R语言实现主成分分析
Posted DU Group
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言实现主成分分析相关的知识,希望对你有一定的参考价值。

主成分分析(PCA)是一种常见的排序方法。通过正交变换将一组存在相关性的变量转换为一组线性不相关的变量,变换之后的变量叫做主成分。
在进行多变量的研究时,变量数量太多就会增加研究的复杂性。如果将一个变量比作一个维度,那么多元数据可以看作由多个变量组成的多维空间内点的合集。在很多情形中,变量间存在一定的相关关系,因此研究者可以将多维度的数据降维,用新的排序轴去尽可能地反映原数据的信息。
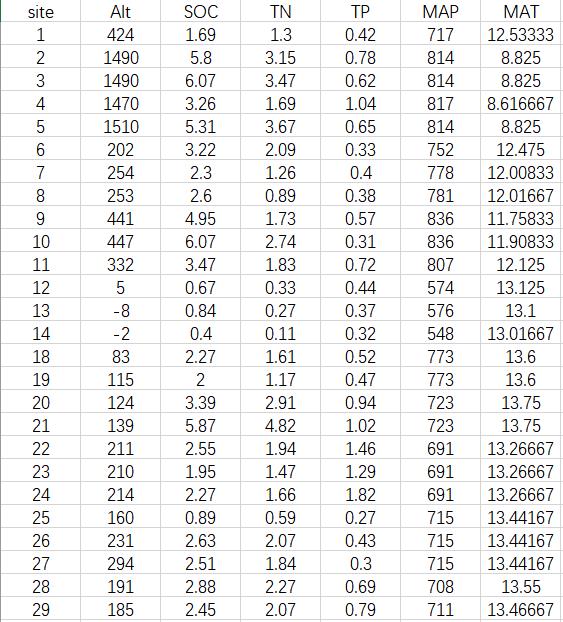
图1 灌丛调查环境数据举例
图1是灌丛调查时获得的样地环境因子数据(列名分别为样地号、海拔、土壤有机碳、全氮、全磷、年均降水和年均温)。那么如何对环境数据进行主成分分析呢?

#读取数据
env = read.csv("env.csv", row.names = 1, header = T)
library(vegan)#加载R包(需提前安装)
env.pca = rda(env, scale = TRUE)
# vegan包里rda( )函数是最常用的PCA分析函数
#scale = TRUE,意为分析前将数据进行标准化(PCA前标准化是必需的步骤)
summary(env.pca)
#PCA的主要结果
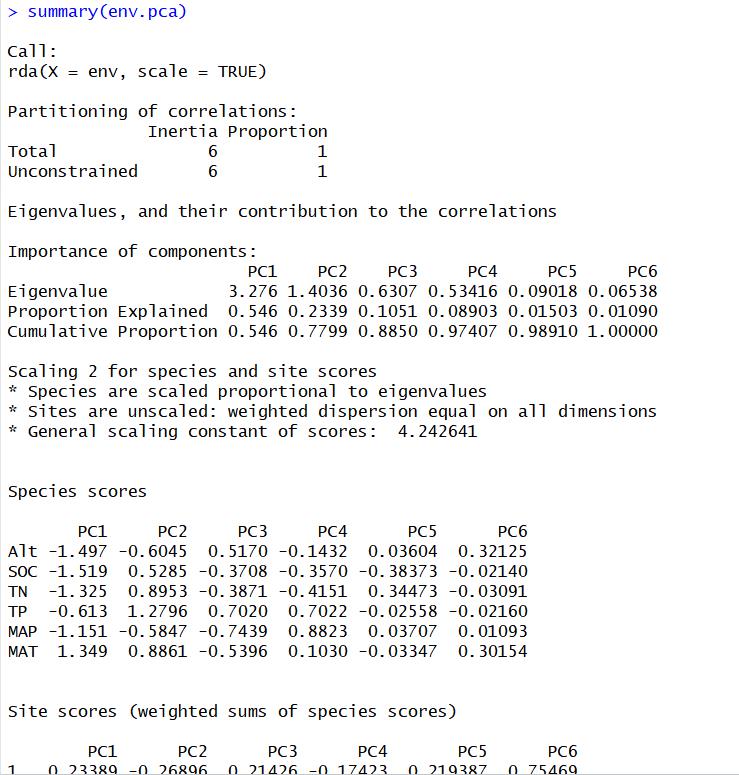
下面对主要的结果进行解释:
Eigenvalue (特征根):是每个排序轴的重要性指标。
Proportion Explained (排序轴解释率):排序轴解释总方差的比例。例如PC1 0.546,意为PC1轴解释了数据总方差的54.6%。
Cumulative Proportion (总解释率):排序轴累计解释率。例如PC2 0.7799,意为第一轴和第二轴共解释了数据77.99%的方差。
PCA的结果可以用排序图(简图)呈现。
biplot(env.pca)
site.scores=scores(env.pca, choices = c(1:2),scaling = 2)
points(site.scores$sites[,1],site.scores$sites[,2]+0.05,pch = 17,col= "blue")
#将样地点加入排序图内,+0.05是为了将样地号和点在图上分开。
图2 PCA双序图
生成的图片如图2所示,最后成图时,还应将第一轴和第二轴的解释率加入排序图中,例:PC1(54.6%)。在排序图内(默认是2型双序图),我们可以看到海拔和年均降水是高度正相关的,这两者也与年均温负相关。表征土壤养分的土壤有机碳、全氮、全磷之间是正相关关系。调查的大多数样地集中在图中第四象限内,表明调查地灌丛主要分布在土壤相对贫瘠,水分适中的中海拔地区。
R学习感言:主成分分析是生态学上比较常见的分析方法,排序图可以直观清晰的表明多个变量之间的关系及对因变量的作用,第一轴可以解释最多的方差因此可以大致代表整个数据的趋势。需要注意的是,主成分分析所使用的变量必须统一量纲(标准化),标准化的方式也要根据数据而定。
以上是关于R语言实现主成分分析的主要内容,如果未能解决你的问题,请参考以下文章
R语言主成分分析PCA和因子分析EFA主成分(因子)个数主成分(因子)得分主成分(因子)旋转(正交旋转斜交旋转)主成分(因子)解释
R语言进行主成分分析(PCA):使用prcomp函数来做主成分分析使用summary函数查看主成分分析的结果计算每个主成分解释方差的每个主成分解释的方差的比例以及多个主成分累积解释的方差比例