精品大数据文本挖掘在广播电视中的应用与探索
Posted 广电猎酷
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了精品大数据文本挖掘在广播电视中的应用与探索相关的知识,希望对你有一定的参考价值。
本文由《广播与电视技术》杂志独家授权。本文刊发于2017年第4期。
本文在提出一种基于多种人工智能技术的媒体创新平台,详细讨论了广电大数据文本挖掘在传统广播电视领域中的应用与探索。提出了业界首个基于五大模块(依据工作流的处理方向,依次为互联网数据检测与收集模块、数据筛选与预处理模块、数据分析与特征提取模块、数据统计与分析模块、以及数据可视化模块)的广电大数据分析平台,并给出了技术框架设计与各模块的实现框图,给出了最终平台实现的数据可视化界面。
0 引言
近年来,随着信息技术与广播电视行业的不断融合,作为传统意义上评判广电节目好坏唯一指标的收视率,已不能满足对新媒体内容价值评估的需求。传统的收视率数据反映的只是用户收视行为,即谁在看,看什么,看了多久。然而该指标无法反映出观众对节目的评价与感受;也无法知道人们关注的热点是什么;更做不到实时反馈。很显然,传统收视率指标已远远不能满足新媒体环境下,对广电节目全方位的,快速的价值评估的需求。
因此,在大数据时代,广播电视行业如何顺应当今媒体发展的潮流,更准确、实时地了解受众的感想和需求,是摆在广电人面前不可回避的课题。据2016年1月12日,路透社向全球发布的《2016年新闻、媒体、技术预测》报告[1] 显示,英国广播公司BBC、英国《金融时报》等许多大出版商和媒体都在投入力量以更好地分析用户数据,提高用户黏性。76%的受访者认为,媒体要提高分析用户数据的能力。45%的媒体和出版商使用自己开发的平台了解内容的传播情况。可见,媒体人在当今激烈的竞争中,对了解用户需求的重视。
在此背景下,本文要推出的课题就是怎样把大数据挖掘应用于广播电视,用文本挖掘和大数据分析的结果,打造一个可以实时洞悉受众的心声,掌握收视情况和竞争的态势的全新平台。该系统将是业界首次将大数据文本挖掘和人工智能信息处理技术引入到广播电视领域的尝试。在技术上,将多种机器学习算法与分布式计算技术,包括网络爬虫、分布式消息队列、分布式哈希表、朴素贝叶斯网络、POS分词、词向量模型、神经网络、PCA主元分析、SVM支持向量机、K-means无监督分类、回归分析等,成功融合到同一个系统中。从而也为相关技术与系统在广电领域内的应用与推广提供了可行的技术依据。在有益成果上,广电文本大数据系统通过对受众需求进行充分的分析,使广电部门能够科学系统、有针对性和前瞻性的规划和设置栏目,在保证其收视率的同时,为地区社会生活提供正确的舆论导向,提升广播电视影响力。同时,广电文本挖掘也能为各级领导解决发展思路和方向、定位问题;解决战略布局和发展措施问题,全面统筹规划提供决策依据。
1 广电大数据分析介绍
本章节将从对传统广播电视数据分析方法的讨论开始,分析其存在的问题。从而针对这些问题,提出一种基于网络文本大数据的新型广电大数据分析方法。
1.1 传统的广电数据分析方法
1.2 广电文本大数据挖掘概述
在此背景下,我们提出了一种自动化的广电文本大数据挖掘系统。该系统不仅对由传统渠道中人工录入的结构化数据进行分析,还能够从网络上海量的非结构化文本中提取出观众关注的热点问题,了解观众对节目的评论,再把热点去和结构化数据做关联分析,并生成可视化的相应分析结果(如收视率变化,节目关注度,热门话题分析等)。
2 广电文本大数据挖掘的实现讨论
本章节采用自顶向下的设计方法,详细讨论了系统的总体技术架构框架,系统在实现层面的五个模块,以及各模块的内部实现。
2.1 广电大数据系统技术框架设计
本系统的技术框架设计如图1所示,主要分为分布式消息队列、计算集群、数据库与文件存储、以及前端网页服务器。具体来说,由于此类大数据系统都具有信息输入量大,处理计算量大,存储内容多等特点,我们需要分布式的系统框架来满足系统的实时性和高吞吐量。首先,我们采用基于Apache Spark[3]的高性能计算集群进行大数据的爬取、收集和处理。具体处理逻辑通过调用Spark Python编程语言接口即pySpark实现。这些集群由Zookeeper[4]进行监控和管理,以保证计算集群的稳定性和健壮性。由于我们将在同一组集群上部署多种不同的任务,且各模块任务特性的不同,处理速度可能各不相同。因此模块间的通信采用基于Kafka 的分布式消息队列[5],实现异步无阻塞的消息传输,从而提升整个系统的实时性和处理速度。我们采用Cassandra[6]作为分布式NoSQL数据库用来存储处理得到的大量分析数据,并将自动生成的相关报告文件存储到分布式文件系统HDFS[7]中,这两个存储框架的高效的读写性能能够保证海量数据写入与读取的实时性。最后,我们的网页服务器前后端均采用基于javascript的框架,即后端的NodeJS[8]和前端的AngularJS[9],来保证整个项目的高效快速开发。
图1 广电文本大数据系统技术框架设计
所有上述技术选型均采用当前的较为成熟技术框架,这些框架均被谷歌、脸书、阿里、百度等大型互联网企业,成功应用于多种不同的大数据系统中。
2.2 广电大数据系统工作流设计
如图2所示,基于上一节阐述的技术框架,广电文本大数据系统的设计实现工作流,可以分为五大模块。依据工作流的处理方向,依次为互联网数据检测与收集模块,数据筛选与预处理模块,数据分析与特征提取模块,数据统计与分析模块,以及数据可视化模块。模块间遵循“高内聚,低耦合”的设计原则,各模块均有明确定义的输入输出,且前一模块的输出即后一模块的输入。

图2 广电文本大数据系统工作流模块框图
图3总体给出了各模块内部的详细设计框图,本章的剩余章节将针对这些设计给出具体描述。
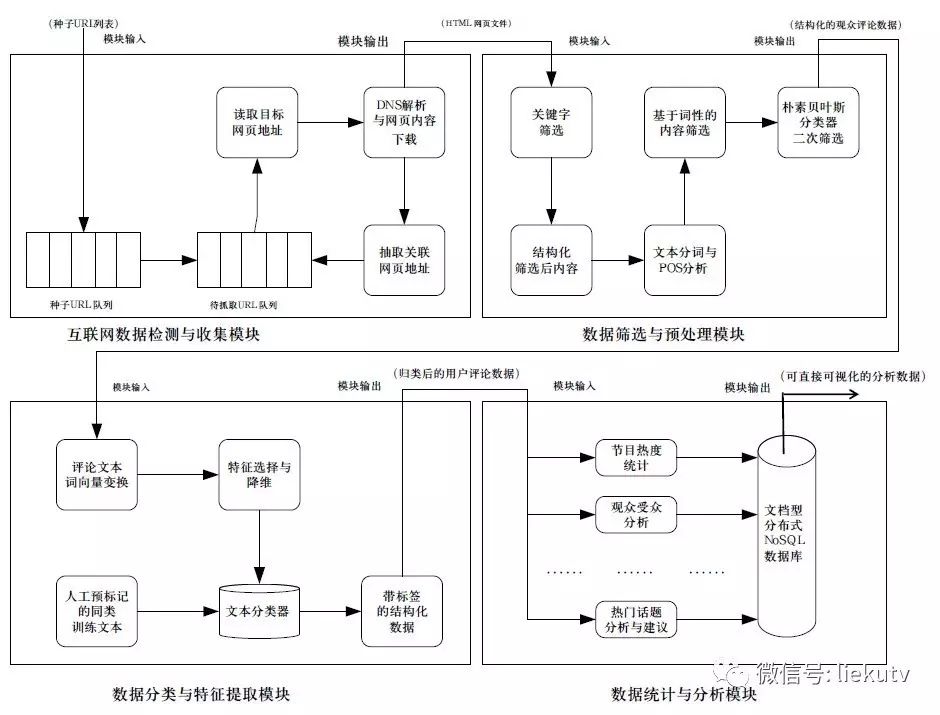
图3 互联网数据监测与收集模块实现框图
2.3 网络数据监测与收集模块实现
2.4 数据筛选与预处理模块实现
该模块以海量相关html网页内容为输入,以筛选后的结构化内容为输出。由于输入数据源全部都是从互联网上通过网络爬虫获取,不可避免的包含大量噪声信息。因此,该模块负责对这些内容进行多次筛选,从而保证获得有效高质量的分析信息。
如图3右上所示,该模块的实现基于两次内容筛选,一次结构化操作和一次词性分析。具体来说,首先,所有的网页文件会通过一个关键字筛选模块,将不含有相关关键字的网页内容去除。然后,系统对初步筛选后的内容进行结构化规范,去除HTML 标签,并提取出格式化内容( 如用户名,发表时间,评论/ 话题内容等)。进一步的,我们对结构化后的文本内容进行POS 词性分析,并将助词(如“的”,“了”,“得”等)、代词( 如“你”,“我”,“他”等)、语气词( 如“吧”,“啊”,“哦”等) 等信息含量较小的单词去除。基于筛选后的单词,我们使用朴素贝叶斯分类器进行二次筛选,从而能够有效地去除广告内容,垃圾内容等,进一步保证了挖掘到的内容的高质量。经过这两次筛选之后的结构化内容即作为该模块的输出,进入下一模块。
2.5 数据分类与特征提取模块实现
该模块以筛选后的结构化数据为输入,对这些数据进行文本分析后,输出归类后的用户评论数据以及相关分析结果。如图3左下所示,该模块采用基于词向量的语义分析方法,配合机器学习的分类算法,对文本产生分析结果(例如文本正面/ 负面情绪分析,政治敏感度指标分析等)。具体来说,首先,分词并筛选后的文本内容会通过词向量模型,转换成高维空间中的向量组。该词向量模型本质上是一个输入为n-gram语料库的神经网络模型,其可由公开的中文语料库(如中文维基百科)附加预先抓取到的广电特定文本(如节目内容介绍,官方节目评论等)作为输入,以最大似然估计作为目标函数值训练得到。由于这些输出的向量组维度相对较高(在默认配置下,谷歌word2vec[10]工具生成的向量维度为每个词组500维),对后期处理造成比较大的负载。因此我们进一步通过PCA主元分析对特征进行选择并进行降维。经过降维操作后,我们将词向量的维数降低到100维左右,即得到最重要的100个维度特征。我们将一部分此类文本进行人工预标记(例如哪些文本是表达的负面情绪,哪些文本的政治敏感度较高),并将这些文本的词向量组作为输入,采用SVM支持向量机进行训练。训练后得到的文本分类器模型即可用于对未知文本进行分析判断,从而得到其对应的标签。最后,这些带标签的结构化数据成为本模块的输出数据,进入下一个模块。
2.6 数据统计与分析模块实现
该模块以语义分析后的结构化数据为输入,经过统计、聚类、计算后,将数据全部汇聚到文档性分布式数据库中,供下个模块的数据可视化操作使用。由于各种不同的统计操作之间相对独立,相互间没有依赖,因此我们采用分布式并行计算框架来提高本模块的处理和读写效率。
如图3右下所示,该模块针对同一类数据的不同方面,进行全方位多角度的分析,并将分析结果写入到数据库中。具体来说,这些统计与分析方法包括但不限于:
1. 以节目为单位,对单个节目的热度统计,以及在此基础上对节目热度的排序,平均值计算,最优/ 最差节目统计等,从而准确掌握对各个节目的走势分析;
2. 对各个节目进行讨论的观众群体分析(如平均年龄、男女比例、地域划分等),从而得到对节目受众群体的准确认识;
3. 对热门话题的词云分析,找出出现频率较高的热点单词,从而能够实时搜集关注热点,并对热点问题进行回答或进行正确的舆论引导;
4. 采用k-means算法对同一节目的观众以话题或相似指标进行观众聚类,从而能够根据不同观众群体的不同关注度来精确投放广告,以获得最大效益;
5. 采用回归分析的方法,将节目与观众特质的内在联系用数学函数的形式表现出来,从而理解不同的节目设置与其对所收看的观众群体的影响。
2.7 数据可视化界面实现
数据可视化模块是本系统的最后一步,负责将数据以用户友好的方式呈现给广电系统的相关管理人员。如图4所示,其具体表现为一个直观的网页形式。其中前端页面以HTTP请求的方式通过Rest API接口与服务后端交互,从而取得分布式数据库中的相关数据。根据这些分析统计得到的数据,在页面以多种图形的方式,实时显示分析结果。这些结果包括但不仅限于:
1. 节目关注度及排行;
2. 特定节目关注度走势与所有节目平均走势;
3. 实时热点话题分类;
4. 观众年龄、性别、地域分析;
5. 实时热点话题词云分析;
6. 每个节目的实时热点用户评论更新;
7. 观众评论的实时情绪分析;
8. 观众评论的实时政治敏感度分析。
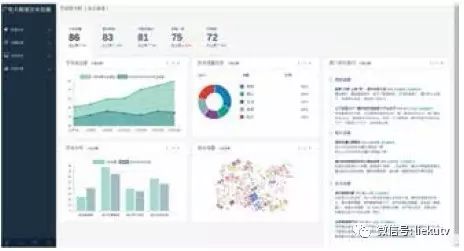
图 4 数据可视化界面与最终平台实现
3 系统部署与实施
在具体试点系统实施中,我们使用2台服务器构建一个小型集群,每台物理服务器配有2TB 硬盘,64GB内存,Intel Xeon E5系列4核2.9GHz主频CPU。操作系统使用Ubuntu 16.04 server 版,并在每台服务器上使用安装脚本自动安装并配置Spark、HDFS、Kafka、Cassandra 以及开发环境(包括Java、Python、Vim、NodeJS 等)。物理机之间通过千兆网线连接,并通过一个万兆路由器连接公有网络。为保证广电内部网络的安全,我们也在路由器上设置了数据的单向性,即只允许HTTP数据请求由我们的服务器发出,从而屏蔽所有来自外部的数据请求。在试点期间,我们平均每日从新浪微博、本地论坛、百度贴吧、优酷评论等数据源,通过分布式网络爬虫脚本抓取超过50 万条源记录,并进行处理。
按照第三章所述的工作流程设计,我们最终将分析结果通过数据可视化界面模块,以图4 所示的直观的方式呈现在广电系统的管理与策划人员的面前。目前系统涵盖小新说事、嘉兴新闻等5项嘉兴广电集团的具体栏目,分析内容包括节目关注度、热点话题分类、政治敏感度分析、观众分类、热点话题关键字云等。当然,这是一个可以不断升级和完善的系统,根据实际需求对界面进行修改,对内容进行增减。
4 广电大数据挖掘的效益分析
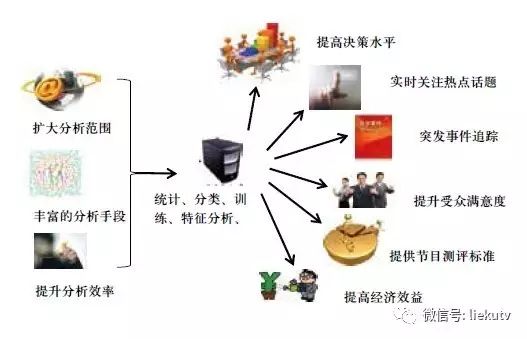
如图5所示,本系统的实现将能为传统广播电视行业的内容价值评估带来全方位的提升。概括来说,首先,系统所能收集到的观众反馈数据更多样化,覆盖更全面。其次,通过领先的人工智能与机器学习技术,能够对海量数据进行更完整更全面的分析与统计。最后,通过这些统计数据,我们能得到更多的可视化图形,并在此基础上得到对广播电视节目更多的启发。因此,本章将从观众反馈数据覆盖度、大数据处理的创新性、以及分析结果的全面性,三方面对广电本文大数据挖掘系统进行效益分析。
图5 广电大数据系统效益示意图
4.1 观众反馈数据的覆盖度与实时性
从数据输入的层面来说,首先,广电大数据系统扩大了观众反馈数据的分析范围。传统方法只是基于进行抽样调查,而通过我们的广电大数据分析系统也能够对观众在互联网上发表的各类海量文本内容进行分析。从有限的样本扩大到海量样本,从而获得更准确、全面、实时的信息。在用户越来越多地使用网络平台发表自己声音,探讨热点话题的时代,只有对大范围的多源数据进行汇总分析,才能真正更加了解观众的心声。
其次,广电大数据系统也丰富了对观众数据分析的手段。传统方法下,广电数据分析方法只对观众的人数、性别、年龄进行简单统计。而本系统可以分析观众的所思所想所关注,实时搜集关注热点,并对热点问题进行回答或进行正确的舆论引导,从而提供全方位的测评标准。
最后,系统也同时提升了分析的效率,由传统的人工参与、人工统计与计算、人工书写报告,改进成为计算机收集信息,自动分析,与自动生成报告,从而节省了大量的人力物力。
4.2 广电大数据处理的创新性
在广播电视海量观众文本数据的信息处理方面,本系统是广播电视行业中首次将人工智能、机器学习、与语义分析等领域的诸多技术,成功整合到一个完整系统的积极尝试。
从技术实现的层面上来说,广电文本大数据挖掘系统涉及到多个科学技术领域,包括数据库、信息检索、信息提取、信息分类、自然语言处理、分布式计算、统计分析、组合优化等。这些技术领域的实现,每一个都具有自己独特的创新性。而我们更是在此基础上,将这些技术领域内包括网络爬虫、分布式消息队列、分布式哈希表、朴素贝叶斯网络、POS分词、词向量模型、神经网络、PCA 主元分析、SVM 支持向量机、K-means 无监督分类、回归分析等具体技术完整实现并有机地协调起来,最终用于实现广电大数据的整套工作流,则是将技术实现的创新性更提升到一个新的层次。
从系统应用的层面上说,在如今的大数据时代,传统广电行业面临互联网等新媒体的激烈挑战,如何实现广播电视行业与新媒体的双赢局面,是当前广电所面临的一大难题。而本系统的目标,则正是致力于解决这一难题。系统的实现流程和技术应用方法,为在广电领域内的大规模应用与进一步推广提供了可行的技术依据。
4.3 广电大数据分析结果的全面性
基于更全面的观众数据收集与更先进的信息处理方式,本系统能够将分散、零碎堆积的海量数据内容进行有效地整合,并将分析结果以最有意义、最直观的方式呈现在广电系统的管理与策划人员的面前。具体来说,透过这些分析,播出的节目可以得到更科学、更准确、更全面的评价,从而为节目的改善改进提供有力的依据。我们的记者可以根据所检测到的实时热点话题与热点评论,对突发事件、热点时间进行快速追踪,从而得到第一手全方位的报导。节目策划人员也可根据实时观众反馈数据和热门评论,打造出热门的跨媒体的实时互动节目,创造具有广泛关注性的节目内容,创作出更能满足观众的需求、更具网络传播特性的节目。广电节目的广告投放商则可根据不同节目的不同观众群体和其行为,为节目精准设计并投放广告,从而提高经济效益,并同时提升观众满意度。广电系统的领导更可以根据数据分析的结果,快速、有效地调整节目安排策略,和相应的人员配置调整,从而做出更科学、更有前瞻性的决策。
5 总结
以用户为中心并不是一个新鲜的议题,但互联网时代赋予了用户更多的权利与意义。对媒体而言,必须时刻清楚自身用户是什么人、用户的需求是什么、如何满足需求等。据报道,脸书(Facebook)正在计划推出多样的情绪按键,并已在西班牙和爱尔兰测试。脸书CEO马克扎克伯格(Mark Zuckerberg) 说:“人们有时想表达同情或同感,并不是所有的内容都可以‘赞’”。我们的文本挖掘,正是有着无数情绪按钮的系统,不但可以知道有多少个赞,还是一种可以了解人们的具体想法和真实情感的新手段,是一个受众深度洞察的工具。
通过文本挖掘我们可以看到《钢铁侠》里的情景将变为现实:计算机像帮助钢铁侠那样帮助记者,自动提供最新的信息,告诉记者哪有突发的事件,哪发生了什么大众感兴趣的事。通过文本挖掘掌握了大量的信息后,我们的记者就把某个事件看得更加清楚与全面,事件复杂的演进过程以及这个过程中的各个方面,都能描述得直观且有趣 [11]。未来真正高效强悍的全能记者,应该是那些善于借助“机器人”的人。
据美林公司(Merrill Lynch) 和高德纳公司(Gartner) 联合进行的一项调查表明,85% 的企业数据或多或少是以无序的方式收集储存的。广播电视是一个每天都产生大量的信息的领域,用文本挖掘的方法,搭建起一个媒体研究的创新平台,通过这个平台,我们可以从大量无序的信息中提取有用的内容,经过对文本信息的抓取、过滤、挖掘及分析,能够高效且有效地挖掘文本数据背后的资源,完成对媒体现状和我们所关注问题最全面的分析报告。助力媒体腾飞。
广电媒体要深刻认识自身所处的发展阶段,直面新媒体带来的挑战,抓住时代带给我们的机遇。通过利用技术手段来达到受众面增加不仅是一种创新,更能顺应发展的需要,可以毫不夸张地说,将文本挖掘用于广播电视领域将是是一种全新的尝试,在此基础上建立起来的这个系统将成为提高媒体竞争力的一项重要手段。
参考文献
[1] Newman, Nic. Journalism, media and technology predictions 2016 [ J]. Reuters Institute for the study ofjournalism, Oxford University Press, 2016(4).
[2] 李宇. 数字时代收视率调查的挑战与变革——以美国尼尔森公司为例[J]. 中国广播电视学刊 2014(3).
[3] Apache Spark, Lightning-fast Cluster Cmputing [ Online].http://spark.apache.org/ 2016-11-07.
[4] Apache ZooKeeper [ Online] https://zookeeper.apache.org/doc/r3.4.9/ 2016-04-09.
[5] Apache Kafka, A Distributed Streaming Platform [ Online].https://kafka.apache.org/ 2016.
[6] Apache Cassandra, Manage Massive Amounts of Data Fast[Online]. http://cassandra.apache.org/ 2016.
[7] Apache Hadoop, Hadoop Distributed File System ( HDFS)[Online]. https://hadoop.apache.org/docs/stable/hadoop-projectdist/hadoop-hdfs/HdfsUserGuide.html 2016-01-26.
[8 NodeJS.[Online] https://nodejs.org/en/ 2016.
[9] AngularJS. Superheroic JavaScript MVW Framework [ Online].https://angularjs.org/ 2016.
[10] Mikolov, Tomas, Ilya Sutskever, Kai Chen, Greg S. Corrado,and Jeff Dean. Distributed representations of words and phrases and their compositionality [J]. In Advances in neural information processing systems, 2013:3111-3119.
[11] 陈力丹,李熠祺,娜佳. 大数据与新闻报道[J],新闻记者,2015(2).
俞冶,女,1959 年出生,高级工程师,就职于浙江省嘉兴市广播电视集团总工办。近年在《第二十届国际广播电视技术讨论(ISBT2015)论文集》发表了“利用BloomFioter 优化广电云内容路由”一文,在《广播与电视技术》上发表了“云媒体融合电视的解决方案的研究与实现” 一文。
有话要说?关注"广电猎酷",可在文末写留言:)
以上是关于精品大数据文本挖掘在广播电视中的应用与探索的主要内容,如果未能解决你的问题,请参考以下文章