如何优雅的用十分钟对Pubmed文本挖掘掌握研究现状?
Posted 小张聊科研
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何优雅的用十分钟对Pubmed文本挖掘掌握研究现状?相关的知识,希望对你有一定的参考价值。
转眼2018年即将结束啦,白介素2同学年度最后一稿,实用有效上干货。
生命医学领域鼎鼎有名的Pubmed,当然大家是很熟啦,无论是开题,还是申请基金,当然是少不了文献查阅的。Pubmed虽好,却多有不便。比如像小编这样查阅下某个分子,某个领域的研究现状:
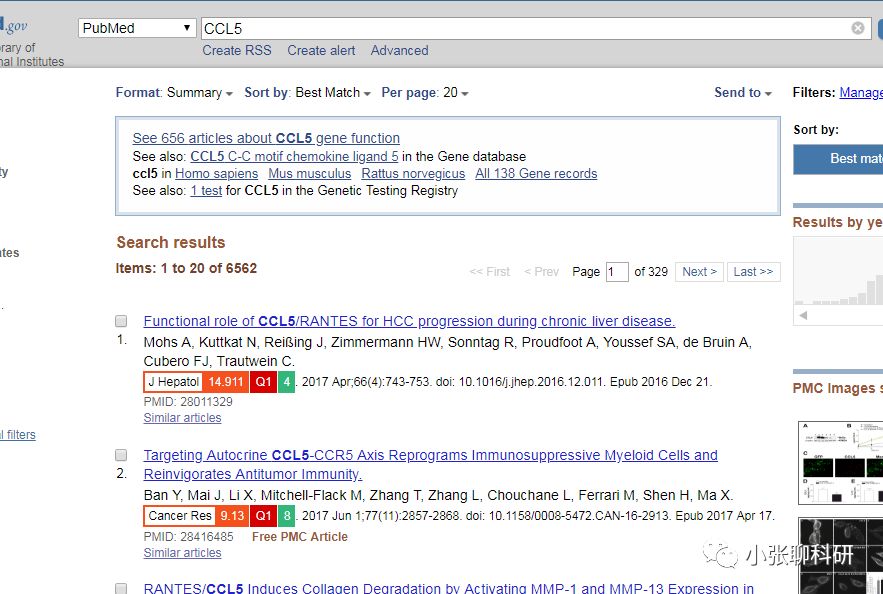
一看结果6000多篇,这时Pubmed本身提供对文献进行适当的精简,比如按时间,按文章类型,于是小编设置了物种human,时间5years。
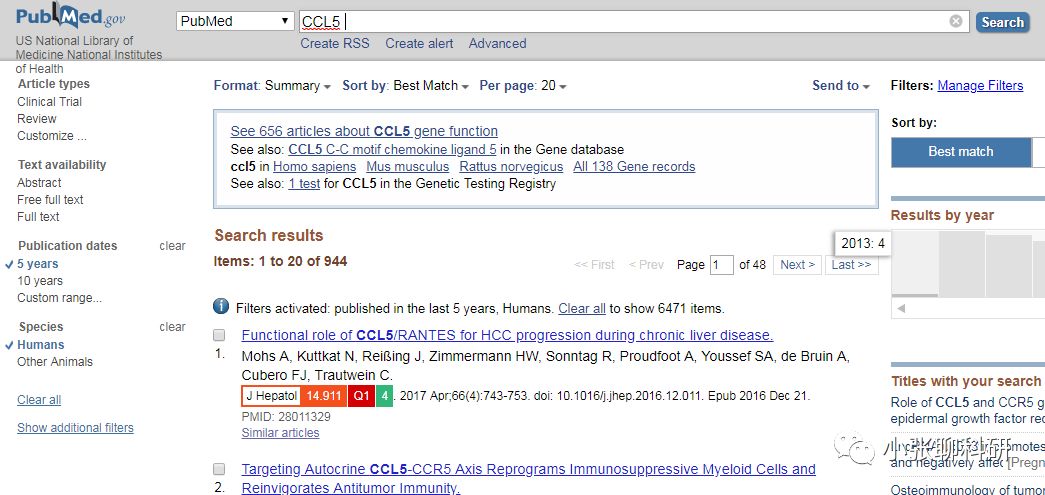
一看结果,还有900多篇,可咋办,总不能一页页在pubmed上点击吧,也不能随时排除不需要的,也不好全导入到endnote去吧,况且就算要导入也每次只能导入200。那白介素2同学就想,有没有办法一次性的,检索到的Title一次性的导入到excel,然后再愉快的阅读标题嘞,经过一翻检索,调试之后,当然是找到啦,特地分享给大家!
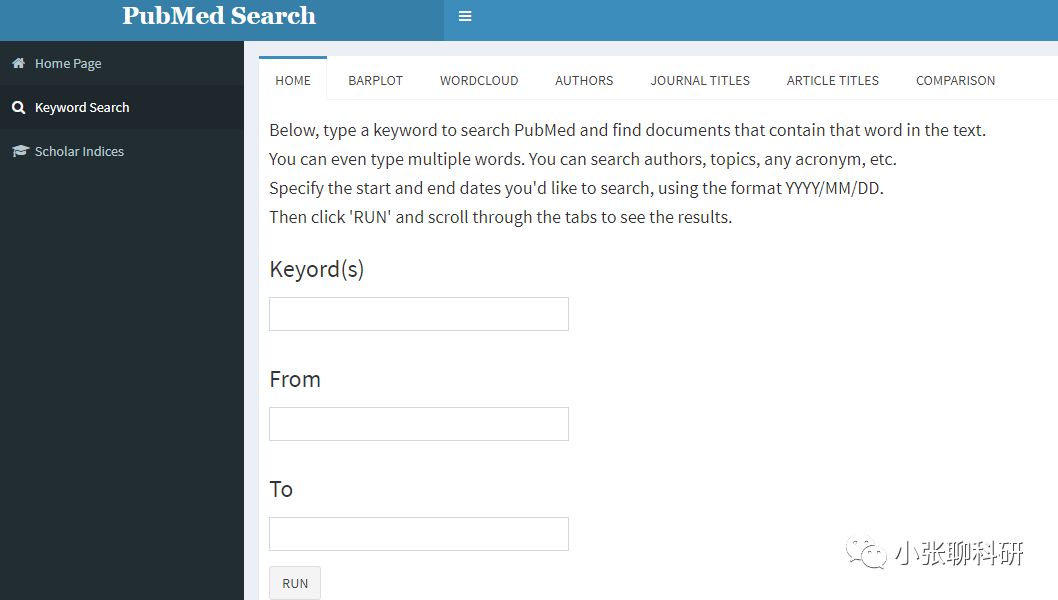
本身是有网页版的可供点击操作的(网址:https://aarongowins.shinyapps.io/PubMedSearch/),很无奈小编同学截止写稿仍然是服务器无响应,那没办法,小编同学只好用作者提供的R包来完成啦,小编同学就随便检索了关键词 “lncRNA”,然后导出几个感兴趣的,发表时间,杂志,文章标题,见下图:

当然除此以外,如需要还可获取很多其它信息,比如作者,接收日期,摘要内容,机构信息,杂志,那这些信息有好处嘞?
随便举个例子,你可以看下感兴趣的领域一般发表在什么杂志呀,最牛的是哪些文章呀,哪些机构呀? 这样一来是不是心中有数啦,Pubmed上翻网页的日子将一去不返,翻完又忘了(绝望)。如果还感兴趣还可以做一些可视化看下,词云等等等看下研究的热点是啥?
比如,这是白介素同学做的柱状图图,看了下2015-2018年,关于lncRNA发表的文章数目,很显然啦,lncRNA的文章自然是越来越多,逐年递增。
另白介素2同学附上R代码(含注释),如有基础者可愉快的使用啦!(没有R基础的小伙伴们,wuwuwu对不住啦,我尽力了)
##Pubmed 文本挖掘
library(RISmed)
##限定下检索主题
search_topic <- c('lncRNA')
search_query <- EUtilsSummary(search_topic,db="pubmed", retmax=10000,datetype='pdat', mindate=2013, maxdate=2018)
##查查看下检索内容
summary(search_query)
##看下这些文献的Id
QueryId(search_query)
##获取检索结果
records<- EUtilsGet(search_query)
class(records)
str(records)
##提取检索结果
pubmed_data <- data.frame('Title'=ArticleTitle(records),
'Year'=YearAccepted(records),
'journal'=ISOAbbreviation(records))
head(pubmed_data,1)
pubmed_data[1:3,1]
write.csv(pubmed_data,file='lncRNA.csv')
##分析lncRNA文章情况
y <- YearPubmed(EUtilsGet(search_query))
##可视化一下
library(ggplot2)
date()
count<-table(y)
count<-as.data.frame(count)
names(count)<-c("Year", "Counts")
p<-ggplot(data=count, aes(x=Year, y=Counts,fill=Year)) +
geom_bar(stat="identity", width=0.5)+
labs(y = "Number of articles",title="PubMed articles containing lncRNA"
)+
scale_fill_brewer(palette="Dark2")
p
长按二维码识别关注“小张聊科研”
关注后获取《科研修炼手册》1、2、3、4、5、6、7,8。
以上是关于如何优雅的用十分钟对Pubmed文本挖掘掌握研究现状?的主要内容,如果未能解决你的问题,请参考以下文章