文本挖掘模型:本特征提取
Posted 大数据挖掘DT数据分析
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本挖掘模型:本特征提取相关的知识,希望对你有一定的参考价值。
数据挖掘资料,点击底部"阅读原文",手慢无
文本挖掘模型结构示意图
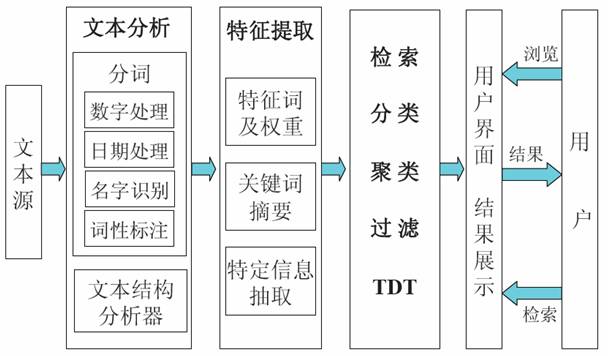
1. 分词
分词实例:
提高人民生活水平:提高、高人、人民、民生、生活、活水、水平
分词基本方法:
最大匹配法、最大概率法分词、最短路径分词方法
1.1 最大匹配法
中文分词在中文信息处理中是最最基础的,无论机器翻译亦或信息检索还是其他相关应用,如果涉及中文,都离不开中文分词,因此中文分词具有极高的地位。正向最大匹配法算法如下图:
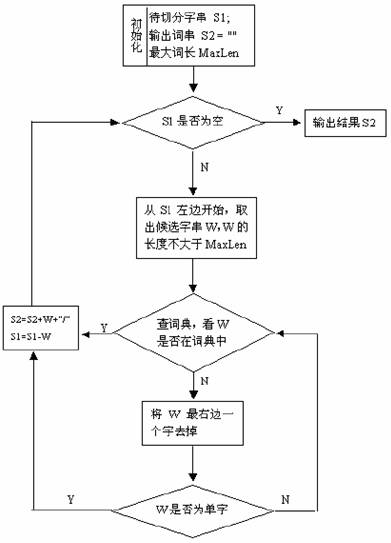
实例:S1="计算语言学课程是三个课时",设定最大词长MaxLen= 5,S2= " "
(1)S2=“”;S1不为空,从S1左边取出候选子串W="计算语言学";
(2)查词表,“计算语言学”在词表中,将W加入到S2中,S2=“计算语言学/ ”,并将W从S1中去掉,此时S1="课程是三个课时";
(3)S1不为空,于是从S1左边取出候选子串W="课程是三个";
(4)查词表,W不在词表中,将W最右边一个字去掉,得到W="课程是三";
(5)查词表,W不在词表中,将W最右边一个字去掉,得到W="课程是";
(6)查词表,W不在词表中,将W最右边一个字去掉,得到W="课程"
(7)查词表,W在词表中,将W加入到S2中,S2=“计算语言学/ 课程/ ”,并将W从S1中去掉,此时S1="是三个课时";
(8)S1不为空,于是从S1左边取出候选子串W="是三个课时";
(9)查词表,W不在词表中,将W最右边一个字去掉,得到W="是三个课";
(10)查词表,W不在词表中,将W最右边一个字去掉,得到W="是三个";
(11)查词表,W不在词表中,将W最右边一个字去掉,得到W="是三"
(12)查词表,W不在词表中,将W最右边一个字去掉,得到W=“是”,这时W是单字,将W加入到S2中,S2=“计算语言学/ 课程/ 是/ ”,并将W从S1中去掉,此时S1="三个课时";
。。。。。。
。。。。。。
(21)S2=“计算语言学/ 课程/ 是/ 三/ 个/ 课时/ ”,此时S1=""。
(22)S1为空,输出S2作为分词结果,分词过程结束。
代码如下:
[cpp]
#include <iostream>
#include <string>
#include <fstream>
#include <sstream>
#include <hash_map>
using namespace std;
using namespace stdext;
class CDictionary
{
public:
CDictionary(); //将词典文件读入并构造为一个哈希词典
~CDictionary();
int FindWord(string w); //在哈希词典中查找词
private:
string strtmp; //读取词典的每一行
string word; //保存每个词
hash_map<string, int> wordhash; // 用于读取词典后的哈希
hash_map<string, int >::iterator worditer; //
typedef pair<string, int> sipair;
};
//将词典文件读入并构造为一个哈希词典
CDictionary::CDictionary()
{
ifstream infile("wordlexicon"); // 打开词典
if (!infile.is_open()) // 打开词典失败则退出程序
{
cerr << "Unable to open input file: " << "wordlexicon"
<< " -- bailing out!" << endl;
exit(-1);
}
while (getline(infile, strtmp, 'n')) // 读入词典的每一行并将其添加入哈希中
{
istringstream istr(strtmp);
istr >> word; //读入每行第一个词
wordhash.insert(sipair(word, 1)); //插入到哈希中
}
}
CDictionary::~CDictionary()
{
}
//在哈希词典中查找词,若找到,则返回,否则返回
int CDictionary::FindWord(string w)
{
if (wordhash.find(w) != wordhash.end())
{
return 1;
}
else
{
return 0;
}
}
#define MaxWordLength 10 // 最大词长为个字节(即个汉字)
#define Separator "/ " // 词界标记
CDictionary WordDic; //初始化一个词典
//对字符串用最大匹配法(正向或逆向)处理
string SegmentSentence(string s1)
{
string s2 = ""; //用s2存放分词结果
while(!s1.empty())
{
int len =(int) s1.length(); // 取输入串长度
if (len > MaxWordLength) // 如果输入串长度大于最大词长
{
len = MaxWordLength; // 只在最大词长范围内进行处理
}
//string w = s1.substr(0, len); // (正向用)将输入串左边等于最大词长长度串取出作为候选词
string w = s1.substr(s1.length() - len, len); //逆向用
int n = WordDic.FindWord(w); // 在词典中查找相应的词
while(len > 2 && n == 0) // 如果不是词
{
len -= 2; // 从候选词右边减掉一个汉字,将剩下的部分作为候选词
//w = w.substr(0, len); //正向用
w = s1.substr(s1.length() - len, len); //逆向用
n = WordDic.FindWord(w);
}
//s2 += w + Separator; // (正向用)将匹配得到的词连同词界标记加到输出串末尾
w = w + Separator; // (逆向用)
s2 = w + s2 ; // (逆向用)
//s1 = s1.substr(w.length(), s1.length()); //(正向用)从s1-w处开始
s1 = s1.substr(0, s1.length() - len); // (逆向用)
}
return s2;
}
//对句子进行最大匹配法处理,包含对特殊字符的处理
string SegmentSentenceMM (string s1)
{
string s2 = ""; //用s2存放分词结果
int i;
int dd;
while(!s1.empty() )
{
unsigned char ch = (unsigned char)s1[0];
if (ch < 128) // 处理西文字符
{
i = 1;
dd = (int)s1.length();
while (i < dd && ((unsigned char)s1[i] < 128) && (s1[i] != 10) && (s1[i] != 13)) // s1[i]不能是换行符或回车符
{
i++;
}
if ((ch != 32) && (ch != 10) && (ch != 13)) // 如果不是西文空格或换行或回车符
{
s2 += s1.substr(0,i) + Separator;
}
else
{
//if (ch == 10 || ch == 13) // 如果是换行或回车符,将它拷贝给s2输出
if (ch == 10 || ch == 13 || ch == 32) //谢谢读者mces89的指正
{
s2 += s1.substr(0, i);
}
}
s1 = s1.substr(i,dd);
continue;
}
else
{
if (ch < 176) // 中文标点等非汉字字符
{
i = 0;
dd = (int)s1.length();
while(i < dd && ((unsigned char)s1[i] < 176) && ((unsigned char)s1[i] >= 161)
&& (!((unsigned char)s1[i] == 161 && ((unsigned char)s1[i+1] >= 162 && (unsigned char)s1[i+1] <= 168)))
&& (!((unsigned char)s1[i] == 161 && ((unsigned char)s1[i+1] >= 171 && (unsigned char)s1[i+1] <= 191)))
&& (!((unsigned char)s1[i] == 163 && ((unsigned char)s1[i+1] == 172 || (unsigned char)s1[i+1] == 161)
|| (unsigned char)s1[i+1] == 168 || (unsigned char)s1[i+1] == 169 || (unsigned char)s1[i+1] == 186
|| (unsigned char)s1[i+1] == 187 || (unsigned char)s1[i+1] == 191)))
{
i = i + 2; // 假定没有半个汉字
}
if (i == 0)
{
i = i + 2;
}
if (!(ch == 161 && (unsigned char)s1[1] == 161)) // 不处理中文空格
{
s2+=s1.substr(0, i) + Separator; // 其他的非汉字双字节字符可能连续输出
}
s1 = s1.substr(i, dd);
continue;
}
}
// 以下处理汉字串
i = 2;
dd = (int)s1.length();
while(i < dd && (unsigned char)s1[i] >= 176)
{
i += 2;
}
s2 += SegmentSentence(s1.substr(0, i));
s1 = s1.substr(i,dd);
}
return s2;
}
int main(int argc, char *argv[])
{
string strtmp; //用于保存从语料库中读入的每一行
string line; //用于输出每一行的结果
ifstream infile(argv[1]); // 打开输入文件
if (!infile.is_open()) // 打开输入文件失败则退出程序
{
cerr << "Unable to open input file: " << argv[1]
<< " -- bailing out!" << endl;
exit(-1);
}
ofstream outfile1("SegmentResult.txt"); //确定输出文件
if (!outfile1.is_open())
{
cerr << "Unable to open file:SegmentResult.txt"
<< "--bailing out!" << endl;
exit(-1);
}
while (getline(infile, strtmp, 'n')) //读入语料库中的每一行并用最大匹配法处理
{
line = strtmp;
line = SegmentSentenceMM(line); // 调用分词函数进行分词处理
outfile1 << line << endl; // 将分词结果写入目标文件
}
return 0;
}
其它基于匹配的分词方法:
最大匹配法(Maximum Matching method):匹配的方向是从左向右。
逆向最大匹配法(Reverse Maximum method):匹配方向与MM法相反,是从右向左。实验表明:对于汉语来说,逆向最大匹配法比最大匹配法更有效。
双向匹配法(Bi-direction Matching method):比较MM法与RMM法的分词结果,从而决定正确的分词。
最佳匹配法(Optimum Matching method, OM法):将词典中的单词按它们在文本中的出现频度的大小排列,高频度的单词排在前,频度低的单词排在后,从而提高匹配的速度。
联想-回溯法(Association-Backtracking method):采用联想和回溯的机制来进行匹配。
1.2 最大概率法分词
基本思想是:(1)一个待切分的汉字串可能包含多种分词结果
(2)将其中概率最大的那个作为该字串的分词结果
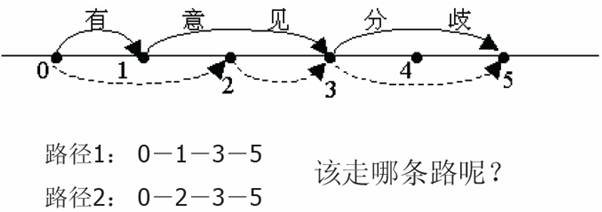
S: 有意见分歧
W1: 有/ 意见/ 分歧/
W2: 有意/ 见/ 分歧/

其中,可以近似地将 P(S|W) 看作是恒等于 1 的,因为任意假想的一种分词方式之下生成我们的句子总是精准地生成的(只需把分词之间的分界符号扔掉即可),而P(S)在各种分词方式下总是相等的,所以不影响比较。所以P(W|S)约等于P(W)。
最大概率法分词示例:

1.3 最短路径分词方法
基本思想:在词图上选择一条词数最少的路径
优点:好于单向的最大匹配方法
最大匹配:独立自主和平等互利的原则 (6)
最短路径:独立自主和平等互利的原则 (5)
缺点:同样无法解决大部分歧义
例如:结合成分子时
2. 文档模型
包含三种模型:布尔模型、向量空间模型、概率模型
2.1 布尔模型
布尔模型是建立在经典的集合论和布尔代数的基础上,根据每个词在一篇文档中是否出现,对应权值为0或1,文档检索也是由布尔逻辑运算来决定的。
优点:简单、易理解、简洁的形式化。
缺点:准确匹配,信息需求的能力表达不足。
2.2 向量空间模型(VSM)
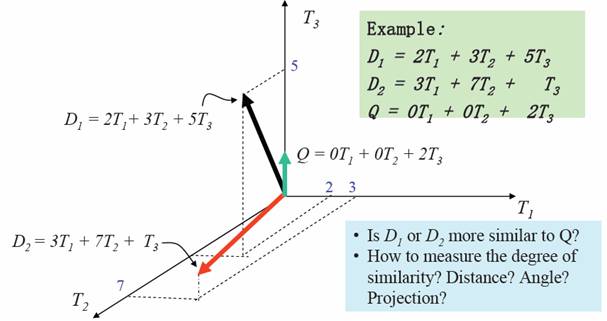
向量空间模型中将文档表达为一个矢量,看作向量空间中的一个点
(1) 词权重
一个句子中的每个词在决定句子的含义时贡献度并不相同,也就是每个词的权重不同,例如下面的句子:
“Most scientists think that butterflies use the position of the sun in the sky as a kind of compass that allows them to determine which way is north.”
重要的词:butterflies, monarchs, scientists, compass
不重要的词:most, think, kind, sky
词权重就是反映每个词的重要性的度量。
(2) 词频(tf)
一个词在一个句子中出现的次数越多,那么这个词在描述这个句子的含义方面贡献度越大,可通过下面两个式子中的一个来计算每个词的词权重:
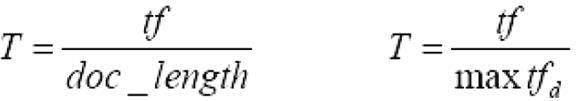
(3) 逆文档频率(idf)
通常来说,如果一个词在越多的文档中出现过,那个这个词对某一个文档的贡献度应该就越小,也就是通过这个词来区分文档的区分度越小,可以用逆文档频率(idf)来度量这个概念。先定义另一个概念,文档频率(df),表示包含某个词的文档的数目。逆文档频率计算公式如下:
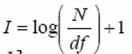
有时候为了让idf范围在[0,1]内,使用下面的式子来计算:
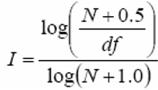
VSM计算简单,很容易表示词权重,它的缺点是必须假设词与词之间的独立性
2.3 概率模型
概率统计检索模型(Probabilistic Retrieval Model)是另一种普遍使用的信息检索算法模型,它应用文档与查询相关的概率来计算文档与查询的相似度。通常利用检索单元作为线索,通过统计得到每个检索单元在相关的文档集(对应于某询)中出现和不出现的概率以及其在与该查询不相关的文档集中出现和不出现的概率,最终,利用这些概率值,计算文档与查询的相似度。设文档D包含t个检索单元,分别记为(ω1,ω2,...,ωt),其中,ωi为第i个检索单元的权值,可以理解为该检索单元的出现为文档D与查询Q相关所作的“贡献”,文档D与查询Q的相似度则是t个包含在D中的检索单元“贡献”的组合。
在信息检索的研究中,对于概率统计检索模型,通常,为了计算方便需要做一些假设,比如:假设检索单元在相关文档集中的分布相互独立,在不相关文档集中的分布也相互独立。虽然这一假设与实际情况并不完全一致,比如,“中国”和“北京”如果同时出现在某一篇文档中,则不能认为这样的两个检索单元是相互独立的。但是,如果考虑检索单元的相关性,则会使相应的概率计算变得非常复杂,因此,在实际中,仍然保持了这一假设。实际的效果表明,尽管概率统计检索模型存在这样的不足,但仍可以取得相对令人满意的信息检索效果。
具体来说,在独立性假设的前提下,同时考虑检索单元出现在文档中的概率以及不出现在文档中的概率,对于给定的查询q 的某一个检索单元ωi,可以定义wi :
wi=log[r(N-R-n+r) / (R-r)(n-r)]
其中
N:文档集合中文档的总数;
R:与查询q 相关的文档总数;
n:含有检索单元ωi 的文档总数;
r:与q 相关的文档中,含有检索单元ωi 的文档数。
由于训练集合所能提供的信息并不是十分完全,Robertson 和Sparck-Jones建议对上式进行修正,在相关的信息不完全的情况下,在每一项后面加上0.5.
现在,我们已经获得了各检索单元的权值,下一步是如何利用这些权值来计算文档与查询的相似度。考虑我们的假设条件,由于各检索单元的分布相互独立,因此,我们可以简单的利用这些权值的乘积来计算文档与查询的相似度,
SC (Q, D)= logΠ(wi)=Σlogwi
至此,我们仅讨论概率统计检索模型最基本的一种检索思路,实际使用中的概率统计检索模型会复杂很多,通常,在检索单元的权值的计算中,还会考虑检索单元在文档中出现的频率(tf),检索单元在查询中出现的频率(qtf),以及文档的长度(dl)等信息,BM25算法就是这样一种在目前信息检索系统中常用的检索算法。BM25 检索算法是Roberston 1994年在TREC3上提出,BM25计算文档D和查询Q的相似性。对查询Q中的每一个检索单元ωi ,一共有三个权值与之相关:
U =(k2+1)ψ/(k2+ψ),其中k2是由用户指定的参数,ψ是检索单元ωi在Q中出现的频率qtf(within query term frequency)。
V =(k+1)φ/k*(1-b+bL)+φ其中k 和b 是用户指定的参数,φ 是检索单元ωi 在D 中出现的频率tf (term frequency),L 是正则化之后的文档长度,计算方法为原始文档长度除以文档集合中平均的文档长度。
W就是我们上面提到的加0.5后的式子。在BM25 公式中,查询Q 和文档D 的分值为SC(Q,D)= ΣUVW
3 文本间相似度的计算
3.1 基于概率模型的相关度
wi=log[r(N-R-n+r) / (R-r)(n-r)]
SC (Q, D)= logΠ(wi)=Σlogwi
见上面的概率模型
3.2 基于VSM的相关度
基于向量空间模型的常用方法:欧氏距离、向量内积、向量夹角余弦
(1)欧氏距离

(2)向量内积

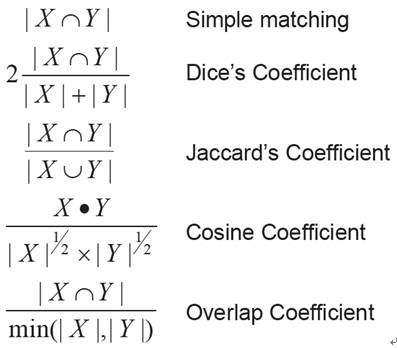
(3)向量夹角余弦

(4)Jaccard相似度

(5)基于向量内积的几种方法的对比
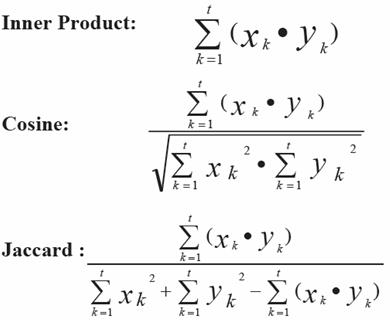
(6)基于集合计算的几种方法
4. 特征空间的变化
机器学习的主要难点在于“被阐述”的词法和“真正要表达”的语义的区别。产生这个问题的原因主要是:1.一个单词可能有多个意思和多个用法。2. 同义词和近义词,而且根据不同的语境或其他因素,原本不同的单词也有可能表示相同的意思。LSA是处理这类问题的著名技术,其主要思想就是映射高维向量到潜在语义空间,使其降维。潜在语义分析(LSA)又称为潜在语义索引(LSI),是一种使用数学和统计的方法对文本中的词语进行抽取,推断它们之间的语义关系,并建立一个语义索引,而将文档组织成语义空间结构的方法。它的出发点是文档的特征项与特征项之间存在着某种潜在的语义联系,消除词之间的相关性,简化文本向量的目的。它通过奇异值分解(SVD),把特征项和文档映射到同一个语义空间,对文档矩阵进行计算,提取K个最大的奇异值,近似表示原文档。这个映射必须是严格线性的而且是基于共现表的奇异值分解。
问题提出:一词多义和同义词
中心思想:用概念(或特征)代替词
基本方法:利用矩阵理论中的“奇异值分解(singular value decomposition,SVD)”技术,将词频矩阵转化为奇异矩阵(K×K)
4.1 奇异值分解
特征值分解是一个提取矩阵特征很不错的方法,但是它只是对方阵而言的,在现实的世界中,我们看到的大部分矩阵都不是方阵,比如说有N个学生,每个学生有M科成绩,这样形成的一个N * M的矩阵就不可能是方阵,我们怎样才能描述这样普通的矩阵呢的重要特征呢?奇异值分解可以用来干这个事情,奇异值分解是一个能适用于任意的矩阵的一种分解的方法:
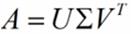
假设A是一个N * M的矩阵,那么得到的U是一个N * N的方阵(里面的向量是正交的,U里面的向量称为左奇异向量),Σ是一个N * M的矩阵(除了对角线的元素都是0,对角线上的元素称为奇异值),V’(V的转置)是一个N * N的矩阵,里面的向量也是正交的,V里面的向量称为右奇异向量),从图片来反映几个相乘的矩阵的大小可得下面的图片
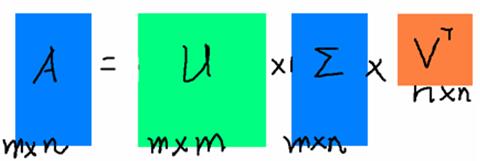
那么奇异值和特征值是怎么对应起来的呢?首先,我们将一个矩阵A的转置乘以A,将会得到一个方阵,我们用这个方阵求特征值可以得到: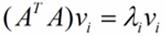 这里得到的v,就是我们上面的右奇异向量。此外我们还可以得到:
这里得到的v,就是我们上面的右奇异向量。此外我们还可以得到:
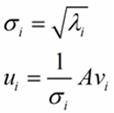
这里的σ就是上面说的奇异值,u就是上面说的左奇异向量。奇异值σ跟特征值类似,在矩阵Σ中也是从大到小排列,而且σ的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上了。也就是说,我们也可以用前r大的奇异值来近似描述矩阵,这里定义一下部分奇异值分解:
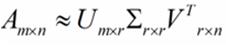
r是一个远小于m、n的数,这样矩阵的乘法看起来像是下面的样子:
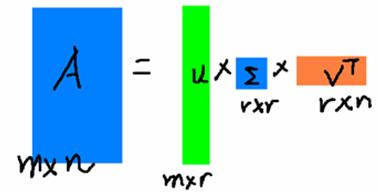
右边的三个矩阵相乘的结果将会是一个接近于A的矩阵,在这儿,r越接近于n,则相乘的结果越接近于A。而这三个矩阵的面积之和(在存储观点来说,矩阵面积越小,存储量就越小)要远远小于原始的矩阵A,我们如果想要压缩空间来表示原矩阵A,我们存下这里的三个矩阵:U、Σ、V就好了。
4.2 隐语义分析(LSA)
输入:term-by-document matrix
输出:
U: concept-by-term matrix
V: concept-by-document matrix
S: elements assign weights to concepts
基本步骤
1.建立词频矩阵frequency matrix
2.计算frequency matrix的奇异值分解
分解frequency matrix成3个矩阵U,S,V。U和V是正交矩阵(UTU=I),S是奇异值的对角矩阵(K×K)
3.对于每一个文档d,用排除了SVD中消除后的词的新的向量替换原有的向量
4.用转换后的文档索引和相似度计算
之前吴军老师在矩阵计算与文本处理中的分类问题中谈到:
“三个矩阵有非常清楚的物理含义。第一个矩阵X中的每一行表示意思相关的一类词,其中的每个非零元素表示这类词中每个词的重要性(或者说相关性),数值越大越相关。最后一个矩阵Y中的每一列表示同一主题一类文章,其中每个元素表示这类文章中每篇文章的相关性。中间的矩阵则表示类词和文章雷之间的相关性。因此,我们只要对关联矩阵A进行一次奇异值分解,w 我们就可以同时完成了近义词分类和文章的分类。(同时得到每类文章和每类词的相关性)。”
上面这段话可能不太容易理解,不过这就是LSI的精髓内容,我下面举一个例子来说明一下,下面的例子来自LSA tutorial,具体的网址我将在最后的引用中给出:
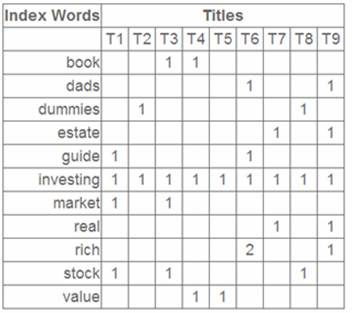
这就是一个矩阵,不过不太一样的是,这里的一行表示一个词在哪些title中出现了(一行就是之前说的一维feature),一列表示一个title中有哪些词,(这个矩阵其实是我们之前说的那种一行是一个sample的形式的一种转置,这个会使得我们的左右奇异向量的意义产生变化,但是不会影响我们计算的过程)。比如说T1这个title中就有guide、investing、market、stock四个词,各出现了一次,我们将这个矩阵进行SVD,得到下面的矩阵:
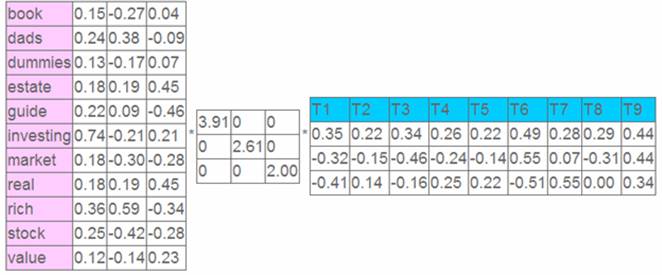
左奇异向量表示词的一些特性,右奇异向量表示文档的一些特性,中间的奇异值矩阵表示左奇异向量的一行与右奇异向量的一列的重要程序,数字越大越重要。
继续看这个矩阵还可以发现一些有意思的东西,首先,左奇异向量的第一列表示每一个词的出现频繁程度,虽然不是线性的,但是可以认为是一个大概的描述,比如book是0.15对应文档中出现的2次,investing是0.74对应了文档中出现了9次,rich是0.36对应文档中出现了3次;
其次,右奇异向量中一的第一行表示每一篇文档中的出现词的个数的近似,比如说,T6是0.49,出现了5个词,T2是0.22,出现了2个词。
然后我们反过头来看,我们可以将左奇异向量和右奇异向量都取后2维(之前是3维的矩阵),投影到一个平面上,可以得到:
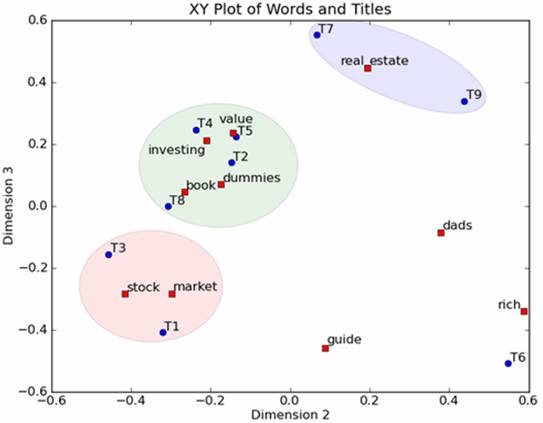
在图上,每一个红色的点,都表示一个词,每一个蓝色的点,都表示一篇文档,这样我们可以对这些词和文档进行聚类,比如说stock 和 market可以放在一类,因为他们老是出现在一起,real和estate可以放在一类,dads,guide这种词就看起来有点孤立了,我们就不对他们进行合并了。按这样聚类出现的效果,可以提取文档集合中的近义词,这样当用户检索文档的时候,是用语义级别(近义词集合)去检索了,而不是之前的词的级别。这样一减少我们的检索、存储量,因为这样压缩的文档集合和PCA是异曲同工的,二可以提高我们的用户体验,用户输入一个词,我们可以在这个词的近义词的集合中去找,这是传统的索引无法做到的。
以上是关于文本挖掘模型:本特征提取的主要内容,如果未能解决你的问题,请参考以下文章