dfs题目这样去解题,秒杀leetcode题目
Posted 程序员的技术圈子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了dfs题目这样去解题,秒杀leetcode题目相关的知识,希望对你有一定的参考价值。
“
这是本人第45篇原创博文,每周至少两篇更新,谢谢赏脸阅读文章
今天来聊聊 dfs 的解题方法,这些方法都是总结之后的出来的经验,有值得借鉴的地方。
1 从二叉树看 dfs
二叉树的思想其实很简单,我们刚刚开始学习二叉树的时候,在做二叉树遍历的时候是不是最常见的方法就是递归遍历,其实,你会发现,二叉树的题目的解题方法基本上都是递归来解题,我们只需要走一步,其他的由递归来做。
我们先来看一下二叉树的前序遍历、中序遍历、后序遍历的递归版本。
//前序遍历
void traverse(TreeNode root) {
System.out.println(root.val);
traverse(root.left);
traverse(root.right);
}
//中序遍历
void traverse(TreeNode root) {
traverse(root.left);
System.out.println(root.val);
traverse(root.right);
}
//后续遍历
void traverse(TreeNode root) {
traverse(root.left);
traverse(root.right);
System.out.println(root.val);
}
其实你会发现,二叉树的遍历的过程就能够看出二叉树遍历的一个整体的框架,其实这个也是二叉树的解题的整体的框架就是下面这样的。
void traverse(TreeNode root) {
//这里将输出变成其他操作,我们只完成第一步,后面的由递归来完成。
traverse(root.left);
traverse(root.right);
}
我们在解题的时候,我们只需要去想当前的操作应该怎么实现,后面的由递归去实现,至于用前序中序还是后序遍历,由具体的情况来实现。
下面来几个二叉树的热身题,来体会一下这种解题方法。
1. 如何把⼆叉树所有的节点中的值加⼀
首先还是一样,我们先写出框架。
void traverse(TreeNode root) {
//这里将输出变成其他操作,我们只完成第一步,后面的由递归来完成。
traverse(root.left);
traverse(root.right);
}
接下来,考虑当前的一步需要做什么事情,在这里,当然是给当前的节点加一。
void traverse(TreeNode root) {
if(root == null) {
return;
}
//这里改为给当前的节点加一。
root.val += 1;
traverse(root.left);
traverse(root.right);
}
发现是不是水到渠成?
不爽?再来一个简单的。
2. 如何判断两棵⼆叉树是不是同一棵二叉树
这个问题我们直接考虑当前一步需要做什么,也就是什么情况,这是同一颗二叉树?
1)两棵树的当前节点等于空:root1 == null && root2 == null,这个时候返回 true。2)两棵树的当前节点任意一个节点为空:root1 == null || root2 == null,这个时候当然是 false。3)两棵树的当前节点都不为空,但是 val 不一样:root1.val != root2.val,返回 false。
所以,答案就显而易见了。
boolean isSameTree(TreeNode root1, TreeNode root2) {
// 都为空的话
if (root1 == null && root2 == null) return true;
// ⼀个为空,⼀个⾮空
if (root1 == null || root2 == null) return false;
// 两个都⾮空,但 val 不⼀样
if (root1.val != root2.val) return false;
// 递归去做
return isSameTree(root1.left, root2.left) && isSameTree(root1.right, root2.right);
}
有了上面的讲解,我相信你已经有了基本的思路了,下面我们来点有难度的题目,小试牛刀。
3. leetcode中等难度解析
114. 二叉树展开为链表
这个题目是二叉树中的中等难度题目,但是通过率很低,那么我们用上面的思路来看看是否可以轻松解决这个题目。
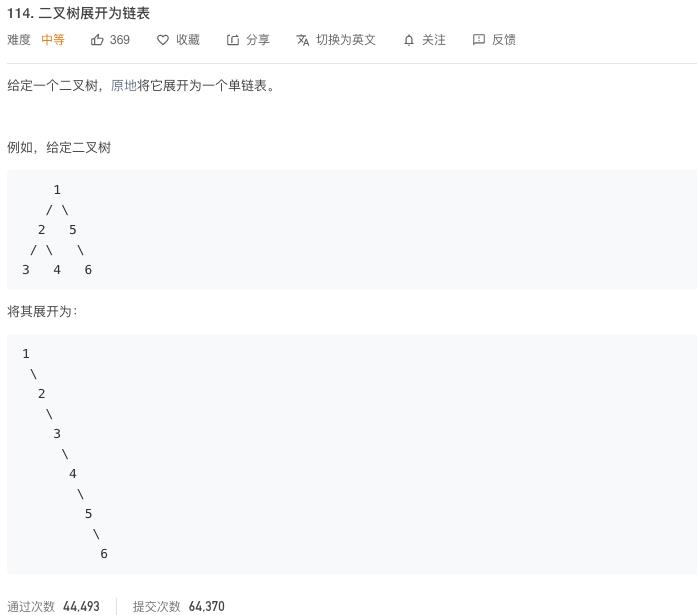
这个题目乍一看,根据前面的思路,你可以能首先会选择前序遍历的方式来解决,是可以的,但是,比较麻烦,因为前序遍历的方式会改变右节点的指向,导致比较麻烦,那么,如果前序遍历不行,就考虑中序和后序遍历了,由于,在展开的时候,只需要去改变左右节点的指向,所以,这里其实最好的方式还是用后续遍历,既然是后续遍历,那么我们就可以快速的把后续遍历的框架写出来了。
public void flatten(TreeNode root) {
if(root == null){
return;
}
flatten(root.left);
flatten(root.right);
//考虑当前一步做什么
}
这样,这个题目的基本思路就出来了,那么,我们只需要考虑当前一步需要做什么就可以把这个题目搞定了。
当前一步:由于是后序遍历,所以顺序是左中右,从展开的顺序我们可以看出来,明显是先连接左节点,后连接右节点,所以,我们肯定要先保存右节点的值,然后连接左节点,同时,我们的展开之后,只有右节点,所以,左节点应该设置为null。
经过分析,代码直接就可以写出来了。
public void flatten(TreeNode root) {
if(root == null){
return;
}
flatten(root.left);
flatten(root.right);
//考虑当前一步做什么
TreeNode temp = root.right;//
root.right = root.left;//右指针指向左节点
root.left = null;//左节点值为空
while(root.right != null){
root = root.right;
}
root.right = temp;//最后再将右节点连在右指针后面
}
最终这就是答案了,这不是最佳的答案,但是,这可能是解决二叉树这种题目的最好的理解方式,同时,非常有助于你理解dfs这种算法的思想。
105. 从前序与中序遍历序列构造二叉树
这个题目也是挺不错的题目,而且其实在我们学习数据结构的时候,这个题目经常会以解答题的方式出现,让我们考试的时候来做,确实印象深刻,这里,我们看看用代码怎么解决。
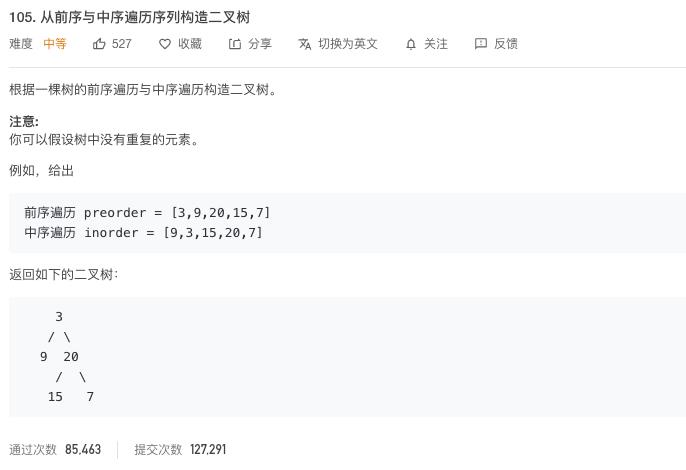
还是同样的套路,同样的思路,已经同样的味道,再来把这道菜炒一下。
首先,确定先序遍历、中序遍历还是后序遍历,既然是由前序遍历和中序遍历来推出二叉树,那么,前序遍历是更好一些的。
这里我们直接考虑当前一步应该做什么,然后直接做出来这道菜。
当前一步:回想一下以前做这个题目的思路你会发现,我们去构造二叉树的时候,思路是这样的,前序遍历第一个元素肯定是根节点a,那么,当前前序遍历的元素a,在中序遍历中,在a这个元素的左边就是左子树的元素,在a这个元素右边的元素就是左子树的元素,这样是不是就考虑清楚了当前一步,那么我们唯一要做的就是在中序遍历数组中找到a这个元素的位置,其他的递归来解决即可。
话不多说,看代码。
public TreeNode buildTree(int[] preorder, int[] inorder) {
//当前前序遍历的第一个元素
int rootVal = preorder[0];
root = new TreeNode();
root.val = rootVal;
//获取在inorder中序遍历数组中的位置
int index = 0;
for(int i = 0; i < inorder.length; i++){
if(rootVal == inorder[i]){
index = i;
}
}
//递归去做
}
这一步做好了,后面就是递归要做的事情了,让计算机去工作吧。
public TreeNode buildTree(int[] preorder, int[] inorder) {
//当前前序遍历的第一个元素
int rootVal = preorder[0];
root = new TreeNode();
root.val = rootVal;
//获取在inorder中序遍历数组中的位置
int index = 0;
for(int i = 0; i < inorder.length; i++){
if(rootVal == inorder[i]){
index = i;
}
}
//递归去做
root.left = buildTree(Arrays.copyOfRange(preorder,1,index+1),Arrays.copyOfRange(inorder,0,index));
root.right = buildTree(Arrays.copyOfRange(preorder,index+1,preorder.length),Arrays.copyOfRange(inorder,index+1,inorder.length));
return root;
}
最后,再把边界条件处理一下,防止root为null的情况出现。
TreeNode root = null;
if(preorder.length == 0){
return root;
}
ok,这道菜就这么按照模板炒出来了,相信你,后面的菜你也会抄着炒的。
2 从leetcode的岛屿问题看dfs
1. 步步为营
这一类题目在leetcode还是非常多的,而且在笔试当中你都会经常遇到这种题目,所以,找到解决的方法很重要,其实,最后,你会发现,这类题目,你会了之后就是不再觉得难的题目了。
我们先来看一下题目哈。
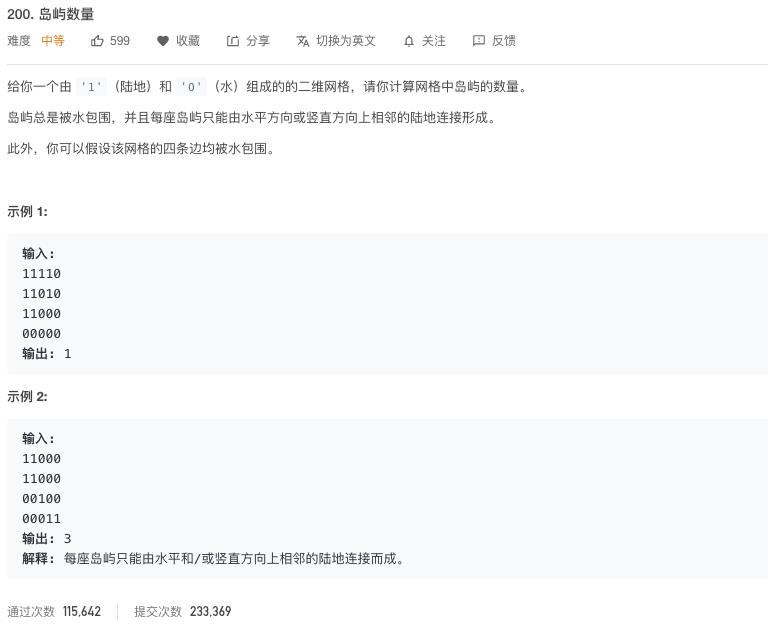
题目的意思很简单,有一个二维数组,里面的数字都是0和1,0代表水域,1代表陆地,让你计算的是陆地的数量,也就是岛屿的数量。
那么这类题目怎么去解决呢?
其实,我们可以从前面说的从二叉树看dfs的问题来看这个问题,二叉树的特征很明显,就是只有两个分支可以选择。
所以,就有了下面的遍历模板。
//前序遍历
void traverse(TreeNode root) {
System.out.println(root.val);
traverse(root.left);
traverse(root.right);
}
但是,回归到这个题目的时候,你会发现,我们的整个数据结构是一张二维的图,如下所示。
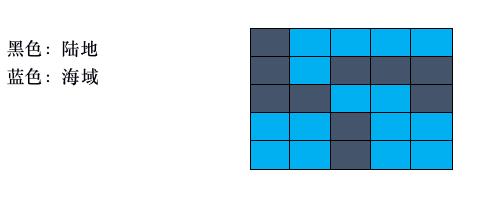
当你遍历这张图的时候,你会怎么遍历呢?是不是这样子?
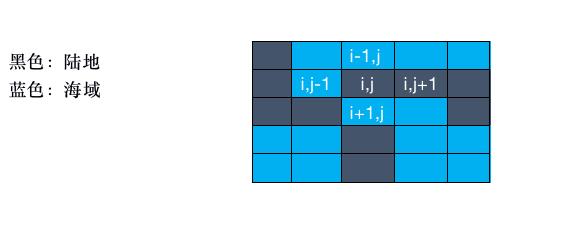
在(i,j)的位置,是不是可以有四个方向都是可以进行遍历的,那么是不是这个题目就有了新的解题思路了。
这样我们就可以把这个的dfs模板代码写出来了。
void dfs(int[][] grid, int i, int j) {
// 访问上、下、左、右四个相邻方向
dfs(grid, i - 1, j);
dfs(grid, i + 1, j);
dfs(grid, i, j - 1);
dfs(grid, i, j + 1);
}
你会发现是不是和二叉树的遍历很像,只是多了两个方向而已。
最后还有一个需要考虑的问题就是:base case,其实二叉树也是需要讨论一下base case的,但是,很简单,当root == null的时候,就是base case。
这里的base case其实也不难,因为这个二维的图是有边界的,当dfs的时候发现超出了边界,是不是就需要判断了,所以,我们再加上边界条件。
void dfs(int[][] grid, int i, int j) {
// 判断 base case
if (!inArea(grid, i, j)) {
return;
}
// 如果这个格子不是岛屿,直接返回
if (grid[i][j] != 1) {
return;
}
// 访问上、下、左、右四个相邻方向
dfs(grid, i - 1, j);
dfs(grid, i + 1, j);
dfs(grid, i, j - 1);
dfs(grid, i, j + 1);
}
// 判断坐标 (r, c) 是否在网格中
boolean inArea(int[][] grid, int i, int j) {
return 0 <= i && i < grid.length
&& 0 <= j && j < grid[0].length;
}
到这里的话其实这个题目已经差不多完成了,但是,还有一点我们需要注意,当我们访问了某个节点之后,是需要进行标记的,可以用bool也可以用其他数字标记,不然可能会出现循环递归的情况。
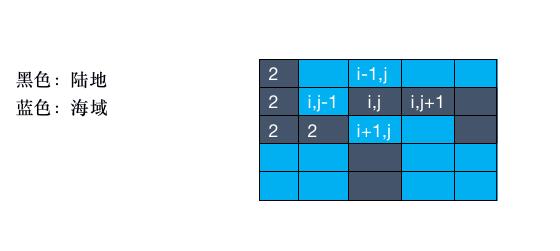
所以,最后的解题就出来了。
void dfs(int[][] grid, int i, int j) {
// 判断 base case
if (!inArea(grid, i, j)) {
return;
}
// 如果这个格子不是岛屿,直接返回
if (grid[i][j] != 1) {
return;
}
//用2来标记已经遍历过
grid[i][j] = 2;
// 访问上、下、左、右四个相邻方向
dfs(grid, i - 1, j);
dfs(grid, i + 1, j);
dfs(grid, i, j - 1);
dfs(grid, i, j + 1);
}
// 判断坐标 (r, c) 是否在网格中
boolean inArea(int[][] grid, int i, int j) {
return 0 <= i && i < grid.length
&& 0 <= j && j < grid[0].length;
}
没有爽够?再来一题。
2. 再来一发
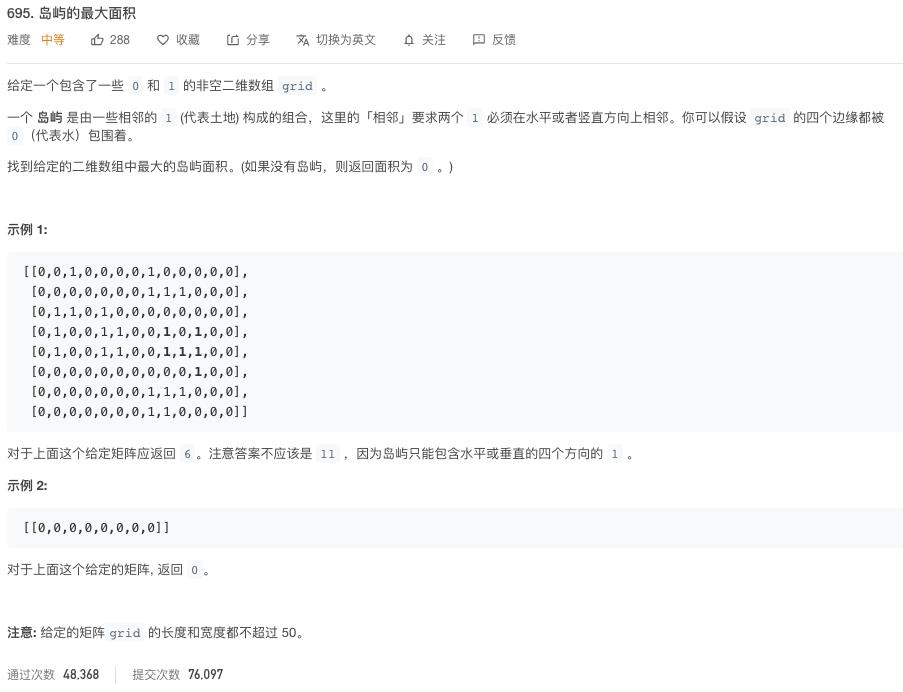
这个题目跟上面的那题很像,但是这里是求最大的一个岛屿的面积,由于每一个单元格的面积是1,所以,最后的面积就是单元格的数量。
这个题目的解题方法跟上面的那个基本一样,我们把上面的代码复制过去,改改就可以了。
class Solution {
public int maxAreaOfIsland(int[][] grid) {
if(grid == null){
return 0;
}
int max = 0;
for(int i = 0; i < grid.length; i++){
for(int j = 0; j < grid[0].length; j++){
if(grid[i][j] == 1){
max = Math.max(dfs(grid, i, j), max);
}
}
}
return max;
}
int dfs(int[][] grid, int i, int j) {
// 判断 base case
if (!inArea(grid, i, j)) {
return 0;
}
// 如果这个格子不是岛屿,直接返回
if (grid[i][j] != 1) {
return 0;
}
//用2来标记已经遍历过
grid[i][j] = 2;
// 访问上、下、左、右四个相邻方向
return 1 + dfs(grid, i - 1, j) + dfs(grid, i + 1, j) + dfs(grid, i, j - 1) + dfs(grid, i, j + 1);
}
// 判断坐标 (r, c) 是否在网格中
boolean inArea(int[][] grid, int i, int j) {
return 0 <= i && i < grid.length
&& 0 <= j && j < grid[0].length;
}
}
基本思路: 每次进行dfs的时候都对岛屿数量进行+1的操作,然后再求所有岛屿中的最大值。
我们看一下我们代码的效率如何。
看起来是不是还不错哟,对的,就是这么搞事情!!!
最后,这篇文章前前后后写了快一周的时间把,不知道写的怎么样,但是,我尽力的把自己所想的表达清楚,主要是一种思路跟解题方法,肯定还有很多其他的方法,去LeetCode去看就明白了。
好了,写的也够久了,下篇文章再来看看其他的,希望对大家有帮助,下次再见!!
以上是关于dfs题目这样去解题,秒杀leetcode题目的主要内容,如果未能解决你的问题,请参考以下文章
leetcode热题100——单词拆分(dfs记忆化的考察)
并查集/dfs解决——leetcode每日一题——1020飞地的数量