「零基础学大数据」HBase基础
Posted 万码学堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了「零基础学大数据」HBase基础相关的知识,希望对你有一定的参考价值。
1. 应用示例
搜索引擎中需要存储大量页面内容和网页之间的链接信息。其中域名可认为不会改变,但页面内容和网页之间的链接信息可能会经常改变,因此可能需要维护多个版本快照。上述数据可通过如下所示的结构进行存储。
· 域名(com.cnn.www)+标识(anchor:cnnsi.com)+时间戳(t9) ==> 数据(CNN)
· 域名(com.cnn.www)+标识类别(anchor)+标志(cnnsi.com)+时间戳(t9) ==> 数据
BigTable的数据模型。
2. HBase简介
HBase是一个用Java写的分布式列式数据库,最初是BigTable的开源实现。它最初是Apache Hadoop的一部分,其第一个版本在2007年10月,随Hadoop 0.15.0 捆绑发布,后在2010年从Hadoop子项目升级为Apache顶级项目,开始独立发展。
TIP:
由于历史发展原因,HBase和Hadoop存在较强的版本耦合,不同版本间存在一定兼容性问题,详见下表。其中S表示支持,X表示不支持,NT表示未知。
HBase-1.2.x |
HBase-1.3.x |
HBase-2.0.x |
|
Hadoop-2.4.x |
S |
S |
X |
Hadoop-2.5.x |
S |
S |
X |
Hadoop-2.6.0 |
X |
X |
X |
Hadoop-2.6.1+ |
S |
S |
S |
Hadoop-2.7.0 |
X |
X |
X |
Hadoop-2.7.1+ |
S |
S |
S |
Hadoop-2.8.[0-1] |
X |
X |
X |
Hadoop-2.8.2 |
NT |
NT |
NT |
Hadoop-2.8.3+ |
NT |
NT |
S |
Hadoop-2.9.0 |
X |
X |
X |
Hadoop-3.0.0 |
NT |
NT |
NT |
3. HBase原理
3.1. HBase整体架构
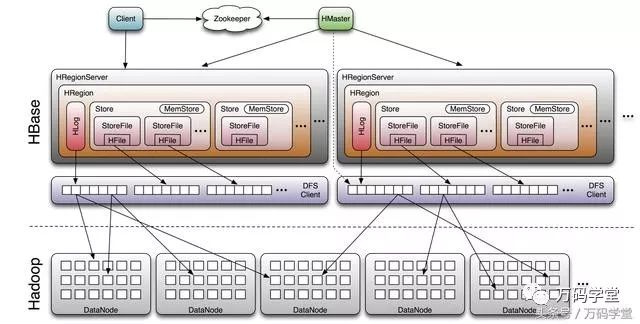
TIP:
HBase架构中有一个十分重要的Zookeeper组件,它也是Apache基金会下的开源项目。该组件可以看做一个“公共白板”,主要用来完成分布式协调工作,如今被广泛应用于其他很多大数据相关项目中。
3.2. HBase表逻辑结构
简单看来,HBase是一个很大的Map,它通过一个有顺序的四元组 (rowkey, column_family, column, version) 来索引一条数据,其中rowkey表示行键,column_family表示列簇,column表示列,version表示时间戳。其中列簇和列通常写在一起,以“:”分隔,例如“cf1:c1”。

3.3. HBase表物理分割
HBase表内数据按照rowkey的字典序排序,被尽可能分割成大小相同的region。每个region server保存多个region的信息,对外提供服务。
TIP:
HBase中rowkey通常是一个“复合式的主键”,它设计至关重要,将直接影响数据的写入、查询速度。
无论HDFS还是HBase,都适合用于“一次写入,多次读取”的场景。
3.4. Hbase特点
1、列式存储,符合很多大数据应用场景的需求;
2、基于HDFS,天然具有良好的伸缩性;
3、提供WAL(写前日志)功能,保障数据可靠性;
4、弱中心化的设计以及region server的自动故障恢复为HBase提供了较高的可用性;
5、支持行级事务;
6、按照rowkey进行查询具有较高的性能。
以上是关于「零基础学大数据」HBase基础的主要内容,如果未能解决你的问题,请参考以下文章