关于Paxos 幽灵复现问题
Posted 基础架构和存储
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于Paxos 幽灵复现问题相关的知识,希望对你有一定的参考价值。
第一轮中A被选为Leader,写下了1-10号日志,其中1-5号日志形成了多数派,并且已给客户端应答,而对于6-10号日志,客户端超时未能得到应答。
第二轮,A宕机,B被选为Leader,由于B和C的最大的logID都是5,因此B不会去重确认6-10号日志,而是从6开始写新的日志,此时如果客户端来查询的话,是查询不到6-10号日志内容的,此后第二轮又写入了6-20号日志,但是只有6号和20号日志在多数派上持久化成功。
第三轮,A又被选为Leader,从多数派中可以得到最大logID为20,因此要将7-20号日志执行重确认,其中就包括了A上的7-10号日志,之后客户端再来查询的话,会发现上次查询不到的7-10号日志又像幽灵一样重新出现了。
对于将Paxos协议应用在数据库日志同步场景的情况,幽灵复现问题是不可接受,一个简单的例子就是转账场景,用户转账时如果返回结果超时,那么往往会查询一下转账是否成功,来决定是否重试一下。如果第一次查询转账结果时,发现未生效而重试,而转账事务日志作为幽灵复现日志重新出现的话,就造成了用户重复转账。
为了处理“幽灵复现”问题,我们在每条日志的内容中保存一个generateID,leader在生成这条日志时以当前的leader ProposalID作为generateID。按logID顺序回放日志时,因为leader在开始服务之前一定会写一条StartWorking日志,所以如果出现generateID相对前一条日志变小的情况,说明这是一条“幽灵复现”日志(它的generateID会小于StartWorking日志),要忽略掉这条日志。
第三态问题
第三态问题也是我们之前经常讲的问题, 其实在网络系统里面, 对于一个请求都有三种返回结果
成功
失败
超时未知
前面两种状态由于服务端都有明确的返回结果, 所以非常好处理, 但是如果是第三种状态的返回, 由于是超时状态, 所以服务端可能对于这个命令是请求是执行成功, 也有可能是执行失败的, 所以如果这个请求是一个写入操作, 那么下一次的读取请求可能读到这个结果, 也可能读到的结果是空的
就像在 raft phd 那个论文里面说的, 这个问题其实是和 raft/multi-paxos 协议无关的内容, 只要在分布式系统里面都会存在这个问题, 所以大部分的解决方法是两个对于每一个请求都加上一个唯一的序列号的标识, 然后server的状态机会记录之前已经执行过序列号. 当一个请求超时的时候, 默认的client 的逻辑会重试这个逻辑, 在收到重试的逻辑以后, 由于server 的状态机记录了之前已经执行过的序列号信息, 因此不会再次执行这条指令, 而是直接返回给客户端
由于上述方法需要在server 端维护序列号的信息, 这个序列号是随着请求的多少递增的, 大小可想而知(当然也可以做一些只维护最近的多少条序列号个数的优化). 常见的工程实现是让client 的操作是幂等的, 直接重试即可, 比如floyd 里面的具体实现
那么对应于raft 中的第三态问题是, 当最后log Index 为4 的请求超时的时候, 状态机中出现的两种场景都是可能的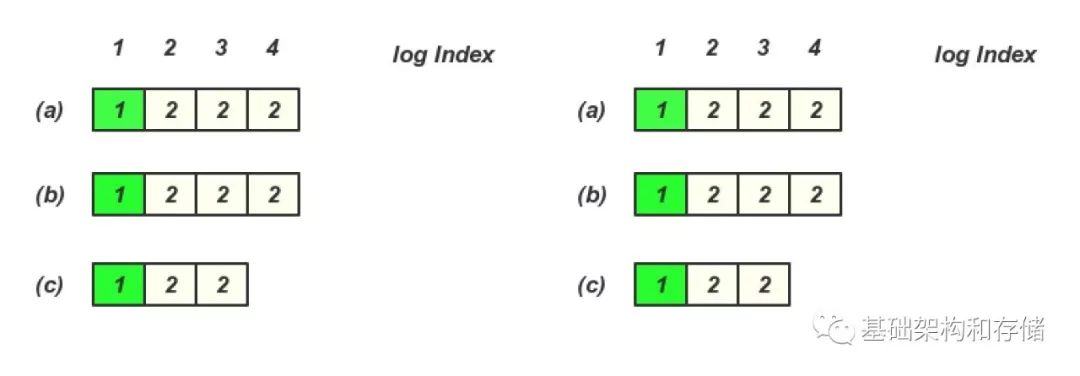
所以下一次读取的时候有可能读到log Index 4 的内容, 也有可能读不到, 所以如果在发生了超时请求以后, 默认client 需要进行重试直到这个操作成功以后, 接下来才可以保证读到的写入结果. 这也是工程实现里面常见的做法
对应于幽灵问题, 其实是由于6-10 的操作产生了超时操作, 由于产生了超时操作以后, client 并没有对这些操作进行确认, 而是接下来去读取这个结果, 那么读取不到这个里面的内容, 由于后续的写入和切主操作有重新能够读取到这个6-10 的内容了, 造成了幽灵复现, 导致这个问题的原因还是因为没有进行对超时操作的重确认.
回到幽灵复现问题
那么Raft 有没有可能出现这个幽灵复现问题呢?
其实在早期Raft 没有引入新的Leader 需要写入一个包含自己的空的Entry 的时候也一样会出现这个问题
Log Index 4,5 客户端超时未给用户返回, 存在以下日志场景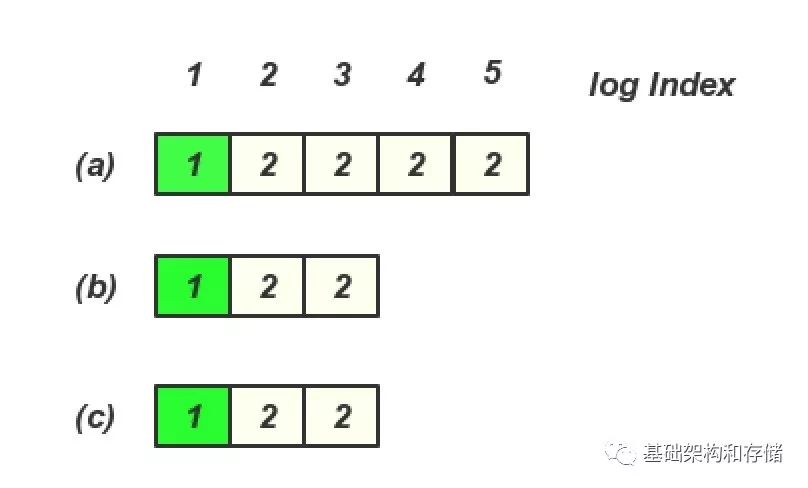
然后 (a) 节点宕机, 这个时候client 是查询不到 Log entry 4, 5 里面的内容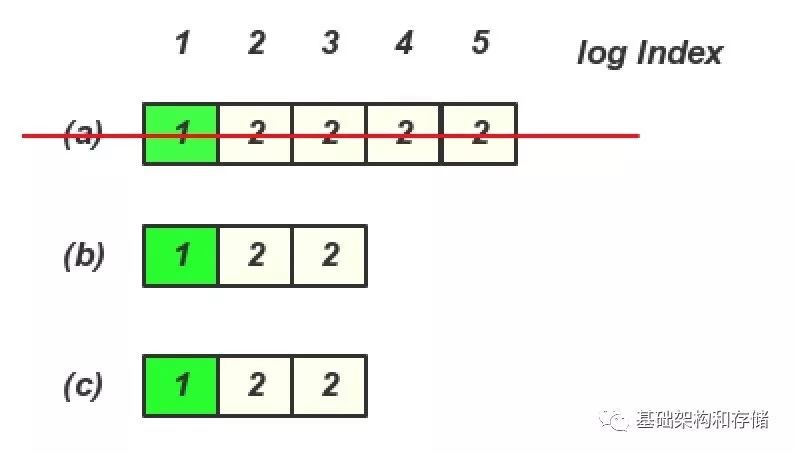
在(b)或(c) 成为Leader 期间, 没有写入任何内容, 然后(a) 又恢复, 并且又重新选主, 那么就存在一下日志, 这个时候client 再查询就查询到Log entry 4,5 里面的内容了
那么Raft 里面加入了新Leader 必须写入一条当前Term 的Log Entry 就可以解决这个问题, 其实和之前郁白提到的写入一个StartWorking 日志是一样的做法, 由于(b), (c) 有一个Term 3的日志, 就算(a) 节点恢复过来, 也无法成了Leader, 那么后续的读也就不会读到Log Entry 4, 5 里面的内容
那么这个问题的本质是什么呢?
其实这个问题的本质是对于一致性协议在recovery 的不同做法产生的. 关于一致性协议在不同阶段的做法可以看这个文章 http://baotiao.github.io/2018/01/02/consensus-recovery/
也就是说对于一个在多副本里面未达成一致的Log entry, 在Recovery 需要如何处理这一部分未达成一致的log entry.
对于这一部分log entry 其实可以是提交, 也可以是不提交, 因为会产生这样的log entry, 一定是之前对于这个client 的请求超时返回了.
常见的Multi-Paxos 在对这一部分日志进行重确认的时候, 默认是将这部分的内容提交的, 也就是通过重确认的过程默认去提交这些内容
而Raft 的实现是默认对这部分的内容是不提交的, 也就是增加了一个当前Term 的空的Entry, 来把之前leader 多余的log 默认不提交了, 幽灵复现里面其实也是通过增加一个空的当前Leader 的Proposal ID 来把之前的Log Entry 默认不提交
所以这个问题只是对于返回超时, 未达成一致的Log entry 的不同的处理方法造成的.
在默认去提交这些日志的场景, 在写入超时以后读取不到内容, 但是通过recovery 以后又能够读取到这个内容, 就产生了幽灵复现的问题
但是其实之所以会出现幽灵复现的问题是因为在有了一个超时的第三态的请求以后, 在没有处理好这个第三态请求之前, 出现成功和失败都是有可能的.
所以本质是在Multi-Paxos 实现中, 在recovery 阶段, 将未达成一致的Log entry 提交造成的幽灵复现的问题, 本质是没有处理好这个第三态的请求.
以上是关于关于Paxos 幽灵复现问题的主要内容,如果未能解决你的问题,请参考以下文章
Java安全-Tomcat AJP 文件包含漏洞(CVE-2020-1938)幽灵猫漏洞复现