R语言-数据的正态性检验
Posted 体育统计代码
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言-数据的正态性检验相关的知识,希望对你有一定的参考价值。
关注我
不迷路
R语言-数据的正态性检验
R语言-数据的正态性检验
数据的分布形势是进行统计学处理的基础,在没有掌握数据结构的情况下进行统计学分析,极有可能得出不可靠的结论,因此对于数据分布的检验就显得非常重要。正态分布是几种常见的数据分布形势,在体育学研究中也较为常见,使用R语言进行数据的正态性的检验非常简单。欲知详情,请点赞关注!
1
01
数据
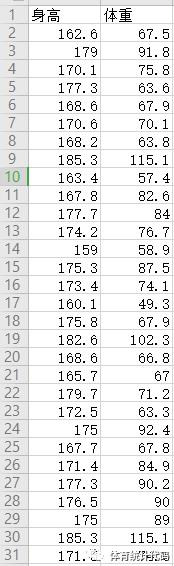
数据如下,这是一份根据真实数据改编的改编数据。
02
读入数据到RStudio
1
方式一
给出文件的相对路径,首先设置R-Studio的工作目录,然后打开数据文件。设置工作目录为“数据”文件夹。
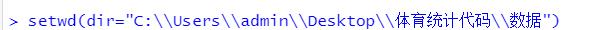
>setwd(dir="C:\Users\admin\Desktop\正在处理\体育统计代码\数据")
读取数据,将数据存放在df数据框里

> read.csv("正态性检验数据.csv",header=T)
2
方式二
给出文件的绝对路径,无需设置工作目录。
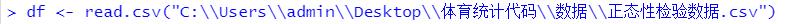
df<-read.csv("C:\Users\admin\Desktop\正在处理\体育统计代码\数据\正态性检验数据.csv",header=T)
3
查看数据

03
绘制条形图
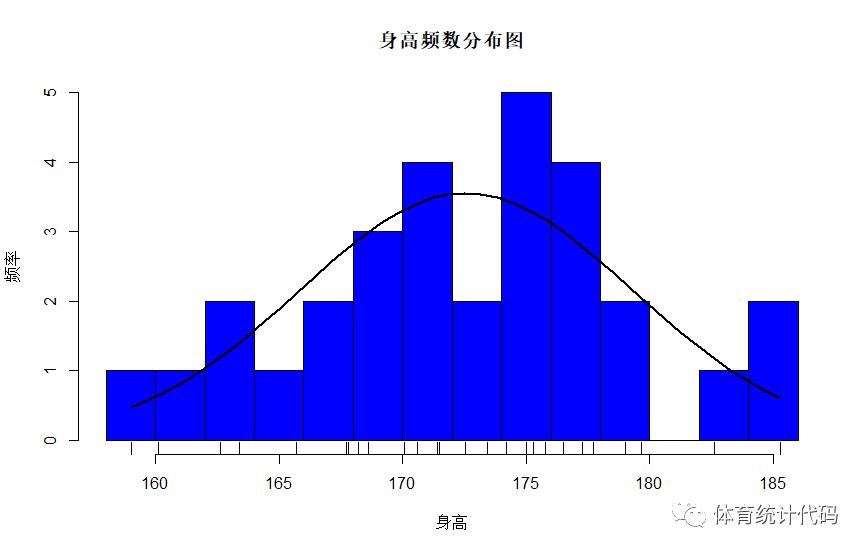
1
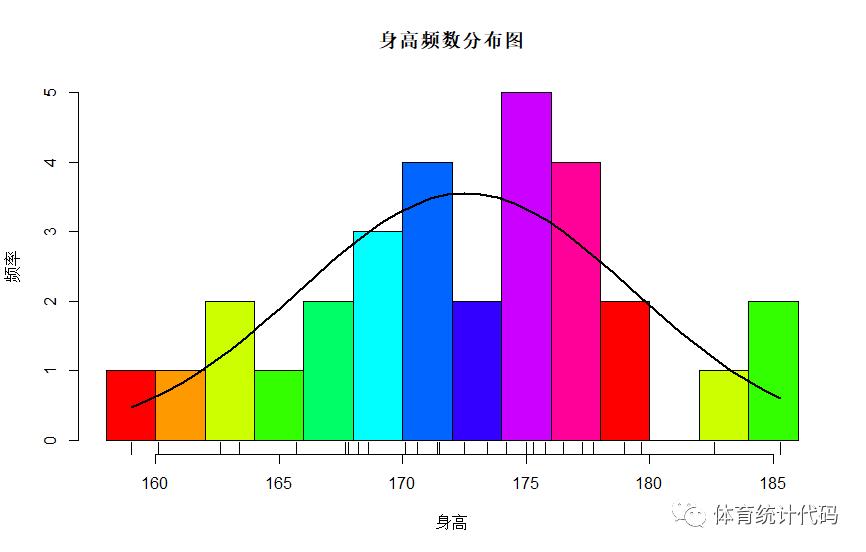
绘制彩色条形图

> h <- hist(df$身高,breaks = 12,col=rainbow(10),xlab="身高",ylab="频率",main = "身高频数分布图")
> x <- df$身高
> xfit <- seq(min(x),max(x),length=40)
> yfit <- dnorm(xfit,mean = mean(x),sd = sd(x))
> yfit <- yfit*diff(h$mids[1:2])*length(x)
> lines(xfit,yfit,col="black",lwd=2)
> rug(jitter(df$身高))#添加轴虚图
> shapiro.test(df$身高)
04
正态性检验
Shapiro-Wilk (SW) 检验,用于验证一个随机样本数据是否来自正态分布。

1
结果解读
H0:该样本数据服从正态分布。
H1:该样本数据不服从正太分布。
SW检验结果为:p>0.05,因此接受原假设,认为该样本符合正态分布。
04
参考资料
[1]https://blog.csdn.net/zzminer/article/details/8858469
以上是关于R语言-数据的正态性检验的主要内容,如果未能解决你的问题,请参考以下文章
R语言使用wilcox.test函数进行两组数据的Wilcoxon符号秩检验wilcox.test函数添加paired参数则为Wilcoxon signed rank,当t检验需要的正态性条件不满足
R语言aov函数进行单因素方差分析(One-way ANOVA)使用Q-Q图来评估方差分析因变量的正态性Bartlett验证方差的相等性(齐次性)car包中的outlierTest函数异常检验