大数据存储- Hbase 基础
Posted 大数据江湖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据存储- Hbase 基础相关的知识,希望对你有一定的参考价值。
由于疫情原因在家办公,导致很长一段时间没有更新内容,这次终于带来一篇干货,是一篇关于 Hbase架构原理 的分享。
Hbase 作为实时存储框架在大数据业务下承担着举足轻重的地位,可以说目前绝大多数大数据场景都离不开Hbase。
今天就先从 Hbase 基础入手,来说说 Hbase 经常用到却容易疏忽的基础知识。
本文主要结构总结如下:
Hbase 安装依靠 Hadoop 与 Zookeeper,网上有很多安装教程,安装比较简单,这里我们就着重看下 Habse 架构,如图:
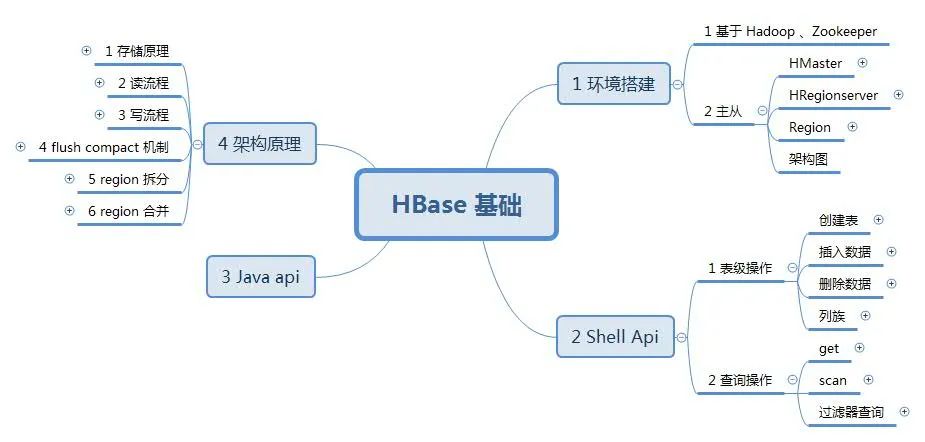
可以从图中看出,Hbase 也是主从架构,其中 HMaster 为主,HRegionServer 为从。
Zookeeper 主要存储了Hbase中的元数据信息,如哪个表存储在哪个 HRegionServer 上;
HLog 是作为 Hbase 写数据前的日志记录;
BLockCache 作为读写数据的缓存;
HMaster:
负责新Region分配到指定HRegionServer
管理HRegionServer 间负载均衡,迁移 region
当HRegionServer 宕机,负责 region 迁移
HRegionserver:
响应客户端读写请求
管理Region
切分变大的 Region
Region:
一个 Region 对应一个 Table 表
Hbase 存储的最小单元
Hbase 列式存储的结构与行式存储不同,它的表模型类似下图:

表中大致可以分为 rowKey 、列族 、版本号三大元素,列族下可以创建多个列,表中的每一个单元格又称为 cell,需要注意的是 cell 并不是只有一个数据,它可以有多个版本从而实现在同一rowkey ,同一列族, 同一列下存储多个数据。
重点来了
有了上面的铺垫,接下来就可以进入正题部分了 ,下面我们来看下 Hbase 的架构原理。
1. Hbase 的存储原理
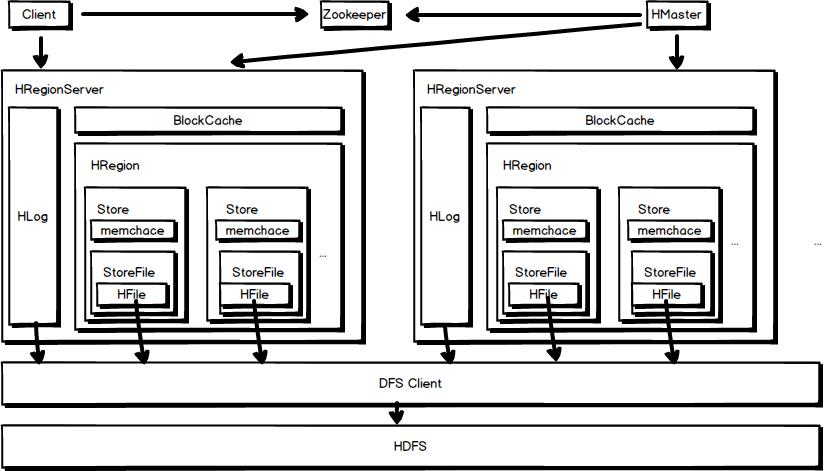
还回到上边的架构图,可以看到 一个 HRegionServer 上有多个 HRegion,一个 Region 实际上就对应了一张表,由于 region 的拆分机制,同一张表的数据可能不会在一个HRegionServer上, 但是一个 Region 肯定只存一张表的数据。
下面我们再看看 HRegion 里面的结构:
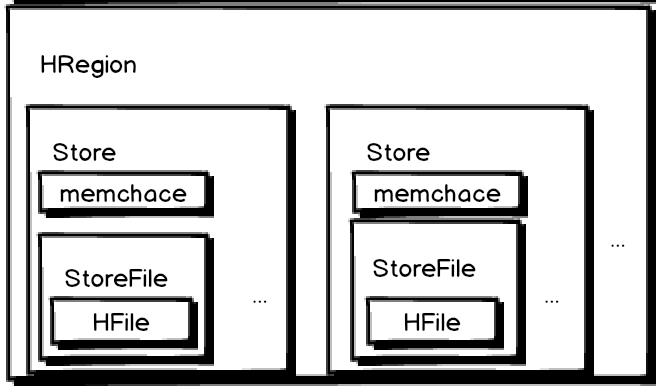
从图中我看可以看到以下几点:
一个region包含多个 store,其中 :
一个列族就划分成一个 store
如果一个表中只有1个列族,那么每一个region中只有一个store
如果一个表中只有N个列族,那么每一个region中有N个store
一个store里面只有一个memstore
memstore 是一块内存,数据会先写进 memstore,然后再把数据刷到硬盘
一个store里面有很多的StoreFile,最后数据以很多 HFile 这种数据结构存在HDFS上
StoreFile 是 Hfile 的抽象对象,说到StoreFile就等于HFile
每次 memsotre 刷新数据到磁盘,就生成对应的一个新的 HFile
2. Hbase 的读流程
在说读读写流程前,需要说明一下,整个 HBase集群,只有一张meta表(元数据信息表),此表只有一个region,该region数据保存在一个HRegionServer上 。
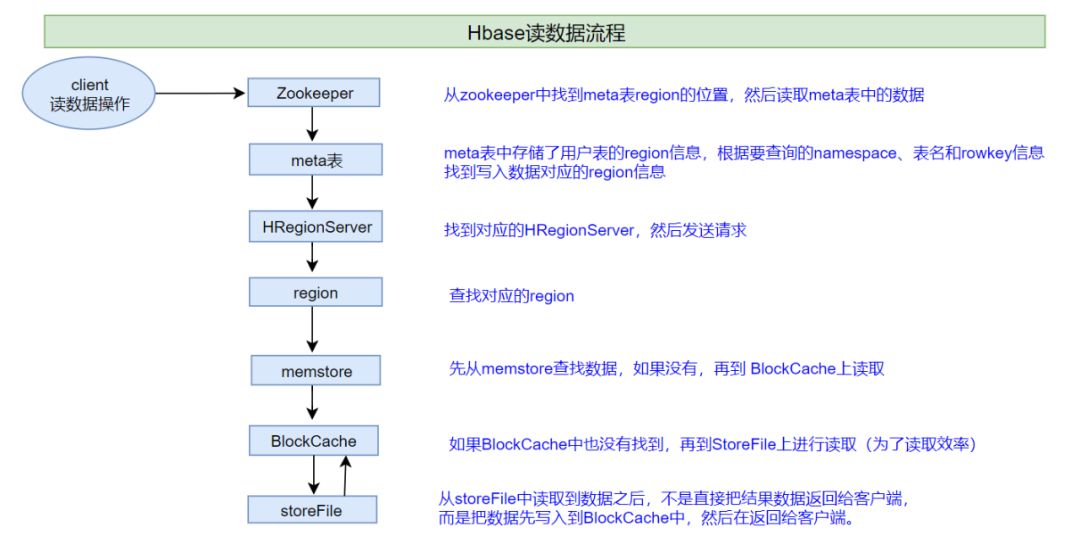
1、客户端首先与zk进行连接;从zk找到meta表的region位置,即meta表的数据存储在某一HRegionServer上;客户端与此HRegionServer建立连接,然后读取meta表中的数据;meta表中存储了所有用户表的region信息,我们可以通过
scan 'hbase:meta'来查看meta表信息2、根据要查询的namespace、表名和rowkey信息。找到写入数据对应的region信息
3、找到这个region对应的regionServer,然后发送请求
4、查找并定位到对应的region
5、先从memstore查找数据,如果没有,再从BlockCache上读取
一部分作为Memstore,主要用来写;
另外一部分作为BlockCache,主要用于读数据;
HBase上Regionserver的内存分为两个部分
6、如果BlockCache中也没有找到,再到StoreFile上进行读取
从storeFile中读取到数据之后,不是直接把结果数据返回给客户端,而是把数据先写入到BlockCache中,目的是为了加快后续的查询;然后在返回结果给客户端。
3. Hbase 的写流程
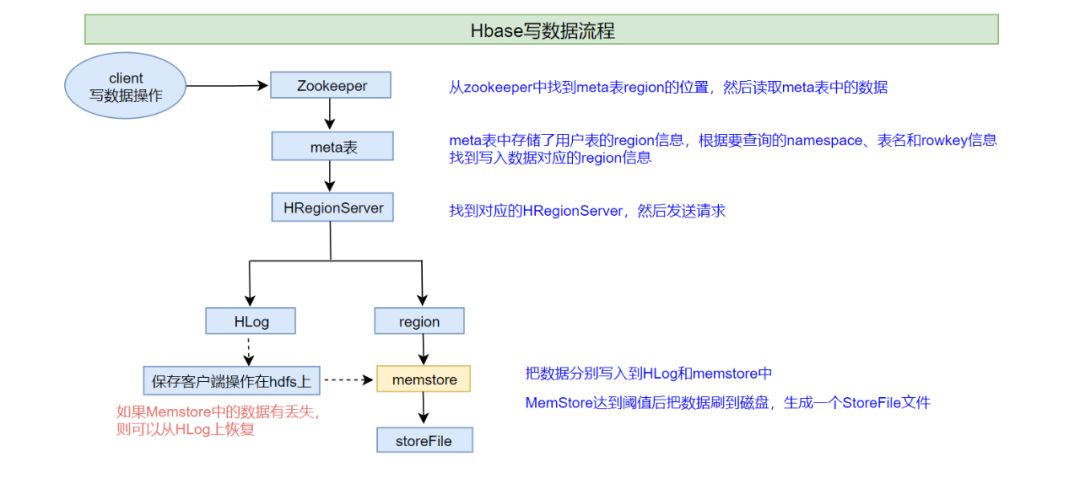
1、客户端首先从zk找到meta表的region位置,然后读取meta表中的数据,meta表中存储了用户表的region信息
2、根据namespace、表名和rowkey信息。找到写入数据对应的region信息
3、找到这个region对应的regionServer,然后发送请求
4、把数据分别写到HLog(write ahead log)和memstore各一份
write ahead log :也称为WAL,类似mysql中的binlog,用来做灾难恢复时用,HLog记录数据的所有变更,一旦数据修改,就可以从log中进行恢复。
5、memstore达到阈值后把数据刷到磁盘,生成storeFile文件
6、删除HLog中的历史数据
4. Hbase 的 flush 与 compact 机制
概括来说,flush 是数据由 memstore 刷写到磁盘的过程,compact 是 磁盘文件合并的过程,如图所示:
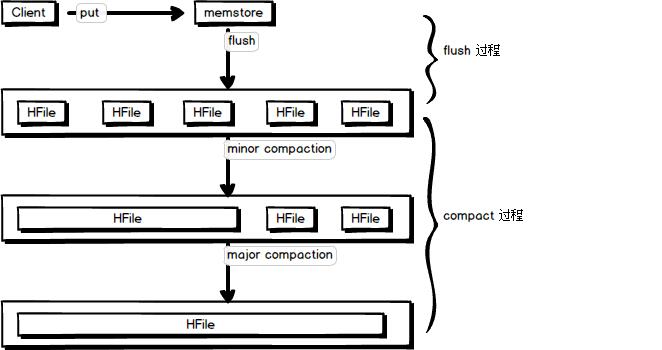
flush 机制
flush 大致可以分为三个阶段,prepare 阶段,flush 阶段,commit 阶段:
prepare 阶段
遍历当前 Region 中所有的 Memstore,将Memstore中当前数据集CellSkipListSet 做一个快照snapshot,之后创建一个新的CellSkipListSet,后期写入的数据都会写入新的CellSkipListSet中
flush 阶段
遍历所有Memstore,将 prepare阶段生成的 snapshot 持久化为临时文件,临时文件会统一放到目录.tmp下。这个过程因为涉及到磁盘IO操作,因此相对比较耗时
commit 阶段
遍历所有 Memstore,将 flush阶段生成的临时文件移到指定的ColumnFamily目录下,针对HFile生成对应的storefile和Reader,把storefile添加到HStore的storefiles列表中,最后再清空prepare阶段生成的snapshot 。
flush 的触发条件一般分为 memstore 级别,region 级别,regionServer 级别,HLog数量上限,具体配置可在官网文档中查询到。
compact 机制
从图中可以看出 compact 合并机制,主要分为 小合并 、大合并两个阶段。
minor compaction 小合并
将Store中多个HFile合并为一个HFile,一次Minor Compaction的结果是HFile数量减少并且合并出一个更大的StoreFile,这种合并的触发频率很高。
major compaction 大合并
合并 Store 中所有的 HFile 为一个HFile,被删除的数据、TTL过期数据、版本号超过设定版本号的数据。合并频率比较低,默认7天执行一次,并且性能消耗非常大,建议生产关闭(设置为0),在应用空闲时间手动触发。一般可以是手动控制进行合并,防止出现在业务高峰期。
5. Hbase 的 region 拆分 与 合并
region 的拆分
为什么要拆分 region 呢?
region中存储的是大量的 rowkey 数据 ,当 region 中的数据条数过多, region 变得很大的时候,直接影响查询效率.因此当 region 过大的时候.hbase会拆分region , 这也是Hbase的一个优点 。
region 拆分策略
0.94版本前默认切分策略,当region大小大于某个阈值(hbase.hregion.max.filesize=10G)之后就会触发切分,一个region等分为2个region。
0.94版本~2.0版本默认切分策略 :根据拆分次数来判断触发拆分的条件
region split的计算公式是:
regioncount^3 * 128M * 2,当region达到该 size 的时候进行split
例如:
第一次split:1^3 * 256 = 256MB
第二次split:2^3 * 256 = 2048MB
第三次split:3^3 * 256 = 6912MB
第四次split:4^3 * 256 = 16384MB > 10GB,因此取较小的值10GB
后面每次split的size都是10GB了
预分区机制
当一个Hbase 表刚被创建的时候,Hbase默认的分配一个 region 给table。也就是说这个时候,所有的读写请求都会访问到同一个 regionServer 的同一个region中,这个时候就达不到负载均衡的效果了,集群中的其他 regionServer 就可能会处于比较空闲的状态。
为了解决这个问题,就有了 pre-splitting,也就是预分区机制,在创建table的时候就配置好,生成多个region,这样的好处就是可以优化数据读写效率;并且使用负载均衡机制,防止数据倾斜。
操作很简单,在创建表时,手动指定分区就好了:
create 'person','info1','info2',SPLITS => ['1000','2000','3000','4000']region 的合并
Region的合并不是为了性能, 而是出于维护的目的 。
比如删除了大量的数据 ,这个时候每个Region都变得很小 ,存储多个 Region就浪费了 ,这个时候可以把Region合并起来,进而可以减少一些 Region 服务器节点,由此可见 region 的合并其实是为了更好的维护 Hbase 集群。
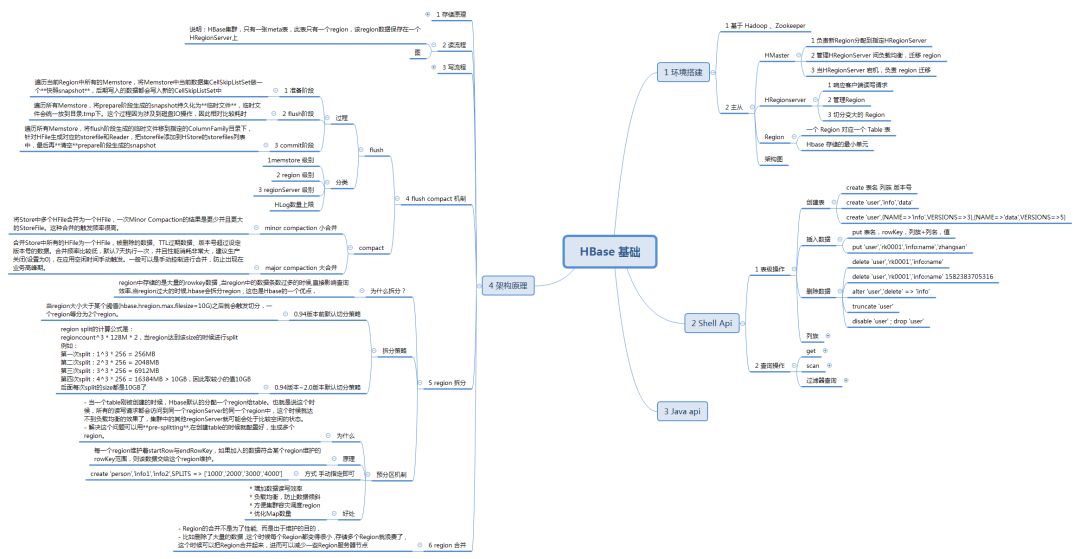
至此,正文内容就结束了,为了更好的梳理这些知识,我将文章中重要的部分都放到下面这张图中,方便以后总结查阅:
PS:后续文章更新方向除涉及大数据框架方向外,额外添加 C 语言和数据结构等计算机基础方向,敬请期待 ~

长按关注,解锁更多精彩内容
以上是关于大数据存储- Hbase 基础的主要内容,如果未能解决你的问题,请参考以下文章