强化学习05 | 动态规划:场景
Posted YESLAB
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强化学习05 | 动态规划:场景相关的知识,希望对你有一定的参考价值。
又到了学习干货的时间

在强化学习第四课中,我参考了《Reinforcement Learning: An Introduction》 一书的内容,而这本书对动态规划同样有着精准的定义: “The term dynamic programming (DP) refers to a collection of algorithms that can be used to compute optimal policies given a perfect model of the environment as a Markov decision process (MDP).”所以讨论动态规划前,需要确定所讨论的过程是一个有限马尔可夫过程,即物体在环境中具备状态(s,集合为S),可以完成行动(a,集合为A),会获得环境给予的相应奖励(r, 集合为R),而这一切都是具有概率的 ,而每一次动作的概率,就像我们股票每次的买进卖出一样,关乎我们的长期收益。

不过我们还是得先来看看跳不过去的数学坑(公式1 与 公式2):
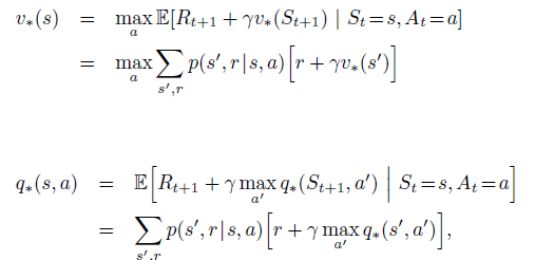

这两个公式其实是用两种定义的数值来表达长期收益,第一个叫状态价值函数(v(s)),第二种是动作价值函数(q(s,a)),不论哪种方式,单次收益都会被表示为“单次奖励 + 单次状态值”这样的数学模型, 而这个长期收益肯定是可以优化的,深度强化学习中会用神经网络来干这种事情,那是后话,是目前阶段无法抵达的海岸,所以我们还是先从有意思的东西着手,一个经典的格子游戏。

4x4的方格构成了冰面游戏:
脚下是冰,随时会塌,从起点走到终点,怎样才是最好的路线规划呢?
我们用表格来表示这个冰面游戏:
始 |
冰 |
冰 |
冰 |
冰 |
洞 |
冰 |
洞 |
冰 |
冰 |
冰 |
洞 |
洞 |
冰 |
冰 |
终 |
▲始——游戏进入点;
▲冰——正常厚冰面,可以安全行走;
▲洞——踩上去会塌陷的薄冰面,非常危险;
▲终——游戏结束点。

把你的AI放在起始点,让它自己开始玩吧!
重新布局
首先我们需要将游戏塑造为适合AI理解的东西,所以上面的游戏方阵需要重新布局为下面的形式。
S1 |
S2 |
S3 |
S4 |
S5 |
S6 |
S7 |
S8 |
S9 |
S10 |
S11 |
S12 |
S13 |
S14 |
S15 |
S16 |
现在每个格子都有自己的状态值了,其实这些状态值也就是公式1中的v(s),但是这些状态值都是多少呢?你可以自己设定,例如像S2这种普通冰面的状态值应该设计大一些,因为路确实好走,而S6这种危险路面状态值就需要小很多,且有可能是负值,因为如果走上去,你的AI可能需要花一点时间爬出来,这样的游戏场景,按照公式1,如果AI一路都走在浅蓝色格子,并最终到达终点S16,那么长期收益必然相当可观。 当然我们需要一种更天然的方法来计算这些状态值,而不是依靠人脑来填入那些值,这个方法被称为“迭代策略评估”,它是整个动态规划的重要组成部分。
奖励机制
如果由人类来指定每个格子的状态值会显得有些不科学,那么由人类来指定游戏规则就显得优雅多了。当我们为每个可能发生的动作设计奖励机制时,就可以设计以下这些计分规则:
▲S12和S15走向S16的路径应给予极大的奖励(+5分),因为AI能这么走的话说明它成功完成游戏了;
▲所有向上、向左的回头路都不是推荐的,应给予小扣分(-1分);
▲所有通向深蓝色冰洞的走法都是应该严格惩罚的,给予极大扣分(-3分);
▲其余情况统一给予正常奖励(+1分);
▲ 格子之外是不允许走的,当AI做出不允许的动作,就让它待在原地,所以不需要奖励(0分)。
设计好的奖励规则如下图:
上:不允许 左:不允许 下:+1 右:+1 |
上:不允许 左:-1 下:-3 右:+1 |
上:不允许 左:-1 下:+1 右:+1 |
上:不允许 左:-1 下:-3 右:不允许 |
上:-1 左:不允许 下:+1 右:-3 |
上:-1 左:-1 下:+1 右:+1 |
上:-1 左:-3 下:+1 右:-3 |
上:-1 左:-1 下:-3 右:不允许 |
上:-1 左:不允许 下:-3 右:+1 |
上:-3 左:-1 下:+1 右:+1 |
上:-1 左:-1 下:+1 右:-3 |
上:-3 左:-1 下:+5 右:不允许 |
上:-1 左:不允许 下:不允许 右:+1 |
上:-1 左:-3 下:不允许 右:+1 |
上:-1 左:-1 下:不允许 右:5 |
The End |
以上奖励值,就是公式1中的R值,之所以称为 是指这个奖励是在下一时刻做完动作才会得到的,即如果AI处于起始点S1,如果下一时刻向右走向S2,就会获得 +1 的奖励。
行动概率
今天所描述的内容没有涉及到策略与概率,所以我们假设每个行动都有1/4 的概率,即无论AI在哪个格子,都可以均等选择上、下、左、右的行为(当然不允许就代表着等待,也是一种行为,不影响概率)
迭代策略评估算法
当AI站在起始点S1时,它所处的位置应该有自身价值,而这个价值取决于未来它能选择的路是否好走,就像有些人一出生家里很有钱,人生道路可能会缺少磨难,那么他一生的估值可能会高,但人生的事情谁知道呢。当我们计算位置S1的估值时,就假设这个值是公式1里等号最左边的那个家伙 ,我们给它换个容易记的名字V(S1),显然从S1只有两个有效动作可以做,就是向下走一步或者向右走一步,以及两个无效动作——等待,且每个动作都有0.25的概率(1/4)。
那么 V(S1)= 0.25*(向上奖励+向上状态值) + 0.25*(向左奖励+向左状态值) + 0.25*(向下奖励+向下状态值) + 0.25*(向右奖励+向右状态值)。
即 V(S1)= 0.25*0 + 0.25*0 + 0.25*(1+V(S2)) + 0.25*(1+V(S5));
哇哦,我们用S2和S5的值表示了S1的值,也就是说,这种状态值具有一定的学习能力,我们再来看一个,假如我们的AI不慎走入了S12:
则有 V(S12)= 0.25*(-3+V(S8)) + 0.25*(-1+V(S11)) + 0.25*(5) + 0.25*0;
可以想象所有的V(S)值都会被其他相邻的V(S)值牵制,而最佳的V(S)值应该是最契合于游戏的奖励机制的,一旦这样的数据模型被搭建起来了,我们就可以给予各个V(S)值初始值并进行迭代,例如所有的V(S)都给予0的初始值,设计程序反复计算各个V(S)值即可,最后会收敛到一个一定程度上可以契合此游戏的V(S)值集群,收获了不错的V(S)值之后,就可以说游戏中的场景都搭建完工了,哪里是坑、哪里是路、哪里走起来容易等这些问题已经被固化在了游戏方格中,以数字这种AI可以理解的形式。
一个很聪明的AI,不仅需要依靠地形环境的评分,还需要了解行动后的奖励情况,并根据这些条件计算自己做出动作的欲望(动作价值 q),才能规划自己最优的路径,而整个规划过程都是动态迭代计算的,这种动态规划的思想为强化学习提供了很好的环境探知方法,关于如何计算q(s,a)请看下回分解。
以上是关于强化学习05 | 动态规划:场景的主要内容,如果未能解决你的问题,请参考以下文章