自助法(bootstrap)在统计检验中的应用及R语言实现过程
Posted R语言统计与绘图
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自助法(bootstrap)在统计检验中的应用及R语言实现过程相关的知识,希望对你有一定的参考价值。
Bootstrap(自助法、自举法)是非参数统计中一种重要的估计统计量方差,进而进行区间估计的统计方法。
Bootstrap通过对给定数据集进行有放回的重抽样以创建多个模拟数据集,生成一系列待检验统计量的经验分布,可以计算标准误差、构建置信区间并对多种类型的样本统计信息进行假设检验。
Bootstrap无需假设一个特定的理论分布,便可生成统计量的置信区间并能检验统计假设,更易于理解以及适用于更多条件,因此常作为传统假设检验的替代方法。
1. Bootstrap在统计检验中的应用
接下来概述bootstrap的基本原理,比较其与常规统计方法的区别以说明何时使用bootstrap是更合适的,以及通过一个示例展示估计置信区间的过程。
1.1 Bootstrap和常规统计方法的比较
Bootstrap和常规统计方法都使用给定样本来推断总体。
为了实现这一目标,这些程序将研究中获得的少数样本视为该研究可能收集的众多样本中的一个随机子集。通过该子集,可以获得各样本的均值、中位数和标准偏差等统计信息。
假设对某项研究重复了很多次,这种情况下,样本的均值将随样本的不同而变化,并获得样本均值的分布。统计学家把这种分布称为抽样分布,抽样分布是至关重要的,因为它们将样本统计值置于许多其它可能值的更广泛分布中。
实际情况中,某项研究的样本生物学重复数量通常不会很多,因此抽样分布通过给定的少数样本进行估计,获得置信区间并执行假设检验。
Bootstrap和常规统计方法之间的主要区别在于对抽样分布的估计方式。
常规的假设检验程序通常假定数据遵循特殊的分布,如T检验、方差分析等参数检验要求正态分布,并使用样本数据的性质、实验设计和检验统计量来估计抽样分布的方程式。因此为了获得有效的结果,需要考虑适当的测试统计数据并满足检验的前提假设。
与此相比,bootstrap不对数据的分布做任何假设。对于bootstrap估计抽样分布的方法,将一项研究获得的样本数据进行多次重抽样,创建多个模拟样本集,该方法中不考虑原数据集的固有分布特征,以及特定的前提假设等。因此所获得的每个模拟数据集都允许有自己的任意的属性,例如均值,使用直方图表示这些均值的分布时,可以观察到均值的抽样分布特征。
随后,使用获得的抽样分布作为置信区间和假设检验的基础。
1.2 Bootstrap的工作原理
Bootstrap对原始数据集进行重抽样,创建模拟数据数据集,其抽样方法具有如下特点:
-
每次抽样对于每个样本具有相同的概率,具有随机抽取每个原始数据点以将其包含在重抽样数据集中的可能性; -
属于"有放回"的抽样方式,某样本可以多次出现在重抽样的数据集中; -
该过程将创建与原始数据集大小相同的重抽样数据集。
在该过程结束时,模拟数据集将包含原始数据集中存在的值的许多种不同组合。每个模拟数据集都有自己的一组样本统计信息,例如均值、中位数和标准差等。bootstrap过程使用模拟数据集中样本统计量的分布作为抽样分布。
以下用一个简单的例子,帮助理解bootstrap的工作方式。
例如,需要计算一个样本均值95%的置信区间。样本现在有10个观测,均值为40,标准差为5。如果假设均值的样本分布为正态分布,那么(1-α/2)%的置信区间可计算如下。
其中,t是自由度为n-1的t分布的1-α上界值。对于95%的置信区间,可得40-2.262(5/3.163) < μ < 40+2.262(5/3.163),即36.424 < μ < 43.577。以这种方式创建的95%置信区间将会包含真实的总体均值。
但倘若假设均值的样本分布不是正态分布,则上式无法适用。此时可通过bootstrap来解决。
-
从样本中随机选择10个观测,依次抽样后再放回,即有放回的抽样方式;因此有些观测可能会被选择多次,有些则可能一次也未被选中; -
计算并记录样本的均值; -
重复1、2过程,到达一个设定的次数,如1000次(考虑到应用bootstrap方法时的样本数量不会很多,因此大部分情况下,1000次足以满足需求了),如此获得了1000个抽样均值的分布,并按从小到大排序; -
在抽样均值分布中找到2.5%和97.5%分位点,对于1000次抽样,则可分别定位于最前和最末位置的第25个数,它们即定义了95%的置信区间;此时可以有95%的信心认为,总体均值处于此范围内。
1.3 Bootstrap的适用范围
以上示例以估计样本均值的置信区间为例展示了bootstrap的使用,获得置信区间后,即可实现假设检验的目的。
除均值之外,bootstrap还可用于分析更多类型的统计量和样本属性,例如中位数、标准差、相关系数、回归系数、二元数据的方差、多元统计量等。
举个例子,构建过进化树的同学们肯定不会陌生,bootstrap就是常用于检验进化分支是否可靠的一种常用方法(这个的细节部分本篇就不讨论了,将来写到基因组分析、进化树构建的时候再阐述它)。
对于小数据集,bootstrap效果通常很好。然而,bootstrap产生的数据集改变了初始数据集的分布,这会引入估计偏差,随着数据集总体的增加而功效降低。尽管可以在Bootstrap过程中调整偏差,但情况就会变得复杂。因此普遍认为原数据集的总体不能过大,这样可以保证每次抽样都能反映总体的特性,多次抽样后即能覆盖原总体,并且抽样组成的新总体比原总体大。
总体均值不连续时也要慎重考虑使用bootstrap。
此外,如果样本均值服从正态分布或其它特定理论分布,则bootstrap就不存在优势(非参数方法普遍存在这个特点,其它如置换检验、Kruskal-Wallis检验、Wilcoxon检验等),此时参数检验方法仍是首选。
但若样本的潜在分布未知,或存在离群点,或样本量过小,以及没有其它合适的参数方法时,bootstrap将是获取置信区间以及进行假设检验的一种有效方法。例如期望估计样本中位数的置信区间,或者两样本的中位数之差,正态理论没有现成的简单公式可直接套用,此时bootstrap将会是不错的选择。
2. R语言执行bootstrap示例
不妨展示一些R语言执行bootstrap的方法示例。
就以前文置换检验中提到的示例继续吧。在上一示例中,计算了多种微生物类群之间的相关性,并通过置换检验确定了这种相关关系是否是显著的。但是,置换检验对于获取置信区间则是很困难的,因此这里继续使用该数据,使用bootstrap的方法获取相关系数的置信区间。
下文展示使用R包boot的方法。
boot扩展了自助法和重抽样的相关用途,可以借助它实现对一个统计量(如单个均值、单个中位数等,为一个数值)或多个统计量(如多变量间的相关系数、一列回归系数等,为一个数值向量)估计置信区间,实现检验的目的。
# 数据获取自http://blog.sciencenet.cn/blog-3406804-1173120.html
# 或直接打开 https://pan.baidu.com/s/1vspGJlOkX8zreKjAE1fS8A 提取码 ouor
dat <- read.table('data.txt', sep = ' ', row.names = 1, header = TRUE, stringsAsFactors = FALSE, check.names = FALSE)
# 只包含细菌类群丰度数据,计算细菌类群之间的相关性,以 pearson 相关系数为例
dat_phylum <- dat[8:17]
dat_phylum <- scale(dat_phylum)
cor0 <- cor(dat_phylum, method = 'pearson')
cor0 # 相关矩阵
以下使用bootstrap的方法获取pearson相关系数的置信区间,用以评估观测值的相关系数是否是可信的。
对于boot()而言,如果只有单个统计量,函数应当返回一个数值;如果存在多个统计量,函数应该返回一个向量。
这里需要计算多变量间的相关系数,即代表了多统计量情形,因此首先创建一个能够返回相关系数向量的函数。
library(reshape2)
cor_prarson <- function(data, indices) {
cor0 <- melt(cor(data[indices, ]))
cor0 <- cor0$value
cor0
}
#自助抽样 1000 次,详情 ?boot
library(boot)
set.seed(123)
boot_result <- boot(data = dat_phylum, statistic = cor_prarson, R = 1000)
boot_result
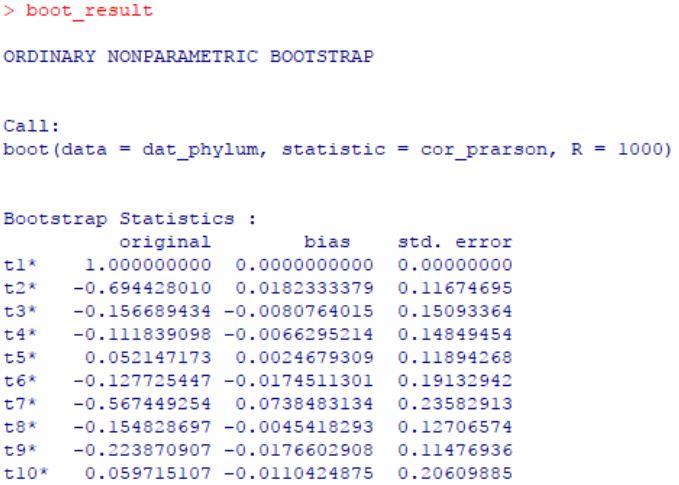
结果中返回了n个统计量,对应了两两变量(微生物类群)间的pearson相关系数的抽样分布。存在多个统计量的bootstrap抽样时,需要通过指定索引参数观测结果。
接下来,我们可以选择感兴起的微生物-微生物关系查看结果。
# 根据一开始计算的相关矩阵,获取索引
cor0 <- melt(cor0)
group <- paste(cor0$Var1, cor0$Var2, sep = '-')
#查看感兴起微生物类群间相关系数的抽样分布
plot(boot_result, index = which(group == 'Acidobacteria-Proteobacteria'))
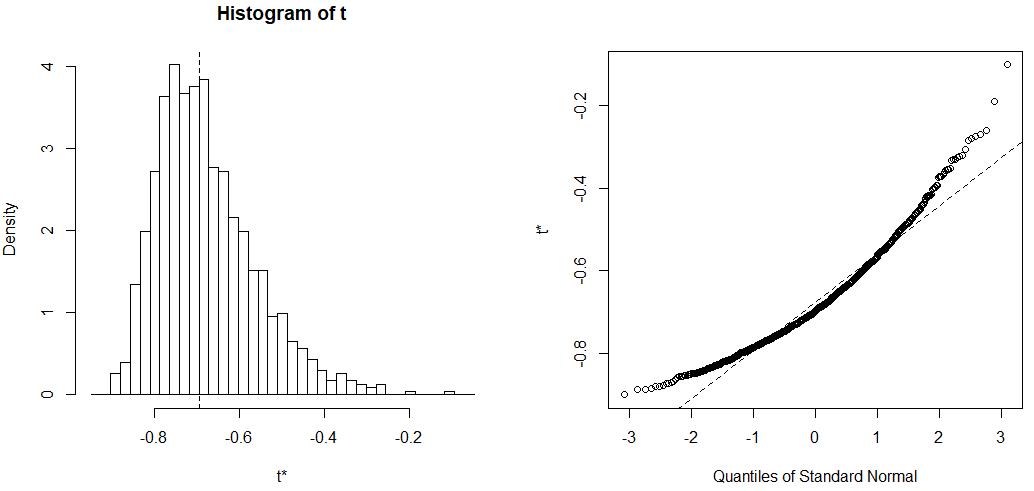
可以看到,由bootstrap抽样1000次计算所得pearson相关系数的分布不呈正态分布。
然后继续获得95%置信区间。
# 获取95%置信区间,详情 ?boot.ci
# type参数设定获取置信区间的方法,这里展示了所有方法的区间估计结果,细节描述见帮助
boot.ci(boot_result, conf = 0.95, type = 'all', index = which(group == 'Acidobacteria-Proteobacteria'))
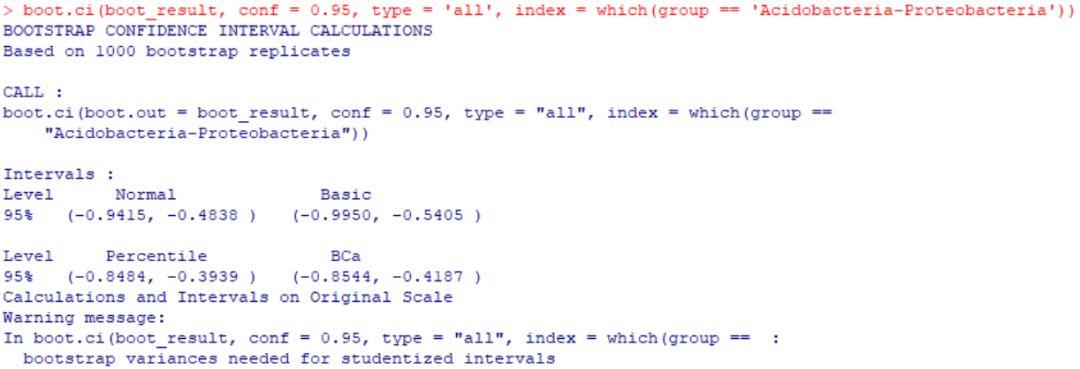
从示例可以看到,生成置信区间的不同方法将导致获得不同的区间。
此时不妨再查看原始观测数据所得的pearson相关系数数值,为-0.6944,落在置信区间之内,并且置信区间均保持在负值(负相关)内,因此有充分(95%的把握)理由认为,所观测两微生物类群间的相关性是可信的。
# 对于原始数据集所观测的两类群间的pearson相关系数
cor0[which(cor0$Var1 == 'Acidobacteria' & cor0$Var2 == 'Proteobacteria'), ]

不妨再看一个不可信的例子。以下示例的置信区间跨0值,显然是不合理的,因为我们不可能允许两变量之间同时存在正相关和负相关的可能性,因此不成立,也就是两微生物类群间的相关性是不可信的。
# 上述结果表明Acidobacteria和Proteobacteria的相关性显著
# 再看一个不显著的例子,Actinobacteria和Proteobacteria
boot.ci(boot_result, conf = 0.95, type = 'all', index = which(group == 'Actinobacteria-Proteobacteria'))
cor0[which(cor0$Var1 == 'Actinobacteria' & cor0$Var2 == 'Proteobacteria'), ]
参考资料
-
Robert I. Kabacoff. R语言实战(第二版)(王小宁、刘撷芯、黄俊文等译).人民邮电出版社,2016. -
https://statisticsbyjim.com/hypothesis-testing/bootstrapping/
热烈欢迎小伙伴们转发、点赞、点在看~~~
以上是关于自助法(bootstrap)在统计检验中的应用及R语言实现过程的主要内容,如果未能解决你的问题,请参考以下文章
R语言boot包中的boot函数格式以及参数说明boot.ci函数格式以及参数说明使用boot包进行自助法Bootstrapping分析的步骤计算统计量或者统计向量的置信区间
R语言编写自定义函数计算R方使用自助法Bootstrapping估计多元回归模型的R方的置信区间可视化获得的boot对象估计单个统计量的置信区间分别使用分位数法和BCa法