K均值算法R语言代码
Posted 生信交流平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了K均值算法R语言代码相关的知识,希望对你有一定的参考价值。
今天给大家简单的介绍经典的聚类学习算法,K均值算法。
K均值算法的R语言代码
# 加载R包
library(tidyverse) # data manipulation
library(cluster) # clustering algorithms
library(factoextra) # clustering algorithms & visualization
# 数据准备
df <- USArrests
# 数据缺失值处理
df <- na.omit(df) # 删除含有缺失值的样本
# 数据标准化处理
df <- scale(df)
head(df)
# 基于距离度量的聚类学习
distance <- get_dist(df)
fviz_dist(distance, gradient = list(low = "#00AFBB", mid = "white", high = "#FC4E07"))
# K均值算法
k2 <- kmeans(df, centers = 2, nstart = 25)
str(k2)
k2
fviz_cluster(k2, data = df)
df %>%
as_tibble() %>%
mutate(cluster = k2$cluster,
state = row.names(USArrests)) %>%
ggplot(aes(UrbanPop, Murder, color = factor(cluster), label = state)) +
geom_text()
# 不同的聚类数目对比分析
k3 <- kmeans(df, centers = 3, nstart = 25)
k4 <- kmeans(df, centers = 4, nstart = 25)
k5 <- kmeans(df, centers = 5, nstart = 25)
# plots to compare
p1 <- fviz_cluster(k2, geom = "point", data = df) + ggtitle("k = 2")
p2 <- fviz_cluster(k3, geom = "point", data = df) + ggtitle("k = 3")
p3 <- fviz_cluster(k4, geom = "point", data = df) + ggtitle("k = 4")
p4 <- fviz_cluster(k5, geom = "point", data = df) + ggtitle("k = 5")
library(gridExtra)
grid.arrange(p1, p2, p3, p4, nrow = 2)
# 最佳的K数量确定
# 方法1 Elbow Method
set.seed(123)
# function to compute total within-cluster sum of square
wss <- function(k) {
kmeans(df, k, nstart = 10 )$tot.withinss
}
# Compute and plot wss for k = 1 to k = 15
k.values <- 1:15
# extract wss for 2-15 clusters
wss_values <- map_dbl(k.values, wss)
plot(k.values, wss_values,
type="b", pch = 19, frame = FALSE,
xlab="Number of clusters K",
ylab="Total within-clusters sum of squares")
set.seed(123)
fviz_nbclust(df, kmeans, method = "wss")
# 方法2 Average Silhouette Method
# function to compute average silhouette for k clusters
avg_sil <- function(k) {
km.res <- kmeans(df, centers = k, nstart = 25)
ss <- silhouette(km.res$cluster, dist(df))
mean(ss[, 3])
}
# Compute and plot wss for k = 2 to k = 15
k.values <- 2:15
# extract avg silhouette for 2-15 clusters
avg_sil_values <- map_dbl(k.values, avg_sil)
plot(k.values, avg_sil_values,
type = "b", pch = 19, frame = FALSE,
xlab = "Number of clusters K",
ylab = "Average Silhouettes")
fviz_nbclust(df, kmeans, method = "silhouette")
# 方法3:Gap Statistic Method
# compute gap statistic
set.seed(123)
gap_stat <- clusGap(df, FUN = kmeans, nstart = 25,
K.max = 10, B = 50)
# Print the result
print(gap_stat, method = "firstmax")
fviz_gap_stat(gap_stat)
# 选择最佳K值后重新实施K均值算法
# Compute k-means clustering with k = 4
set.seed(123)
final <- kmeans(df, 4, nstart = 25)
print(final)
# 聚类学习的可视化效果
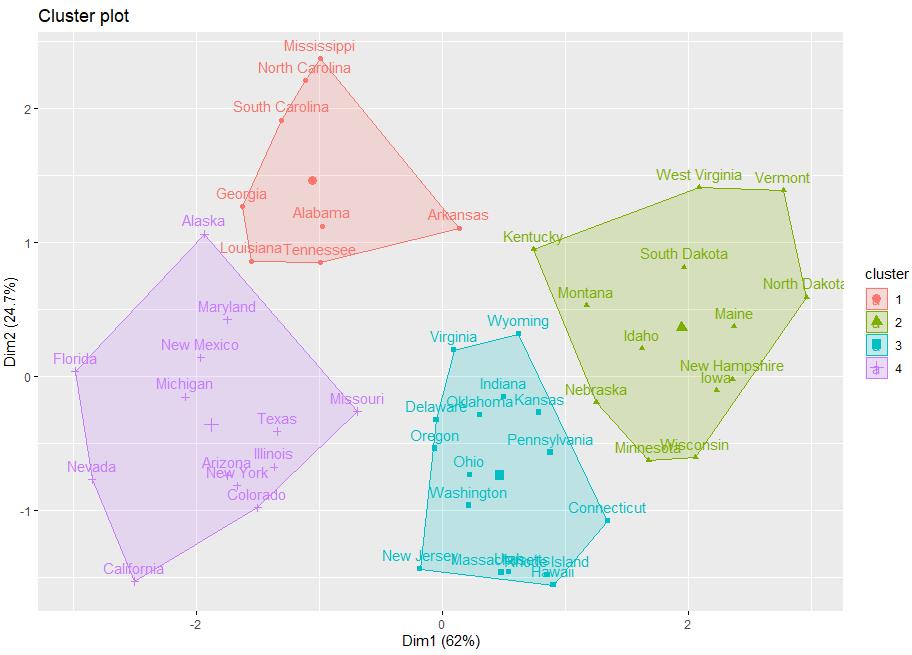
fviz_cluster(final, data = df)
# 聚类的中心点表示
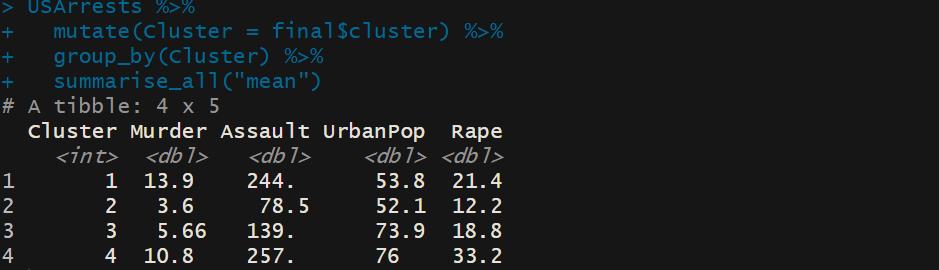
USArrests %>%
mutate(Cluster = final$cluster) %>%
group_by(Cluster) %>%
summarise_all("mean")
# 参考资料:
# https://uc-r.github.io/kmeans_clustering
最佳K=4后,重新执行K均值算法,可视化效果如下图所示。
各个聚类的中心点坐标结果。
关于这段代码有什么问题或者想法,请阅读参考资料,或者下方留言。

独阅乐不如众阅乐
以上是关于K均值算法R语言代码的主要内容,如果未能解决你的问题,请参考以下文章