如何解决分布式系统中的“幽灵复现”?
Posted 阿里技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何解决分布式系统中的“幽灵复现”?相关的知识,希望对你有一定的参考价值。
阿里妹导读:
“幽灵复现”的问题本质属于分布式系统的“第三态”问题,即在网络系统里面,对于一个请求都有三种返回结果:成功,失败,超时未知。对于超时未知,服务端对请求命令的处理结果可以是成功或者失败,但必须是两者中之一,不能出现前后不一致情况。
我们知道,当前业界有很多分布式一致性复制协议,比如Paxos,Raft,Zab及Paxos的变种协议,被广泛用于实现高可用的数据一致性。Paxos组通常有3或5个互为冗余的节点组成,它允许在少数派节点发生停机故障的情况下,依然能继续提供服务,并且保证数据一致性。作为一种优化,协议一般会在节点之间选举出一个Leader专门负责发起Proposal,Leader的存在,避免了常态下并行提议的干扰,这对于提高Proposal处理的效率有很大提升。
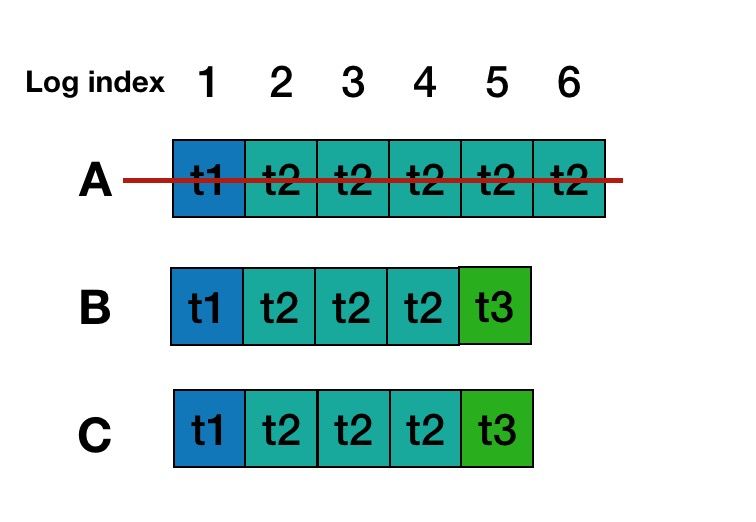
但是考虑在一些极端异常,比如网络隔离,机器故障等情况下,Leader可能会经过多次切换和数据恢复,使用Paxos协议处理日志的备份与恢复时,可以保证确认形成多数派的日志不丢失,但是无法避免一种被称为“幽灵复现”的现象。考虑下面一种情况:

如上表所示,在第一轮中,A成为指定Leader,发出1-10的日志,不过后面的6-10没有形成多数派,随机宕机。随后,第二轮中,B成为指定Leader,继续发出6-20的日志(B没有看到有6-10日志的存在),这次,6以及20两条日志形成了多数派。随机再次发生切换,A回来了,从多数派拿到的最大LogId为20,因此决定补空洞,事实上,这次很大可能性是要从6开始,一直验证到20。我们逐个看下会发生什么:
-
针对Index 6的日志,A重新走一轮basic paxos就会发现更大proposeid形成决议的6,从而放弃本地的日志6,接受已经多数派认可的日志;
-
针对Index 7到Index 10,因为多数派没有形成有效落盘,因此A随机以本地日志发起提议并形成多数派;
-
针对Index 11到Index 19,因为均没有形成有效落盘数据,因此,以noop形成补空洞;
-
针对Index 20,这个最简单,接受已经多数派认可的日志;
在上面的四类情况分析中,1,3,4的问题不大。主要在场景2,相当于在第二轮并不存在的7~10,然后在第三列又重新出现了。按照Oceanbase的说法,在数据库日志同步场景的情况,这个问题是不可接受的,一个简单的例子就是转账场景,用户转账时如果返回结果超时,那么往往会查询一下转账是否成功,来决定是否重试一下。如果第一次查询转账结果时,发现未生效而重试,而转账事务日志作为幽灵复现日志重新出现的话,就造成了用户重复转账。
2、基于 Multi-Paxos 解决“幽灵复现”问题
为了处理“幽灵复现”问题,基于Multi-Paxos实现的一致性系统,可以在每条日志内容保存一个epochID,指定Proposer在生成这条日志时以当前的ProposalID作为epochID。按logID顺序回放日志时,因为leader在开始服务之前一定会写一条StartWorking日志,所以如果出现epochID相对前一条日志变小的情况,说明这是一条“幽灵复现”日志,要忽略掉这条日志(说明一下,我认这里顺序是先补空洞,然后写StartWorkingID,然后提供服务)。
以上个例子来说明,在Round 3,A作为leader启动时,需要日志回放重确认,index 1~5 的日志不用说的,epochID为1,然后进入epochID为2阶段,index 6 会确认为epochID为2的StartWorking日志,然后就是index 7~10,因为这个是epochID为1的日志,比上一条日志epochID小,会被忽略掉。而Index 11~19的日志,EpochID应该是要沿袭自己作为Leader看到的上上一轮StartWorkingID(当然,ProposeID还是要维持在3的),或者因为是noop日志,可以特殊化处理,即这部分日志不参与epochID的大小比较。然后index 20日志也会被重新确认。最后,在index 21写入StartWorking日志,并且被大多数确认后,A作为leader开始接收请求。
首先,我们聊一下Raft的日志恢复,在 Raft 中,每次选举出来的Leader一定包含已经Committed的数据(抽屉原理,选举出来的Leader是多数中数据最新的,一定包含已经在多数节点上Commit的数据),新的Leader将会覆盖其他节点上不一致的数据。虽然新选举出来的Leader一定包括上一个Term的Leader已经Committed的Log Entry,但是可能也包含上一个Term的Leader未Committed的Log Entry。这部分Log Entry需要转变为Committed,相对比较麻烦,需要考虑Leader多次切换且未完成Log Recovery,需要保证最终提案是一致的,确定的,不然就会产生所谓的幽灵复现问题。
因此,Raft中增加了一个约束:对于之前Term的未Committed数据,修复到多数节点,且在新的Term下至少有一条新的Log Entry被复制或修复到多数节点之后,才能认为之前未Committed的Log Entry转为Committed。
为了将上一个Term未Committed的Log Entry转为Committed,Raft 的解决方案如下:
Raft算法要求Leader当选后立即追加一条Noop的特殊内部日志,并立即同步到其它节点,实现前面未Committed日志全部隐式提交。
3.2 Raft解决“幽灵复现”问题
针对第一小节的场景,Raft中是不会出现第三轮A当选leader的情况,首先对于选举,候选人对比的是最后一条日志的任期号(lastLogTerm)和日志的长度(lastLogIndex)。B、C的lastLogTerm(t2)和lastLogIndex(20)都比A的lastLogTerm(t1)和lastLogIndex(10)大,因此leader只能出现在B、C之内。假设C成为leader后,Leader运行过程中会进行副本的修复,对于A来说,就是从log index为6的位置开始,C将会把自己的index为6及以后的log entry复制给A,因此A原来的index 6-10的日志删除,并保持与C一致。最后C会向follower发送noop的log entry,如果被大多数都接收提交后,才开始正常工作,因此不会出现index 7-10能读到值的情况。
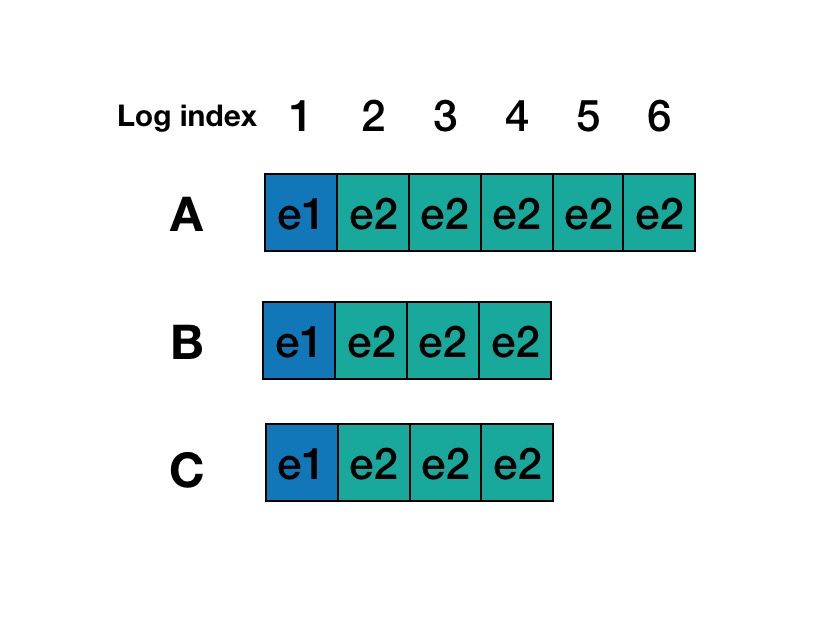
这里考虑另一个更通用的幽灵复现场景。考虑存在以下日志场景:
1)Round 1,A节点为leader,Log entry 5,6内容还没有commit,A节点发生宕机。这个时候client 是查询不到 Log entry 5,6里面的内容。
2)Round 2,B成为Leader, B中Log entry 3, 4内容复制到C中, 并且在B为主的期间内没有写入任何内容。
3)Round 3,A 恢复并且B、C发生重启,A又重新选为leader, 那么Log entry 5, 6内容又被复制到B和C中,这个时候client再查询就查询到Log entry 5, 6 里面的内容了。
Raft里面加入了新Leader 必须写入一条当前Term的Log Entry 就可以解决这个问题, 其实和MultiPaxos提到的写入一个StartWorking 日志是一样的做法, 当B成为Leader后,会写入一个Term 3的noop日志,这里解决了上面所说的两个问题:
-
Term 3的noop日志commit前,B的index 3,4的日志内容一定会先复制到C中,实现了最大commit原则,保证不会丢数据,已经 commit 的 log entry 不会丢。
-
就算A节点恢复过来, 由于A的lastLogTerm比B和C都小,也无法成了Leader, 那么A中未完成的commit只是会被drop,所以后续的读也就不会读到Log Entry 5,6里面的内容。
Zab在工作时分为原子广播和崩溃恢复两个阶段,原子广播工作过程也可以类比raft提交一次事务的过程。
崩溃恢复又可以细分为Leader选举和数据同步两个阶段。
早期的Zab协议选举出来的Leader满足下面的条件:
a) 新选举的Leader节点含有本轮次所有竞选者最大的zxid,也可以简单认为Leader拥有最新数据。
该保证最大程度确保Leader具有最新数据。
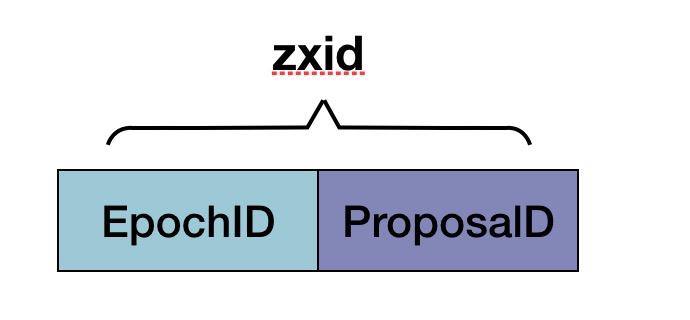
b) 竞选Leader过程中进行比较的zxid,是基于每个竞选者已经commited的数据生成。
zxid是64位高32位是epoch编号,每经过一次Leader选举产生一个新的leader,新的leader会将epoch号+1,低32位是消息计数器,每接收到一条消息这个值+1,新leader选举后这个值重置为0。这样设计的好处在于老的leader挂了以后重启,它不会被选举为leader,因此此时它的zxid肯定小于当前新的leader。当老的leader作为follower接入新的leader后,新的leader会让它将所有的拥有旧的epoch号的未被commit的proposal清除。
选举出leader后,进入日志恢复阶段,会根据每个Follower节点发送过来各自的zxid,决定给每个Follower发送哪些数据,让Follower去追平数据,从而满足最大commit原则,保证已commit的数据都会复制给Follower,每个Follower追平数据后均会给Leader进行ACK,当Leader收到过半Follower的ACK后,此时Leader开始工作,整个zab协议也就可以进入原子广播阶段。
对于第 1 节的场景,根据ZAB的选举阶段的机制保证,每次选举后epoch均会+1,并作为下一轮次zxid的最高32位。所以,假设Round 1阶段,A,B,C的EpochId是1,那么接下来的在Round 2阶段,EpochId为2,所有基于这个Epoch产生的zxid一定大于A上所有的zxid。于是,在Round 3,由于B, C的zxid均大于A,所以A是不会被选为Leader的。A作为Follower加入后,其上的数据会被新Leader上的数据覆盖掉。可见,对于情况一,zab是可以避免的。
对于 3.2 节的场景,在Round 2,B选为leader后,并未产生任何事务。在Round 3选举,由于A,B,C的最新日志没变,所以A的最后一条日志zxid比B和C的大,因此A会选为leader,A将数据复制给B,C后,就会出现”幽灵复现“现象的。
为了解决“幽灵复现”问题,最新Zab协议中,每次leader选举完成后,都会保存一个本地文件,用来记录当前EpochId(记为CurrentEpoch),在选举时,会先读取CurrentEpoch并加入到选票中,发送给其他候选人,候选人如果发现CurrentEpoch比自己的小,就会忽略此选票,如果发现CurrentEpoch比自己的大,就会选择此选票,如果相等则比较zxid。因此,对于此问题,Round 1中,A,B,C的CurrentEpoch为2;Round 2,A的CurrentEpoch为2,B,C的CurrentEpoch为3;Round 3,由于B,C的CurrentEpoch比A的大,所以A无法成为leader。
在阿里云的女娲一致性系统里面,做法也是类似于Raft与Zab,确保能够制造幽灵复现的角色无法在新的一轮选举为leader,从而避免幽灵日志再次出现。从服务端来看“幽灵复现”问题,就是在failover情况下,新的leader不清楚当前的committed index,也就是分不清log entry是committed状态还是未committed状态,所以需要通过一定的日志恢复手段,保证已经提交的日志不会被丢掉(最大 commit 原则),并且通过一个分界线(如MultiPaxos的StartWorking,Raft的noop,Zab的CurrentEpoch)来决定日志将会被commit还是被drop,从而避免模糊不一的状态。“幽灵复现”的问题本质属于分布式系统的“第三态”问题,即在网络系统里面, 对于一个请求都有三种返回结果:成功,失败,超时未知。对于超时未知,服务端对请求命令的处理结果可以是成功或者失败,但必须是两者中之一,不能出现前后不一致情况。在客户端中,请求收到超时,那么客户端是不知道当前底层是处于什么状况的,成功或失败都不清楚,所以一般客户端的做法是重试,那么底层apply的业务逻辑需要保证幂等性,不然重试会导致数据不一致。
1. In Search of an Understandable Consensus Algorithm - Diego Ongaro and John Ousterhout
https://raft.github.io/raft.pdf?spm=ata.13261165.0.0.337d6f55qtohyc&file=raft.pdf
2. Paxos Made Simple – Leslie Lamport
https://lamport.azurewebsites.net/pubs/paxos-simple.pdf?spm=ata.13261165.0.0.337d6f55qtohyc&file=paxos-simple.pdf
http://oceanbase.org.cn/?spm=ata.13261165.0.0.337d6f55qtohyc&p=111
4. 关于Paxos "幽灵复现"问题看法 – 陈宗志
https://zhuanlan.zhihu.com/p/40175038?spm=ata.13261165.0.0.337d6f55qtohyc
https://www.cnblogs.com/wxd0108/p/6251729.html?spm=ata.13261165.0.0.337d6f55qtohyc
 福利来了
福利来了
阿里巴巴集团高级研究员五福
在线直播
AI·OS是阿里集团搜索、推荐、广告共同的大数据深度学习在线服务体系,支撑了阿里集团几乎全部的搜索、推荐与广告业务,该体系也通过阿里开放搜索、智能推荐、Elasticsearch三款云原生产品赋能外部企业和开发者。它的秘密,今晚将被揭开!
阿里巴巴集团高级研究员五福,3月12日(今晚)20:30–21:30在线直播《淘宝千人千面背后的秘密:大数据深度学习技术体系》。

以上是关于如何解决分布式系统中的“幽灵复现”?的主要内容,如果未能解决你的问题,请参考以下文章
Zookeeper和Chubby分布式协调系统
分布式系统中的时间和顺序——关于Spanner中的Linearizability
Zookeeper和Chubby[分布式协调系统]
从Paxos幽灵复现谈Raft实现原理
SchedulerX 如何帮助用户解决分布式任务调度难题?
一文理解分布式开发中的服务治理