大话脑影像之:统计学检验方法总结及R语言实现 Posted 2021-04-18 思影科技
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大话脑影像之:统计学检验方法总结及R语言实现相关的知识,希望对你有一定的参考价值。
一、前言
我们平时分析的数据基本属于两种类型:定性数据(类别变量,数字只有标签含义)及定量数据(数值型变量,每个数值有实际的含义)。针对定量数据资料,我们常用的方法有正态分布检验( KM检验, shipro检验), t检验,方差分析,还有一些没那么常见的 Wilcoxon秩和检验, Mann-Whitney检验及 Kruskal-wallis检验等。针对定性资料,检验方法有各种二维列联表的检验。方法很多,如果不及时进行梳理、总结的话,很容易混淆。总感觉,这个方法可以用,那个也可以(见别人用过)。但是,不同的数据类型,不同的数据分布,其检验方法不同;不同的检验方法,对数据的适用条件也不同。
所以,本文的目的,就是对各种统计检验方法进行梳理、总结,帮大家省却一小部分时间,也让自己胸中更有丘壑,头脑更加清明。同时,本文也将涉及到的统计检验方法的 R语言实现代码罗列出来,让大家能够简单的检验自己的数据集。
首先还是说明一下参数检验和非参数检验的区别 ,见下表:
我们首先会对样本数据做一个最基本的
正态分布检验,
以此决定,该选用参数检验派的一箩筐检验方法还是非参数检验派的方法。我们肯定是希望用参数检验,因为参数检验用的信息是真实的数据,而非参数检验用到的信息是将这些真实值,转换为秩(理解为位置,或者排序)了,检验过程中损失了大量的有效信息,除此以外还有一些其他原因共同导致了他的检验效能较低。
正态分布检验的实现方法有很多,本文总结几种常见的,详情看下表:
函数
输入
结果
适用范围
R包
shapiro.test()
一个参数:数值型数据,理解为你数据集的任何一列:
Shp <- shapiro.test(test)
小样本时使用,可以存在缺失值,非缺失样本量大于3即可
fBasics
基础包无需加载,函数直接用就行
ks.test()
三个参数:一列数据,均值,方差
KS <- ks.test(test,0,1)
非参数检验方法,适用范围广。
fBasics
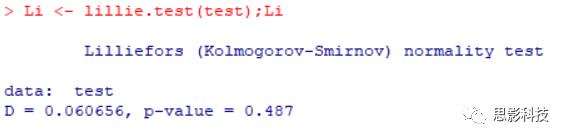
lillie.test()
一个参数:数值型数据
Li <- lillie.test(test)
基于KS的正态性检验,非缺失样本量大于4
nortest
非基础包需要library(nortest)后,才能使用检验函数
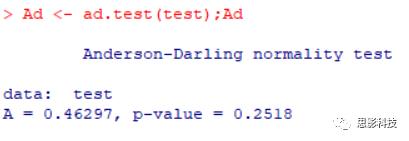
ad.test()
一个参数
Ad <- ad.test(test)
可以有缺失值,但非缺失样本量必须大于7
nortest
test测试数据是通过 rnorm(100)随机生成的 100个服从正态分布的数据,所有以上方法的统计检验结果 P值都大于 0.05,说明数据服从正态分布。平时见到的 KS检验用的最多,非参数检验门槛低。如果数据有一两百例,就别考虑 Shapiro.test()了。一般认为 n>30,可以认为是大样本。
讲了正态分布后,还需要再说一个检验:方差齐性检验。不管是 t检验还是方差分析,比较的都是均值有无差异。 Fisher先生在推导 F分布的时候,是基于样本满足正态分布及方差同质(方差齐性)两个基础假设来的,如果两个条件不满足, F分布就会出现偏差。与此类似,双样本 T检验中,如果方差不齐,合并方差需要做一定的修正,才能很好的满足 t分布。但实际中的样本,大多数情况是异方差,同方差的情况才是少见。有实验表明,当样本量足够大,且两组样本量差距比较小时,可以忽略异方差的影响。如果样本量较小,且两组数据的样本差异较大时,还是老老实实按照书上的步骤,一步步把检验做了。本文对常见的方差齐性的检验方法总结如下:
函数
输入
结果
适用范围
R包
bartlett.test()
2个参数:数值型数据,因子型数据:
Bar <- bartlett.test(count ~ spray, data = InsectSprays)
样本服从正态分布时使用
Stats
基础包无需加载,函数直接用即可
leveneTest()
2个参数:数值型数据,因子型数据:
Lev <-car:: leveneTest(count ~ spray, data = InsectSprays)
相较于Bartlett检验,这一方法更为稳健
car
这个包不是基础包,需要library加载下哦
fligner.test()
2个参数:数值型数据,因子型数据:
Fli <- stats::fligner.test(count ~ spray, data = InsectSprays)
非参数的检验方法,完全不依赖于对分布的假设
Stats
本表中,输入列的 data通过函数 “require(graphics)”获得,采用 “str(InsectSprays)”函数可以看到 InsectSprays数据集中的所有指标及其数据类型。
OK,讲了正态分布和方差齐性的检验,我们就可以进入正题了。你的数据,满足正态分布假设检验的,就进入参数检验方法,否则,选择非参数检验。本文所讲的内容基本如下:
检验类型
参数检验
非参数检验
使用条件
差异检验(定量资料)
与某数字的对比
单样本t检验
单样本wilcoxon检验
满足方差齐性要求,参数检验,否则非参数检验
两组数据对比
独立样本t检验
Mann-Whitney检验
满足方差齐性要求,参数检验,否则非参数检验
多组数据对比
方差分析
Kruskal-wallis检验
满足方差齐性要求,参数检验,否则非参数检验
配对数据对比
配对样本t检验
配对样本wilcoxon检验
满足方差齐性要求,参数检验,否则非参数检验
列联表检验(定性资料)
pearson卡方检验
实际观测值与理论推断值之间的偏离程度:T>=5 & n>40
Fisher检验
两组分类间是否有显著关系:T<1 & n<40
Cochran-Mantel–Haensze卡方检验
Fisher精准检验在大样本下的渐进形式
相关性检验
pearson相关性检验
spearman相关性检验
服从正态分布,参数检验,否则非参数检验
一致性检验
两组数据的一致性
Kappa一致性检验
评价两种方法是否存在一致性,定性数据
配对χ2检验(McNemar检验)(又称边缘齐性检验)
确定两种方法结果前后是否有差别
多组数据的一致性
ICC组内相关系数
用于研究评价一致性,定量&定性数据
(其实看了这个表几乎就看了全文了,不过文中还是把实现方法讲一下,通过输入实际案例,让读者更好的理解检验的作用。同时,在 R语言里用代码实现,让大家明白,其实统计检验真的很简单,就几行代码的事情,而且代码怎么写,也很格式化)
二、参数检验 R语言实现
友情提示,以下案例,均默认随机获得的样本服从正态分布,也满足方差齐性。不要验证我的数据,因为它们经不起验证。真正的去找这些满足以上两个条件的数据,时间花费太多了。本节的主要目的,只是为了让读者更好的理解,这些检验方法,是用在什么地方的,以及怎么理解检验的结果。抱拳!
2.1 单样本 t检验
案例 : 我有点矮,身高只有 1.55米。我想知道,在广大群众之中,我的身高是不是处于一个正常水平,我能说大家的平均身高就是 1.55米吗?于是,我在 1.3米到 2.2米的人中,随机选取 100个人: Height <- sample(seq(1.3,2.2,by=0.1),100,replace=T) 。我对这 100个人的身高进行 t检验:
Tsingle <- t.test(Height , alternative = "greater", mu =1.55 )
P值近乎为 0了,备择假设是真是均值大于 1.55。 So,我,太矮了【在路上我应该只问女生的身高,不问男生的身高才对。把男生的身高加进来,就是自取其辱】。
2.2 独立样本 t检验
案例 :听说南方人普遍较北方人矮,那矮的明显吗?差异真的很大?我要验证一下,选择 100个南方人, 80个北方人(假设在重庆,北方人相对还是太少了),进行我的检验。
South <- sample(seq(1.3,1.9,by=0.1),100,replace=T)
North <- sample(seq(1.3,2.2,by=0.1),80,replace=T)
检验代码如下: IndT <- t.test(South ,North ,paired = F )
嗯,结果 P值远低于 0.05,接收备择假设:均值的真实差异不等于 0.意味着北方人真的比南方人高呀 ~
2.3 配对样本 t检验
案例 : (跟个风 )前段时间做了一个新冠肺炎的课题,患者入院时和出院时均进行了各临床指标的检验,比如 NLR、 CRP、 White Blood Cell等。按理说,其中,多项研究证明, NLR和肺损伤程度是高度正相关的,所以,入院时和出院时的 NLR值,应该不在一个水平。现在,用你的 100个病人,来证明它!
Getin <- sample(seq(3.22,14.9,by=0.1),100,replace=T)
Getout <- sample(seq(1.22,9.9,by=0.1),100,replace=T)
检验代码如下: PairT <- t.test(Getin ,Getout ,paired = T )
P 值远低于 0.05,拒绝原假设,接受备择假设:均值的真实差异不等于 0。说明治疗前后,患者的 NLR指标有明显变化。
2.4方差分析
案例 :还是这批新冠肺炎患者,他们有 NLR、 CRP、 White Blood Cell等指标,还有性别、年龄等基本信息。通过核酸检测,我知道他们的病情是何情况(轻型,重型,危重型)。现在,我要看这些指标在不同病情患者中是否存在差异。此时,我们就可以使用方差分析进行检验。
NLR <- sample(seq(3.22,14.9,by=0.1),100,replace=T)
CRP <- sample(seq(0.06,190,by=0.1),100,replace=T)
Age <- sample(seq(20,70,by=1),100,replace=T)
COVID _Type <- sample(c(1,2,3),100,replace=T) # 1:Mild,2:Moderate,3:Severe
AovData <- data.frame(Type =COVID_Type ,NLR=NLR ,CRP=CRP ,Age =Age )
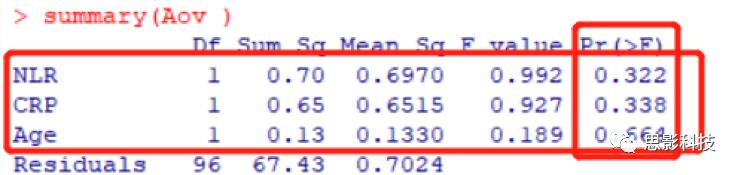
Aov <- aov(Type ~.,data=AovData ) # Type~.是一个公式,意味着我要对 AovData 表格里的所有临床指标与 Type进行方差分析,如果不用 ~.表示的话,就得写成 Type~NLR+CRP+Age。
这里查看方差分析的结果,用 summary(Aov ):
可以看到, 3个指标的 P值均大于 0.05,说明这三个指标在不同的 Type病人下,没有显著差异。
2.5 pearson相关性检验
案例 :长得越好看的人(颜值评分越高 ,10分就是李东旭那样子的),追求者越多。
Face_score <- sample(seq(1,10,by=1),100,replace=T)
Admirers <- sample(seq(1,5,by=1),100,replace=T)
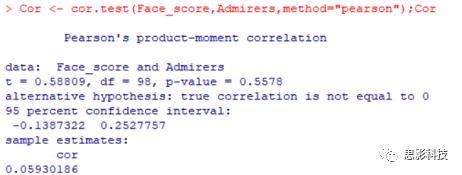
Cor <- cor.test(Face_score,Admirers,method="pearson")
检验结果中, P值大于 0.05,不能拒绝原假设,因此认为,并不是长得越好看的人,追的人就越多【看来我没人追,也不是因为长得不好看呀 ~】( Pearson相关用于双变量正态分布的资料,其相关系数称为积矩相关系数( coefficient of product-moment correlation);当两变量不符合双变量正态分布的假设时,需用 Spearman秩相关来描述变量间的相互变化关系。)
三、非参数检验 R语言实现
本节的数据与第二节完全一致,所以,就省去编案例和随机造数据这两步过程了。
3.1单样本 wilcoxon检验
检验代码: Wilsingle <- wilcox.test(Height)
P值小于 0.05,接收备择假设:位置(中位数)差异不等于 0,说明在非参数检验的情况下,我的身高也还是和锅锅姐姐们有差异的。
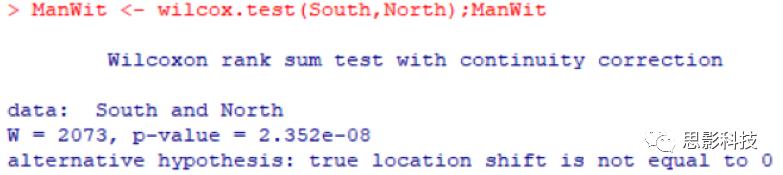
3.2 Mann-Whitney检验
检验代码: ManWit <- wilcox.test(South,North,paired = F)
同上, P值小于 0.05,说明两组数据是有显著性差异的。北方人普遍就是比南方人高鸭 ~
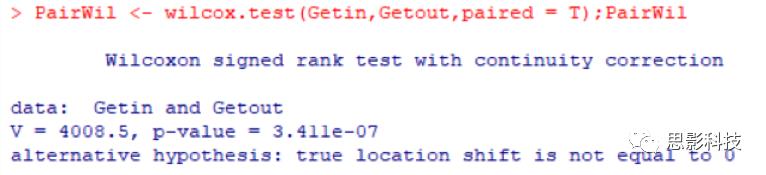
3.3配对样本 wilcoxon检验
检验代码: PairWil <- wilcox.test(Getin,Getout,paired = T)
P值小于 0.05, COVID患者入院时和出院时的 NLR值有显著性差异。
3.4 Kruskal-wallis和置换多元方差分析检验 Kruskal-wallis用于单因素方差分析: KS <- kruskal.test(Type~NLR,data=AovData)
P值大于 0.05,说明 NLR在各组之间没有显著性差异。
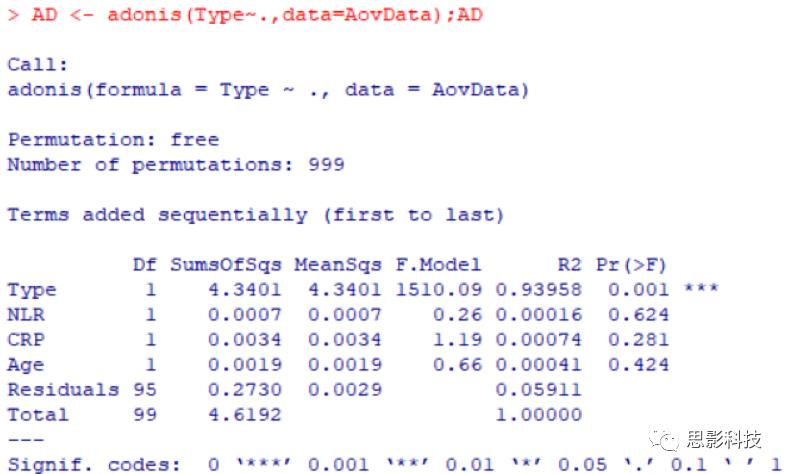
置换多元方差分析用于多因素方差分析: AD <- adonis(Type~.,data=AovData)
可以看到, NLR, CRP和 Age的 P值均大于 0.05,说明他们在各组之间均没有显著性差异。【参数检验方法都做不出来显著,非参数更做不出来了】
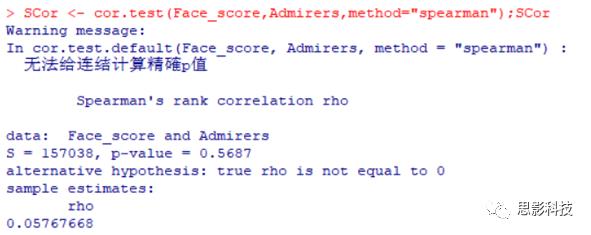
3.5 spearman相关性检验
SCor <- cor.test(Face_score,Admirers,method="spearman")
P值大于 0.05,不能拒绝原假设,所以不能认为长得越好看,追求者越多。
四列联表检验(定性资料) 4.1 pearson卡方检验 适合性检验:
案例 :高中学了孟德尔豌豆杂交实验,二代分离的结果为:黄圆 315、黄皱 101、绿圆 108、绿皱 32,共 556粒。这个结果符合自由组合定律 9:3:3:1吗?
检验数据:
F2split <- c(315,101,108,32)
Ratio <- c(9/16,3/16,3/16,1/16)
Fit <- chisq.test(F2split , p = Ratio )
P值大于 0.05,因此不能拒绝原假设,认为二代分离结果符合自由组合定律。
独立性检验
案例 :大学及研究生阶段,发现班上总是女生入社团很积极,男生很一般。所以,性别和加入社团与否有关系吗?
CHi <- as.table(rbind(c(62, 37), c(48, 23)))
dimnames(CHi ) <- list(gender = c("F", "M"),
party = c("InParty","Notinparty"))
Chiq <- chisq.test(CHi )
检验结果:
P值大于 0.05,说明性别和加不加入社团没关系哦 ~
4.2 Fisher精确检验
Fisher <- rbind(c(28 ,42), c(35, 27))
dimnames(Fisher ) <- list(gender = c("Single", "Mate"),
party = c("Makeup","NoeMakeup"))
检验代码: Fish <- fisher.test(Fisher )
P值大于 0.05,拒绝原假设,接受备择假设:真实比值不等于 1 ,说明化妆对找男朋友还是有用的。 Wu~
4.3 Cochran-Mantel–Haensze卡方检验
案例 :肖战和王一博的男粉和女粉有明显差别不?在不用地区分布咋样(比如在重庆,是不是肖战的粉丝明显更多)?
数据准备(五个城市不同男女喜欢肖战王一博的统计数据):
Fans <- array(c(100,200,28,320,
Response = c('XZ','WYB'),
Penicillin.Level = c('CQ','BJ','SH','GZ','CD')))
检验代码: FanTest <- mantelhaen.test(Fans )
P值小于 0.05,接收备择假设:两个人被喜欢的程度,还是会受到城市的影响的 ~
五、一致性检验 5.1 Kappa一致性检验(定性数据)
一致性检验也分两组比较及多组比较。在 irr包里,有一个 diagnoses数据集,这里面包含了 6个医生多 30个病人的诊断结果。
如果只是对其中两个医生进行一致性检验,采用 Cohen’s Kappa法;如果是多个医生一起比较一致性,采用 Fleiss’s Kappa法。以上两种方法的代码及结果如下:
检验代码: kap2 <- kappa2(dat[,c(1,2)],'unweighted')
P值小于 0.05 ,说明这两个医生的诊断结果具有一致性。
检验代码: Flesi <- kappam.fleiss(dat)
P值为 0, kappa值 0.43,说明这六个医生的评价仍然具有显著的一致性。
5.2 配对 χ2检验 (McNemar检验 )
Performance <- matrix(c(794, 86, 150, 570),
dimnames = list("1st Survey" = c("Approve","Disapprove"),
"2nd Survey" =c("Approve", "Disapprove")))
检验代码: mcnemar.test(Performance )
P值小于 0.05,说明第一次调查和第二次调查的支持者及反对者具有一致性,第一次调查中支持的人,在第二次调查也支持。
5.3 ICC组内相关系数
ICC一般是具体的值,认为大于 0.8,则前后一致性好。没有碰到过像上面一样的检验函数。由于放射组学前后两次勾画 ROI,需要进行提取后特征值的一致性分析,所以,作者自己有写相关的 ICC批量计算代码,如下:
ICC <- function(Data){
if(unique(Data[,1]==unique(Data[,2]))){
ICC <- 1
ICC
}
else{
n <- nrow(Data);k <- ncol(Data)
mean_r <- apply(Data,1,mean)
mean_c <- apply(Data,2,mean)
mean_all <- mean(c(Data[,1],Data[,2]))
l_all <- sum((Data-mean_all)^2)
l_r <- sum((mean_r-mean_all)^2)*k
l_c <- sum((mean_c-mean_all)^2)*n
l_e = l_all-l_r-l_c
v_all = n*k-1
v_r = n-1
v_c = k-1
v_e = v_r*v_c
MSR = l_r/v_r
MSC = l_c/v_c
MSE = l_e/v_e
ICC = (MSR-MSE)/(MSR+(k-1)*MSE+k*(MSC-MSE)/n)
ICC
}
}
ICC1 <- DataFeature;ICC2 <- DataFeature2
ICCvalue <- c()
for(i in 2:ncol(ICC1)){
data1 <- ICC1[,i];data2 <- ICC2[,i]
Data <- data.frame(data1=data1,data2=data2)
Value <- ICC(Data)
ICCvalue <- c(ICCvalue,Value)
}
length(which(ICCvalue>=0.8))# %>% length() # 哪些特征的 ICC系数大于 0.8,则说明这些特征的可重复性好。
总结:
文章涉及到的知识点太多,如果全都清晰的讲,那每个知识点都可以重新写篇新的来说。但是本文已经足够满足基本的统计需要。在这些统计方法中,其实更重要的是对统计思路的理解和严格的统计流程的遵循。其次,本文还未涉及一些在当下使用更为频繁但是难度也更大的统计方法,如协方差分析、混合线性模型等等。建议转发收藏经常对照看看。
七附录
# 随机生成服从均值为 0,方差为 1的 100个正态分布数据
Shp <- shapiro.test(test)
Bar <- bartlett.test(count ~ spray, data = InsectSprays);Bar
Lev <- car::leveneTest(count ~ spray, data = InsectSprays);Lev
Fli <- stats::fligner.test(count ~ spray, data = InsectSprays);Fli
Height <- sample(seq(1.3,2.2,by=0.1),100,replace=T)
Tsingle <- t.test(Height, alternative = "greater", mu =1.55 );Tsingle
Wilsingle <- wilcox.test(Height )
South <- sample(seq(1.3,1.9,by=0.1),100,replace=T)
North <- sample(seq(1.3,2.2,by=0.1),80,replace=T)
IndT <- t.test(South ,North ,paired = F);IndT
ManWit <- wilcox.test(South,North,paired = F);ManWit
Getin <- sample(seq(3.22,14.9,by=0.1),100,replace=T)
Getout <- sample(seq(1.22,9.9,by=0.1),100,replace=T)
PairT <- t.test(Getin ,Getout ,paired = T);PairT
PairWil <- wilcox.test(Getin,Getout,paired = T);PairWil
NLR <- sample(seq(3.22,14.9,by=0.1),100,replace=T)
CRP <- sample(seq(0.06,190,by=0.1),100,replace=T)
Age <- sample(seq(20,70,by=1),100,replace=T)
COVID_Type <- sample(c(1,2,3),100,replace=T)
AovData <- data.frame(Type=COVID_Type,NLR=NLR,CRP=CRP,Age =Age )
Aov <- aov(Type~.,data=AovData )
KS <- kruskal.test(Type~NLR,data=AovData);KS
AD <- adonis(Type~.,data=AovData);AD
Face_score <- sample(seq(1,10,by=1),100,replace=T)
Admirers <- sample(seq(1,5,by=1),100,replace=T)
Cor <- cor.test(Face_score,Admirers,method="pearson");Cor
SCor <- cor.test(Face_score,Admirers,method="spearman");SCor
F2split <- c(315,101,108,32)
Ratio <- c(9/16,3/16,3/16,1/16)
Fit <- chisq.test(F2split , p = Ratio );Fit
Chi <- as.table(rbind(c(62, 37), c(48, 23)))
dimnames(Chi ) <- list(gender = c("F", "M"),
party = c("InParty","NotinParty"))
Chiq <- chisq.test(Chi );Chiq
Fisher<- rbind(c(28 ,42), c(35, 27))
dimnames(Fisher) <- list(gender = c("Single", "Mate"),
party = c("Makeup","NoeMakeup"))
Fish <- fisher.test(Fisher);Fish
Fans<- array(c(100,200,28,320,
Response = c('XZ','WYB'),
Penicillin.Level = c('CQ','BJ','SH','GZ','CD')))
FanTest <- mantelhaen.test(Fans);FanTest
kap2 <- kappa2(dat[,c(1,2)],'unweighted');kap2
Flesi <- kappam.fleiss(diagnoses);Flesi
Performance <- matrix(c(794, 86, 150, 570),
dimnames = list("1st Survey" = c("Approve","Disapprove"),
"2nd Survey" =c("Approve", "Disapprove")))
mcnemar.test(Performance)
本文由思影科技工程师所著,非杨晓飞所著,杨晓飞既不是女生,也不是1米55,长得还满好看的,杨晓飞只是把工程师写的内容登到公众号。另外微信公众号显示的图可能略小,可以点开图片看,如需原始WORD文档,请添加微信号
siyingyxf
或者
18983979082
获取。
觉得有帮助,给个转发,以及右下角点击一下在看, 都是对思影科技莫大的支持。
微信扫码或者长按选择识别关注思影
非常感谢转发支持与推荐
(重庆,8.9-14)
(重庆,7.26-31)
(南京,7.31-8.5)
(南京,6.30-7.5)
以上是关于大话脑影像之:统计学检验方法总结及R语言实现的主要内容,如果未能解决你的问题,请参考以下文章
R语言列联表的统计分析及假设检验
R语言之正态性检验
R语言四格表的统计分析及假设检验
R语言 | 差异显著性检验
R语言之贝叶斯数据分析2
统计 | R语言执行两组间差异分析Wilcox秩和检验