分布式算法 Paxos 的直观解释 (TL;DR)
Posted 高可用架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式算法 Paxos 的直观解释 (TL;DR)相关的知识,希望对你有一定的参考价值。
前言
paxos是什么?
在分布式系统中保证多副本数据强一致的算法.
paxos有啥用?
没有paxos的一堆机器, 叫做分布式;
有paxos协同的一堆机器, 叫分布式系统.
Google Chubby的作者Mike Burrows说过:
这个世界上只有一种一致性算法,那就是Paxos …
其他一致性算法, 都可以看做paxos在实现中的变体和扩展.
另外一个经常被提及的分布式算法是[raft], raft的贡献在于把一致性算法落地. 因为 [Leslie Lamport] 的理论很抽象, 要想把他的理论应用到现实中, 还需要工程师完全掌握他的理论再添加工程必要的环节才能跑起来.
经常有人问起raft和paxos的区别, 或在实现中应该选择哪个, 在不了解paxos之前可能会有这种疑问. 对于这个问题, 就像是被问及四则运算和算盘有什么区别, 小店老板应该使用四则运算还是用算盘结账一样.
记得 Leslie Lamport 2015年时来了一次北京, 那时会场上有人也问了老爷子 paxos和raft有啥区别.
老爷子当时给出的回答是: 没听过raft…
raft的核心可以认为是multi paxos的一个应用, 对于要掌握一致性算法的核心内容, 从paxos入手, 更容易去掉无关干扰, 直达问题本质. 所以我们选择paxos作为了解一致性算法的入口, 聊开了聊透了.
网络上raft比paxos流行, 因为raft的描述更直白一些, 实际上raft比paxos更复杂. raft详细的解释了”HOW”, 缺少”WHY”的解释. paxos从根本上解释清楚了”WHY”, 但一直缺少一份通俗易懂的教程. 以至于没有被更广泛的接受. 所以就有了本文, 一篇paxos入门教程, 从基本的分布式中的复制的问题出发, 通过逐步解决和完善这几个问题, 最后推导出paxos的算法.
本文分为2个部分:
前1部分是分布式一致性问题的讨论和解决方案的逐步完善, 用人话得出paxos算法的过程. 如果只希望理解paxos而不打算花太多时间深入细节, 只阅读这1部分就可以啦.
第2部分是paxos算法和协议的严格描述. 这部分可以作为paxos原paper的实现部分的概括. 如果你打算实现自己的paxos或类似协议, 需要仔细了解协议细节, 希望这部分内容可以帮你节省阅读原paper的时间.
图片是xp之前做过的paxos分享使用的slides, 在此基础上加入了更多口头解释的内容.
分布式系统要解决的问题
slide-00
slide-01
paxos的工作, 就是把一堆运行的机器协同起来, 让多个机器成为一个整体系统. 在这个系统中, 每个机器都必须让系统中的状态达成一致, 例如三副本集群如果一个机器上上传了一张图片, 那么另外2台机器上也必须复制这张图片过来, 整个系统才处于一个一致的状态.

slide-02
我是无需解释的目录页. 
slide-03
分布式系统的一致性问题最终都归结为分布式存储的一致性. 像aws的对象存储可靠性要求是9~13个9. 而这么高的可靠性都是建立在可靠性没那么高的硬件上的.

slide-04
几乎所有的分布式存储(甚至单机系统, 参考[EC第一篇:原理], [EC第二篇:实现], [EC第三篇:极限]) 都必须用某种冗余的方式在廉价硬件的基础上搭建高可靠的存储. 而冗余的基础就是多副本策略, 一份数据存多份. 多副本保证了可靠性, 而副本之间的一致, 就需要paxos这类分布式一致性算法来保证.
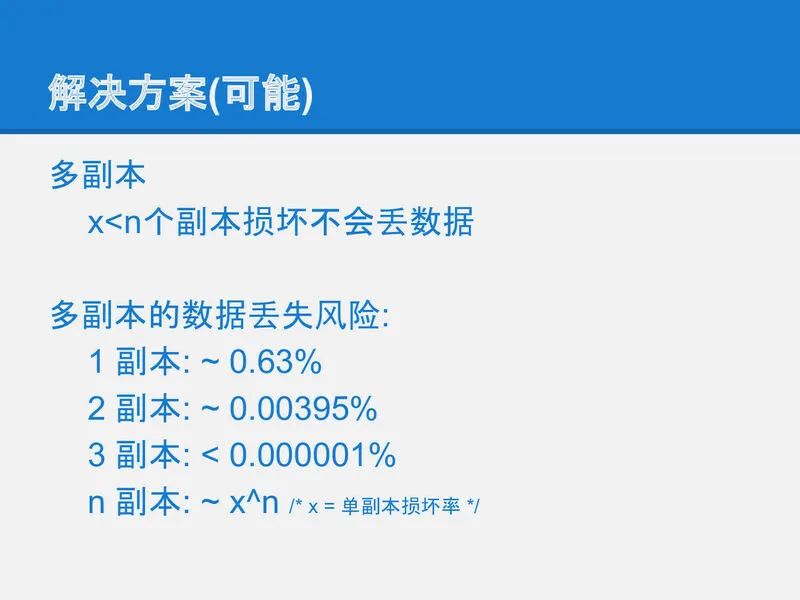
slide-05
在早些年各种各样的复制策略都被提出来来解决各种场景下的需要. 除了复制的份数之外, 各种各样的算法实际上都是在尝试解决一致的问题. 从下一页开始简单回顾下各种复制策略, 看看他们的优缺点以及paxos如何解决副本之间一致性的问题.
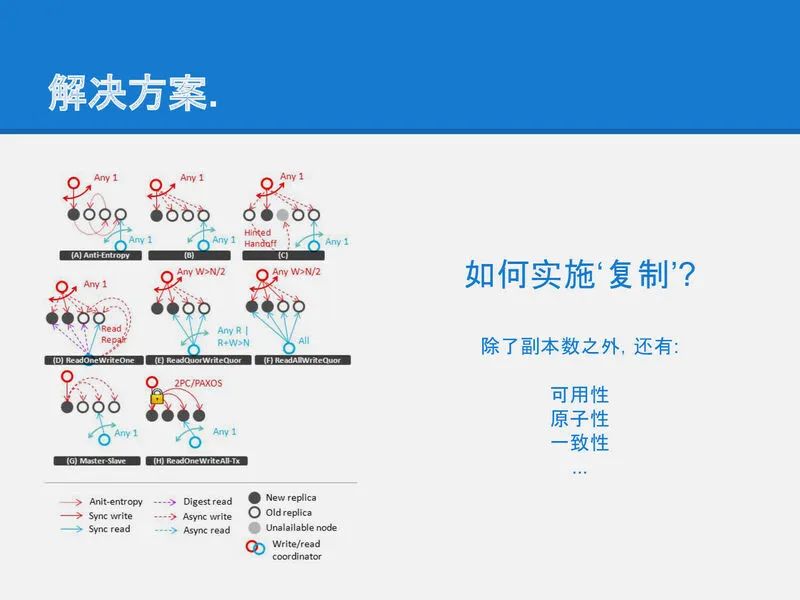
不太完美的复制策略
slide-06
无需解释的目录页 
slide-07
主从异步复制是最简单的策略之一, 它很容易实现, 但存在一个问题: 客户端收到一个数据已经安全(OK)的信息, 跟数据真正安全(数据复制到全部的机器上)在时间上有一个空隙, 这段时间负责接收客户端请求的那个机器(master)如果被闪电击中或被陨石砸到或被打扫卫生的大姐踢断了电源, 那数据就可能会丢失. 因此它不是一个可靠的复制策略(使用主从异步复制要求你必须相信宇宙中不存在闪电陨石和扫地大姐).
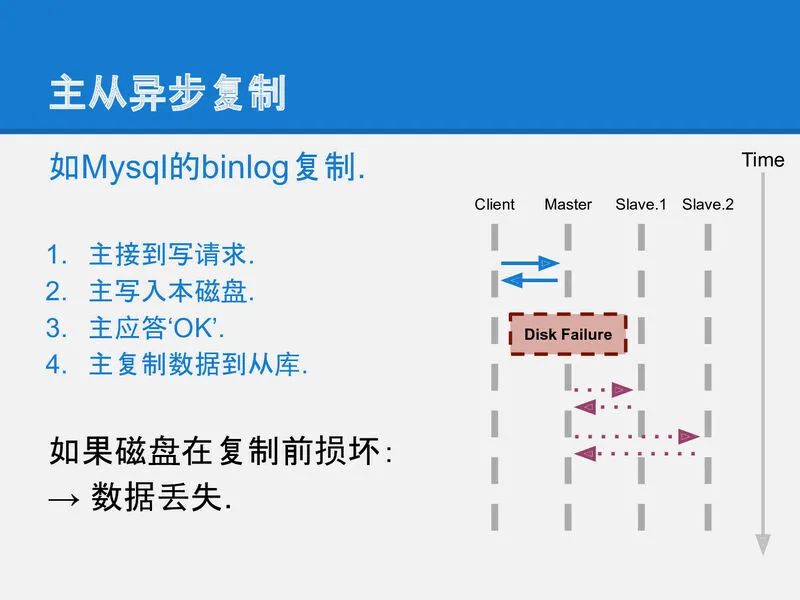
slide-08
跟主从异步复制相比, 主从同步复制提供了完整的可靠性: 直到数据真的安全的复制到全部的机器上之后, master才告知客户端数据已经安全.
但主从同步复制有个致命的缺点就是整个系统中有任何一个机器宕机, 写入就进行不下去了. 相当于系统的可用性随着副本数量指数降低.
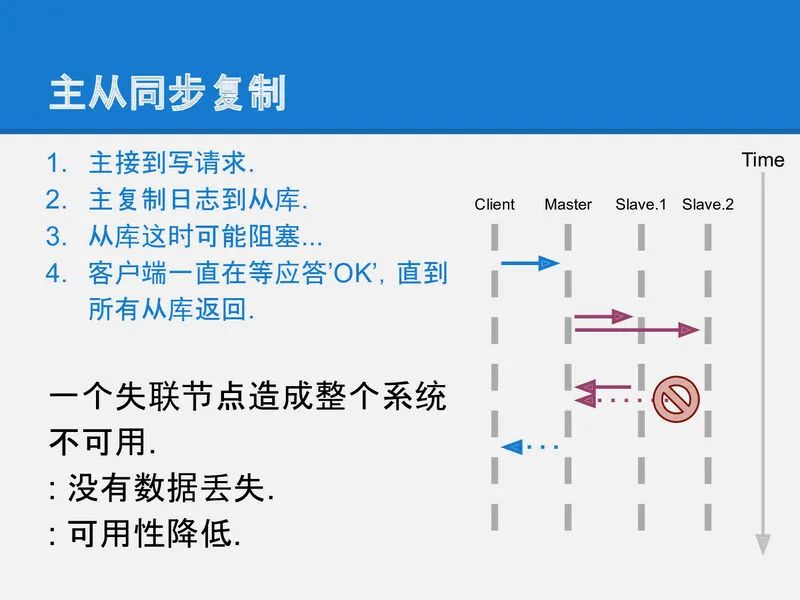
slide-09
然鹅, 在同步和异步之间, 做一个折中, 看起来是一个不错的方案. 这就是半同步复制. 它要求master在应答客户端之前必须把数据复制到足够多的机器上, 但不需要是全部. 这样副本数够多可以提供比较高的可靠性; 1台机器宕机也不会让整个系统停止写入.
但是它还是不完美, 例如数据a复制到slave-1, 但没有到达slave-2; 数据b复制达到了slave-2但没有到达slave-1, 这时如果master挂掉了需要从某个slave恢复出数据, 任何一个slave都不能提供完整的数据. 所以在整个系统中, 数据存在某种不一致.
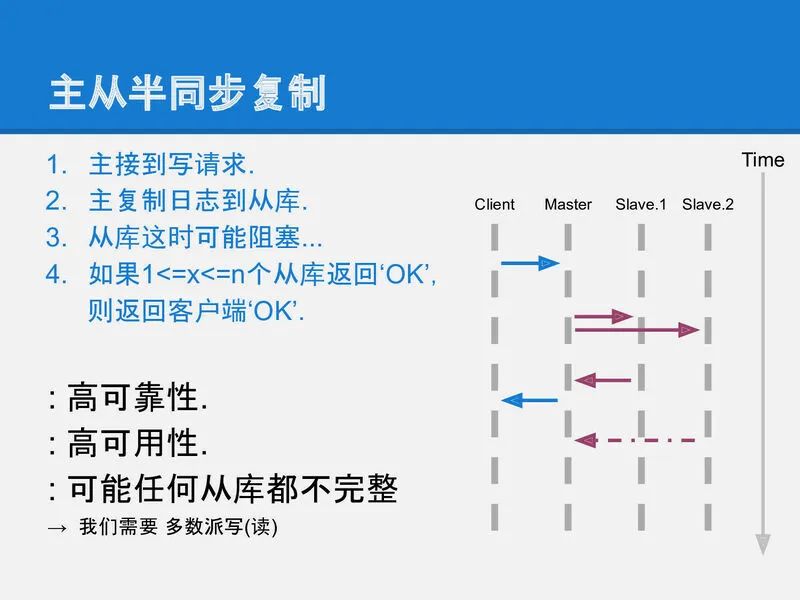
slide-10
为了解决半同步复制中数据不一致的问题, 可以将这个复制策略再做一改进: 多数派读写: 每条数据必须写入到半数以上的机器上. 每次读取数据都必须检查半数以上的机器上是否有这条数据.
在这种策略下, 数据可靠性足够, 宕机容忍足够, 任一机器故障也能读到全部数据.
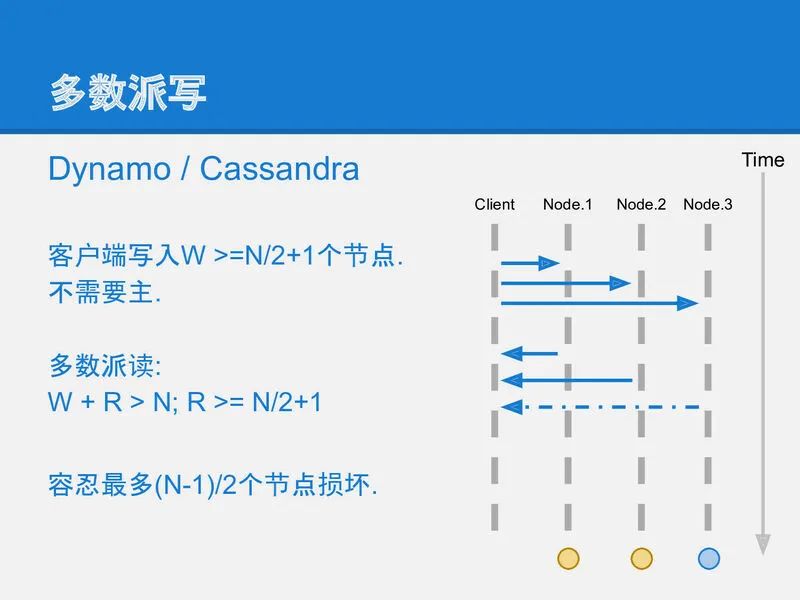
slide-11
然鹅多数派读写的策略也有个但是, 就是对于一条数据的更新时, 会产生不一致的状态. 例如:
node-1, node-2都写入了a=x,
下一次更新时node-2, node-3写入了a=y.
这时, 一个要进行读取a的客户端如果联系到了node-1和node-2, 它将看到2条不同的数据.
为了不产生歧义, 多数派读写还必须给每笔写入增加一个全局递增的时间戳. 更大时间戳的记录如果被看见, 就应该忽略小时间戳的记录. 这样在读取过程中, 客户端就会看到a=x₁, a=y₂ 这2条数据, 通过比较时间戳1和2, 发现y是更新的数据, 所以忽略a=x₁. 这样保证多次更新一条数据不产生歧义.
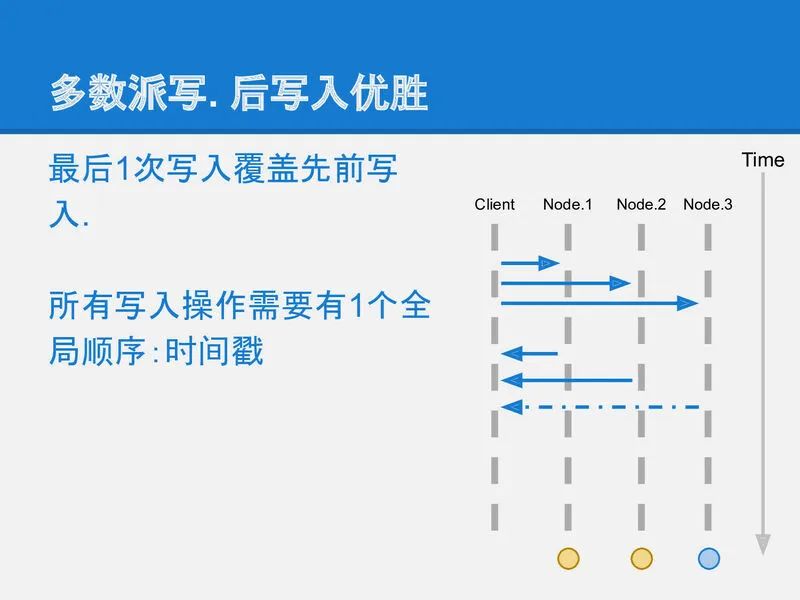
slide-12
是的, 但是又来了. 这种带时间戳的多数派读写依然有问题. 就是在客户端没有完成一次完整的多数派写的时候: 例如, 上面的例子中写入, a=x₁写入了node-1和node-2, a=y₂时只有node-3 写成功了, 然后客户端进程就挂掉了, 留下系统中的状态如下:
node-1: a=x₁
node-2: a=x₁
node-3: a=y₂
这时另一个读取的客户端来了,
如果它联系到node-1和node-2, 那它得到的结果是a=x₁.
如果它联系到node-2和node-3, 那它得到的结果是a=y₂.
整个系统对外部提供的信息仍然是不一致的.

slide-13
现在我们已经非常接近最终奥义了, paxos可以认为是多数派读写的进一步升级, paxos中通过2次原本并不严谨的多数派读写, 实现了严谨的强一致consensus算法.

从多数派读写到paxos的推导
slide-14
首先为了清晰的呈现出分布式系统中的核心问题: 一致性问题, 我们先设定一个假象的存储系统, 在这个系统上, 我们来逐步实现一个强一致的存储, 就得到了paxos对一致性问题的解决方法.

slide-15
在实现中, set命令直接实现为一个多数派写, 这一步非常简单. 而inc操作逻辑上也很简单, 读取一个变量的值i₁, 给它加上一个数字得到i₂, 再通过多数派把i₂写回到系统中.

slide-16
冰雪如你一定已经看到了这种实现方式中的问题: 如果有2个并发的客户端进程同时做这个inc的操作, 在多数派读写的实现中, 必然会产生一个Y客户端覆盖X客户端的问题. 从而产生了数据更新点的丢失.
而paxos就是为了解决这类问题提出的, 它需要让Y能检测到这种并发冲突, 进而采取措施避免更新丢失.
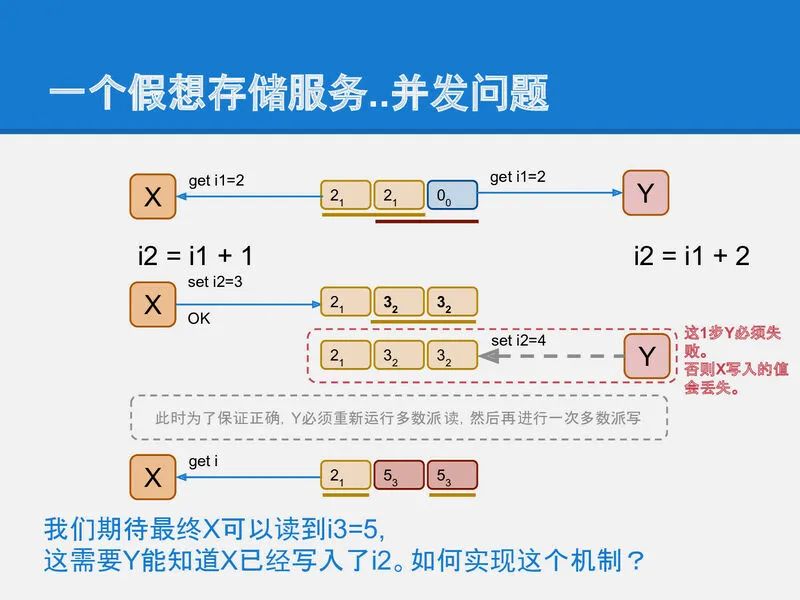
slide-17
提取一下上面提到的问题: 让Y去更新的时候不能直接更新i₂, 而是应该能检测到i₂的存在, 进而将自己的结果保存在下一个版本i₃中, 再写回系统中.
而这个问题可以转化成: i的每个版本只能被写入一次, 不允许修改. 如果系统设计能满足这个要求, 那么X和Y的inc操作就都可以正确被执行了.

slide-18
于是我们的问题就转化成一个更简单, 更基础的问题: 如何确定一个值(例如iⱼ)已经被写入了.
直观来看, 解决方法也很简单, 在X或Y写之前先做一次多数派读, 以便确认是否有其他客户端进程已经在写了, 如果有, 则放弃.
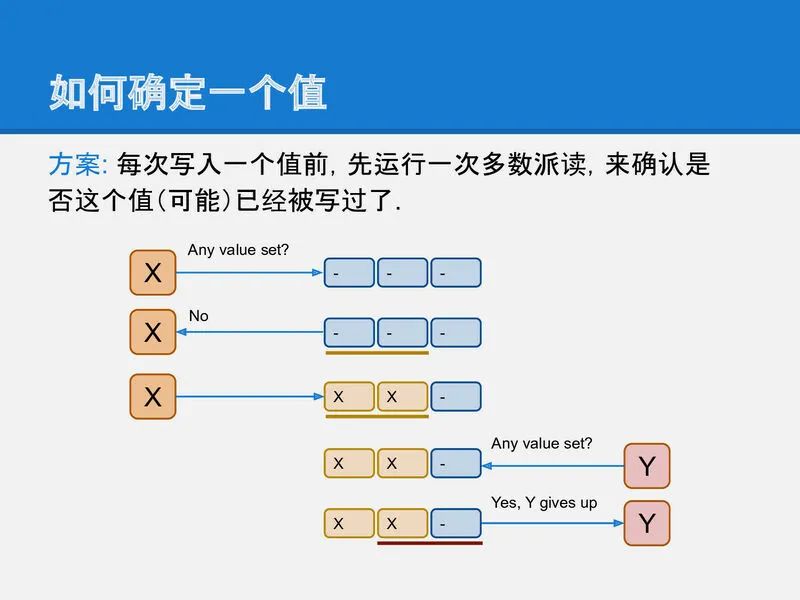
slide-19
但是!!!, 这里还有个并发问题, X和Y可能同时做这个写前读取的操作, 并且同时得出一个结论: 还没有其他进程在写入, 我可以写. 这样还是会造成更新丢失的问题.
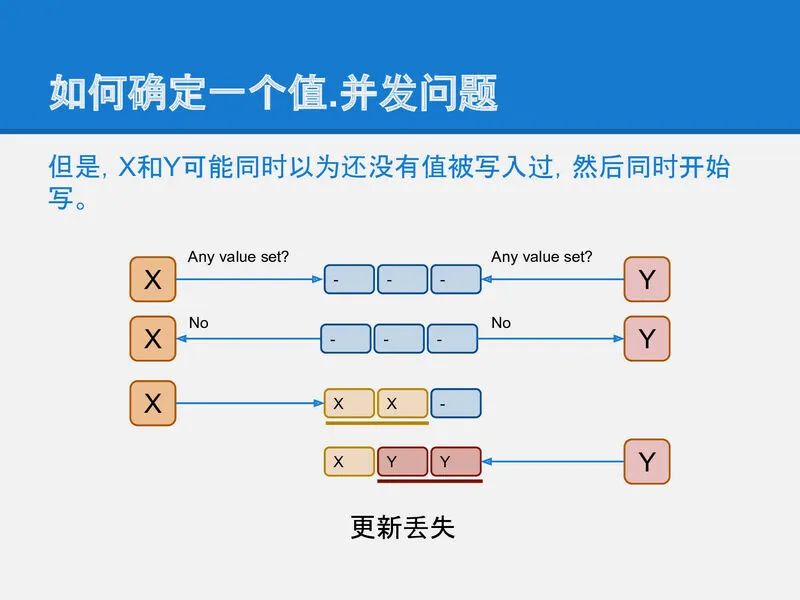
slide-20
为了解决上面的问题, 存储节点还需要增加一个功能, 就是它必须记住谁最后一个做过写前读取的操作. 并且只允许最后一个完成写前读取的进程可以进行后续写入, 同时拒绝之前做过写前读取的进程写入的权限.
可以看到, 如果每个节点都记得谁读过, 那么当Y最后完成了写前读取的操作后, 整个系统就可以阻止过期的X的写入.
这个方法之所以能工作也是因为多数派写中, 一个系统最多只能允许一个多数派写成功. paxos也是通过2次多数派读写来实现的强一致.
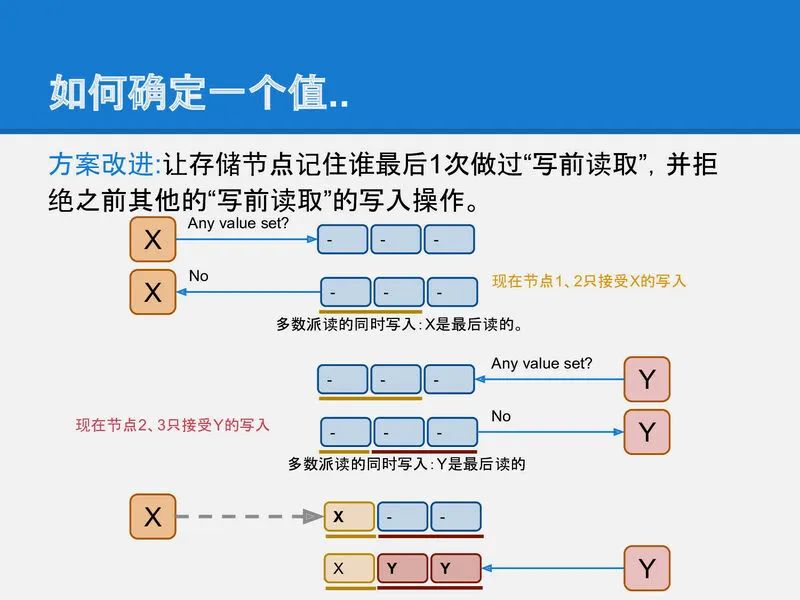
slide-21
以上就是paxos算法的全部核心思想了, 是不是很简单? 剩下的就是如何实现的简单问题了: 如何标识一个客户端如X和Y, 如何确认谁是最后一个完成写前读写的进程, 等等.

slide-22
[Leslie Lamport] 就这么把这么简单的一个算法写了个paper就获得了图领奖! 骚年, 改变世界就这么容易!

paxos算法描述
接下来的篇幅中我们将用计算机的语言准确的描述整个paxos运行的过程.
slide-23
首先明确要解决的问题:

slide-24
我们要介绍的paxos实际上是最朴实的classic paxos, 在这之后我们顺提下几个老爷子对paxos的优化, multi paxso和fast paxos, 它们都是针对paxos的理论层面的优化.

slide-25
paxos算法中解决了如何在不可靠硬件基础上构建一个可靠的分布式系统的方法. 但paxos核心算法中只解决网络延迟/乱序的问题, 它不试图解决存储不可靠和消息错误的问题, 因为这两类问题本质上跟分布式关系不大, 属于数据校验层面的事情.
有兴趣可以参考 [Byzantine Paxos] 的介绍.

slide-26
本文尽量按照 [Classic Paxos] 的术语来描述,
老爷子后面的一篇 [Fast Paxos] 实现了fast-paxos, 同时包含了classic-paxos, 但使用了一些不同的术语表示.
Proposer 可以理解为客户端.
Acceptor 可以理解为存储节点.
Quorum 在99%的场景里都是指多数派, 也就是半数以上的Acceptor.
Round 用来标识一次paxos算法实例, 每个round是2次多数派读写: 算法描述里分别用phase-1和phase-2标识. 同时为了简单和明确, 算法中也规定了每个Proposer都必须生成全局单调递增的round, 这样round既能用来区分先后也能用来区分不同的Proposer(客户端).

slide-27
在存储端(Acceptor)也有几个概念:
last_rnd 是Acceptor记住的最后一次进行写前读取的Proposer(客户端)是谁, 以此来决定谁可以在后面真正把一个值写到存储中.
v 是最后被写入的值.
vrnd 跟v是一对, 它记录了在哪个Round中v被写入了.
v和vrnd是用于恢复一次未完成的paxos用的. 一次未完成的paxos算法运行可能留下一些没有达到多数派的值的写入(就像原生的多数派写的脏读的问题), paxos中通过vrnd来决定哪些值是最后写入的, 并决定恢复哪个未完成的paxos运行. 后面我们会通过几个例子来描述vrnd的作用.

slide-28
首先是paxos的phase-1, 它相当于之前提到的写前读取过程. 它用来在存储节点(Acceptor)上记录一个标识: 我后面要写入; 并从Acceptor上读出是否有之前未完成的paxos运行. 如果有则尝试恢复它; 如果没有则继续做自己想做的事情.
我们用类似yaml的格式来描述phase-1的请求/应答的格式:
request:
rnd: int
response:
last_rnd: int
v: "xxx",
vrnd: int
phase-1成功后, acceptor应该记录X的rnd=1, 并返回自己之前保存的v和vrnd.
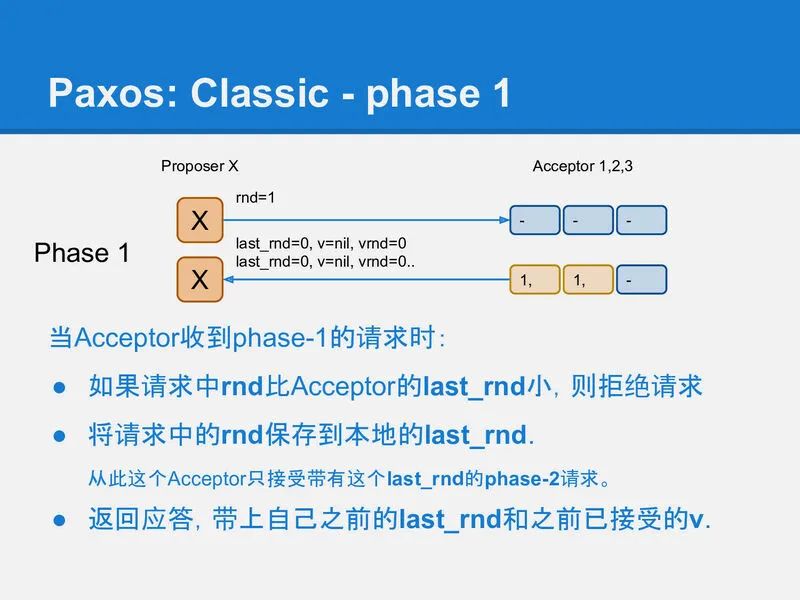
slide-29
Proposer X收到多数(quorum)个应答, 就认为是可以继续运行的.如果没有联系到多于半数的acceptor, 整个系统就hang住了, 这也是paxos声称的只能运行少于半数的节点失效.
这时Proposer面临2种情况:
所有应答中都没有任何非空的v, 这表示系统之前是干净的, 没有任何值已经被其他paxos客户端完成了写入(因为一个多数派读一定会看到一个多数派写的结果). 这时Proposer X继续将它要写的值在phase-2中真正写入到多于半数的Acceptor中.
如果收到了某个应答包含被写入的v和vrnd, 这时, Proposer X 必须假设有其他客户端(Proposer) 正在运行, 虽然X不知道对方是否已经成功结束, 但任何已经写入的值都不能被修改!, 所以X必须保持原有的值. 于是X将看到的最大vrnd对应的v作为X的phase-2将要写入的值.
这时实际上可以认为X执行了一次(不知是否已经中断的)其他客户端(Proposer)的修复.
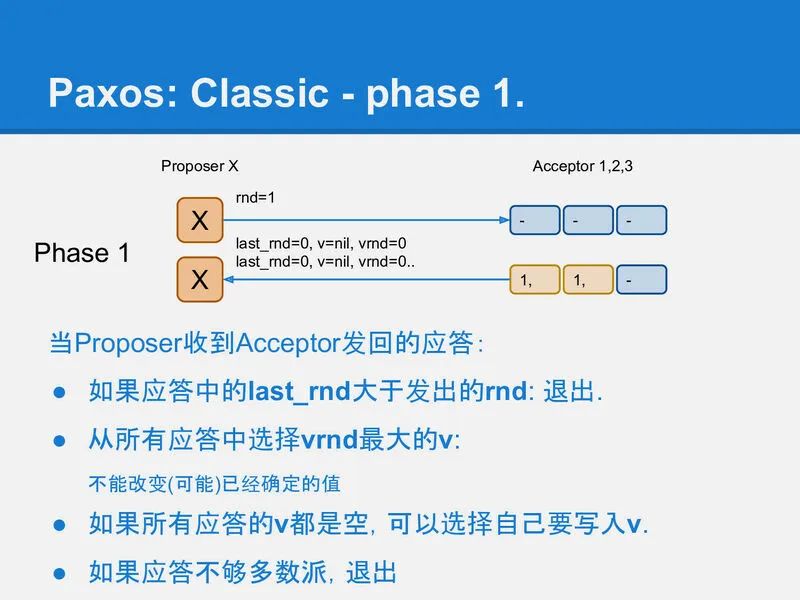
slide-30
在第2阶段phase-2, Proposer X将它选定的值写入到Acceptor中, 这个值可能是它自己要写入的值, 或者是它从某个Acceptor上读到的v(修复).
同样用类似yaml的方式描述请求应答:
request:
v: "xxx",
rnd: int
reponse:
ok: bool
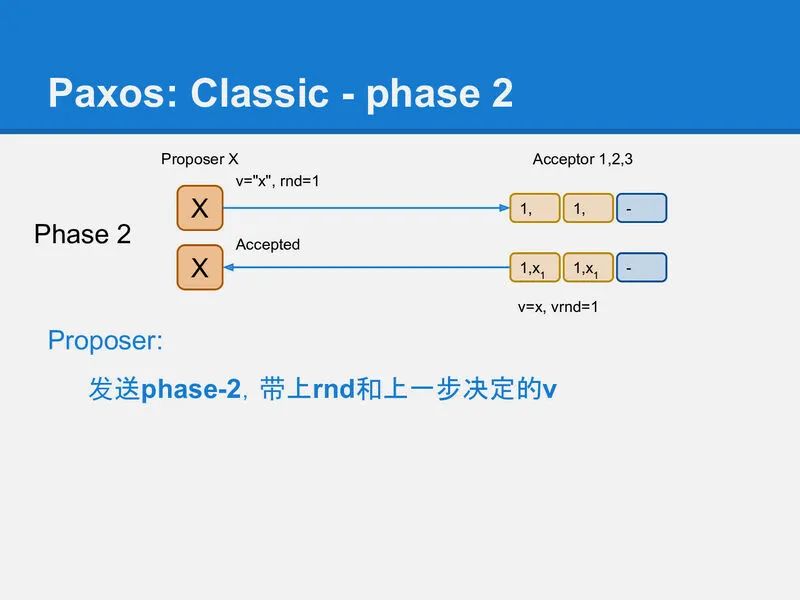
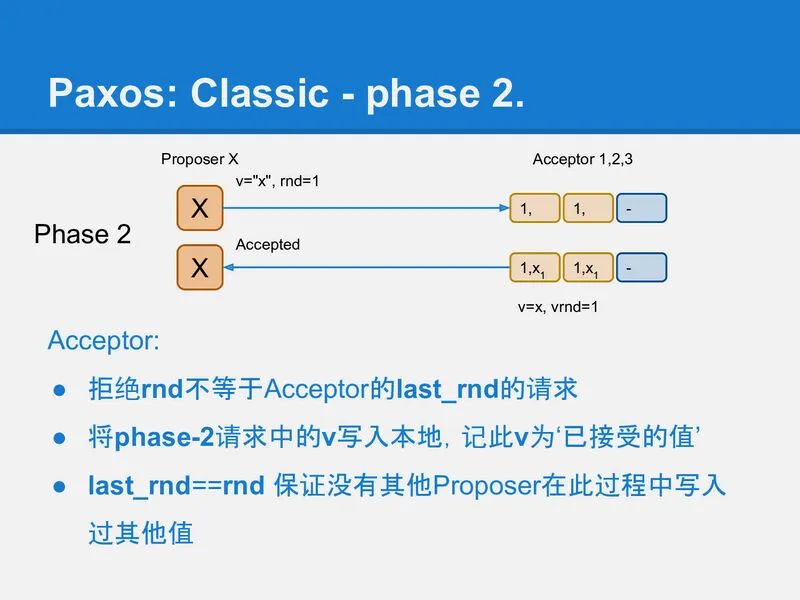
slide-31
当然这时(在X收到phase-1应答, 到发送phase-2请求的这段时间), 可能已经有其他Proposer又完成了一个rnd更大的phase-1, 所以这时X不一定能成功运行完phase-2.
Acceptor通过比较phase-2请求中的rnd, 和自己本地记录的rnd, 来确定X是否还有权写入. 如果请求中的rnd和Acceptor本地记录的rnd一样, 那么这次写入就是被允许的, Acceptor将v写入本地, 并将phase-2请求中的rnd记录到本地的vrnd中.
用例子看paxos运行
好了paxos的算法描述也介绍完了. 这些抽象的算法描述, 其中的规则覆盖了实际所有可能遇到的情况的处理方式. 一次不太容易看清楚它们的作用, 所以我们接下来通过几个例子来看看paxos如何处理各种不同状态并最终使整个系统的状态达成一致.
slide-32
没冲突的例子不解释了 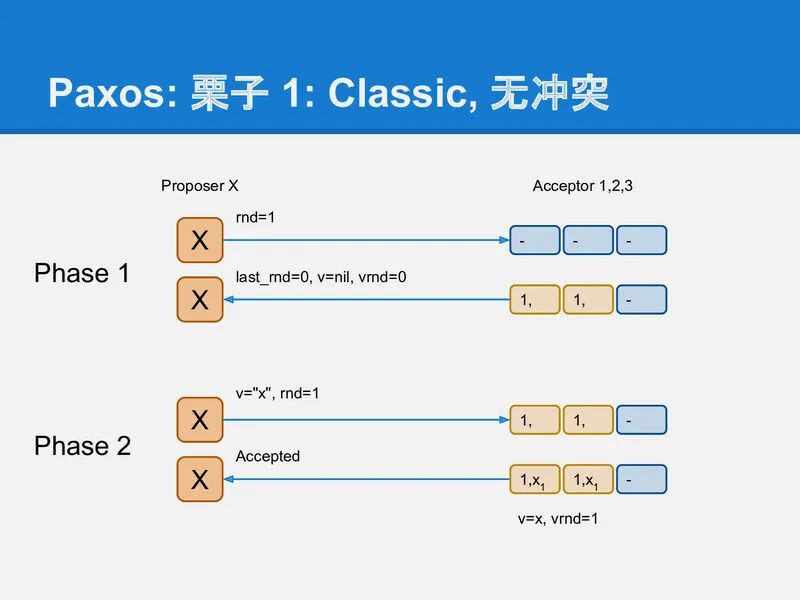
slide-33
X和Y同时运行paxos, Y迫使X中断的例子:
X成功完成了写前读取(phase-1), 将rnd=1写入到左边2个Acceptor.
Y用更大的rnd=2, 覆盖了X的rnd, 将rnd=2写入到右边2个Acceptor.
X以为自己还能运行phase-2, 但已经不行了, X只能对最左边的Acceptor成功运行phase-2, 而中间的Acceptor拒绝了X的phase-2.
Y对右边2个Acceptor成功运行了phase-2, 完成写入v=y, vrnd=2.
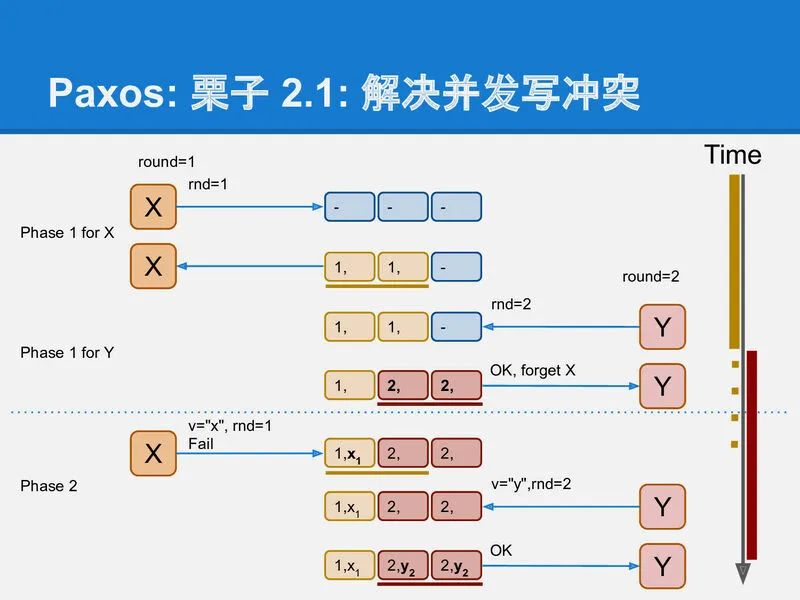
slide-34
继续上面的例子, 看X如何处理被抢走写入权的情况:
这时X的phase-2没成功, 它需要重新来一遍, 用更大的rnd=3.
X成功在左边2个Acceptor上运行phase-1之后, X发现了2个被写入的值: v=x, vrnd=1 和 v=y, vrnd=2; 这时X就不能再写入自己想要写入的值了. 它这次paxos运行必须不能修改已存在的值, 这次X的paxos的运行唯一能做的就是, 修复(可能)已经中断的其他proposer的运行.
这里v=y, vrnd=2 是可能在phase-2达到多数派的值. v=x, vrnd=1不可能是, 因为其他proposer也必须遵守算法约定, 如果v=x, vrnd=1在某个phase-2达到多数派了, Y一定能在phase-1中看到它, 从而不会写入v=y, vrnd=2.
因此这是X选择v=y, 并使用rnd=3继续运行, 最终把v=y, vrnd=3写入到所有Acceptor中.

slide-35
Paxos 还有一个不太重要的角色Learner, 是为了让系统完整加入的, 但并不是整个算法执行的关键角色, 只有在最后在被通知一下.

Paxos 优化
slide-36
第一个优化 multi-paxos:
paxos诞生之初为人诟病的一个方面就是每写入一个值就需要2轮rpc:phase-1和phase-2. 因此一个寻常的优化就是用一次rpc为多个paxos实例运行phase-1.
例如, Proposer X可以一次性为i₁~i₁₀这10个值, 运行phase-1, 例如为这10个paxos实例选择rnd为1001, 1002…1010. 这样就可以节省下9次rpc, 而所有的写入平均下来只需要1个rpc就可以完成了.
这么看起来就有点像raft了:
再加上commit概念(commit可以理解为: 值v送达到多数派这件事情是否送达到多数派了),
和组成员变更(将quorum的定义从”多于半数”扩展到”任意2个quourm必须有交集”).

slide-37
第二个优化 fast-paxos:
fast-paxos通过增加quorum的数量来达到一次rpc就能达成一致的目的. 如果fast-paxos没能在一次rpc达成一致, 则要退化到classic paxos.

slide-38
fast-paxos为了能在退化成classic paxos时不会选择不同的值, 就必须扩大quorum的值. 也就是说fast-round时, quorum的大小跟classic paxos的大小不一样. 同样我们先来看看为什么fast-quorum不能跟classic-quorum一样, 这样的配置会引起classic阶段回复时选择错误的值 y₀:
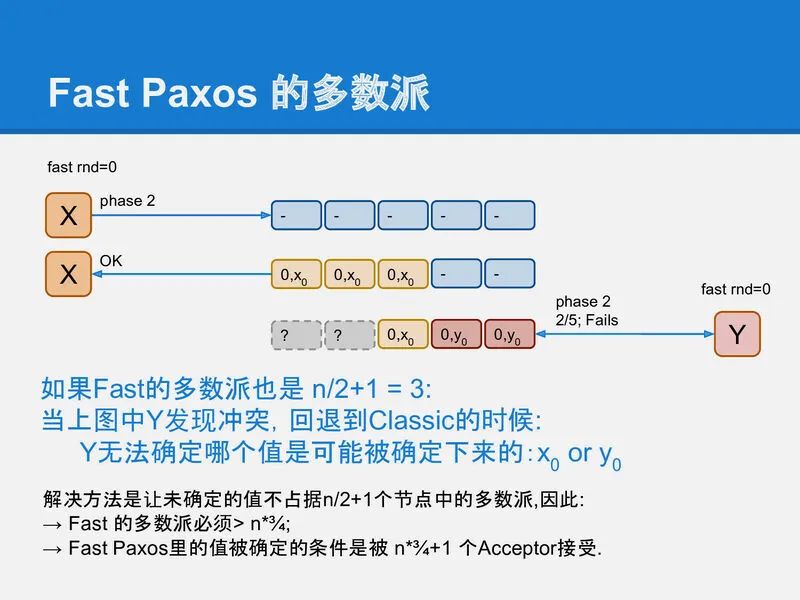
slide-39
要解决这个问题, 最粗暴的方法是把fast-quorum设置为n, 也就是全部的acceptor都写入成功才认为fast-round成功(实际上是退化到了主从同步复制). 这样, 如果X和Y两个proposer并发写入, 谁也不会成功, 因此X和Y都退化到classic paxos进行修复, 选任何值去修复都没问题. 因为之前没有Proposer认为自己成功写入了.
如果再把问题深入下, 可以得出, 如果classic paxos的quorum是n/2+1, 那么fast-round的quorum应该是大于¾n, ¾的由来可以简单理解为: 在最差情况下, 达到fast-quorum的acceptor在classic-quorum中必须大于半数, 才不会导致修复进程选择一个跟fast-round不同的值.

slide-40
下面是一个fast-round中X成功, Y失败的冲突的例子:
X已经成功写入到4(fast-quorum>¾n)个acceptor, Y只写入1个, 这时Y进入classic-round进行修复, 可以看到, 不论Y选择哪3(classic quorum)个acceptor, 都可以看到至少2个x₀, 因此Y总会选择跟X一样的值, 保证了写入的值就不会被修改的条件.
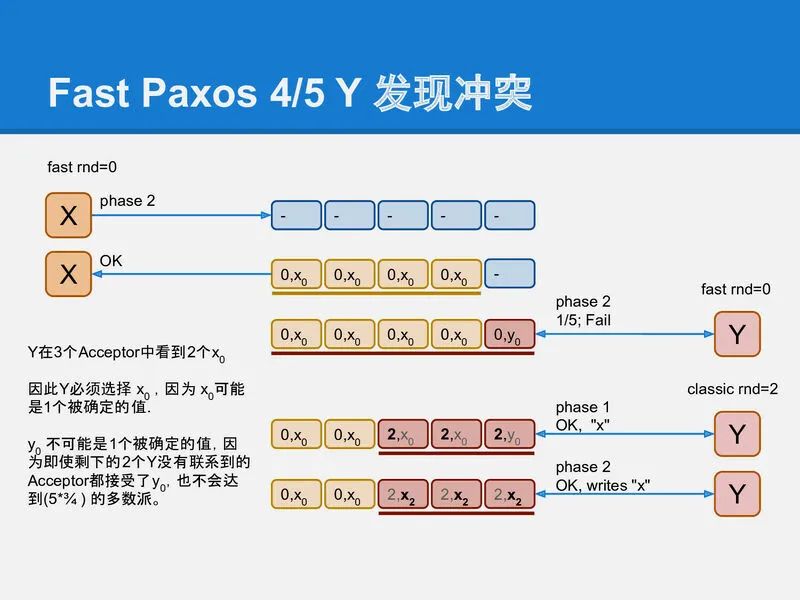
slide-41
再来看一个X和Y都没有达到fast-quorum的冲突:
这时X和Y都不会认为自己的fast-round成功了, 因此修复过程选择任何值都是可以的. 最终选择哪个值, 就回归到X和Y两个classic-paxos进程的竞争问题了. 最终会选择x₀或y₀中的一个.
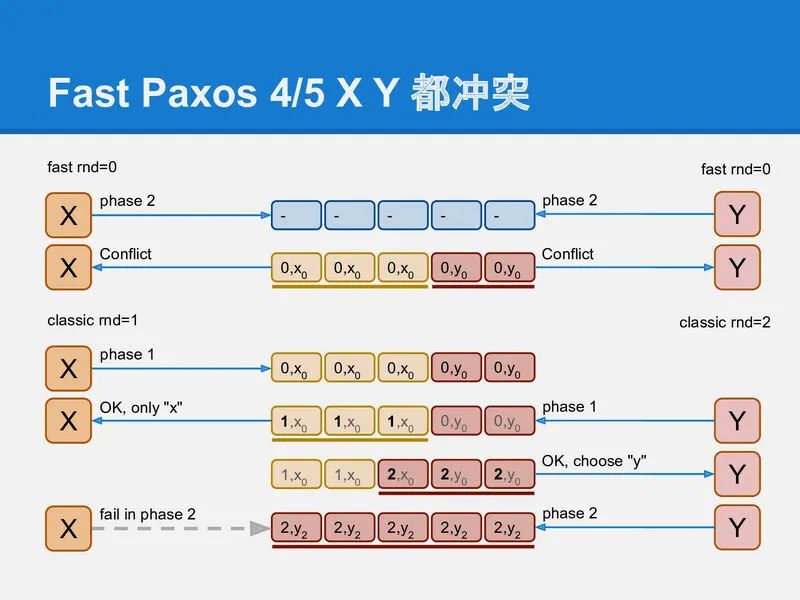
其他
slide-42
一个很容易验证的优化, 各种情况下都能得到一致的结果.

slide-43
广告页, 不解释了 
本次的 pdf 可以下载和在线看哦:
[可靠分布式系统-paxos的直观解释.pdf]
[可靠分布式系统-paxos的直观解释.html]
本文链接: [https://blog.openacid.com/algo/paxos/]
[可靠分布式系统-paxos的直观解释.pdf]: https://blog.openacid.com/post-res/paxos/可靠分布式系统-paxos的直观解释.pdf
[可靠分布式系统-paxos的直观解释.html]: https://blog.openacid.com/post-res/paxos/可靠分布式系统-paxos的直观解释.html
[raft]: https://raft.github.io/
[Leslie Lamport]: http://www.lamport.org/
[Byzantine Paxos]: https://en.wikipedia.org/wiki/Paxos_(computer_science)#Byzantine_Paxos
[Classic Paxos]: http://lamport.azurewebsites.net/pubs/pubs.html#paxos-simple
[Fast Paxos]: http://lamport.azurewebsites.net/pubs/pubs.html#fast-paxos
[EC第一篇:原理]: https://blog.openacid.com/storage/ec-1
[EC第二篇:实现]: https://blog.openacid.com/storage/ec-2
[EC第三篇:极限]: https://blog.openacid.com/storage/ec-3
长按二维码 关注「高可用架构」公众号
以上是关于分布式算法 Paxos 的直观解释 (TL;DR)的主要内容,如果未能解决你的问题,请参考以下文章