使用Python的文本挖掘的特征选择/提取
Posted yspxizhen
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Python的文本挖掘的特征选择/提取相关的知识,希望对你有一定的参考价值。
在文本挖掘与文本分类的有关问题中,文本最初始的数据是将文档表示成向量空间模型的一个矩阵,而这个矩阵所拥有的就是不同的词,常采用特征选择方法。原因是文本的特征一般都是单词(term),具有语义信息,使用特征选择找出的k维子集,仍然是单词作为特征,保留了语义信息,而特征提取则找k维新空间,将会丧失了语义信息。
当然,另一方面,在处理文本时,对于我们来说,已经拥有将不同词在低维空间上总结归纳的能力,知道这些词的联系和区别,但是对于计算机来说,它们怎么知道这些的联系呢?也就是它们根本还不拥有这些降维的能力,那么就要依靠我们告诉它们这个方法,这个工具就是SVD,其核心思想就是:将这些不同的词都映射到低维空间中去,在低维空间中去总结,去发现这些词的内在联系,一旦这些内在联系建立了,那么我们就知道了这些文档的内在联系了。
特征选择
对于一个语料而言,我们可以统计的信息包括文档频率和文档类比例,所有的特征选择方法均依赖于这两个统计量,目前,文本的特征选择方法主要有:DF, MI, IG, CHI,WLLR,WFO六种。
概率定义简述
p(t):一篇文档x包含特征词t的概率。
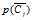 :文档x不属于Ci的概率。
:文档x不属于Ci的概率。
p(Ci|t):已知文档x的包括某个特征词t条件下,该文档属于Ci的概率
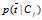 : 已知文档属于Ci 条件下,该文档不包括特征词t的概率
: 已知文档属于Ci 条件下,该文档不包括特征词t的概率
类似的其他的一些概率如p(Ci), 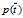 ,
,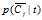 等,有着类似的定义。
等,有着类似的定义。
为了估计这些概率,需要通过统计训练样本的相关频率信息,如下表:

其中:
Aij: 包含特征词ti,并且类别属于Cj的文档数量 Bij: 包含特征词ti,并且类别属于不Cj的文档数量
Cij:不包含特征词ti,并且类别属于Cj的文档数量 Dij:不包含特征词ti,并且类别属于不Cj的文档数量
Aij + Bij: 包含特征词ti的文档数量 Cij + Dij:不包含特征词ti的文档数量
Aij + Cij:Cj类的文档数量数据 Bij + Dij:非Cj类的文档数量数据
Aij + Bij + Cij + Dij = N :语料中所有文档数量。
有了这些统计量,有关概率的估算就变得容易,如:
p(ti) = (Aij + Bij) / N; p(Cj) = (Aij + Cij) / N;
p(Cj|tj) = Aij / (Aij + Bij)
类似的一些概率计算可以依照上表计算。
常见的四种特征选择方法计算方法
1)DF(Document Frequency)
DF是统计特征词出现的文档数量,用来衡量某个特征词的重要性,DF的定义如下:
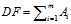
DF的动机是,如果某些特征词在文档中经常出现,那么这个词就可能很重要。而对于在文档中出现很少(如仅在语料中出现1次)特征词,携带了很少的信息量,甚至是"噪声",这些特征词,对分类器学习影响也是很小。
DF特征选择方法属于无监督的学习算法(也有将其改成有监督的算法,但是大部分情况都作为无监督算法使用),仅考虑了频率因素而没有考虑类别因素,因此,DF算法的将会引入一些没有意义的词。如中文的"的"、"是", "个"等,常常具有很高的DF得分,但是,对分类并没有多大的意义。
2)MI(Mutual Information)
互信息法用于衡量特征词与文档类别直接的信息量,互信息法的定义如下:
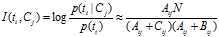
继续推导MI的定义公式:
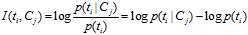
从上面的公式上看出:如果某个特征词的频率很低,那么互信息得分就会很大,因此互信息法倾向"低频"的特征词。相对的词频很高的词,得分就会变低,如果这词携带了很高的信息量,互信息法就会变得低效。
3)IG(Information Gain)
信息增益法,通过某个特征词的缺失与存在的两种情况下,语料中前后信息的增加,衡量某个特征词的重要性。
信息增益的定义如下:
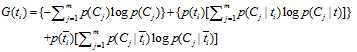
依据IG的定义,每个特征词ti的IG得分前面一部分: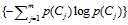 计算值是一样,可以省略。因此,IG的计算公式如下:
计算值是一样,可以省略。因此,IG的计算公式如下:
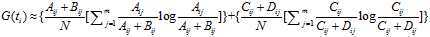
IG与MI存在关系:
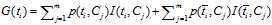
因此,IG方式实际上就是互信息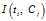 与互信息
与互信息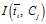 加权。
加权。
4)CHI(Chi-square)
CHI特征选择算法利用了统计学中的"假设检验"的基本思想:首先假设特征词与类别直接是不相关的,如果利用CHI分布计算出的检验值偏离阈值越大,那么更有信心否定原假设,接受原假设的备则假设:特征词与类别有着很高的关联度。CHI的定义如下:
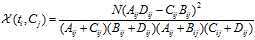
对于一个给定的语料而言,文档的总数N以及Cj类文档的数量,非Cj类文档的数量,他们都是一个定值,因此CHI的计算公式可以简化为:
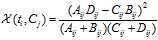
CHI特征选择方法,综合考虑文档频率与类别比例两个因素。
5)WLLR(Weighted Log Likelihood Ration)
WLLR特征选择方法的定义如下:
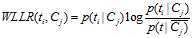
计算公式如下:
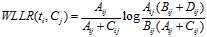
6)WFO(Weighted Frequency and Odds)
最后一个介绍的算法,是由苏大李寿山老师提出的算法。通过以上的五种算法的分析,李寿山老师认为,"好"的特征应该有以下特点:
-
- 好的特征应该有较高的文档频率
- 好的特征应该有较高的文档类别比例
WFO的算法定义如下:
如果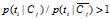 :
:
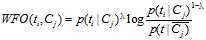
否则:
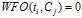
不同的语料,一般来说文档词频与文档的类别比例起的作用应该是不一样的,WFO方法可以通过调整参数 ,找出一个较好的特征选择依据。
,找出一个较好的特征选择依据。
文本挖掘
文本的特征选择方法:sklearn提供的CHI + 自定义的IG/MI/WLLR
#!/usr/bin/env python # coding=gbk import os import sys import numpy as np def get_term_dict(doc_terms_list): term_set_dict = for doc_terms in doc_terms_list: for term in doc_terms: term_set_dict[term] = 1 term_set_list = sorted(term_set_dict.keys()) #term set 排序后,按照索引做出字典 term_set_dict = dict(zip(term_set_list, range(len(term_set_list)))) return term_set_dict def get_class_dict(doc_class_list): class_set = sorted(list(set(doc_class_list))) class_dict = dict(zip(class_set, range(len(class_set)))) return class_dict def stats_term_df(doc_terms_list, term_dict): term_df_dict = .fromkeys(term_dict.keys(), 0) for term in term_set: for doc_terms in doc_terms_list: if term in doc_terms_list: term_df_dict[term] +=1 return term_df_dict def stats_class_df(doc_class_list, class_dict): class_df_list = [0] * len(class_dict) for doc_class in doc_class_list: class_df_list[class_dict[doc_class]] += 1 return class_df_list def stats_term_class_df(doc_terms_list, doc_class_list, term_dict, class_dict): term_class_df_mat = np.zeros((len(term_dict), len(class_dict)), np.float32) for k in range(len(doc_class_list)): class_index = class_dict[doc_class_list[k]] doc_terms = doc_terms_list[k] for term in set(doc_terms): term_index = term_dict[term] term_class_df_mat[term_index][class_index] +=1 return term_class_df_mat def feature_selection_mi(class_df_list, term_set, term_class_df_mat): A = term_class_df_mat B = np.array([(sum(x) - x).tolist() for x in A]) C = np.tile(class_df_list, (A.shape[0], 1)) - A N = sum(class_df_list) class_set_size = len(class_df_list) term_score_mat = np.log(((A+1.0)*N) / ((A+C) * (A+B+class_set_size))) term_score_max_list = [max(x) for x in term_score_mat] term_score_array = np.array(term_score_max_list) sorted_term_score_index = term_score_array.argsort()[: : -1] term_set_fs = [term_set[index] for index in sorted_term_score_index] return term_set_fs def feature_selection_ig(class_df_list, term_set, term_class_df_mat): A = term_class_df_mat B = np.array([(sum(x) - x).tolist() for x in A]) C = np.tile(class_df_list, (A.shape[0], 1)) - A N = sum(class_df_list) D = N - A - B - C term_df_array = np.sum(A, axis = 1) class_set_size = len(class_df_list) p_t = term_df_array / N p_not_t = 1 - p_t p_c_t_mat = (A + 1) / (A + B + class_set_size) p_c_not_t_mat = (C+1) / (C + D + class_set_size) p_c_t = np.sum(p_c_t_mat * np.log(p_c_t_mat), axis =1) p_c_not_t = np.sum(p_c_not_t_mat * np.log(p_c_not_t_mat), axis =1) term_score_array = p_t * p_c_t + p_not_t * p_c_not_t sorted_term_score_index = term_score_array.argsort()[: : -1] term_set_fs = [term_set[index] for index in sorted_term_score_index] return term_set_fs def feature_selection_wllr(class_df_list, term_set, term_class_df_mat): A = term_class_df_mat B = np.array([(sum(x) - x).tolist() for x in A]) C_Total = np.tile(class_df_list, (A.shape[0], 1)) N = sum(class_df_list) C_Total_Not = N - C_Total term_set_size = len(term_set) p_t_c = (A + 1E-6) / (C_Total + 1E-6 * term_set_size) p_t_not_c = (B + 1E-6) / (C_Total_Not + 1E-6 * term_set_size) term_score_mat = p_t_c * np.log(p_t_c / p_t_not_c) term_score_max_list = [max(x) for x in term_score_mat] term_score_array = np.array(term_score_max_list) sorted_term_score_index = term_score_array.argsort()[: : -1] term_set_fs = [term_set[index] for index in sorted_term_score_index] print term_set_fs[:10] return term_set_fs def feature_selection(doc_terms_list, doc_class_list, fs_method): class_dict = get_class_dict(doc_class_list) term_dict = get_term_dict(doc_terms_list) class_df_list = stats_class_df(doc_class_list, class_dict) term_class_df_mat = stats_term_class_df(doc_terms_list, doc_class_list, term_dict, class_dict) term_set = [term[0] for term in sorted(term_dict.items(), key = lambda x : x[1])] term_set_fs = [] if fs_method == ‘MI‘: term_set_fs = feature_selection_mi(class_df_list, term_set, term_class_df_mat) elif fs_method == ‘IG‘: term_set_fs = feature_selection_ig(class_df_list, term_set, term_class_df_mat) elif fs_method == ‘WLLR‘: term_set_fs = feature_selection_wllr(class_df_list, term_set, term_class_df_mat) return term_set_fs
# 基于movie语料比较自定义的三种特征选择方法 #!/usr/bin/env python # coding=gbk import os import sys import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import load_files from sklearn.cross_validation import train_test_split from sklearn.feature_extraction.text import CountVectorizer from sklearn.naive_bayes import MultinomialNB import feature_selection def text_classifly_twang(dataset_dir_name, fs_method, fs_num): print ‘Loading dataset, 80% for training, 20% for testing...‘ movie_reviews = load_files(dataset_dir_name) doc_str_list_train, doc_str_list_test, doc_class_list_train, doc_class_list_test = train_test_split(movie_reviews.data, movie_reviews.target, test_size = 0.2, random_state = 0) print ‘Feature selection...‘ print ‘fs method:‘ + fs_method, ‘fs num:‘ + str(fs_num) vectorizer = CountVectorizer(binary = True) word_tokenizer = vectorizer.build_tokenizer() doc_terms_list_train = [word_tokenizer(doc_str) for doc_str in doc_str_list_train] term_set_fs = feature_selection.feature_selection(doc_terms_list_train, doc_class_list_train, fs_method)[:fs_num] print ‘Building VSM model...‘ term_dict = dict(zip(term_set_fs, range(len(term_set_fs)))) vectorizer.fixed_vocabulary = True vectorizer.vocabulary_ = term_dict doc_train_vec = vectorizer.fit_transform(doc_str_list_train) doc_test_vec= vectorizer.transform(doc_str_list_test) clf = MultinomialNB().fit(doc_train_vec, doc_class_list_train) #调用MultinomialNB分类器 doc_test_predicted = clf.predict(doc_test_vec) acc = np.mean(doc_test_predicted == doc_class_list_test) print ‘Accuracy: ‘, acc return acc if __name__ == ‘__main__‘: dataset_dir_name = sys.argv[1] fs_method_list = [‘IG‘, ‘MI‘, ‘WLLR‘] fs_num_list = range(25000, 35000, 1000) acc_dict = for fs_method in fs_method_list: acc_list = [] for fs_num in fs_num_list: acc = text_classifly_twang(dataset_dir_name, fs_method, fs_num) acc_list.append(acc) acc_dict[fs_method] = acc_list print ‘fs method:‘, acc_dict[fs_method] for fs_method in fs_method_list: plt.plot(fs_num_list, acc_dict[fs_method], ‘--^‘, label = fs_method) plt.title(‘feature selection‘) plt.xlabel(‘fs num‘) plt.ylabel(‘accuracy‘) plt.ylim((0.82, 0.86)) plt.legend( loc=‘upper left‘, numpoints = 1) plt.show()
输出结果:
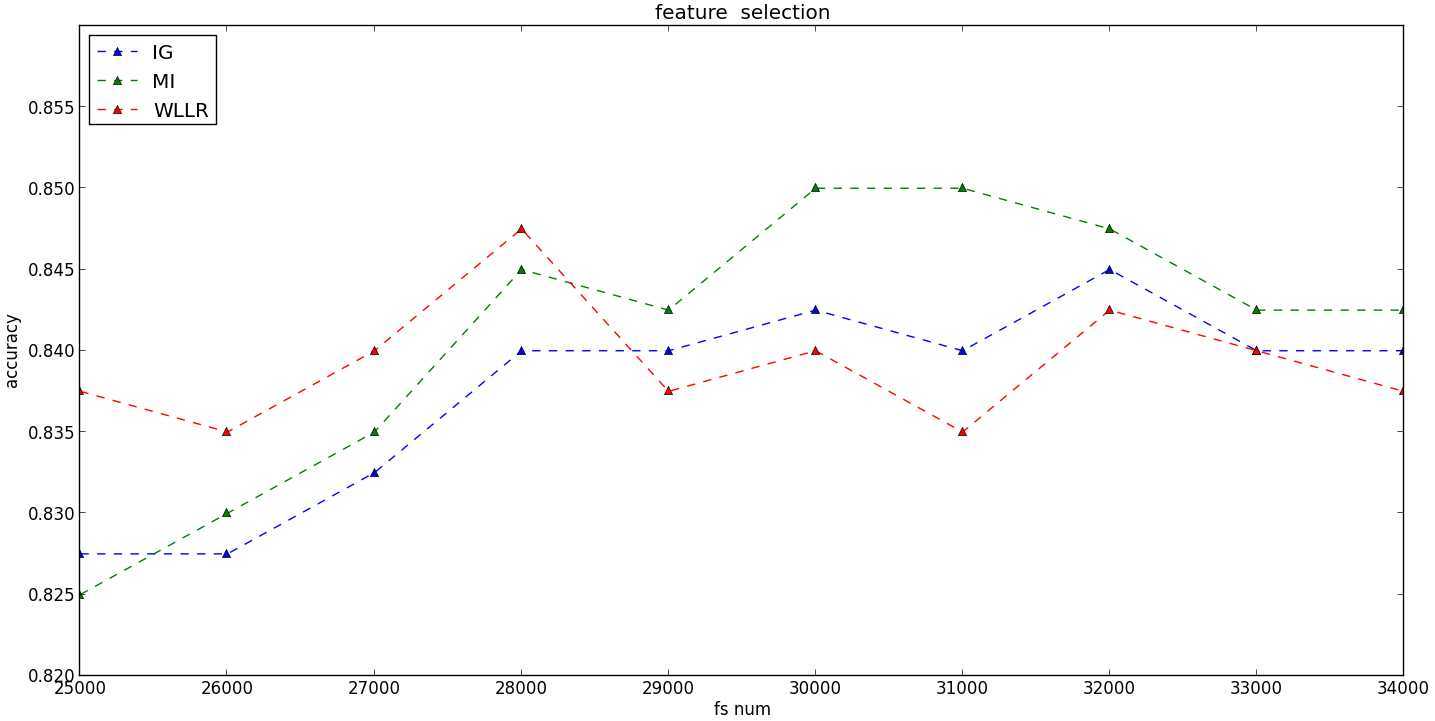
如图所示,分类的性能随着特征选择的数量的增加,呈现“凸”形趋势:
1)在特征数量较少的情况下,不断增加特征的数量,有利于提高分类器的性能,呈现“上升”趋势;
2)随着特征数量的不断增加,将会引入一些不重要的特征,甚至是噪声,因此,分类器的性能将会呈现“下降”的趋势。
这张“凸”形趋势体现出了特征选择的重要性:选择出重要的特征,并降低噪声,提高算法的泛化能力。
特征提取
构建用于文本聚类的空间向量模型的特征提取
如何抽取文章特征? - 如何从海量候选中选取有代表性的特征
1. 如开头所提到的问题中的回答,最常见的特征类型是词汇/词语,利用Chi-squre进行特征选取,利用TFIDF作为特征权重。这也是搜索引擎和文本分类中最通用鲁棒的做法。
2. 对于短文本,如微博、查询词、社区问答系统中的提问问题等,利用基于词汇的特征向量空间计算相似度会面临比较严重的数据稀疏性问题,解决的方案是利用隐含主题模型等方法,建立词汇之间的相似度。具体方案可以参考2008年发表在WWW上的一篇论文:Learning to classify short and sparse text & web with hidden topics from large-scale data collections。需要注意的是,在LDA的原始论文中作者就尝试仅用文档主题来作为特征进行分类,但经验表明,仅用隐含主题的特征表示效果明显弱于使用词汇的特征表示方案。实用的做法是将两者相结合。
3. 2007年有研究者在IJCAI的论文中提出利用维基百科中的概念表示单词和文档,取得较好效果:Computing Semantic Relatedness Using Wikipedia-based Explicit Semantic Analysis。它的优点是可以做任意长度文本的特征表示,由于它将所有单词和文档都表示为维基百科词条数目长度的向量,因此具有较强的表达能力,但问题就是计算效率的问题。一个可行的解决方案是限制每个单词或文本只在几百万维的少数概念/词条上取值。
微博短文本分析的特征提取
一般是用词袋模型+隐含主题模型来完成,在短文本的主题模型有一些研究工作:
1. KDD 2014上来自Twitter团队的Large-Scale High-Precision Topic Modeling on Twitter,对Twitter数据上进行主题模型建模做了大量定制化工作。
2. WWW 2008上的Learning to classify short and sparse text & web with hidden topics from large-scale data collections,专门研究如何用主题模型帮助解决短文本类分类的稀疏性问题。
3. ECIR 2011上的Comparing twitter and traditional media using topic models提出TwitterLDA,假设每条短文本只属于一个隐含主题,属于专门针对短文本隐含主题建模所做的合理性假设。
以上是关于使用Python的文本挖掘的特征选择/提取的主要内容,如果未能解决你的问题,请参考以下文章