R语言基于Keras的小数据集深度学习图像分类
Posted 拓端数据部落
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言基于Keras的小数据集深度学习图像分类相关的知识,希望对你有一定的参考价值。
原文链接:http://tecdat.cn/?p=6714
必须使用非常少的数据训练图像分类模型是一种常见情况,如果您在专业环境中进行计算机视觉,则在实践中可能会遇到这种情况。“少数”样本可以表示从几百到几万个图像的任何地方。作为一个实际例子,我们将重点放在将图像分类为狗或猫的数据集中,其中包含4,000张猫狗图片(2,000只猫,2,000只狗)。我们将使用2,000张图片进行训练- 1,000张用于验证,1,000张用于测试。
深度学习与小数据问题的相关性
您有时会听到深度学习仅在有大量数据可用时才有效。这部分是有效的:深度学习的一个基本特征是它可以自己在训练数据中找到有趣的特征,而不需要手动特征工程,这只有在有大量训练样例可用时才能实现。对于输入样本非常高维的问题(如图像)尤其如此。
让我们从掌握数据开始吧。
下载数据
使用 Dogs vs. Cats数据集 。
图片是中等分辨率的彩色JPEG。这里有些例子:
该数据集包含25,000张狗和猫的图像(每类12,500张),543 MB 。下载并解压缩后,您将创建一个包含三个子集的新数据集:每个类包含1,000个样本的训练集,每个类500个样本的验证集,以及每个类500个样本的测试集。
以下是执行此操作的代码:
original_dataset_dir < - “〜/ Downloads / kaggle_original_data”base_dir < - “〜/ Downloads / cats_and_dogs_small”dir.create(base_dir)train_dir < - file.path(base_dir,“train”)dir.create(train_dir)validation_dir < - file。path(base_dir,“validation”)使用预训练的convnet
在小图像数据集上深入学习的一种常见且高效的方法是使用预训练网络。一个预训练的网络是一个先前在大型数据集上训练的已保存网络,通常是在大规模图像分类任务上。如果这个原始数据集足够大且足够通用,则预训练网络学习的特征的空间层次结构可以有效地充当视觉世界的通用模型,因此其特征可以证明对许多不同的计算机视觉问题有用,甚至虽然这些新问题可能涉及与原始任务完全不同的类。
有两种方法可以使用预训练网络:特征提取和微调。让我们从特征提取开始。
特征提取
特征提取包括使用先前网络学习的表示来从新样本中提取感兴趣的特征。然后,这些功能将通过一个新的分类器运行,该分类器从头开始训练。
为什么只重用卷积基数?您是否可以重复使用密集连接的分类器?一般来说,应该避免这样做。原因是卷积基础学习的表示可能更通用,因此更具可重用性 。
注意,由特定卷积层提取的表示的一般性(以及因此可重用性)的级别取决于模型中的层的深度。模型中较早出现的图层会提取局部的,高度通用的特征贴图(例如可视边缘,颜色和纹理),而较高层的图层会提取更抽象的概念(例如“猫耳朵”或“狗眼”) 。因此,如果您的新数据集与训练原始模型的数据集有很大不同,那么最好只使用模型的前几层来进行特征提取,而不是使用整个卷积基础。
让我们通过使用在ImageNet上训练的VGG16网络的卷积基础来实现这一点,从猫和狗图像中提取有趣的特征,然后在这些特征之上训练狗与猫的分类器。
让我们实例化VGG16模型。
conv_base < - application_vgg16(weights =“imagenet”,include_top = FALSE,input_shape = c(150,150,3))您将三个参数传递给函数:
weights 指定从中初始化模型的权重检查点。
include_top“密集连接”是指在网络顶部包括(或不包括)密集连接的分类器。默认情况下,此密集连接的分类器对应于ImageNet的1,000个类。因为您打算使用自己的密集连接分类器(只有两个类:cat和dog),所以您不需要包含它。
input_shape是您将提供给网络的图像张量的形状。这个参数纯粹是可选的:如果你不传递它,网络将能够处理任何大小的输入。
它类似于你已经熟悉的简单的网络:
summary(conv_base)Layer (type) Output Shape Param #================================================================input_1 (InputLayer) (None, 150, 150, 3) 0________________________________________________________________block1_conv1 (Convolution2D) (None, 150, 150, 64) 1792________________________________________________________________block1_conv2 (Convolution2D) (None, 150, 150, 64) 36928________________________________________________________________block1_pool (MaxPooling2D) (None, 75, 75, 64) 0________________________________________________________________block2_conv1 (Convolution2D) (None, 75, 75, 128) 73856________________________________________________________________block2_conv2 (Convolution2D) (None, 75, 75, 128) 147584________________________________________________________________block2_pool (MaxPooling2D) (None, 37, 37, 128) 0________________________________________________________________block3_conv1 (Convolution2D) (None, 37, 37, 256) 295168________________________________________________________________block3_conv2 (Convolution2D) (None, 37, 37, 256) 590080________________________________________________________________block3_conv3 (Convolution2D) (None, 37, 37, 256) 590080________________________________________________________________block3_pool (MaxPooling2D) (None, 18, 18, 256) 0________________________________________________________________block4_conv1 (Convolution2D) (None, 18, 18, 512) 1180160________________________________________________________________block4_conv2 (Convolution2D) (None, 18, 18, 512) 2359808________________________________________________________________block4_conv3 (Convolution2D) (None, 18, 18, 512) 2359808________________________________________________________________block4_pool (MaxPooling2D) (None, 9, 9, 512) 0________________________________________________________________block5_conv1 (Convolution2D) (None, 9, 9, 512) 2359808________________________________________________________________block5_conv2 (Convolution2D) (None, 9, 9, 512) 2359808________________________________________________________________block5_conv3 (Convolution2D) (None, 9, 9, 512) 2359808________________________________________________________________block5_pool (MaxPooling2D) (None, 4, 4, 512) 0================================================================Total params: 14,714,688Trainable params: 14,714,688Non-trainable params: 0
此时,有两种方法可以继续:
在数据集上运行卷积基 。
conv_base通过在顶部添加密集层来扩展您拥有的模型() 。
在这篇文章中,我们将详细介绍第二种技术 。请注意, 只有在您可以访问GPU时才应该尝试 。
特征提取
由于模型的行为与图层类似,因此您可以像添加图层一样将模型(如conv_base)添加到顺序模型中。
model < - keras_model_sequential()%>%conv_base%>%layer_flatten()%>%layer_dense( = 256,activation =“relu”)%>%layer_dense(u its = , “sigmoid”)这就是模型现在的样子:
summary(model)Layer (type) Output Shape Param #================================================================vgg16 (Model) (None, 4, 4, 512) 14714688________________________________________________________________flatten_1 (Flatten) (None, 8192) 0________________________________________________________________dense_1 (Dense) (None, 256) 2097408________________________________________________________________dense_2 (Dense) (None, 1) 257================================================================Total params: 16,812,353Trainable params: 16,812,353Non-trainable params: 0
如您所见,VGG16的卷积基数有14,714,688个参数,非常大。
在Keras中, 使用以下freeze_weights()函数冻结网络:
freeze_weights(conv_base)length(model $ trainable_weights)
数据扩充
过度拟合是由于过多的样本需要学习,导致无法训练可以推广到新数据的模型。
在Keras中,这可以通过配置要对由a读取的图像执行的多个随机变换来完成image_data_generator()。例如:
train_datagen = image_data_generator(rescale = 1/255, = 40,width_shift_range = 0.2,height_shift_range = 0.2, = 0.2,zoom_range = 0.2,horizo = TRUE,fill_mode =“nearest”)浏览一下这段代码:
rotation_range 是一个度数(0-180)的值,一个随机旋转图片的范围。
width_shift并且height_shift是在垂直或水平方向上随机平移图片的范围(作为总宽度或高度的一部分)。
shear_range 用于随机应用剪切变换。
zoom_range 用于随机缩放图片内部。
horizontal_flip 用于水平地随机翻转一半图像 - 当没有水平不对称假设时相关(例如,真实世界的图片)。
fill_mode 是用于填充新创建的像素的策略,可以在旋转或宽度/高度偏移后出现。
现在我们可以使用图像数据生成器训练我们的模型:
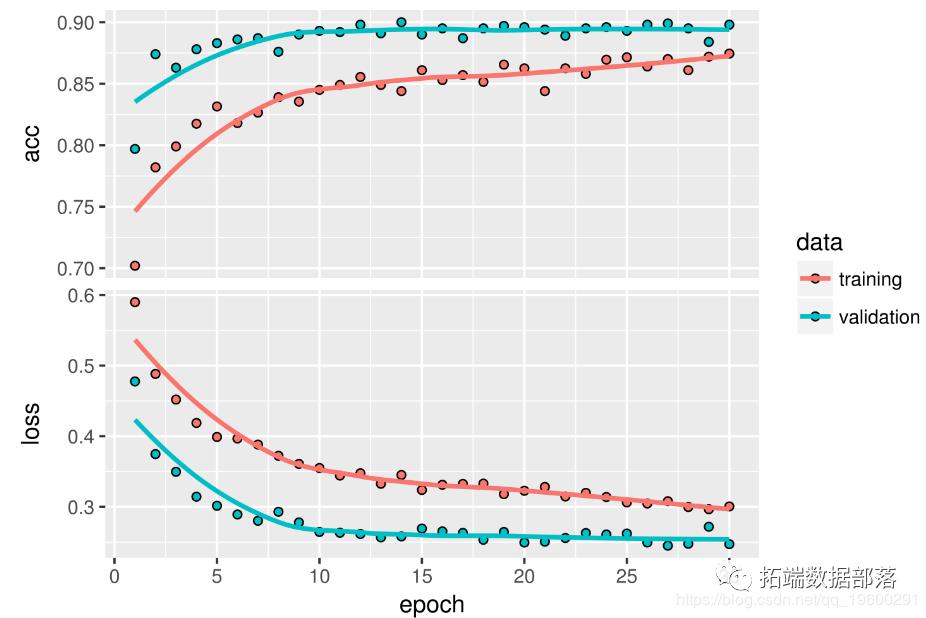
validation_generator < - flow_images_from_directory(validation_dir,test_datagen,target_size = c(150,150),batch_size = 20,class_mode =“binary”)model%>%compile(loss =“binary_crossentropy”,optimizer = optimizer_rmsprop(lr = 2e-5),metrics = c(“accuracy”))history < - model%>%fit_generator(train_generator,steps_per_epoch = 100,让我们绘制结果。准确率达到约90%。
微调
另一种广泛使用的模型重用技术,是对特征提取的补充,是微调 ,微调网络的步骤如下:
在已经训练过的基础网络上添加自定义网络。
冻结基础网络。
训练你添加的部分。
解冻基础网络中的某些层。
联合训练这些层和您添加的部分。
在进行特征提取时,您已经完成了前三个步骤。让我们继续第4步:您将解冻您的内容conv_base,然后冻结其中的各个图层。
现在您可以开始微调网络了。
model%>%compile(lo ropy”,optimizer = opt imizer_rmsprop(lr = 1e-5),metrics = c(“accuracy”))his el%>%fit_generator(train_ g steps_per_epoch = 100,epochs = 100 ,validation_data = validation_genera tor,validation_steps = 50)让我们绘制结果:
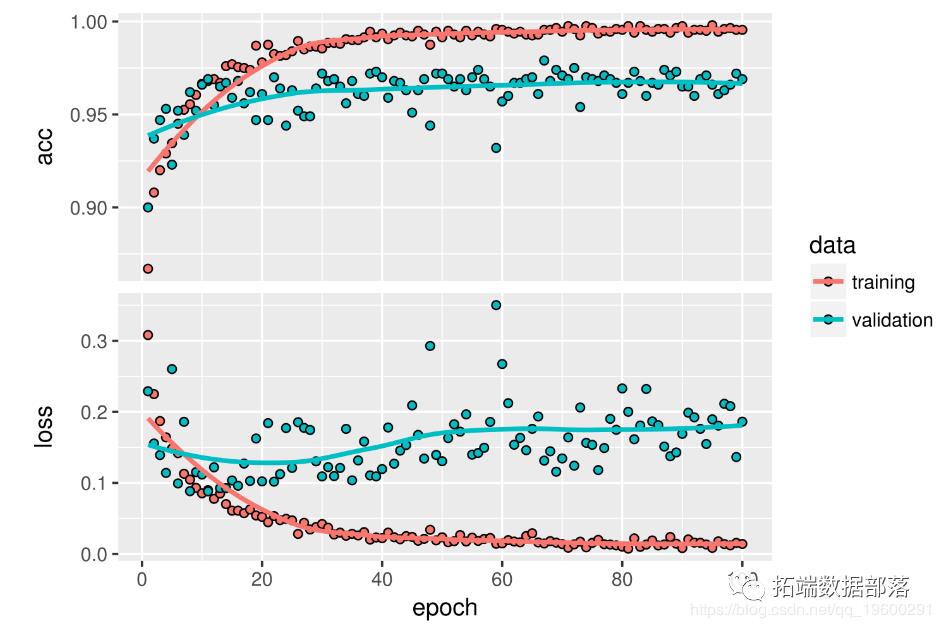
·
你可以看到准确度有6%的绝对提升,从大约90%到高于96%。
您现在可以最终在测试数据上评估此模型:
test_generator < - (test_dir,test_datagen,target_size = c(150,150),batch_size = 20, =“binary”)model%>%evaluate_generator( ,steps = 50)$ loss[1] 0.2158171$ acc[1] 0.965
在这里,您可以获得96.5%的测试精度。
非常感谢您阅读本文,有任何问题请在下面留言!
点击标题查阅往期内容
更多内容,请点击左下角“阅读原文”查看


![]()
案例精选、技术干货 第一时间与您分享
长按二维码加关注
更多内容,请点击左下角“阅读原文”查看
以上是关于R语言基于Keras的小数据集深度学习图像分类的主要内容,如果未能解决你的问题,请参考以下文章