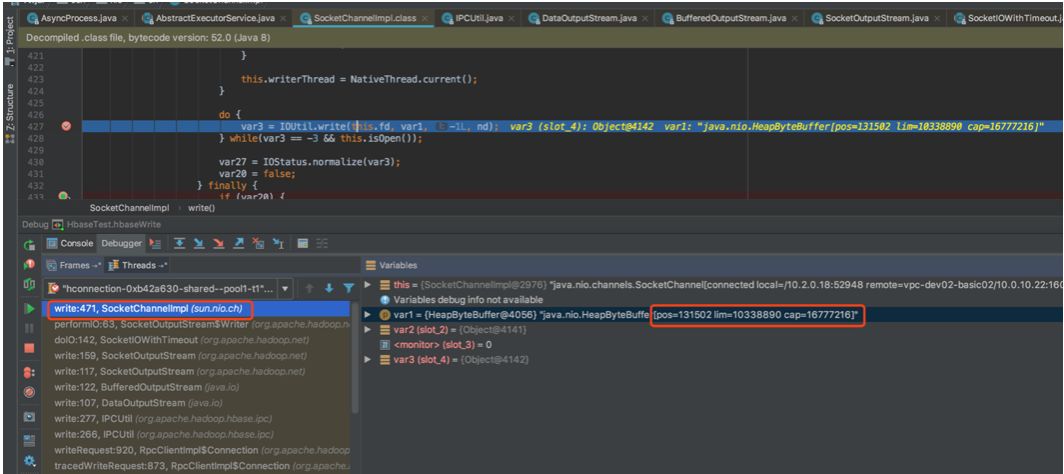
这里的线程池为前面获取 HTable 创建的,核心线程数默认256,那么最大占用堆外内存=256*10=2560M,未达到溢出的量。是不是还有其他地方在分配堆外内存呢?
2) HBase 读的源码
HTable.get() 通过匿名内部类的方式实现 RetryingCallable
#call() 接口,在 RpcClientImpl#call 方法内被调用,向 HBase 发送读请求之前初始化 socket 连接,并启动 RpcClientImpl.Connection 线程,接收数据。其中发起请求流程和 HBase 写的流程一样:
断点查看 IOUtil.read() 一次读取的字节数为 8192:
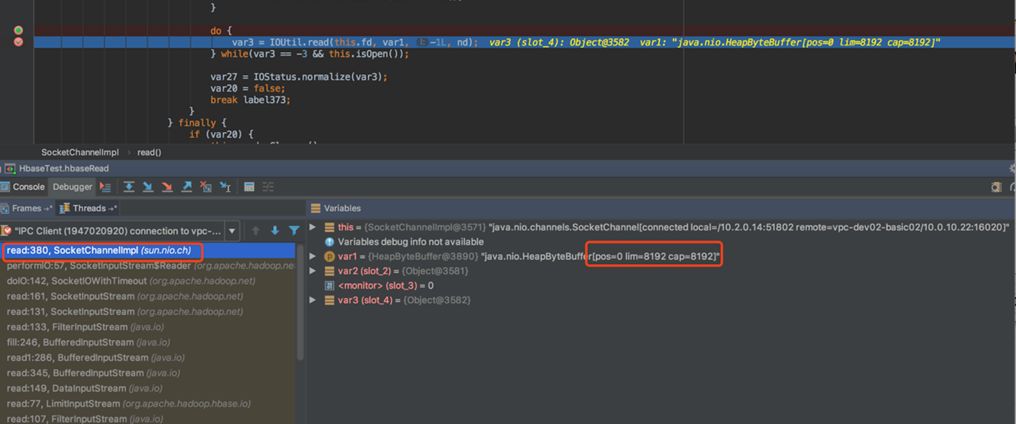
查看 BufferedInputStream 类默认一次读取的字节数为 8192:

因此虽然调用 IOUtil.read() 也不会占用太大的堆外内存,而且由于 RpcClientImpl.Connection 线程接收完数据就消亡了,持有的堆外内存也会被 gc 回收。因此 HBase 读不会造成堆外内存泄露。
7.分析性能环境 dump 文件
到这里,可以确定 HBase 写会造成泄露,但目前造成泄露的内存量远大于前面分析的值。查看性能环境的 dump 文件,使用OQL 语句查看 java.nio.DirectByteBuffer 的数量和大小,发现占据 10M 空间的对象数量有 788个,总内存大约为=10338894*788=7800M:
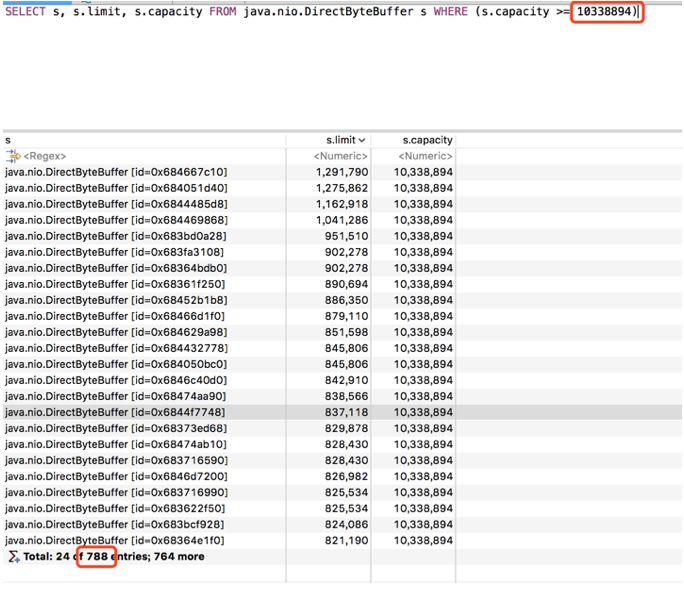
查看 java.nio.DirectByteBuffer 对象的 GC Roots,发现大量对象只有 cleaner 引用:

Cleaner 为 PhantomReference 的子类,在创建 DirectByteBuffer 对象时被创建。虚引用的作用在于跟踪垃圾回收过程,如果 GC 时发现一个对象的 GC Roots 只有虚引用,那么会将这个虚引用加入引用队列(ReferenceQueue),系统有个后台线程 Reference.ReferenceHandler 会从这个队列获取 Cleaner 对象,调用它的 clean 方法,释放资源:
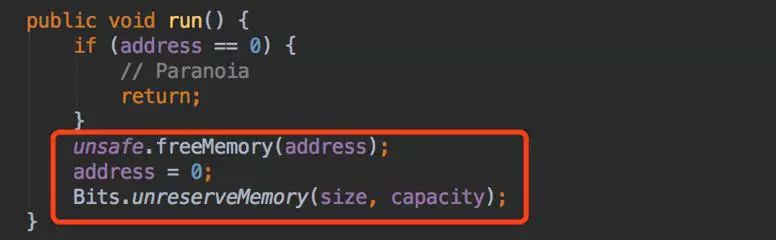
现在有大量的不可达对象,说明持有堆外内存的线程对象消亡了,但资源未被回收。jstat 查看 GC 情况,发现未进行 FGC,说明这些对象都进入了 Old 区,而导致大量的堆外内存不能被释放,造成溢出。
而根据前面的分析,会持有堆外内存对象引用的只有 HConnection 线程池中的线程。于是仔细的再梳理一遍 hbase 写的链路,发现处理网络 IO 任务的线程池,创建的时候设置了allowCoreThreadTimeOut 为 true,允许核心线程消亡,keepAliveTime 为60s:
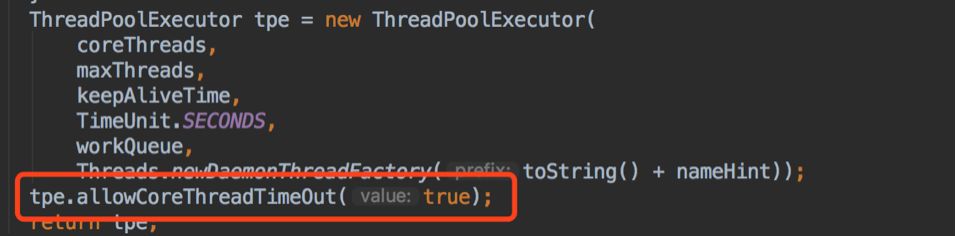
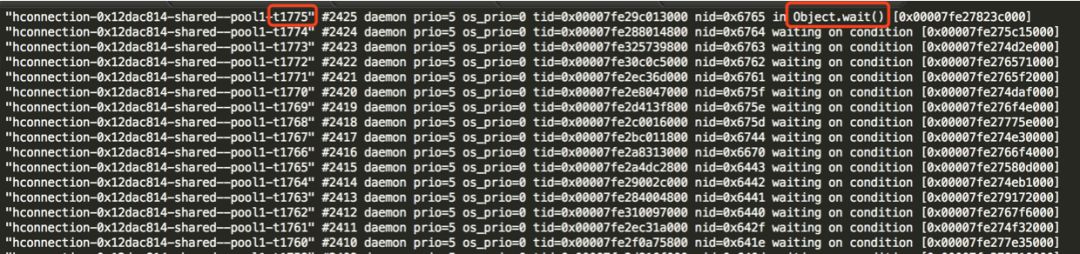
继续用 Jmeter 压测 HBase 写接口,并使用 jstack 观察 HConnection 线程的情况,发现以1s一个线程的速度进行写入时,HConnection 线程数保持在60左右,只有一个线程是活跃的,其他线程都是等待状态(waiting),且线程 count 数一直累加,说明进程一直在创建新线程并且一直有线程在消亡:
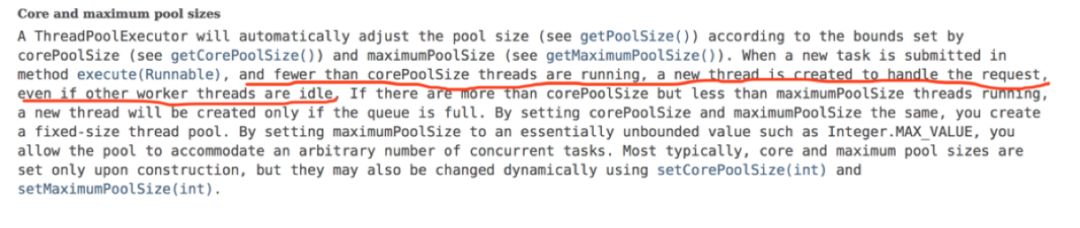
再查看线程池 ThreadPoolExecutor 源码,当线程池内活跃线程数少于核心线程数时,有新请求进来,会直接创建一个新的线程处理:
到这里基本定位到了泄露的原因。
8.总结
导致 HBase 堆外内存溢出的主要是下面几个条件共同作用的结果:
默认的 RpcClientImpl 中使用了 HeapByteBuffer: 网络IO时数据会复制到堆外内存
sun.nio.ch.Util 类会缓存堆外内存大小,且使用 ThreadLocal 方式: 引用由线程持有
异步写的线程池设置 allowCoreThreadTimeOut 为 true: 导致线程频繁消亡
写入的频率
JVM 未进行 FGC: 已进入 Old 区的不可达的线程对象,持有的堆外内存资源无法被回收
关于第四点,单独压测写入接口时,未限制频率,导致堆外内存到 3.5g 左右时,系统就直接进行 FGC 了,由于回收了堆外内存资源,因此未出现堆外内存溢出现象。
完整导致流程描述:
HBase 创建的线程池内的线程使用 HeapByteBuffer 存储数据,网络IO前会将数据复制到堆外内存对象 DirectByteBuffer 中;而 JDK 会以 ThreadLocal 的方式缓存该 DirectByteBuffer 对象申请的堆外内存,如果线程不消亡则不释放该内存;同时该线程池允许核心线程消亡,当业务方以一定的频率调用 HBase 写接口时,导致有些线程对象消亡并进入 Old 区;由于未进行 FGC,这些线程对象无法被回收,占用的堆外内存资源也无法被 GC 回收。一段时间后,造成堆外内存溢出。
对象进入 Old 区有很多可能,比如:
Eden 区空间不足
长期存活对象进入 Old 区(线上查看存活年龄配置: jinfo -flag MaxTenuringThreshold = 6)
梳理到这里,那么解决方案就多了几种,比如:
配置 RpcClient 实现为 AsyncRpcClient (使用 Netty 方式,性能环境已验证)
使用 Connection#getTable(tableName, pool) 传入自定义的线程池,设置allowCoreThreadTimeOut 为false,并限制每次写入的大小 (已验证)
提高核心线程消亡时间
控制 HBase 写入的频率
调低FGC 的阈值
调大JVM年龄计数器
以上就是完整的流程了,如有疑问可与我交流。
三.工具简介
前面排查堆外内存溢出的过程中,使用了很多工具,主要有:
JDK 命令行工具: jps, jstat, jmap
JDK 提供的内存监控工具: jConsole, jVisualVM
Eclipse 提供的内存分析工具: mat
Google 的监控堆外内存工具: gperftools
性能压测工具: jmeter
查看进程内存: smaps, pmap, gdb
sun 推出的针对 java 的动态追踪工具: btrace
具体的工具用法就不介绍了,可自行搜索资料。
四.后记
已反馈至 HBase issue:
https://issues.apache.org/jira/browse/HBASE-19320


以上是关于HBase实战 | 排查HBase堆外内存溢出的主要内容,如果未能解决你的问题,请参考以下文章
利用阿里云ARMS排查Java大量文件处理场景堆外内存溢出(线上JVM排障之八)
利用阿里云ARMS排查Java大量文件处理场景堆外内存溢出(线上JVM排障之八)
实战经验 | Cassandra Java堆外内存排查经历全记录