软件R语言入门之向量
Posted 统计学爱好者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了软件R语言入门之向量相关的知识,希望对你有一定的参考价值。
“ R语言入门开篇,向量(vector)相关知识的介绍”
R语言是一款优秀统计学编程语言,本文介绍R语言的几个重要命令,以及R语言中非常重要的一种数据结构-向量(Vector)的相关知识。
本文使用的开发工具为RGui,以">"开头的语句表示输入的命令,没有">"开头的语句是上一个语句的输出结果。
01
—
常用命令
help()
help()为帮助命令,在()中输入求助的内容并执行(按下回车键),返回网页帮助文档
> help(help)以上命令返回如下网页文档
ls()
ls()命令显示workspace中存储的对象名称
> ls()character(0)> x<-1> ls()[1] "x"> y<-1> ls()[1] "x" "y"
rm()
rm()为删除命令,在()中输入workspace中存储的对象名称并执行,将删除workspace中该对象
> ls()[1] "x" "y"> rm(x)> ls()[1] "y"
rm(list=ls())命令能够清空workspace中所有对象
> ls()[1] "c" "e" "v" "x" "y" "z"> rm(list=ls())> ls()character(0)
02
—
向量(vector)
数据对象的简单说明
R语言中包含几种基本数据类型:
数值型(numeric)
字符型(character)
逻辑型(logical)
复数型(complex)
raw型
缺失型(missing value)
将上述基本数据以一定的规则组织起来形成的数据结构:
向量(vector)
矩阵(matrix)
数组(array)
因子(factor)
列表(list)
数据帧(data frame)
向量的赋值
1)c()函数
c()函数可将()中包含的向量、数字等元素顺序连接成为一个向量
> x<-c(1,2,3,4,5)> x[1] 1 2 3 4 5> y<-c(c(1,2,3),4,5)> y[1] 1 2 3 4 5
2)向量的赋值表达式
可使用<-或=或->或assign函数赋值,前两者用于向左赋值
> x<-c(0,0,0,0,0)> c(1,1,1,1,1)->y> assign("z",c(2,2,2,2,2))> n=c(3,3,3,3,3)> h<-c(x,y,z)> x[1] 0 0 0 0 0> y[1] 1 1 1 1 1> z[1] 2 2 2 2 2> n[1] 3 3 3 3 3> h[1] 0 0 0 0 0 1 1 1 1 1 2 2 2 2 2
向量的算术运算
1)规则
向量之间进行算术运算时,向量中的每一个元素将进行相同的运算操作
> x[1] 1 1 1 1 1> y[1] 1 2 3 4 5> x+y[1] 2 3 4 5 6> x-y[1] 0 -1 -2 -3 -4> x+2*y[1] 3 5 7 9 11
当两个向量的长度不相同时,较短的向量以自身元素循环的形式进行补充,直至与较长的向量中元素个数一致。
> x[1] 1 -1> y[1] 0 0 0 0 0 0 0 0> x+y[1] 1 -1 1 -1 1 -1 1 -1
2)算术运算符
+ 加
- 减
* 乘
/ 除
^ 乘方
3)函数
sin() 求正弦值
cos() 求余弦值
tan() 求正切值
log() 求底数为10的对数值
exp() 求底数为e的指数
sqrt() 求平方根
sqrt(-2) 返回NaN
sqrt(-2+0i) 返回复数
> c<-sqrt(-2)Warning message:In sqrt(-2) : NaNs produced> c[1] NaN> x<-sqrt(-2+0i)> x[1] 0+1.414214i
max() 求最大值
min() 求最小值
median() 求中位数
range() 求最大值和最小值,相当于c(min(),max())
length() 求向量中元素个数
sum() 求向量中所有元素之和
prod() 求向量中所有元素之积
mean() 求样本均值
var() 求样本方差,var(x)等价于sum((x-mean(x))^2)/(length(x)-1)
sd() 求样本标准差
quantile() 求百分位数
cov(x, y) 求向量x和y的协方差
cor(x,y) 求向量x和y的相关系数
sort() 返回递增排序后的向量
规则序列的生成
1)":"运算符
生成间隔为1的递增或递减数列
> x<-c(1:10)> x[1] 1 2 3 4 5 6 7 8 9 10> y<-c(10:1)> y[1] 10 9 8 7 6 5 4 3 2 1
2)seq()函数
seq()函数生成规则序列
seq(from=1, to=1, by=(to-from)/(length.out-1), length.out=NULL, along.with=NULL, ...)
---by 表示步长或间隔
> seq(1,10)[1] 1 2 3 4 5 6 7 8 9 10> seq(from=1,to=10,by=2)[1] 1 3 5 7 9
3)rep()函数
rep()函数生成重复序列,设置参数times或each可实现不同的重复形式
> rep(1,5)[1] 1 1 1 1 1> rep(c(1,2,3),times=2)[1] 1 2 3 1 2 3> rep(c(1,2,3),each=2)[1] 1 1 2 2 3 3
逻辑向量
与上述介绍的数值型向量类似,R语言可以定义逻辑向量。逻辑向量的元素可以是TRUE、FALSE、NA(无效值)
1)赋值
> l<-c(TRUE,FALSE,NA,NA,FALSE)> l[1] TRUE FALSE NA NA FALSE
条件表达式可生成逻辑向量
> x<-c(1:10)> x_bigger_than_5<-x>5> x[1] 1 2 3 4 5 6 7 8 9 10> x_bigger_than_5[1] FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE TRUE TRUE
2)条件运算符
> 大于
< 小于
== 等于
>= 大于等于
<= 小于等于
!= 不等于
& 且
| 或
!非
> x1[1] 0 1> !x1[1] TRUE FALSE> x1[1] 0 1> x2[1] 1 0> x1&x2[1] FALSE FALSE> x1|x2[1] TRUE TRUE
缺失值
当元素是无效值或缺失值的时候,元素被赋予NA值(not avaliable的缩写)。一般情况下,作用于NA值的操作将得到NA值。
> x[1] 1 2 3 NA> x+1[1] 2 3 4 NA
is.na(x)函数逐个判断向量x中的元素是否为NA值
> x<-c(1,2,3,NA,5,NA)> is.na(x)[1] FALSE FALSE FALSE TRUE FALSE TRUE
R语言中还有第二类缺失值,即NaN(Not a Numbe的缩写)。is.na()函数能够不加区别地识别NA值和NaN值,is.nan()函数仅识别NaN值。
> x<-c(1,2,NaN,NA,3)> x[1] 1 2 NaN NA 3> is.na(x)[1] FALSE FALSE TRUE TRUE FALSE> is.nan(x)[1] FALSE FALSE TRUE FALSE FALSE
字符向量
字符型数据即包含在单引号或双引号中的一串字符
1)赋值
> x<-c("x","y","How","Jun","R")> x[1] "x" "y" "How" "Jun" "R"
2)转义字符
在字符型数据中,称为转义字符,使用?Quotes命令可查看所有转义字符。
3)paste()函数
paste()函数能够逐个连接两个或多个字符向量中每一个元素
paste(..., sep="", collapse = NULL)
---... 一个或多个R对象,被转换为字符串
---sep 分隔符
> c<-paste(1:5,"kg",sep="")> c[1] "1kg" "2kg" "3kg" "4kg" "5kg"> x<-paste("Jun",1:5,sep="-")> x[1] "Jun-1" "Jun-2" "Jun-3" "Jun-4" "Jun-5"> x<-paste(2020,"6",1:5,sep="-")> x[1] "2020-6-1" "2020-6-2" "2020-6-3" "2020-6-4" "2020-6-5"
索引向量
向量名后加中括号,并在中括号中填入索引向量,可获得原向量的子集。
创建向量子集的表达式:vector[index_vector]
索引向量分为如下四种类型:
1)逻辑索引向量
逻辑索引向量使用逻辑值TRUE和FALSE进行索引,遇到TRUE值时取出作为子集的元素。当逻辑索引向量和原向量长度不一时,索引向量或循环补充或截断。
> x<-c(1:5)> x[1] 1 2 3 4 5> x[x>2][1] 3 4 5> index_x<-c(TRUE,FALSE)> x[index_x][1] 1 3 5> (x+2)[x>2&x<5][1] 5 6
2)正整数索引向量
正整数索引向量表示创建子集时取出该位置上的元素,正整数索引向量中元素的取值范围是{1,2,3,4,length(x)},R语言中第一个元素的位置为1。
> x<-c(1:10)> x[1] 1 2 3 4 5 6 7 8 9 10> x[5][1] 5> x[4:8][1] 4 5 6 7 8> x[rep(c(3,5),times=3)][1] 3 5 3 5 3 5
3)负整数索引向量
负整数索引向量中表示排除该元素的意思,即在创建子集时不选择负整数的绝对值位置上的元素。
> x[1] 1 2 3 4 5 6 7 8 9 10> x[-5][1] 1 2 3 4 6 7 8 9 10> x[-(2:6)][1] 1 7 8 9 10
4)字符索引向量
当向量中的元素具有名称时,可使用名称进行索引。names()函数可以为向量中的元素添加名称,名称与数字索引相比更容易记忆。
x<-c(1:3)names(x)<-c("apple","cat","fish")x["fish"]fish3xapple cat fish1 2 3
索引赋值操作:
> x<-c(-5:5)> x[1] -5 -4 -3 -2 -1 0 1 2 3 4 5> x[x<0]<--x[x<0]> x[1] 5 4 3 2 1 0 1 2 3 4 5
03
—
描述性统计实践
使用某班级的身高数据作为练习的数据集,对数据集进行描述性统计。
1)输入数据:
> s<-c(176,170,173,179,170,163,168,167,178,173,172,169,178,182,165,172,174,170,166,167,172,164,172,163,176,163,170,174,174,173,169,165,170,172,172,159,163,155,154,156,158,161,162,165,162,163,158,160,161,162,159,156,156,162,156,157,166,155,156,158,157,162,162,155,157,156,157,157)> s[] 176 170 173 179 170 163 168 167 178 173 172 169 178 182 165 172 174 170 166[] 167 172 164 172 163 176 163 170 174 174 173 169 165 170 172 172 159 163 155[] 154 156 158 161 162 165 162 163 158 160 161 162 159 156 156 162 156 157 166[] 155 156 158 157 162 162 155 157 156 157 157
2)数值描述性度量
计算数据集的样本容量、平均值、极差、样本方差、样本标准差、最小值、下四分位数、中位数、上四分位数、最大值
mean_s<-mean(s)var_s<-var(s)sd_s<-sd(s)len_s<-length(s)min_s<-min(s)Q1<-quantile(s,0.25)median_s<-median(s)Q3<-quantile(s,0.75)max_s<-max(s)range_s<-max_s-min_sresult_s<-c(len_s,mean_s,range_s,var_s,sd_s,min_s,Q1,median_s,Q3,max_s)names(result_s)<-c("len","mean","range","var","sd","min","Q1","median","Q3","max")result_slen mean range var sd min Q168.000000 165.058824 28.000000 52.951712 7.276793 154.000000 158.000000median Q3 max163.500000 172.000000 182.000000
summary()函数能够一次性计算出最小值、下四分位数、中位数、样本均值、上四分位数、最大值;
fivenum()函数能够一次性计算出最小值、下四分位数、中位数、上四分位数、最大值。
> summary(s)Min. 1st Qu. Median Mean 3rd Qu. Max.154.0 158.0 163.5 165.1 172.0 182.0> fivenum(s)[1] 154.0 158.0 163.5 172.0 182.0
3)直方图和箱线图
hist(s,main="",col="pink",xlab="height (cm)",breaks=8)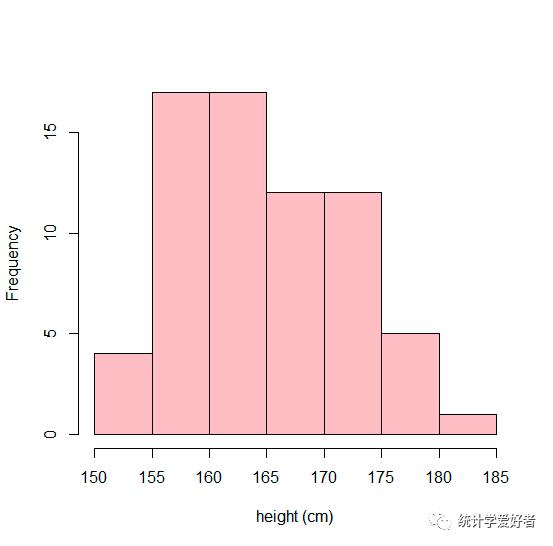
boxplot(s,col="pink") 4)判断异常值
z得分判据:abs(z)>3
s[abs((s-mean_s)/sd_s)>3]numeric(0)
盒子图判据:>Q3+3*(Q3-Q1) or <Q1-3*(Q3-Q1)
s[(s>Q3+3*(Q3-Q1))|(s<Q1-3*(Q3-Q1))]numeric(0)
5)判断数据的正态性
判据1:四分位间距与标准差之比IQR/s≈1.3时,数据近似正态
(Q3-Q1)/sd_s75%1.923925
判据2:正态概率图
qqnorm(s)qqline(s,col=2,lwd=2)
以上是关于软件R语言入门之向量的主要内容,如果未能解决你的问题,请参考以下文章