SRE:源自Google的DevOps最佳实践 | 学在GOPS
Posted 高效运维
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SRE:源自Google的DevOps最佳实践 | 学在GOPS相关的知识,希望对你有一定的参考价值。
本文根据〖2016 全球运维大会•深圳站〗现场演讲嘉宾分享内容整理而成。想成为运维大神吗,关注“高效运维(greatops)” 抢先赏阅干货满满的各种原创文章。
讲师简介
孙宇聪
《SRE:Google运维揭密》译者(即将在923 GOPS上海站全球首发);Google 前SRE(2007-2014),GOPS全球运维大会联合主席。
导语
非常荣幸有这个机会跟大家做交流,因为是最后一场,起初还有点担心,但是看样子留下来的都是真爱。今天我给大家带来的分享是《来自Google的SRE/DevOps经验》。
其实我想跟大家回顾一下我在Google大概八年时间内经历的一些事情,有一些好的想法、idea跟大家共享一下。

我是2015年回国,07年加入的Google,一直在Google大概待了八年的时间。目前是在Coding公司做CTO。

我在Google做SRE这么多年大概做了两件事情:
第一个是参与了Google Cloud Platform,做全球100万台的数据中心、一百万台的机器,自动化系统都是我们团队在维护。
第二个就是Borg系统,Google的所有机器都是运行在Borg系统下,写的代码要分发到这个系统上执行。还包括GCE,还有GAE

之前我主要是负责YouTube STREAMING,YouTube增长得很快,一个月时间就有一个PB的数据,建立了CDN网络,全球大概有三四万台机器组成的节点,所有的节点在峰值的输出量达到了10TB。

天下运维是一家,炮兵连中的炊事兵

我们运维同学最头疼的就是开发人员写完代码之后就交给我们上线,我们往线上一放就变成了“着火的房子”,然后开发说这是你的问题。

所以,我们每天一上班就是“消防员”造型,火场着了火,我们只有斧头和锤子,连个水管都没有带。
我们自己感觉自己是很牛的,没有我们,这个公司就倒闭了

最可惜的是老板看不到这一点,老板说你们没事儿的时候也上班,每天上网,玩游戏,有的时候找不到你们,所以老板为我们评价不高。
所以,大家对我们的理解实际上是这样:
想请个假就得拜一下。
回到主题,Google 的 SRE是什么意思。
Google 的 SRE

Google在成立SRE的时候是按照网站来划分的,SRE团队是负责这个网站的,每一个小SRE团队都负责一项业务,这项业务对生产团队有完全主导权,到底怎么样部署,生产环境怎么样维护都是SRE决定。

业务大,SRE团队就大;
业务小,SRE团队就小。
对最终用户负责,SRE跟最终用户最接近,开发人员写完代码关心功能做好没有,不关心用户是否高兴,SRE最关心的是用户看到错误页面的数量是否会增加。
SRE最重要的一点是做RELIABILITY,每秒钟Google会有几十万的查询,每个查询都会显示广告,运维团队要确保业务连续性。
制订、监控SLO,我们一定都是制订一个SLO,我们的目标是把这个服务做到比较稳定,稳定的级别是什么,如果没有做到这个目标会提升,会在哪些方面下功夫。
代码化、自动化、无人化,Google讲究的是所有人操作都不能以堆人来解决。
大部分互联网的业务都是这样的,它的增长速度是远超过你招人的速度,如果说这个业务一开始需要一个人,后来需要两个人、十个人,总有一天招不到足够的人,我们讲究的是无人化。
SRE最重要的一点,ENGINERRING,它在美国是一个很牛的词,必须是修桥、修路的专家,否则其他都是搬砖的。
SRE是非常强调的是,每一个SRE都必须是一个合格的码农,要自己写代码,要能理解业务代码是什么。
SRE是监控系统中毒用户,发现不好用,要自己开发,自己写插件完善它。
SRE是对整个产品的未来负责的,我要能够知道在运行的时候,用户量会增长到什么程度,需不需要架构的调整,需要不需要部署方式的改变等等。
要回答这个问题,不是只解决现在的问题,而是要向未来负责。
WHO:SRE


双技能树的程序员,既会写代码,又会做开发。你去开发自动化的程序,去改Bug,这些是开发的工作,SRE是强制50% 的时间,各做一半。
我们时不时会有一些开发人员转成了SRE,有一些SRE转成了开发,它和开发、运维是一个非常模糊的分工。
还有一个比较有意思的特点,SRE或者运维部门都需要这样的人,这个人就是看不惯事情,图表上每天会有一个波动,你就会觉得受不了,为什么会这样?你就要把它解决。
看右面的图很难受的话,你当运维是比较合适的,你有一种动力要改进这个东西,把这个东西做好,这是强迫症,运维团队都应该是强迫症。

SRE在公司内部拥有绝对的话语权,Google尤其是这一点,我在Google待了八年时间,见到很多次开发和运维团队争吵,VP听完之后
“不用跟我说那么多,就听SRE的就完了!”
你今天不听运维的,明天还得听运维的。
所以,SRE在Google中是非常强的,这件事情不舒服SRE,你这件事情基本上就办不成。当然,SRE也要知道有这样的信任,SRE会非常详细地帮助你分析对生产造成什么影响,有什么危害,能不能做得更好,这是互相促进的过程。
SRE不会一律说NO,肯定是说要一起前进。
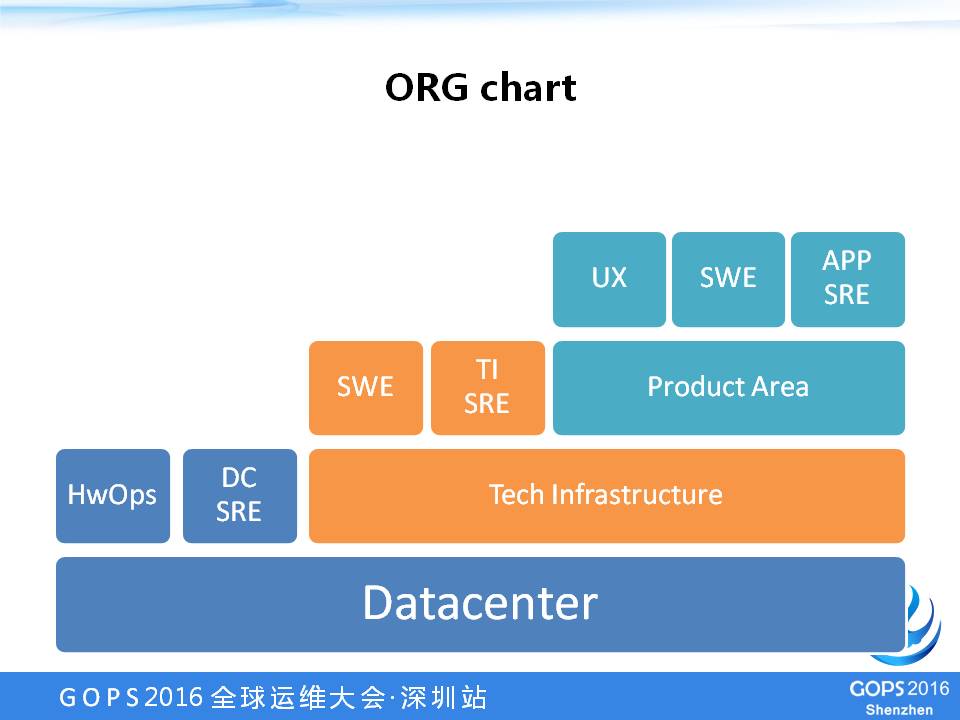
SRE在整个公司里,有一个简单的架构图,这个架构图的最下层是Datacenter,Google全球有一百多个Datacenter,每个Datacenter有自己的运维人员,运维人员像操作某台机器一样,去上架、下架、接网。
DC SRE就是说,每个数据中心现在都是智能化了,你要监控它的电压、温控等等。
所有的技术中心上跑的基础软件我们称为TI,TI里面有自己的开发人员,会有TI自己的系统的SRE,有维护数据库的,有维护分布式文件系统的。
具体再往上,其实我们支撑的是公司的主要业务,主要业务是PA,PA里面是应用运维。
SRE是公司运维部门组合在一起,用同样的方式指导我们的工作,每个团队面对的问题和产生的技术和方法都是不一样的。
WHAT: SRE

SRE平时都干什么事儿呢?这八年都做什么事呢?
我就做了三件事:纵火犯、救火队员、兼职开发。

所以,运维是整个公司里面持证纵火。在美国比较讲究这一点,任何东西不动的一般就不坏,当一个东西足够稳定之后,它一般不坏,什么时候会容易出事故?做更新,做改动。
SRE最大的一个工作职责就是持证放火,产品要进步,新功能要发布。
所以,每次产品发布为SRE来说,SRE都要处理问题,从变更实施的第一个小时到48小时是出现问题最严重的时候。
SRE做灰度发布等都是要解决这个问题,不要把全世界的用户都搞挂了,要挂就挂一小部分。
放火放到一定程度要知道现在生产系统到底是好的还是坏的,我们去分析和找到哪些关键的指标告诉这个服务是正常运行的,这个变更到底能不能继续实施,这些都是SRE做决策的关键点。

Google的On-call,每个人大概是一个月分到一次,每次On-call是早上九点到晚上九点,在我们睡觉的时候,实际上是地球另外一边的SRE做,大部分都是在工作时间内。
这个On-call是非常紧急的事情,不是说可以慢慢悠悠地从食堂都回座位看一看,Google的每条报警都是有严格规定的,必须要在5分钟之内赶到电脑前,登录上线处理问题,5分钟我觉得是人类的极限了。
Google如果有On-call的话,它就是5分钟,还有30分钟的,30分钟的是不是很关键的。
5分钟响应的才需要SRE,SRE接到报警之后要做的第一件事,报警是比较严重的事,半个地球都访问不了网站了。
SRE要在30分钟或者一个小时内快速决定怎么样把这个问题解决,是重启服务器还是重新调新的资源配置机器也好,反正在一个小时之内必须要把问题解决。否则,整个公司的业务就受到严重的影响。
只有关键性的东西才会发报警,接到报警之后必须要做紧急的处理。
我们会参加Incident Management,在紧急事件发生的时候,正确的流程是什么?
很多人不知道紧急流程是什么,很多公司线上出现问题的时候,整个公司人都不能干活。
老板说必须解决这个问题,每个人都在不停地刷网页,没有一个很清晰的职责,没有人沟通需要谁参与、不需要谁参与、目前的进展是什么样
这恰恰是SRE最需要的,当一个灾难发生的时候,该做什么事情、谁负责对外沟通、谁需要调配资源,这些都是需要演练的,就要求每一个运维团队的人有这种能力和意识解决这个问题。
最正确的处理是迅速恢复网站的正常访问,公司内部认为SRE的On-call时间应该多发1/3工资,正是因为要求非常严格,对公司影响非常大,所以才有这个要求。
当我们on-call的时候,吃饭的时候必须要带笔记本,哪怕坐车回家都要随时可以上网,报警来了必须要马上解决问题,也是挺苦的一件事情。

开发主要是集中在几个方面:监控系统的开发是SRE的一个重点。
管理性和高可用性架构。它经常是做非常小的事情,这些业务的组件有一个统一的管理方式,管理接口、监控接口,这些都非常细,一点一点的开发是SRE做得最多的事情。
HOW:SRE

SRE在初期阶段,任何项目都有一个初期阶段,初期阶段是还在不断发展、不断进步的过程中,每个业务都有这样的阶段。

SRE在这个阶段主要做的事情是帮助开发人员做一些重复的工作,比如发布、监控。为什么要做这些事情呢?
第一,可以降低一些开发的压力;
第二,可以让开发把这些事情整理成文档,你在做一个新业务的时候,你如果让开发一个人负责开发和部署。
最后这个东西都存在开发的脑子里,对他来说没有必要写文档。
中间加入另外一个角色的时候,很多东西必须要文档化,要规范。SRE就是负责挑毛病,看你这个地方文档写得不正确,这么执行老有问题,就是在这样一个拉锯战的过程中。
SRE更多的是帮助开发团队做一些比较基础的,建立起比较规范的流程,建立起比较规范的监控环境。

到了业务成熟期,开发团队和运维团队的目标就不一样了,开发团队想的是要做一个新功能,加一个新板块,运维更关心的你要上一个新的版本就把整个网站搞挂了。
这个时候SRE和开发团队打仗就比较多一点,如何能够保障上新功能不会影响旧功能,上新功能的速度是不是应该放缓一点等等。

进入ONCALL阶段,西海岸有6个人,在欧洲有6个人,这12个人一个月轮一次,ONCALL最主要的是把问题解决,通过各种各样的小脚本把这个问题解决。
如果开发不能立刻写出的时候,SRE就要定时重启服务器或者定时删东西,大家都遇到过开发写的这个功能上线之后,隔一段时间服务器就挂、内存泄露,一时半会又查不出问题所在,SRE就每天几个小时上线重启一下服务器。
但是这是SRE的一大作用,整个公司就需要一个这样的人,就需要知道现在公司需要每天重启服务器,那你就要重启服务器。
SRE更重要的一点是推进,不能每天都重启服务器,要把这个问题找出来,剩下的50% 时间是在做这个事情,推动开发、运维团队把这个问题解决。
BEST PRACTICES:SRE


SRE非常强调可管理性,可管理性这个事情,很多公司没有系统地重视它,实际上它是一个非常重要的东西,因为一个人记住的东西是有限的。
所以,可管理性就直接决定了你一个人能干多少活,如果所有的东西都是一样的,一个人能发挥的作用就是很大的。
Google的一百个数据中心几乎是一样的,对于一个管理人员来说,它只是一百个副本,它所有机器的配置方式、机器的管理方式,这些东西都是一样的。
所以,找到一个合适的抽象层,把底层细节稳定下来,你才能把这个东西管好。
怎么跟开发团队去填这个坑,开发团队天天写出很多烂代码,运维来背锅,这件事情很难办。怎么办呢?
在Google,我们采用了一个可靠性预算的方式,开发的头儿和运维的头儿坐在一起,大家讨论一下你们写的这个服务,你到底想让它多可靠。
什么东西都是有可能出问题的,你觉得你们这个业务非常重要,公司没有它活不下去,是三个九还是四个九?你要问清楚,把这个事情想清楚了,其实很多问题就得到解决了。
如果你觉得这个东西要非常可靠,这个服务必须是每天三个九状态在运行,上线之后不停地抛各种错误,实际上是在以两个九的方式在运行,这个时候不应该再做新的开发,应该修BUG,修到三个九的时候才有一点空间做别的事情。
如果不把可靠性当成产品的要求,开发不背黑锅,运维说是你们写代码写的问题。所以,产品部门要做这个决定。
给大家举一个实际的例子,大家去看优酷或者YouTube的视频要存几份?
当年YouTube一个月就是一个TB的存储量,如果说把每个视频文件存两份,就相当于两个TB,整个容量设计、系统吞吐量全部要涨。
存一份和存两份就是可靠性的区别。所以,最后产品做出决定:不重要的事情就做一份,这个决定做出来了,就好办了。
很多升级或者可靠性的东西就可以衡量了,我可以清晰地知道我想要什么,不是说这个东西上线之后就百分之百可以做到,开发、运维人员背黑锅的问题就好一点。
SRE会做一些基础性的服务,公司发现管机器的地方多,就建立起一套重装机器的流程,SRE在这个过程中不断地发现哪些地方可以自动化,他去做这个事情。
SRE要提出基础设施的优化,多发奖金等等,公司里面要推动,给运维团队足够的信心和足够的激励让他们来做这个事情,否则就没有人做这个事情。

填坑是一个长期的过程,很多时候SRE或者运维团队要堆硬件,硬件是不可靠的,不可靠也得堆,堆多了,怎么变成可靠?
在Google中讲的特别多的就是N无+M,大家可以想象N+1、N+2,N+3,很多公司都不知道N是什么,不知道需要几台机器,大概需要两台,就先放两台,流量一来,瞬间就瘫掉了。
我们可以进行压力测试工具。
我们一般把昨天的流量保存下来,找一些流量重放工具去测试,我们一般都是测100-130%这个区间,我们在做服务容量的时候都是做130%,在这个基础之上才做N+几,在业务顶峰的时候,突然两个集群挂掉了,整个集群还可以正常运行。
所以,这是一个比较高的标准,一般三个九或者四个九的服务至少需要N+2,稍微低一点的需要N+1,美国没有了,欧洲还有一个可以做。
在Google和国内不一样的是从来我们也不提灾备计划,你冷备机房想迅速切换过来,总会有各种各样的问题。
Google讲,你要么就是讲容量,你告诉我有多少富余的容量,我们讲究的N+几是在容量上的N+几。堆硬件可能对大家有一点启发。

SRE怎么解决自己的人头问题?
SRE要根据业务的成长,大部分外部业务都是成指数增加的。SRE招人比较难,我们应该做什么呢?应该做一套不会坏的系统。
首先,这个东西从用户请求到中间件、服务器、数据库,每一层之间有各种各样的备份,有本地缓存,有负载均衡,这样不会遇到业务链越长坏的可能性越大。
所以,SRE的一般做法是在每一层把问题都拦住,相当于这一层对下一层是负责的,可以保证整个链路的容量能够满足要求。
比如说前端平时是2.5倍容量,关键时刻是10倍顶上,每一个负责业务的人要准备好足够的容量去做这件事情。
这种方式的好处,相当于变成有损命令,Google比较讲究的是整个用户的质量是从端到端控制,如果不是特别重要的请求,可以在请求进入Google内网的一瞬间,可以被打一个标签:
这个请求是可以被丢弃的,能请求的请求,不能请求就被丢弃了。
按照这种方式组织的系统,在系统容量出现问题或者有灾难情况的情况下,这对用户质量是非常可靠的,自然而然就保持了业务的连续性。
SRE的指导思想,不能有人的参与。
人是Google灾难的主要原因,Google90%以上的灾难都是由人引起的。讲一个实际的例子,无论这个文档写得有多好,只要让人参与,一定会把命令打错,今天没有打错,明天也会打错。
如果到数据中心就更严重了,我们经常发现机房的一整个机柜的机器坏了,等这个消息传达到数据中心的时候,数据中心这个人去扳这个开关,就扳错了,另一个机柜灭了,然后扳起来,结果把两个一起扳起来,导致整个供电负载超高,整个数据中心停电了,这可能是数据中心人员最糟糕的错误。
事实上任何工作要人来操作肯定会出现错误,要解决这个问题,必须要把人排除在外。
5分钟是人的极限,如果你想达到四个九,每次光收报警然后上线就得五分钟,实际上你永远达不到。
所以,必须要把人排除在外,设计任何系统都要以没有人参与为核心,即使不能完全自动化,人也只是审批的功能。
前两天美国有一个网站访问不了,过两天发了一个通告说有一个运维人员把线上数据库干掉了,点错按钮把它干掉了。
运维同学如果想不背锅,不要老离锅太近。

如何正确设计一个监控系统?
Google SRE的标准是每周只有十条报警,如果超过十条,说明你能力有问题,没有正确地把无效报警过滤掉。
整个监控系统有三种输出:
报警
系统以自动化的方式找到的,要你马上处理,这是一个紧急事件,你必须要去处理;
工单
系统还剩10%,这不是马上处理的,在一天、两天之内搞定就可以了,SRE处理这个工单;
记录
记录是没有人看的,因为记录实在是太多了,访问有记录,中间件有记录,数据库有记录,所有的东西都有记录,如果你用这种方式来发,如果说什么事都发报警的话,最后你的报警就看不到了。
SRE的要求是所有的报警都必须是接到报警,有明确的事情要干,马上要干,这才叫报警。
其他如果不是的话,要么就是工单,要么就是记录,比如发布就是一个记录,记录信息能够查到就可以了。
所以,监控系统,这是值得好好思考的,所有的监控系统设计都应该按照这个方式来做。你要想把报警用好,就让报警的数量减少,让它报该报的事情,不要让所有的事情都烦到你。

我们国内大家没有ONCALL的概念,大家是随时ONCALL。
但是Google不是这样的,Google的ONCALL是非常明确的报警,它也一个升级策略。
首先,一条报警只有一个人来处理,这个人就是当前ONCALL的人,不会分配给别的人,所以ONCALL的人必须能够解决问题。
如果他由于各种不可控的原因导致他没有及时地响应这个报警,我们会有一个收集策略:
5分钟之内发给一个人,5分钟之内他没有标记为“正在处理”,就自动发给一个备份。
每次ONCALL都是两个人,一个人是主ONCALL,一个人备份,备份的这个人的主要目的是把ONCALL的这个人给找回来。
ONCALL的这个人就应该是在电脑旁边,如果说在公司出门抽烟,这个任务就交给别人处理了,这就不叫ONCALL了。
备份ONCALL的首要目的是把主要的ONCALL的人找回来。
运维必须要处理线上问题,公司让你ONCALL发一份工资是让你赶紧解决问题的,不是让你修一个东西的。
老板说让你紧急处理一下,你打开浏览器看了一下说代码可以重新改一下,改完代码CI系统又坏了,去修修CI,老板很生气,你一天了没有干任何事,他真正想让你干的就是把现场问题解决了。
解决现场问题的能力非常关键,你要有一个好的想法,马上实施,马上解决问题,这才是最关键的。
最后,我们每周会有一次例会,其实就是把这一周收到的所有报警信息大家一起过一下,每一个信息当时是怎么处理的,有没有更好的处理方案。
你要问为什么,这个问为什么是一位咨询专家提出的,你要问5次大概就问到点了,你找到Root cause,做一些防范工作,这样报警的次数会变少。
SRE把运维事情当成一种开发,当成一种修Bug,目的就是把线上的Bug都吃掉。
实战演习需要演习,需要学习,我们会做Operation Readiness Drill,每两周组织全组人的演习,待的时间比较长的人给新来的人出一个题。
假如说网站现在都访问不了,该怎么解决?
这个人拿出笔记本,就在全组人的目光之下,去尝试修复这个问题。
这个问题一般是比较普遍的问题,基本上你要去分析这个问题是为什么发生,怎么解决,跟大家讨论。但是这个过程是非常有意义的,处理过这类问题的人,可以看到不同的新的处理方式,没有处理过这类问题的人可以学习。
所以,我们会针对各种各样不同的报警去做这种演习。
场景演练,每两周选出一两个人进行场景演练,每半年公司都会组织一次大型的场景演练,那半个月的时间公司说我们新的业务开发可以稍微等一等,全公司各个部门一起来做实战演习。
当具体做的时候是每个部门自己做,想出来要做什么样的演习,怎么执行。从公司的层面,这两周时间就去做这个事情,我们来支持你们。
Google做演习是假如总部停电了,怎么办?
如果一个网站每天都需要你不停地去看,一个关键组件只有一个人能管了,如果人突然感冒发烧拉肚子,没有看报警,难道整个网站就不运行了吗?
通过不断的实践演练和演习,最后才能做好ONCALL,才能真正满足你的要求。

SRE最好的一个传统就是针对每一次大事故,我们都会做一次事后总结。
这个事后总结虽然是领导要求的,但是实际上领导们是有一条硬性规定,不能按照事后总结的内容发奖金,这是很关键的。
事后总结的目标是把整个事件的流程和经历的事情、暴露什么问题写下来。
Capture the facts,什么时间到什么时间网站是不可用的,你从中学到了什么,你要做什么。
每次大事故都会组织这样的人去分享,这个文档是非常好的,是我们SRE团队之间互相学习的一个主要渠道。
所以,背锅实际上要背得正确才行,很多是SRE擅长写事后总结,写完之后让你觉得原来他对这个系统这么了解,这个锅实在是背得太好了!
背锅不一定是坏事,如果背锅不罚钱是最好的,你一定要说你背了这次锅,一定要保证别人不会再背这次锅。
SRE最推崇这一点,如果你能够把一个事件吃透,你可以在公司之内给别人做演讲,做培训。
过载的问题很难解决,但是我们SRE在某一次事故中发现了这个问题,他做了非常详细的事后总结,搞出一套新的方案,推动了整个公司前端服务架构的一个演进。
所以,这是运维的最高层次,你什么也不干,就坐在那里挑开发写出来的毛病,你设计出新的方案,推进到全公司。

最后跟大家分享一点,怎么样解决这个问题才算真的解决了,我们一定要把它解决到以后再也没有人需要关注这个问题、再也不用解决。
如果说这个东西两三天坏一次,需要重启。你的解决方案是重启,对不起,这不叫解决问题,这只是叫处理问题,你只是把它处理一下,隔两天还要重启。
真正解决问题的方案是找到原因,去把它真正解决掉,这才是所有运维或者SRE主要干的事情。
我们曾经有一个具体案例,公司聘了一个五六十岁的老头儿,他是一个学术专家,每天上班之后也不做什么事,每天喝喝茶,看看报纸,翻翻图表。
我们都不知道他干什么,突然有一天跑过来他跟我们说,他看了公司的很多监控,发现大概每隔一百毫秒图表就会波动,他就去查这个问题。
公司调了很多资源来处理这个波动,他看到了这个问题,他怎么做的呢?他发现这个问题,就去各个部门问在什么情况下会出现这个问题。
他花了大半年的时间查到了,他自己最后总结,他这一项给公司挣回了十年的工资。
我们还曾经帮英特尔修过一次CPU,它做大规模的计算,加密运算,AES,在几百万分之一的情况下会写出一个错误。
我们的SRE在运维这个系统的时候发现为什么每个月都会产生一些错误数据,一开始觉得是我们自己程序写的错误,后来没有找到。
后来到某种CPU,发现这种CPU执行就会出现措施,证实确实是如此。后来,他就找到了英特尔,英特尔给了我们一个内部的小册子,这个册子是全公司只有几个人才能拿到的,CPU不是每一个执行起来都不是一样的耗电量。
这个人后来帮助英特尔解决了这个问题,最后英特尔发了一个新的微内核,我们应用上去。
其实这个问题,很多团队其实都遇到过各种各样形式的问题,这个人从业务出发,一直推动了技术架构的更新,以后推动了英特尔,在整个业内都造成了一定的影响。
这就是SRE比较成功的地方。

我跟大家分享一个图,这个图是一个七级的图表。
灾难分类,你可以回想一下,运维同学曾经遇到的灾难。最差的灾难,一个东西坏了,坏得最彻底,不光是把新数据丢了,老数据也都删了。
再往上是只丢新数据,不丢老数据。再往上是压根不坏,虽然出问题,但是不会停止提供服务,还可以操作,还可以继续运行。
从一到七实际上是一个级别,大家可以拿这个图对比一下自己的系统处于哪个级别。
如果所有的系统都能够拿到第七级,就算出一个灾难,出一个问题,也可以很快地恢复,不影响质量,这个时候运维才算是真正把自己的工作做好。

今天就到这里,谢谢大家!
好消息
万众期待的《SRE:Goolge运维解密》,即《Google SRE》 中文版,将于9月23日-24日举行的GOPS上海站,全球首发。本书封底封面预览版,先睹为快哟。

作为GOPS全球运维大会联合主席,孙宇聪同学将在GOPS上海站限量签售,并做两个精彩演讲。
不仅如此,《SRE:Google运维解密》的原书作者及Google SRE主管工程师也将莅临现场,并作精彩演讲。
全贤汇聚的923 GOPS上海站,70个精彩演讲,还有哪些契合您的要求?请访问如下链接,或猛戳“阅读原文”链接:
你留言,我送书
您从本文中学到了哪些金句?欢迎在文末留言,show出来让大家看。24小时内留言获赞 Top 3 将各获得《SRE:Google运维解密》一本(预约本,尚未正式销售)。
以上是关于SRE:源自Google的DevOps最佳实践 | 学在GOPS的主要内容,如果未能解决你的问题,请参考以下文章