AlphaWolf—狼人杀中的文本挖掘应用
Posted 木小东和他的朋友们
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AlphaWolf—狼人杀中的文本挖掘应用相关的知识,希望对你有一定的参考价值。
1. 概况
这学期选修了《大数据中的文本挖掘前沿专题:应用与实践》,课程内容包括介绍NLP领域的一些研究方向以及最近几年来深度学习在NLP领域的应用等等。课程最后的考核形式是组队完成自命题大作业,我和数院的两名童鞋一起组了队(Team JZC)开始搞起。大作业的创意来自CY同学,提出最近狼人杀这款游戏大火,我们可以利用学到的一些NLP相关的知识去分析狼人杀游戏产生的语料看看能出什么成果。大家一致认为这个课题挺有意思,于是开始研究可行性。
PPT中间即我们项目的logo,是AlphaGo的logo与狼人杀logo的结合体:)
下面是百度百科对狼人杀的定义:
狼人杀,是一款多人参与的、以语言描述推动的、较量口才和分析判断能力的策略类桌面游戏。狼人杀属于桌面游戏,通常的版本需要8-18人参与。游戏分为两大阵营,狼人和村民;村民方以投票为手段投死狼人获取最后胜利,狼人阵营隐匿于村民中间,靠夜晚杀人及投票消灭村民方成员为获胜手段。
—— 百度百科
从狼人杀游戏的描述中我们可以发现游戏有几个特点,即“语言描述推动”,“策略类”,“两大阵营”,分别对应了NLP、RL、Discriminative Model这几个领域,可以说狼人杀游戏是一个多领域交叉的问题。一开始我们想利用增强学习和深度学习结合来实现狼人杀的最优归票策略,期望的效果是每一轮发言过后模型可以根据场上局面和发言情况给出各个玩家是狼人的概率,所以我给项目取名为AlphaWolf,当做对AlphaGo的一种致敬:),但是后来我们仔细调研后发现这个问题绝对不简单,以我们三个人和一个月不到的准备时间很难实现,所以后面我们对方向进行了调整。
这里放下汇报时的PPT辅助讲解:

2. 数据
我们首先要采集一些狼人杀的对局数据,这里我们采用了熊猫直播PandaKill的数据,主要是由于PandaKill中选手基本按照规则进行比赛,各个选手按顺序发言,比赛节奏比较好,因此数据质量比较高。

需要注意的是,狼人杀游戏中是通过发言来表达观点,因此还需要将语音数据转化为文本数据才能进行分析。为了减少工作量,我们直接利用了讯飞听见提供的语音识别接口,将语音数据转化成了文本。
整个数据预处理流程如下:
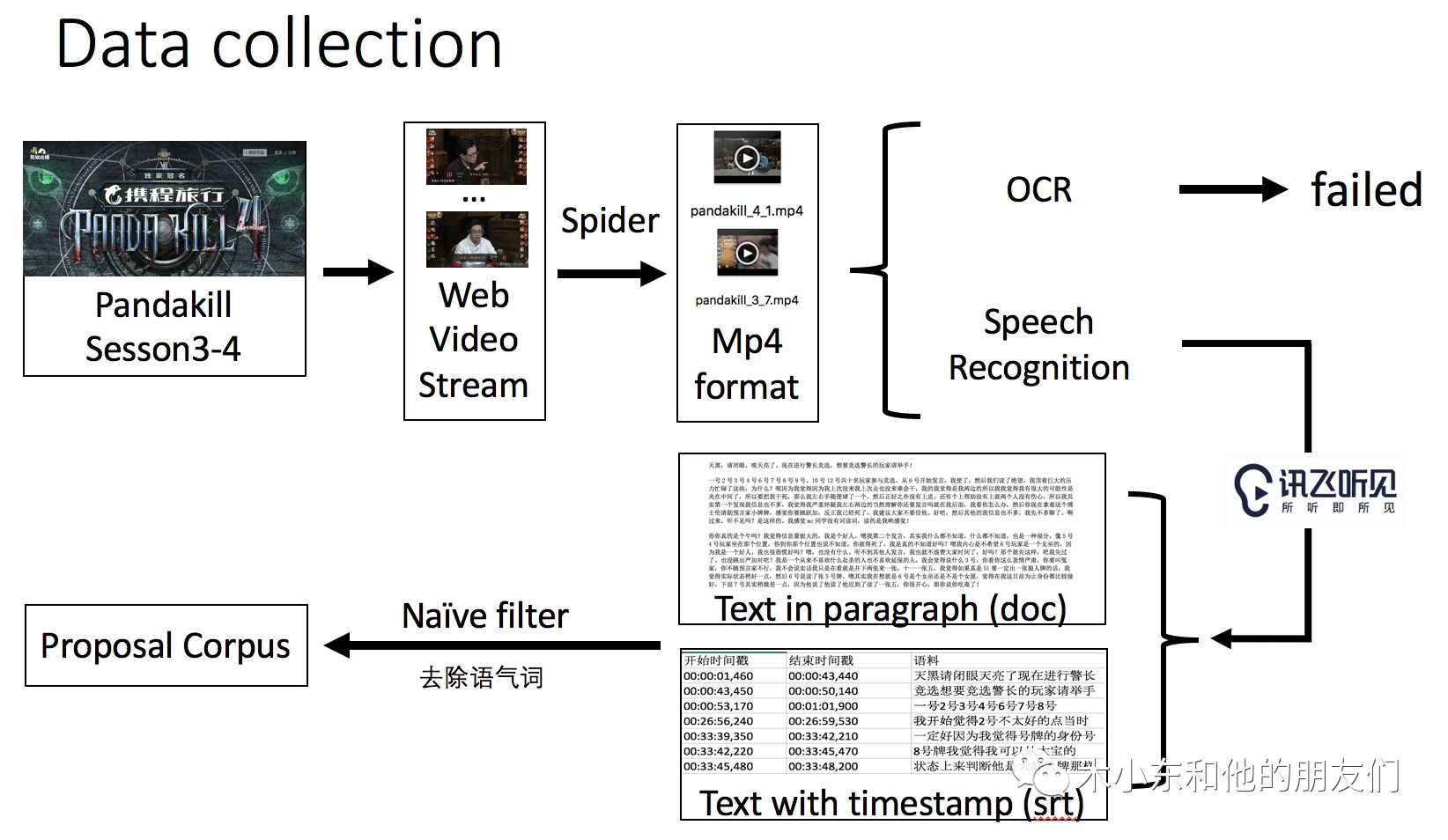
由于我们在后续任务中需要训练一些监督学习模型,因此我们还需要进一步对数据进行标注,这部分稍后会介绍。
3. 任务
从目前采集到的数据以及我们的时间精力等出发,我们将本次大作业的目的分解为两大任务:
Task 1 :Sentiment Analysis,即对每个选手的发言进行情感分析,提取其发言对象及其态度。
Task 2 :Dialoge Cluster,即对所有选手在该局游戏中的发言进行无监督的聚类,了解其社群分类(在狼人杀游戏中即为好坏两大阵营)。
针对以上两类任务,我们需要比较充分的数据标注规则,这样一来可以满足当前的人无需求,另一方面也可以为后续的工作提供数据源。我们的标注规则如下:

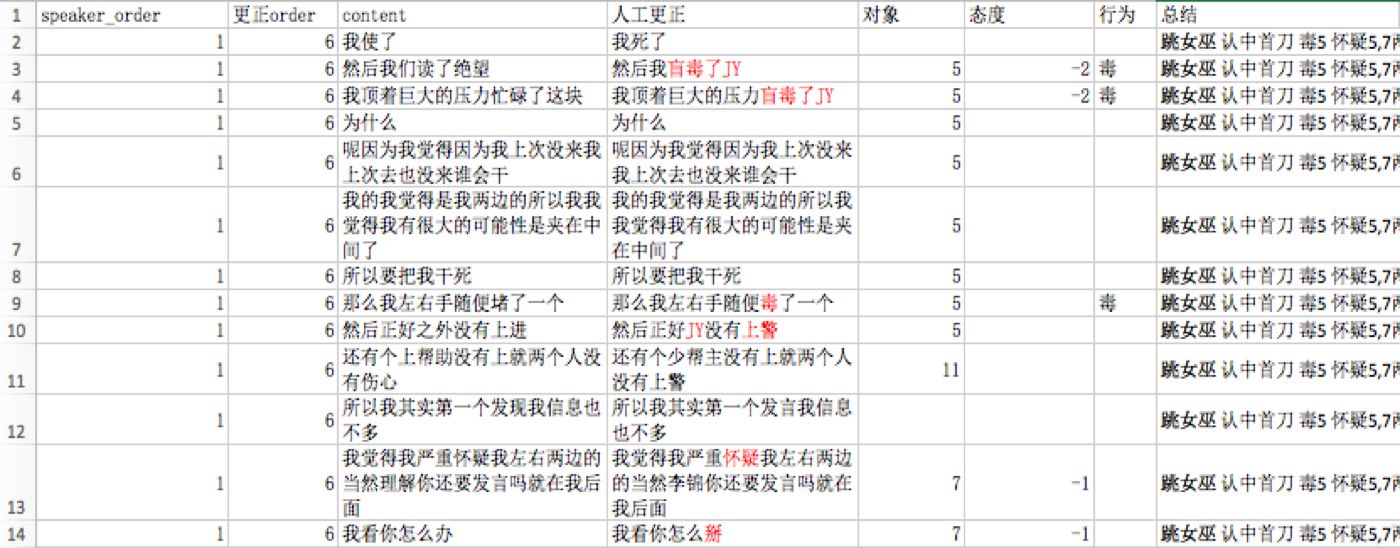
我们采集了pandakill第3季度及第4季度(截止至第1集)的视频,选择了其中第四季度第一集的三局游戏进行分析。其有效游戏时长共4小时37分钟,语音转化及去除语气词后,共6028条发言,经过人工修正及标注的数据共3953条。部分标注数据如下图:
下面开始介绍各个任务的具体实现。
4. 模型
Task 1 sentiment analysis
task1和传统的情感分析存在一些异同,其难点和容易点列举如下:
- 容易点:
词库小 :
在2165句语料中,只出现词1579个
出现10次以上的高频词仅244个
表达形式固定 :
我认***是好人/狼人
在我这***身份高/低
...
- 难点:
逻辑性强 :
我不认为9号就一定不是好人
“我认为他是好人”与“他认为我是好人”
...
部分句子情感模糊 :
9号10号出一狼一预言家
我不认为1 2出两狼,我觉得至多只出一狼
...
一开始我们尝试了SVC+词袋向量的模型,即首先利用词袋模型将句子化为向量,然后用SVC模型对句子进行分类,但是结果惨不忍睹:
| 混淆矩阵 | -1 | 0 | 1 |
|---|---|---|---|
| -1 | 7 | 15 | 1 |
| 0 | 4 | 179 | 7 |
| 1 | 0 | 12 | 10 |
可以看到有情感倾向的句子基本都没有分对,只有少数几个判断正确。我们分析了一下可能的原因:
词袋向量忽略了单词顺序
普通情感分类起决定作用的是情感词
狼人杀情感分类起决定作用的是词序
分析问题原因后我们进行了以下调整:
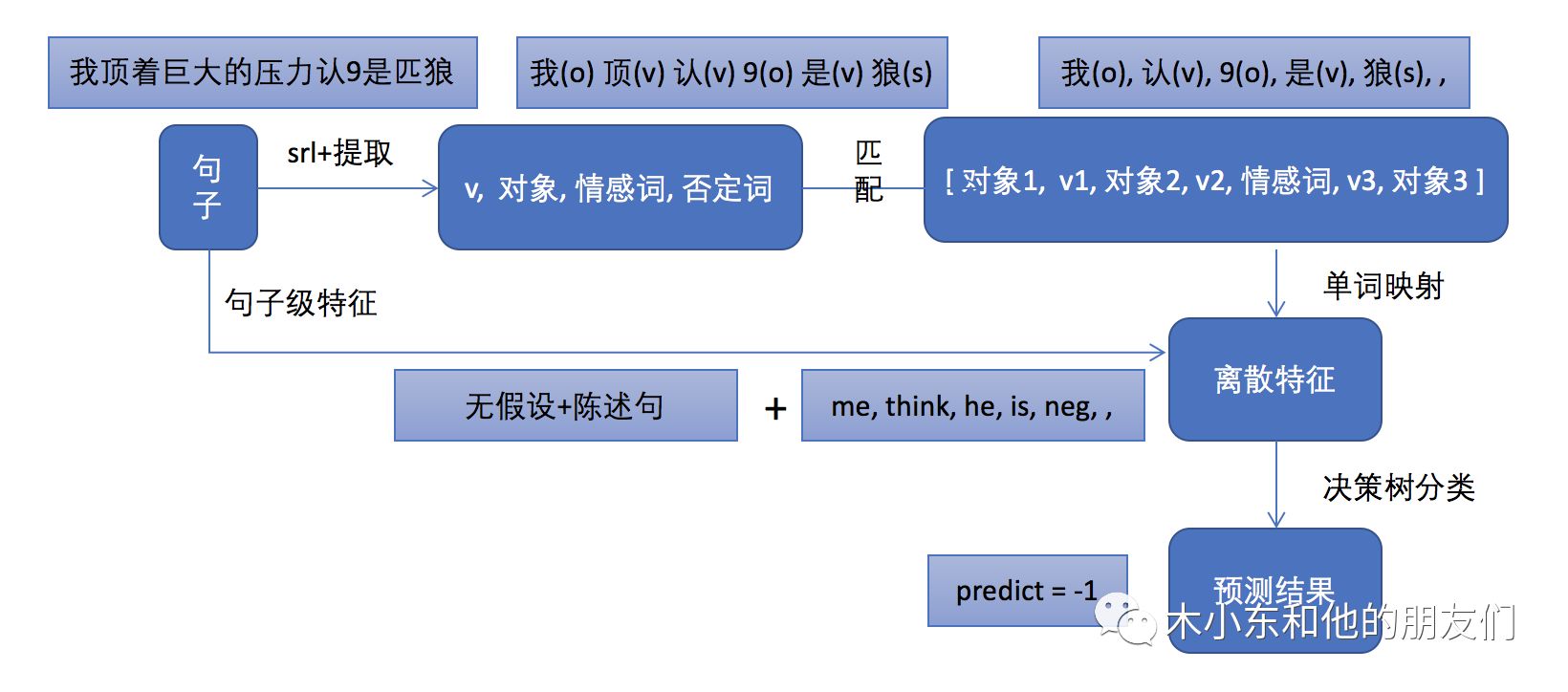
即采用了传统NLP领域中的句法分析的思路,提取情感对象和态度关键词。此外,我们还发现单词映射这个trick对于这种特定领域情感分析的问题很有用,我们进行单词映射的规则是:
对象词
我 --> me
你 --> you
他 她 *号 --> he
动词
觉得 认为 认 ... --> think
是 像 就是 ... --> is
其它 --> unimp
情感词
金水 好人 ... --> pos
狼 坏人 ... --> neg
采用上述几种优化措施后,我们模型的效果得到了提升:
| 混淆矩阵 | -1 | 0 | 1 |
|---|---|---|---|
| -1 | 50 | 22 | 2 |
| 0 | 39 | 160 | 8 |
| 1 | 4 | 17 | 53 |
其他一些指标如图:
| Metric | precision | recall | F1-score | support |
|---|---|---|---|---|
| -1 | 0.54 | 0.68 | 0.60 | 74 |
| 0 | 0.80 | 0.77 | 0.79 | 207 |
| 1 | 0.84 | 0.72 | 0.77 | 74 |
| avg/total | 0.76 | 0.74 | 0.75 | 355 |
总结一下最终模型效果提升的原因:
模板匹配:限定了词数(特征维数)为7
单词映射:限定了每维取值
将句子转化为7维的离散特征,模型抗干扰能力更强
Task 2 dialoge cluster
我们设计task2的目的是想无监督的从所有玩家的发言中学习到不同阵营的发言模式,设计pipeline如下:
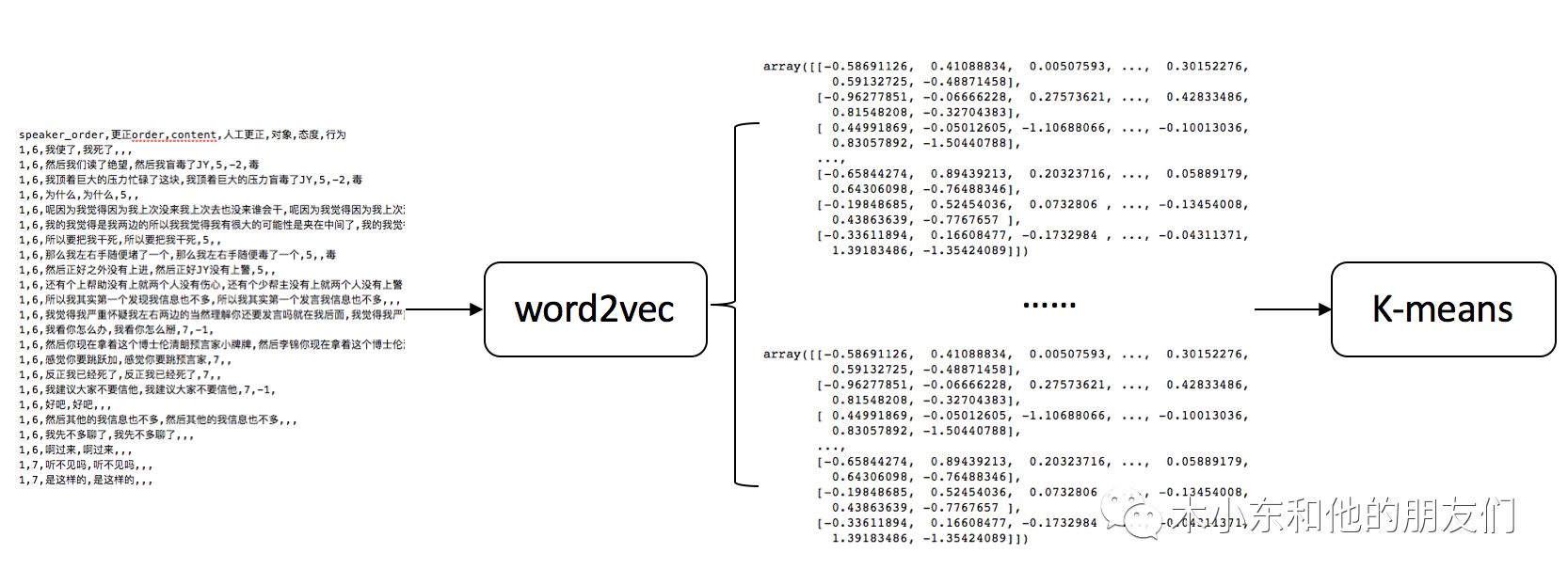
首先我们需要将文本数据映射为词向量,这里我们利用了word2vec进行训练。词向量的训练集主要有两个来源,第一个是我们自己标注的数据,另一来源则是搜狗开放的大规模中文新闻数据集。我们分别在这两个数据集上进行训练来比较效果。
sogou新闻数据集
Sogou新闻数据训练word vector
2012年6月—7月期间国内,国际,体育,社会,娱乐等18个频道的新闻
1294233条,1.53 GB
www.sogou.com/labs/resource/ca.php
训练词向量利用了Python的gensim库,参数采用了默认的参数,并没有精细调参:
feature_size = 400
window = 5
min_count = 5
workers = cpu_count()
1080ti, i7-6800k, 32G RAM, 30 minutes to train
训练好词向量后我们先测试一下:
result = model.most_similar(u'狼人')
for word in result:
print(word[0], word[1])
结果如下:

这都是模型认为和'狼人'这个词相似度比较高的一些词。
接下来我们可以把玩家发言的语料转化成词向量,利用k-means进行聚类。聚类结果如下图所示:
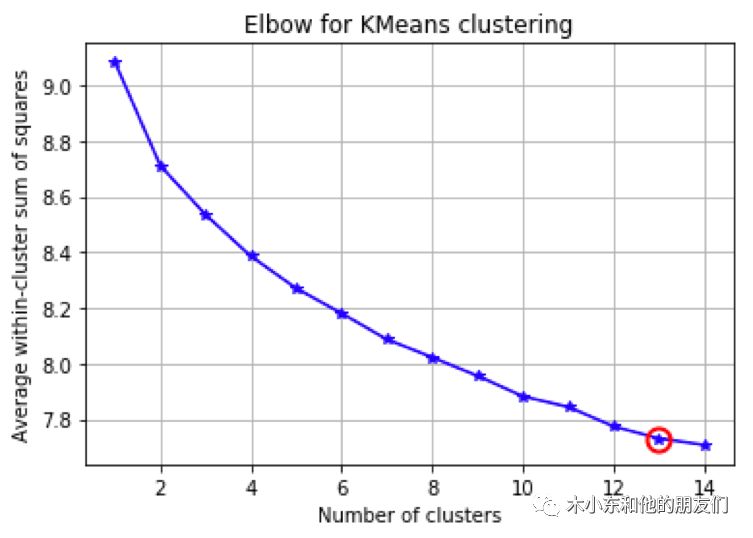
可以发现组间方差图在k=12时有个波动且下降趋势减缓(图中红点左侧),因此k=12是一个比较好的参数。而每一局狼人杀玩家的数量也是12!说明模型在无监督的情况下将玩家发言分成了12个类别,也就是说模型学习到了玩家发言的”风格“。目前还不知道这是否为巧合,我们今后还需要用更多的数据来验证这一结果。
我们又对原有的word2vec词向量的特征进行了压缩,绘制了tsne图:
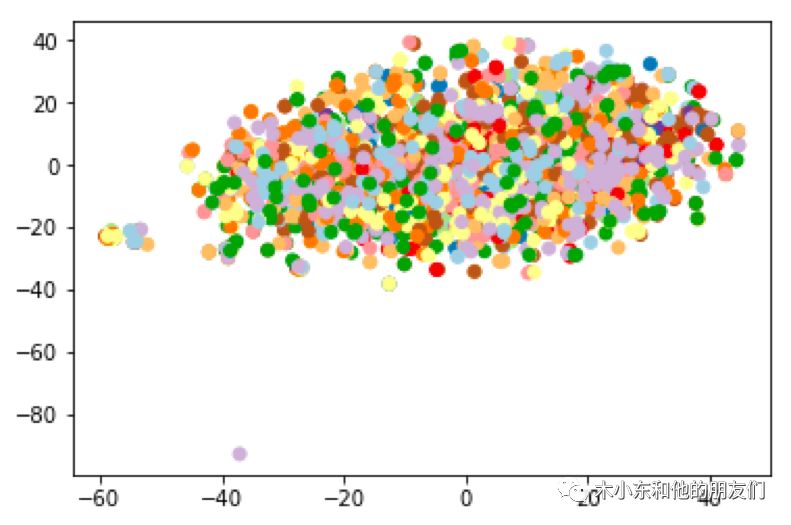
从tsne图中发现特征提取效果并不理想,即word2vec学习到的特征并没有很好的在低维度空间将文本分开。我们对其中的离群点记性了验证,比如图片中下方浅紫色的点,其对应的句子是"I don't know"这句英文:

可以发现在sogou新闻数据集上训练的词向量并不特别适用于狼人杀这个问题,因此我们还需要在狼人杀相关的语料上训练word2vec词向量。
狼人杀游戏语料数据集
狼人杀语料训练word vector
2017年第四季第一集, 有效时长4小时37分钟
有效语句6028条, 已标注3953条

训练采用的参数和在sogou上训练使用的一样,都是gensim中的默认参数。
同样的,我们测试一下词向量模型找到的和”狼人”这个关键词相似度较高的词:

以上都是模型认为和'狼人'这个词相似度比较高的一些词,我们可以发现由于训练语料较小,因此这些词的相似度取值都比较高,其中大多数为玩家编号,这些编号确实是经常与“狼人”这个词出现在上下文中。
将文本通过新的word2vec模型转化为词向量后,我们绘制其tsne图:
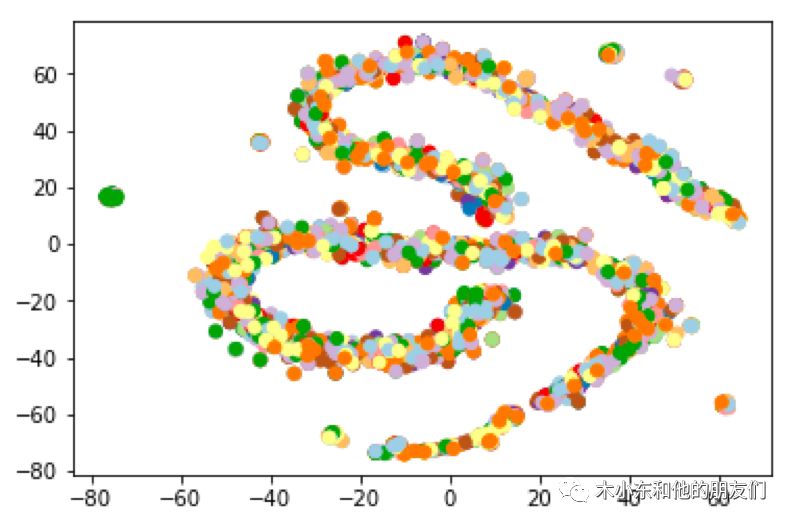
我们可以发现这回模型学习到的特征应该上一个模型要好,在低维空间很好的将文本分为了两大类,很可能对应着好坏两大阵营,我们后续还需要进一步验证。
5. 结果及展望
最后我们还开发了web app将模型应用于实时(伪)的语料上,如下图所示:
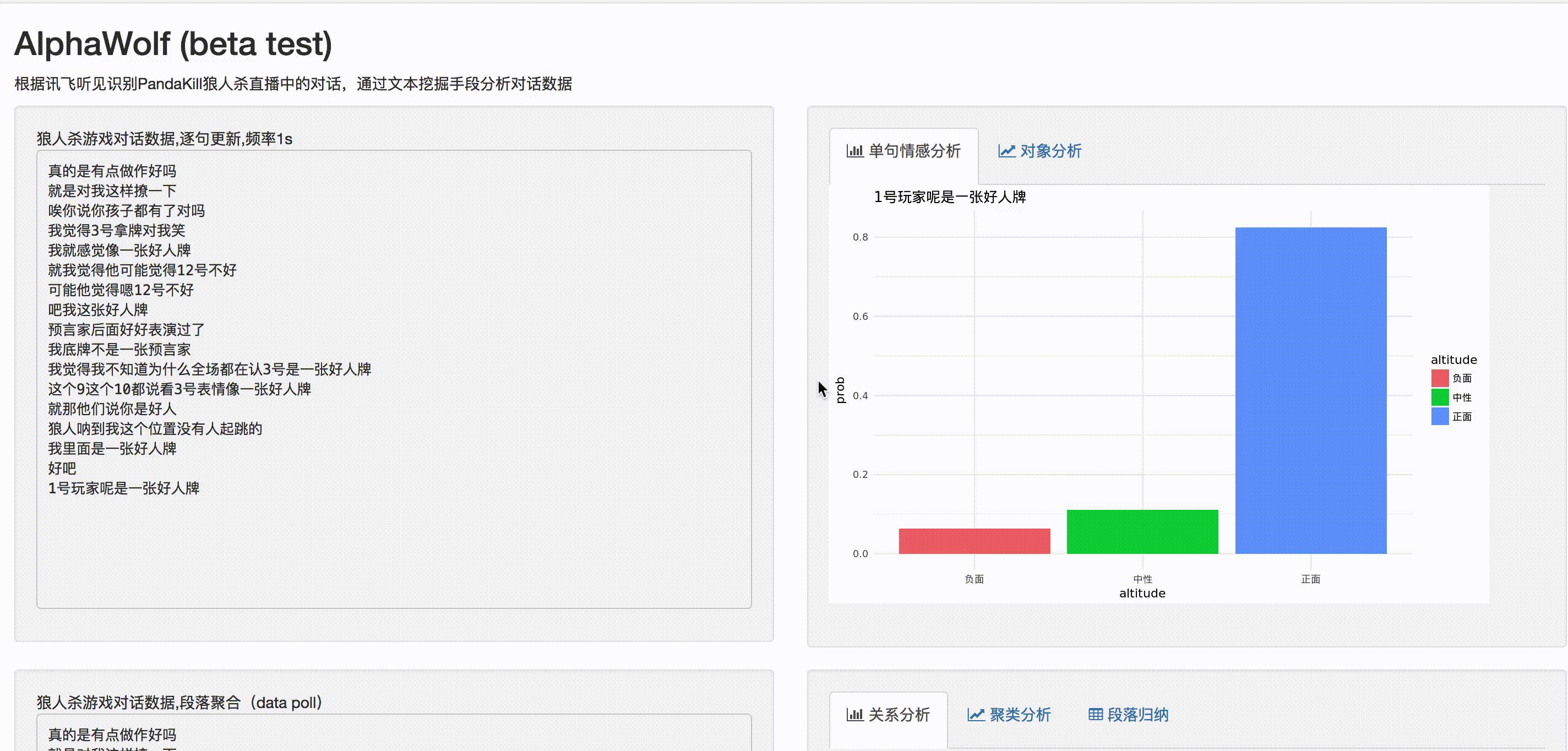
左侧为流式更新的玩家发言数据,右侧图表是模型判断的该语句针对的玩家和相应的情感态度。demo基于R+shiny开发,详情可以戳:https://jjdblast.shinyapps.io/AlphaWolf
后续还需要继续深入的部分主要有三点:
完善对象提取功能
增加训练数据集数量
实现玩家发言的自动摘要
其中,对象提取功能目前是实现了一个chord diagram,以前三轮发言结束后时为例:
这张图是三轮过后玩家之间的情感倾向图,其中T+编号代表情感的针对方,S+编号代表情感的发出方,红色代表肯定情绪(即认好人阵营),绿色代表否定情绪(即指认为狼人阵营),白色代表中立。目前这张图的实现还是依靠linguistic的一些传统方法,我们希望随着数据量的增加能够自动生成类似的情绪网络。
另外,我们还希望实现自动摘要,即对玩家一轮的发言进行总结。熊猫TV的pandakill中有人工的总结标签,因此我们希望能利用深度学习方法进行Auto Summarization。在这门课程的第一次作业中,我们小组已经实现了一个结合抽取式摘要模型以及RNN+attention模型的集成模型,效果很好,如果我们继续扩充狼人杀游戏的数据,就可以尝试利用集成模型实现玩家发言内容摘要。
最后是项目的代码及demo:
项目代码:https://github.com/jjdblast/AlphaWolf
项目demo:https://jjdblast.shinyapps.io/AlphaWolf
以上。
以上是关于AlphaWolf—狼人杀中的文本挖掘应用的主要内容,如果未能解决你的问题,请参考以下文章