分布式算法:还不懂Paxos?Paxos和Multi-Paxos详解
Posted crazstom
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式算法:还不懂Paxos?Paxos和Multi-Paxos详解相关的知识,希望对你有一定的参考价值。
主要内容来自Implementing Replicated Logs With Paxos
https://ongardie.net/static/raft/userstudy/paxos.pdf
Implementing Replicated Logs With Paxos
论文Paxos made simple从简单易懂的角度阐述了Paxos算法。之后,2013年斯坦福大学的Diego Ongaro做了一个讲座:Implementing Replicated Logs With Paxos,详细讲了Paxos以及Multi-Paxos。Multi-Paxos其实就是更具体的分布式算法实现,包括选举leader,配置改变,优化效率,完整性复制日志等。如果有人看过Raft的论文,可能会惊呼,这TM不是Raft吗?哈哈哈,Diego Ongaro就是提出Raft算法的原作者,所以可以说Raft就是基于Paxos然后进化而来的。
http://lamport.azurewebsites.net/pubs/paxos-simple.pdf
Paxos made simple
https://ongardie.net/static/raft/userstudy/paxos.pdf
Implementing Replicated Logs With Paxos
本文通过实现日志复制系统的方式来阐述Paxos和Multi-Paxos算法。Paxos的目标就是维持各个服务器副本相同,进而实现分布式一致性。保持各个服务器上副本的一致性,就是复制状态机,即所有的服务器会以相同的顺序执行客户端输入的指令。
分布式系统复制日志的过程如上图,主要为:
客户端将新的指令(add, jmp, mov...)发送给一个服务器
服务器使用Paxos算法选择一条日志记录指令
服务器等待这个日志被复制到剩余的服务器中,然后执行日志中的状态机指令
服务器将状态机的输出返回给客户端
1. Basic Paxos
Paxos算法是以议会通过提案的流程来阐述的,所以Paxos论文中使用提案来表示需要达成共识的内容。提案中包括一个提案编号和提案的内容,提案编号是不重复的且递增,提案内容就是当前服务器的状态机指令,比如:"把服务器的X加一"可能就是一条"INCR X"指令。
Paxos论文把"提出提案->通过提案->应用提案"整个过程称为一个实例,提案编号为n,提案内容为v,那么就说"n号实例选中了v"。分布式系统常使用日志来记录执行的指令,各个服务器通过保持日志的一致性来实现复制状态机模型,状态机的输入就是一条条日志,客户端输入的指令v作为日志条目保存下来,所以也称为"n号日志选中了v"。
1.1. 三种角色
Paxos论文中提到了三种角色:proposer、acceptor和learner,分布式系统的进程至少扮演一个角色。
proposer:提出一个提案,存在不止一个proposer
acceptor:接受或者忽略一个proposer的提案,如果一个提案被大多数的acceptor接受,这个提案就被通过
learner:学习已经通过的提案

在多副本状态机中,每个副本同时具有proposer、acceptor和learner三种角色,这意味着任何一个服务器副本都能够提出提案,接受其他副本的提案,以及学习通过的提案。
1.2. Paxos提案过程
Paxos算法把通过提案分成两个阶段:prepare阶段和accept阶段,另外还有一个learn阶段。

在上图中,每条线表示消息的传递,箭头为传递方向,使用序号来标记消息传递的顺序。
第一阶段:称为prepare阶段。
第一条消息:proposer发给所有acceptor。proposer选取一个没有用过的编号n,附带在prepare请求中发送给所有的acceptor,记为prepare(n)
第二条消息:acceptor发给proposer。acceptor从prepare请求中取出编号n,返回自己已经接受的提案中n以下的最大编号提案,如果没有就返回空。同时,acceptor会承诺:(1)不再接收编号小于等于n的prepare请求;(2)不再接受编号小于n的propose请求。
第二阶段:称为propose阶段。
第三条消息:proposer发给所有acceptor。proposer将所有prepare请求的回复中,取出编号最大的提案。如果这样的提案存在,就把其内容作为编号为n的新提案内容发送给所有的acceptor;如果提案不存在,proposer就可以设置新的提案内容,(一般为客户端传输的新指令),然后发送给所有的acceptor。记为propose(n,v)
第四条消息:acceptor发给proposer。如果acceptor没有接受过编号大于等于n的提案,就接受这个新的提案,返回一个"OK",同时持久化这个提案编号和提案内容。
第三阶段:称为learn阶段。
第五条消息:proposer发给所有learner。如果proposer收到大多数acceptor的"OK"回复,说明提案通过了,否则回到第一阶段。proposer将通过的提案作为消息发送给所有的learner,让learner学习提案中的内容。
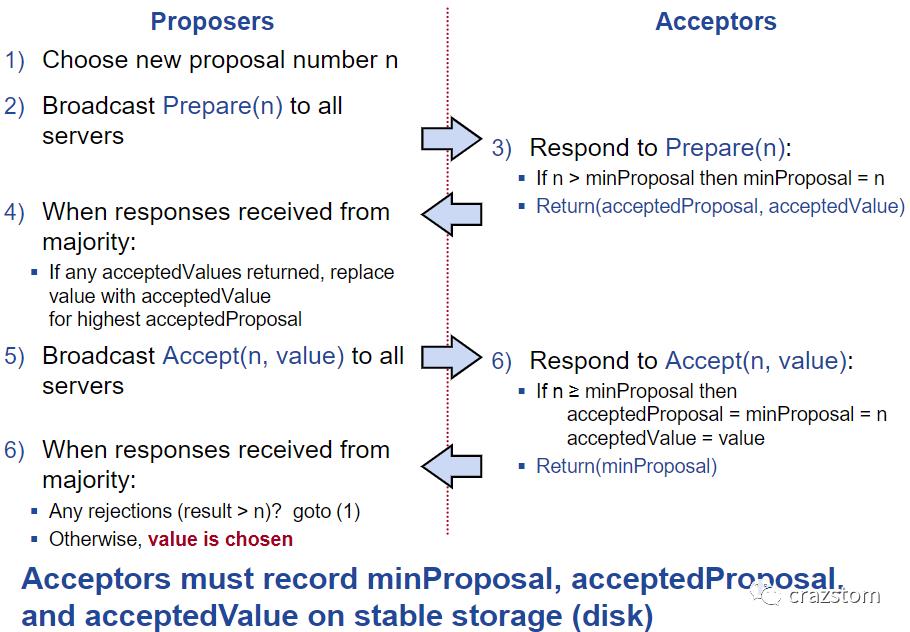
在使用Paxos算法实现日志复制的时候,每个Paxos服务器同时扮演这三个角色。
1.3. 实现算法时产生的问题
1.3.1. 单个acceptor
为了使得客户端输入的一系列指令在Paxos服务器中的执行顺序都是一样的,可以使用单个acceptor,这样每个指令只有通过唯一的acceptor接受之后才执行。
但是,单个acceptor宕机之后,整个服务就不可用了。
解决方法是:使用奇数多个acceptor;如果提案被大多数的acceptor接受就通过;如果一个acceptor宕机了,之前选中的提案内容也还是可用的。
1.3.2. 分散投票
首先是P1法则:acceptor必须接受它收到的第一个提案
分散投票就是同时有多个proposer提出提案,而有多个acceptor之前都没有收到过提案,所以这些proposer被这些acceptor接受了,只不过是一个acceptor接受一个提案。这样的话,没有提案占大多数,也就没有提案被通过。
这些proposer就会再进行一轮提案。这样的情况会降低Paxos的效率。
Paxos论文中通过设置提案编号以及让acceptor接受多个提案解决的。
1.3.3. 选择冲突
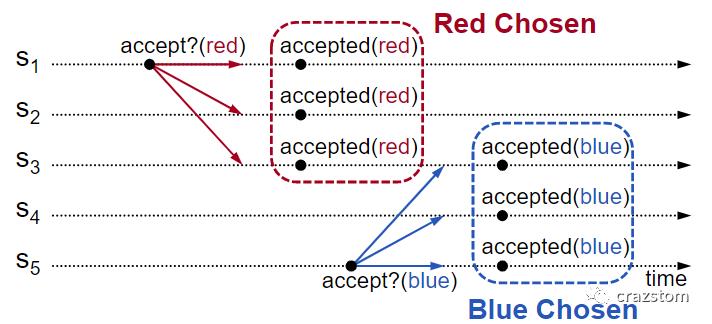
已知在一次流程中,acceptor可以接受多个提案。
那么在下面的流程中,两次accept请求使用相同的提案编号n:
S1向S2、S3发出accept(red)请求
S2、S3作为acceptor会接受这个请求,那么red提案就通过了。S2、S3也学习到提案的内容:red
在S2、S3学习提案red的时候,S5也提出一个新提案blue,记作accept(blue)
S3、S4会通过提案blue并学习提案
现在所有的acceptor中,编号为n的提案并不完全相同:red和blue。
如何解决选择的提案内容冲突呢,就是要保证同一个流程中的多个被通过的提案内容是一样的。
而上述的两个accept请求可以放在两个流程中进行。假设red提案编号的n,那么blue的提案编号就是n+1,这样就不会出现冲突现象,不过可能导致活锁。
1.3.4. 活锁现象
如下过程会产生活锁现象:
S1提出编号为3.1的提案并执行完prepare阶段
S5提出编号为3.5的提案并执行完prepare阶段,S3作为acceptor不会再接受小于3.5的accept请求
S1发给S3的accept请求被忽略了,所以提案3.1没有通过
S1选择编号4.1提出新提案,并执行prepare阶段,S3收到之后就不会再接受低于4.1的accept请求
S5的accept 3.5的请求也就失败了,S5选择一个新的提案编号并执行新的prepare阶段
至此,没有提案被通过,但是服务器的资源一直被消耗,这就是活锁。
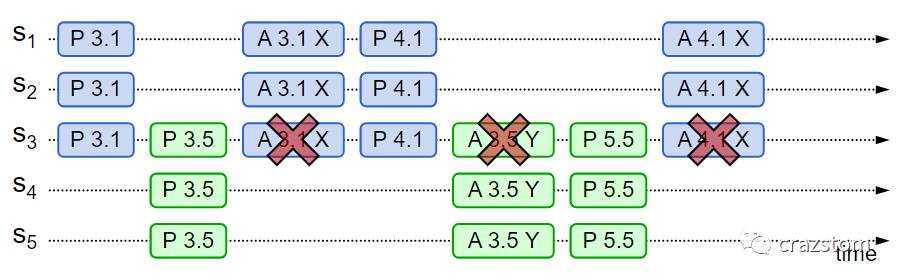
以上就是活锁产生的情形。
为了防止活锁,必须选出一个且只能有一个proposer来发布提案。如果这个proposer可以和大多数acceptor通信,而且使用的提案编号比之前通过的提案编号都大,那么这个提案通过。如果proposer发现有更高编号的proposer,它会放弃现在的提案,然后提出更高编号的提案。
这个proposer就称为leader,这也是Multi-Paxos使用的方法。
1.3.5. 提案编号
每个提案的编号都是独一无二的。编号高的提案的优先级要比编号低的提案的优先级高。proposer在提出新提案时,他必须选择一个比之前提案都高的编号。
一种生成提案编号的方法如下:

每个服务器都保存它看到过的最大轮次数(Round Number)。
一个新的提案编号就是将最大轮次数自增,然后和服务器的ID连接。例如,"P 2.1"表示编号为2.1的prepare过程;其中轮次数是2,服务器ID是1。"A 3.1 X"则是编号为3.1,内容为X的提案的accept过程。
proposer必须将轮次数保存在磁盘上;而且每次失败重启之后不能使用之前保存的编号。
1.4. Paxos prepare阶段可能出现的情况
1.4.1 proposer中没有之前通过的提案内容
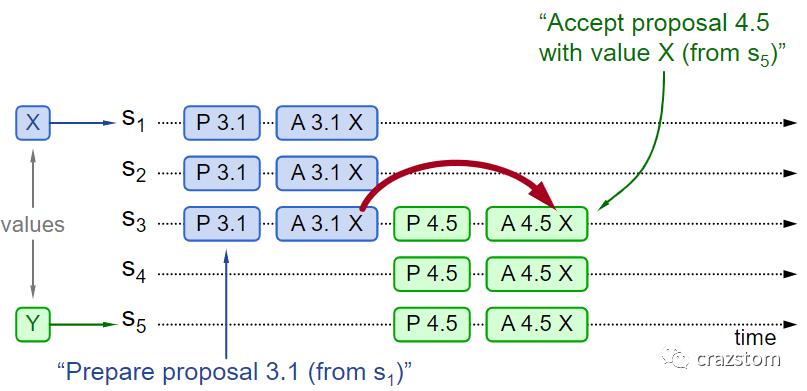
S1使用3.1作为编号,X作为内容提出提案,然后被通过并且S3学习到了该提案
S5使用4.5作为编号进行新一轮的提案,S5计划使用Y作为提案内容的,但是在S3回复prepare请求"P 4.5"的内容中有X,所以S5就将X设置为4.5的提案内容,发出accept请求
之后S1~S5都学习到X,即各个服务器中都有相同的条目
1.4.2. 之前的提案内容没有通过,但是新proposer发现了
S1首先提出了3.1的提案,S3首先接受并记录了3.1提案;S2可能有网络延迟,导致下一个新提案的prepare阶段完成还没有结束3.1的accept阶段
S5使用4.5作为编号开始新一轮的提案,S5从S3的prepare回复中发现了X,就把X作为本次提案的内容,之后执行accept阶段
而在此时,S1和S2也接受了3.1提案,这样所有的服务器中都有X

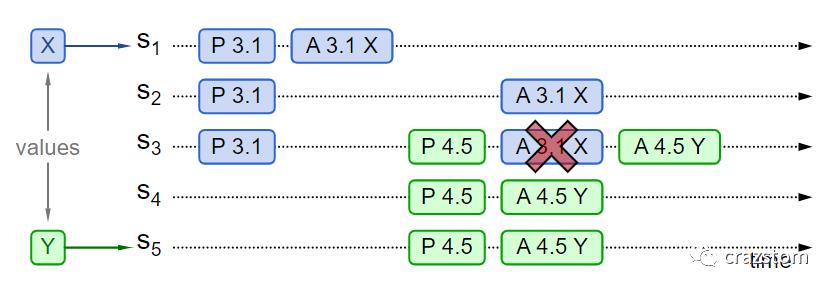
1.4.3. 之前的提案内容没有通过,新proposer没发现
S1开始3.1的prepare阶段
S1开始3.1的accept阶段,只有S1中有X,其他的acceptor因为网络的延迟没有接受该提案
S5开始4.5的prepare阶段,S3不会再接受4.5以下的accept请求
3.1的accept请求到达S3,S3因为之前承诺过,所以会忽略掉这个请求
S1、S2中有X,而S3、S4和S5中有Y
2. Multi-Paxos
在Multi-Paxos中,每一条日志都是Basic Paxos中的一个实例。在每个prepare和accept请求中都增加一个索引,用来选择特定的日志条目,所有的服务器日志里的每条日志都是独立的状态。
2.1. 日志内容选择
当新的客户端指令发送到服务器时:
寻找第一条没有被选中的日志(该日志中没有提案或者提案还没有通过)
执行Paxos算法以该条目索引为编号提出提案
之后通过的提案内容就是该条目日志选择的内容,如果:
选择了服务器中存在的指令,即该提案编号以下的最大未通过提案指令,就从步骤一重新开始
否则就选择该客户端的请求指令
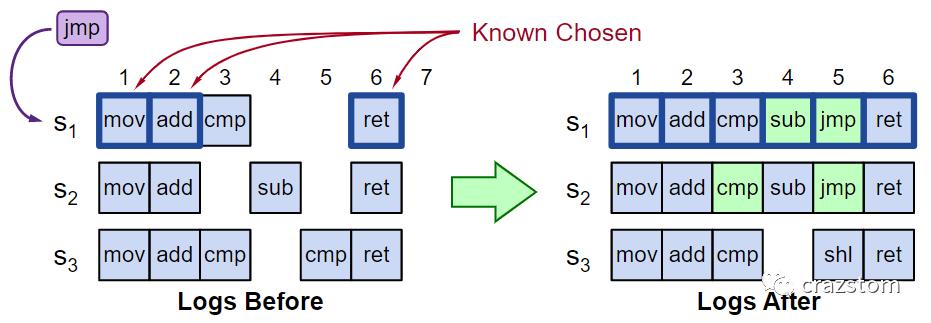
如上图所示,S1是proposer,同时S1和S2也是acceptor,这也占了大多数的acceptor,所以S3的日志变化在此次分析中忽略:
有一条新的客户端指令"jmp"到达S1
已知日志1和日志2已经被选中了,其中的指令已经在Paxos算法中作为提案的内容通过
S1查看日志3,以"cmp"为提案内容执行Paxos算法,通过的提案内容是该处已存在的指令"cmp"。此时日志3也被选中了。
S1继续查看日志4,在Paxos算法中,S2在S1的prepare请求中返回了它的"sub"指令,这样S1就将"sub"作为提案内容执行accept阶段。最后,"sub"提案通过,日志4存放的内容就是"sub"。
S1继续查看日志5,在Paxos算法中,S2在S1的prepare请求中没有返回任何内容,这样S1就可以把"jmp"作为提案内容。最后提案通过,日志5就选中了"jmp"作为其内容。
S1继续扫描,日志6已经被选中了
那么下一条客户端指令将被日志8选中而存放在该位置处
服务器在为日志选择了指令之后,这些指令必须按照在日志中的顺序应用到状态机中。
Paxos可以同时提起多个prepare请求,所以服务器也可以并发得处理多个客户端的请求,并为每个客户端指令选择不同的日志条目。
2.2. 性能优化
Basic Paxos效率很低,因为:
同时存在多个proposer,存在提案内容冲突等情况
通过一个提案需要两个来回的rpc调用(prepare阶段和accept阶段)
解决方案:
选举leader:无论任何时候,只有一个服务器是proposer
压缩prepare过程的rpc:
一次让所有的日志执行prepare阶段(并不是一条日志执行一次)
大部分的日志条目在一个来回的rpc调用中就可以确定
2.2.1. leader选举
每个服务器一个ID,让ID最大的服务器当leader
服务器之间通过T ms的心跳来维持联系
如果2T ms时间后,服务器A没有收到比他ID更高的服务器的心跳信息,它就可以当leader。任务是响应客户端的请求,扮演proposer、acceptor和learner的角色
如果服务器不是leader,它会将客户端的请求忽略掉或者重定向给leader;同时它只是acceptor和learner。
2.2.2. 压缩prepare请求
压缩prepare请求可以减少rpc调用的次数。
prepare阶段的作用:
阻止之前的提案,通过改变提案编号的含义来解决这个问题。提议编号被全局化,表示所有的日志,而不是为每个日志记录都保留独立的提案编号。这样的话就只需要一次prepare请求就可以prepare所有的日志了。
获得acceptor保存的可能被选中的提案内容。对当前的preapre(n)中的提案编号,acceptor会返回其收到过的n以下最大编号的提案。其次,acceptor还会检查n以后的日志,如果之后的日志都没有通过任何提案,说明之后的日志都是空的,即可用的,acceptor就会在回复prepare(n)时携带一个noMoreAccepted。
如果使用了选举leader的机制,最终leader会收到大部分acceptor返回的noMoreAccepted。这表示这些acceptor在n号日志之后的内容都是空的,leader不需要再发送多余的prepare请求了。
2.3. 日志全复制
在Basic Paxos中,日志并没有完整的复制到所有的服务器:
只有大多数的服务器中有通过的日志
当日志被选中时,只有proposer知道
解决方案:
proposer在后台一直重发accept请求,直到所有的acceptor都回应。
大部分的日志可以完全复制
记录选中的日志
使用已知被选中的日志i,并记录acceptedProposal[i]=∞
每个服务器都维持一个firstUnchosenIndex:没有被选中的最早的日志索引
proposer告诉acceptor哪些日志被选中

但是还是没有实现完全的复制
proposer在accept请求中携带它的firstUnchosenIndex
acceptor把日志i记录为被选中,前提是:i<accept请求中的firstUnchosenIndex而且acceptor中维持的acceptedProposal[i]==请求中携带的提案内容
结果就是:acceptor已经学习了大部分被选择的日志
上任leader的日志
Success(index,v):通知acceptor已经选择的条目:
Success调用包括两个参数,日志记录的下标位置及日志内容。这条消息可以让某一特定位置的日志被选定,不会再存在未知的情况,所以acceptor只要将这个信息从消息中提取并更新它自己的日志记录即可,然后返回它更新的 firstUnchosenIndex ,因为可能存在有多个未知状态的情况,所以 proposer 会发送多个 RPC 请求,直到最后acceptor与 proposer的日志状态达成一致。
acceptedValue[index]=v
acceptedProposal[index]=∞
返回acceptor的firstUnchosenIndex
acceptor在accept请求的回复中携带它的firstUnchosenIndex
如果propsoer.firstUnchosenIndex>回复中的firstUnchosenIndex,表明acceptor中的某些状态是不确定的,proposer会在后台发送Success rpc调用。
2.4. 客户端协议
客户端发送指令给leader:
如果leader未知,就联系任意一个服务器
如果联系的服务器不是leader,服务器会将请求重定向给leader
直到客户端指令被选中为leader的日志条目(被复制到所有的服务器中)而且由leader的状态机执行完毕(所有的服务器状态机都会执行),leader才会回复客户端,并携带状态机执行产生的输出。
如果客户端的请求超时了(leader宕机):
客户端给其他的服务器重发指令请求
请求最终重定向给一个新的leader
客户端最终向新的leader发请求
如果leader宕机了,而此时它执行完了指令但是没有回应:
leader不能重复执行这个指令
解决方案:客户端在指令中附带一个独特的id
服务器将id包括在日志内容中
状态机记录最近执行的指令
状态机在执行指令的时候,首先检查这个指令是否执行过,如果执行过,就忽略这个指令同时返回之前执行相同指令产生的输出。
2.5. 配置变更
分布式系统中的配置包括:
仲裁过程:多少服务器表示大多数
共识机制必须支持系统配置的变化,例如:替换宕机的机器;调整仲裁的规模,比如将5台改变为7台机器为大多数。
在配置变更的时候,不同的多数服务器集合必须使用相同的配置,下图的情况是不允许的。
Paxos提出的解决方案:使用日志来管理配置变更
配置以日志的形式储存在每个服务器中
配置和其他的客户端指令一样复制到所有的服务器
假设α=3;服务器在执行第i条日志的时候使用第i-α条配置日志
上图是记录配置的日志,可以把这个日志和客户端指令的日志分开。
当服务器执行到第一条日志时,服务器会使用C0配置;当执行到第4条日志的时候,服务器发现在1位置处有C1,所以服务器就开始使用C1配置了。
α限制了并发度:只有条目i日志被选中了,才能选择条目i+α
如果想快速完成配置变更,可以发出"noop"指令,详情见Paxos论文描述。
总结
Basic Paxos主要阐述了prepare和accept两个阶段以及在这两个阶段中proposer和acceptor的行为。
更细节的事情都是由Multi-Paxos来完成的,例如提高效率、日志完整性复制等。
其实这些内容在Paxos论文中都详细描述了。至此,笔者还是建议同学将本文搭配Paxos论文一起学习,这样才了解的更透彻;更进一步的话,有余力的同学可以实现一下Paxos算法。笔者下一步就是实现Raft算法,敬请期待。
以上是关于分布式算法:还不懂Paxos?Paxos和Multi-Paxos详解的主要内容,如果未能解决你的问题,请参考以下文章