基于R语言PredictABEL包对Logistic回归模型外部验证
Posted 临床研究与医学统计
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于R语言PredictABEL包对Logistic回归模型外部验证相关的知识,希望对你有一定的参考价值。
1. 背景知识
Logistic回归可以用于建立二分类结局变量的临床预测模型,在医学研究中可用于预测如有效/无效、发生/未发生、复发/未复发等二值化的临床事件。预测模型有优劣之分,好的模型不仅可以较准确的预测终点事件发生概率(校准度好),也可以很好地区分数据集中发生终点事件概率不同的对象(区分度好),还可以从中发现某种因素对终点事件可能的影响(独立风险因素或保护因素)。因此如何判断并验证模型的优劣就显得尤为重要。有关模型优劣的评估指标我们前文已经述及,本文主要介绍Logistic回归模型的外验证问题。
模型验证可采取Out time validation,比方说使用2005-2010年的样本建模后,在2010-2015年的样本中对模型进行验证,这样可以评价模型随着时间推移,预测是否仍然准确;可采取Across modeling techniques,即对于某个数据集,既可以采用逻辑回归建模,也可以使用判别分析、决策树、支持向量机等方式进行建模,从中选择在testing data中表现最好的模型。无论使用何种手段,使用不同于建模时所用的数据集对模型进行外部验证都是非常重要的一环。
建模时,通常会先样本数据集中抽取部分样本用于建模,该部分样本称为training set。建模完成后对模型进行验证时,先使用数据集中的保留样本进行模型的初步评价(internal validation),这部分样本称为testing set。在单个数据集中表现良好的模型在其他数据集中的表现不一定令人满意,因此还需要在全新的数据集中对模型进行外部验证,这个数据集称为validation set。
2. 校准度评价
下面我们使用ResourceSelection包中的hoslem.test()来进行Hosmer-Lemeshow拟合优度检验,通常用来评价Logistic模型的校准度。首先加载所需r包:
#install.packages("ResourceSelection")
library(ResourceSelection)一、建立Logistic回归模型 我们模拟一个数据集(training set)用于建模,这里将该数据集全部样本拿来建模,也可以抽取部分样本建模,剩余样本即testing set用于对模型进行内部验证:
set.seed(123)
n <- 100
x <- rnorm(n)
xb <- x
pr <- exp(xb)/(1+exp(xb))#根据逻辑回归生成一个0-1的概率
y <- 1*(runif(n) < pr)#根据发生概率pr确定单个病人事件是否发生,pr越大,y=1的概率越大,该样本发生终点事件的概率越大
intern.data <- data.frame(x=x,y=y)
mod <- glm(y~x,intern.data,family=binomial)#生成模型mod对模型进行Hosmer-Lemeshow test,该检验将数据划分为一定的组数g,此处参数g的含义我们在前述章节阐述校准度概念时已作出解释。假设我们预测100个人的结局发生概率,不是指我们真用模型预测出来有病/无病,模型只给我们有病的概率,根据概率大于某个截断值(比如说0.5)来判断有病/无病。100个人,我们最终通过模型得到了100个概率,也就是100个0-1之间的数,我们将这100个数,按照从小到大排列,再依次将这100个人分成10组,每组10个人,实际的概率其实就是这10个人中发生疾病的比例,预测的概率就是每组预测得到的10个比例的平均值,然后比较这两个数,一个作为横坐标,一个作为纵坐标,就得到了一致性曲线图(Calibration Plot),也可计算这个图的95%区间范围。在Logistic回归模型中,校准度也可以通过拟合优度检验(Hosmer-Lemeshow goodness-of-fit test)来度量。
hl <- hoslem.test(mod$y, fitted(mod), g=10)
#第一个参数为目标事件是否真实发生,
#第二个参数为根据变量x预测的事件发生概率,
#第三个参数为分组参数g
#在Hosmer-Lemeshow检验中,计算拟合优度统计量,若模型拟合良好,该统计量则应服
#从自由度为g-2的卡方分布。若假设检验的P值<检验水准α,则提示模型的拟合不佳。
#输出Hosmer-Lemeshow test的结果
hl## Hosmer and Lemeshow goodness of fit (GOF) test
## data: mod$y, fitted(mod)
## X-squared = 6.4551, df = 8, p-value = 0.5964P值为0.5964,尚不能认为该模型拟合不良。
cbind(hl$observed,hl$expected)## y0 y1 yhat0 yhat1
## [0.111,0.298] 7 3 7.692708 2.307292
## (0.298,0.396] 8 2 6.491825 3.508175
## (0.396,0.454] 5 5 5.764301 4.235699
## (0.454,0.494] 6 4 5.243437 4.756563
## (0.494,0.564] 7 3 4.739571 5.260429
## (0.564,0.624] 4 6 4.077834 5.922166
## (0.624,0.669] 2 8 3.532070 6.467930
## (0.669,0.744] 2 8 2.910314 7.089686
## (0.744,0.809] 1 9 2.213029 7.786971
## (0.809,0.914] 2 8 1.334912 8.665088#生成Hosmer-Lemeshow检验列联表,
#y0代表未发生事件的次数,
#y1代表发生事件的次数,
#yhat0代表模型预测事件未发生的概率,
#yhat1代表模型预测事件发生概率二、用同样的方法模拟生成的外部数据集,对建好的模型进行外部验证:
set.seed(123)
n.e <- 150#.e代表external
x.e <- rnorm(n.e)#自变量x
xb.e <- x.e
pr.e <- exp(xb.e)/(1+exp(xb.e))#pr.e为根据logistic回归模拟的事件发生概率
y.e <- 1*(runif(n.e) < pr.e)#y为事件实际是否发生,0为没有发生,1为发生
exter.data <- data.frame(x=x.e,y=y.e)
#模拟好的外部数据集
#用内部数据生成的模型预测外部数据的事件发生概率
pr.e <- predict(mod,exter.data,type = c("response"))
#使用建好模型mod预测新数据集得到的预测概率,
#第一个参数为模型对象glm,
#第二个参数为要验证的数据集
hl.e <- hoslem.test(y.e,pr.e, g=10)
hl.e##
## Hosmer and Lemeshow goodness of fit (GOF) test
##
## data: y.e, pr.e
## X-squared = 10.313, df = 8, p-value = 0.2437P=0.2437>0.05,尚不能认为模型拟合不良,提示模型在新数据集中表现也较好。若P<0.05,则说明模型拟合不良。
三、Hosmer-Lemeshow检验统计量的计算原理如下:计算模型预测的概率,根据预测概率从大到小将数据分为10组,即上述函数中的参数g。
pihat <- mod$fitted
pihatcat <- cut(pihat, breaks=c(0,quantile(pihat, probs=seq(0.1,0.9,0.1)),1), labels=FALSE)然后计算Hosmer-Lemeshow检验统计量
meanprobs <- array(0, dim=c(10,2))
#建立一个10行2列的矩阵用于存放事件发生和未发生的平均概率值
expevents <- array(0, dim=c(10,2))
#建立一个10行2列的矩阵用于存放根据概率值计算的事件发生数和未发生数
obsevents <- array(0, dim=c(10,2))
#建立一个10行2列的矩阵用于存放事件的实际发生数和未发生数
for (i in 1:10) {
meanprobs[i,1] <- mean(pihat[pihatcat==i])#计算每组事件发生的平均概率
expevents[i,1] <- sum(pihatcat==i)*meanprobs[i,1]#预测事件数=组内样本个数*平均概率
obsevents[i,1] <- sum(y[pihatcat==i])#实际事件数
#同样的方法计算预测事件未发生数和实际事件未发生数
meanprobs[i,2] <- mean(1-pihat[pihatcat==i])
expevents[i,2] <- sum(pihatcat==i)*meanprobs[i,2]
obsevents[i,2] <- sum(1-y[pihatcat==i])
}计算 Hosmer-Lemeshow 检验统计量。已经证明了若模型拟合良好,该统计量则应服从自由度为g-2的卡方分布。无效假设为:Hosmer-Lemeshow 检验统计量服从自由度为g-2的卡方分布。备择假设为:Hosmer-Lemeshow。检验统计量不服从自由度为g-2的卡方分布。检验水准α=0.05
hosmerlemeshow <- sum((obsevents-expevents)^2 / expevents)
hosmerlemeshow## [1] 6.455077计算得出的统计量同上述函数计算的结果一致
四、使用校正曲线图直观评价模型
#install.packages("PredictABEL")
library(PredictABEL)#使用plotCalibration绘制校正曲线
#参数说明:data为要验证的数据集,
#cOutcome指定结局变量为哪一列,
#predRisk为模型预测的发生概率可以通过predict()函数计算得出,
#groups为组数,
#rangeaxis为坐标轴的范围。
#现在在外部数据中进行校正图绘制
plotCalibration(data=exter.data,
cOutcome=2,
predRisk=pr.e,
groups=10,
rangeaxis=c(0,1))## $Table_HLtest
## total meanpred meanobs predicted observed
## [0.111,0.259) 15 0.199 0.333 2.99 5
## [0.259,0.372) 15 0.306 0.333 4.59 5
## [0.372,0.426) 15 0.393 0.333 5.90 5
## [0.426,0.477) 15 0.449 0.267 6.73 4
## [0.477,0.536) 15 0.499 0.400 7.49 6
## [0.536,0.593) 15 0.562 0.467 8.44 7
## [0.593,0.655) 15 0.624 0.533 9.36 8
## [0.655,0.725) 15 0.685 0.733 10.28 11
## [0.725,0.808) 15 0.764 0.600 11.46 9
## [0.808,0.914] 15 0.866 0.733 12.99 11
##
## $Chi_square
## [1] 10.329
##
## $df
## [1] 8
##
## $p_value
## [1] 0.2427校正图的横轴为预测的风险率,纵轴为实际风险率,每个点代表一个组,其基本思想同Hosmer-Lemeshow检验一致
仅仅评价模型的校准度还不够。假设某项手术后病人的短期死亡率为0.1%,现在有这样一个糟糕的模型,无论病人的健康状况如何、是否吸烟、是否有糖尿病,该模型预测的所有病人死亡率均为1%,最后术后1000例病人中有1例短期死亡。尽管模型的预测与事实相符(均为0.1%的短期死亡率)即拟合优度较高,但这个模型并没有将死亡风险高的病人同死亡风险低的病人区分开来,即模型的区分度不够,因此我们需要评价模型的区分度(即模型将短期死亡率高的患者同短期死亡率低的患者区分开的能力)进一步对模型进行外部验证。。
3. 区分度评价
一、使用上文拟合好的Logistic回归模型绘制ROC曲线
#提取模型预测的概率值
pr <- predict(mod,type=c("response"))
#install.packages("pROC")
library(pROC)#使用roc函数,方程左侧为实际事件发生与否,右侧为模型预测的事件发生率
roccurve <- roc(y ~ pr)#绘制ROC曲线
plot.roc(roccurve,xlim = c(1,0),ylim=c(0,1))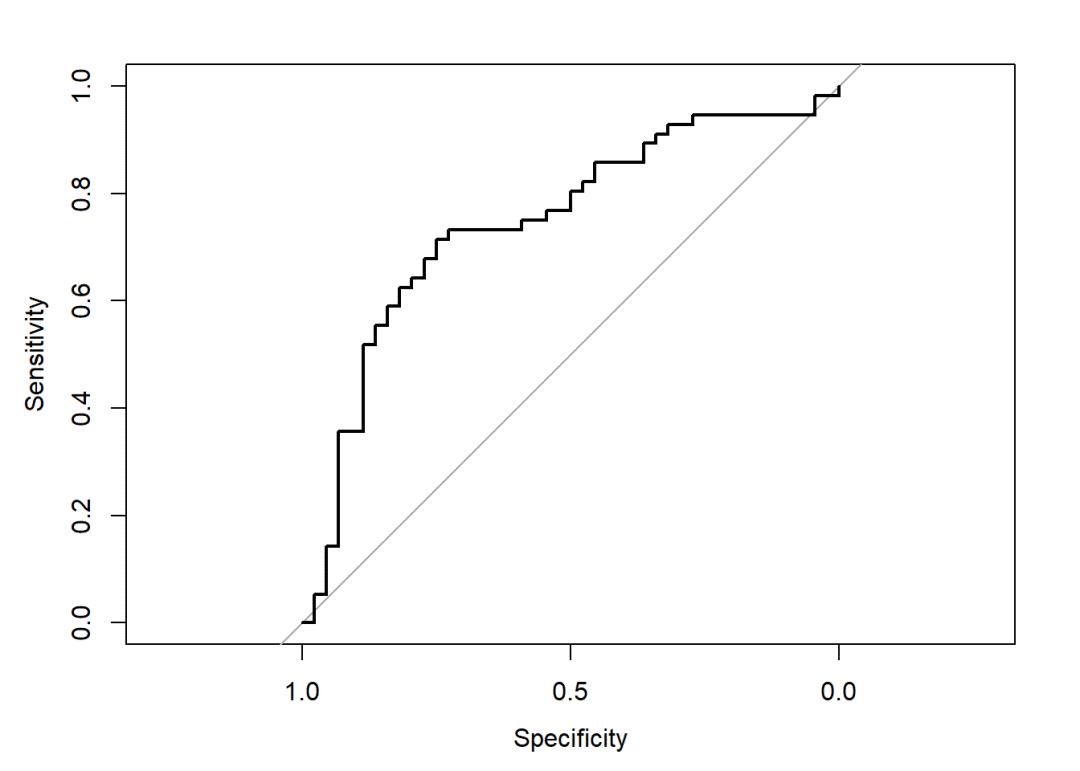
#获取ROC曲线的AUC值
auc(roccurve)## Area under the curve: 0.7455在intern.data中,模型的AUC为0.7455
二、接下来验证模型在外部数据集中的区分度
pr.e <- predict(mod,newdata = exter.data, type=c("response"))
roccurve <- roc(y.e ~ pr.e)
#绘制ROC曲线
plot.roc(roccurve)#获取ROC曲线的AUC值
auc(roccurve)## Area under the curve: 0.6723可见,模型在外部数据集中进行验证,AUC=0.6723,模型在外部数据集验证中区分度较好。
4. 总结
以上我们总结了对于Logistic回归模型进行外部验证的方法,包括校准度评估和区分度评估。
5. 参考文献
[1]. https://cran.r-project.org/web/packages/ResourceSelection/index.html
[2]. https://cran.r-project.org/web/packages/PredictABEL/index.html
[3]. Xavier Robin, Natacha Turck, Alexandre Hainard, Natalia Tiberti, Frédérique Lisacek, Jean-Charles Sanchez and Markus Müller (2011). “pROC: an open-source package for R and S+ to analyze and compare ROC curves”. BMC Bioinformatics, 12, p. 77. DOI: 10.1186/1471-2105-12-77
作者简介:王子威,海军军医大学附属长海医院泌尿外科研究生在读,R语言爱好者。
*扫描下图二维码或点击“阅读原文”查看周老师全部课程
以上是关于基于R语言PredictABEL包对Logistic回归模型外部验证的主要内容,如果未能解决你的问题,请参考以下文章
使用 R 中 predictABEL 包中的 plotCalibration() 的问题
R语言dplyr包对数据进行超前或者之后处理(leadlag)实战
R语言使用caret包对GBM模型自定义参数调优:自定义参数优化网格
R语言使用DALEX包对h2o包构建的机器学习模型进行解释分析:总结及实战
R语言使用caret包对GBM模型进行参数调优实战:Model Training and Parameter Tuning