leetcode热题100——单词拆分(dfs记忆化的考察)
Posted C+++++++++++++++++++
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了leetcode热题100——单词拆分(dfs记忆化的考察)相关的知识,希望对你有一定的参考价值。
题目

题目详解
看完此题,我们可能很快就会想到回溯的暴力解法,我们通过构建 start ,为取 substr 的开始点,然后每一层 dfs 枚举它的长度即可。
具体而言就是下面的代码:
sz代表需要拆分的单词总长度,而其中的s就是这个总单词(本代码用的lamda表达式,所以会引入很多外部变量)
function<bool(int start)>dfs = [&](int start)
if(start==sz)
return true;
int maxLen = sz-start; //TODO 计算出最大可枚举的长度
for(int i=1;i<=maxLen;i++)//TODO 枚举substr长度
if(check.count(s.substr(start,i))&&dfs(start+i))
return true;
return false;
;
- 根据以上思路写回溯,然后你会发现你大概率会超时,因为这中间有大量重复的动作,这个时候可以通过记忆化来解决。
重复的动作在哪?
看看这张图:
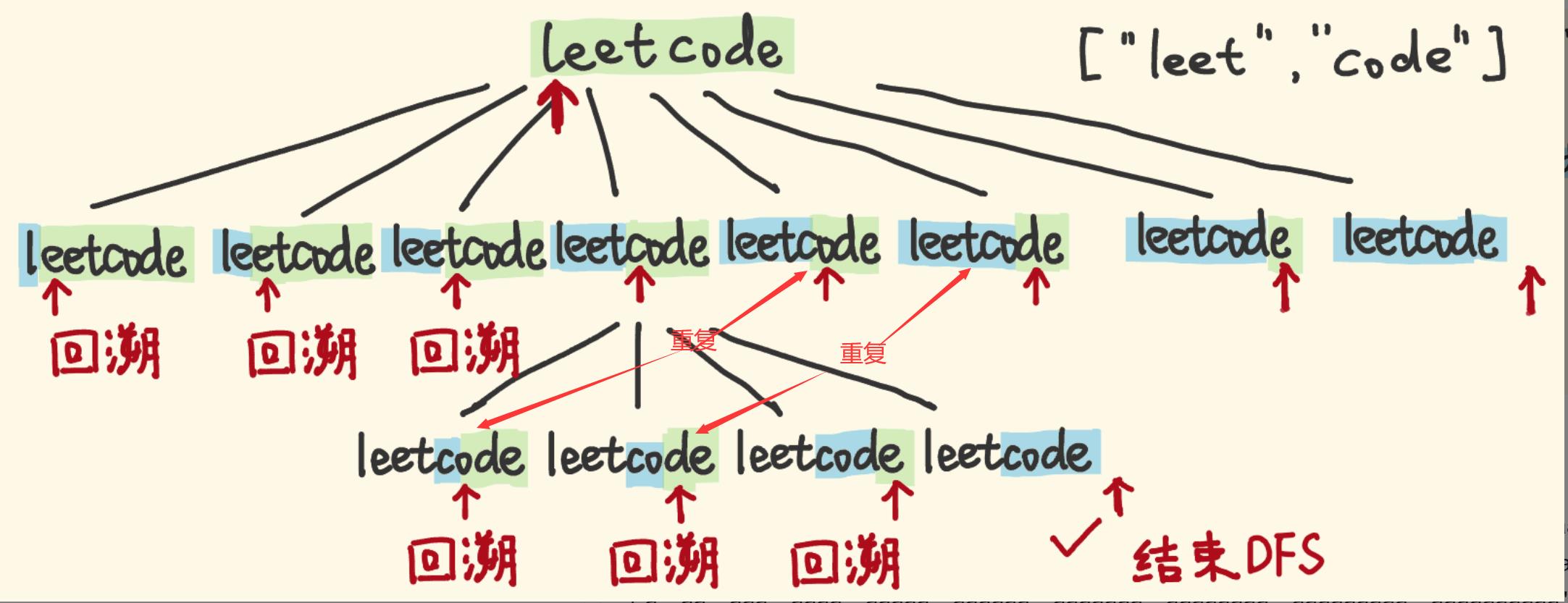
该图只是以最简单的例子列出了一点点重复的情况,实际上你会发现,只要在子问题里面已经计算过了那个位置的匹配结果,你就完全没必要再重复计算了,所以可以引入记忆化,而这个记忆化的标准就是 start 指针所处于的位置!
所以之前的回溯代码应该加入一个用于记忆化的 memo,如下:
function<bool(int start)>dfs = [&](int start)
if(start==sz)
return true;
if(memo[start]==1)return true;
if(memo[start]==-1)return false;
int maxLen = sz-start;
for(int i=1;i<=maxLen;i++)
if(check.count(s.substr(start,i))&&dfs(start+i))
return bool(memo[start] = 1);//TODO 当前结点的计算结果为true,保存下来
memo[start] = -1;//TODO 当前结点的计算结果为false,保存下来
return false;
;
解题代码
class Solution
public:
bool wordBreak(string s, vector<string>& wordDict)
unordered_set<string>check(begin(wordDict),end(wordDict));
int sz = s.size();
int memo[305]0;
function<bool(int start)>dfs = [&](int start)
if(start==sz)
return true;
if(memo[start]==1)return true;
if(memo[start]==-1)return false;
int maxLen = sz-start;
for(int i=1;i<=maxLen;i++)
if(check.count(s.substr(start,i))&&dfs(start+i))
return bool(memo[start] = 1);
memo[start] = -1;
return false;
;
return dfs(0);
;
以上是关于leetcode热题100——单词拆分(dfs记忆化的考察)的主要内容,如果未能解决你的问题,请参考以下文章