AWS DevOps实践:一年5000万次部署是怎样一种概念?
Posted DBAplus社群
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AWS DevOps实践:一年5000万次部署是怎样一种概念?相关的知识,希望对你有一定的参考价值。
本文根据张孝峰老师在〖Gdevops 2017全球敏捷运维峰会广州站〗现场演讲内容整理而成。

(点击底部“阅读原文”获取张孝峰演讲完整PPT)
讲师介绍
张孝峰,AWS资深架构师,20年技术研发经验。
今天将跟大家分享一下亚马逊AWS在DevOps方向的一些见解。AWS其实是在亚马逊整个DevOps沃土中发展起来的一个产品体系,所以在讲AWS时,我希望给大家看到的不是一个服务的广告,而是一些DevOps理念真正的实现。
关于DevOps
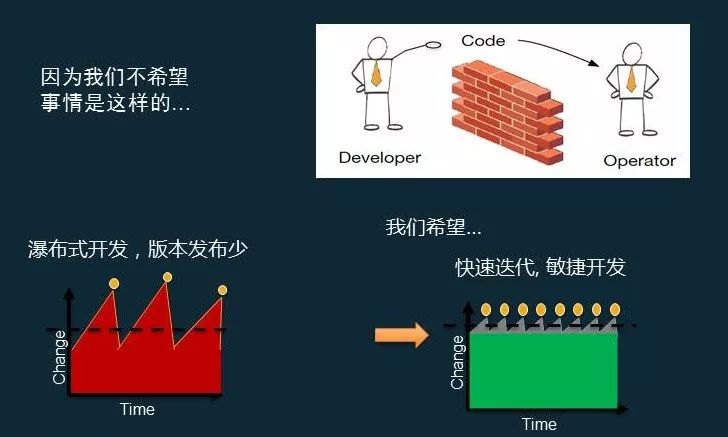
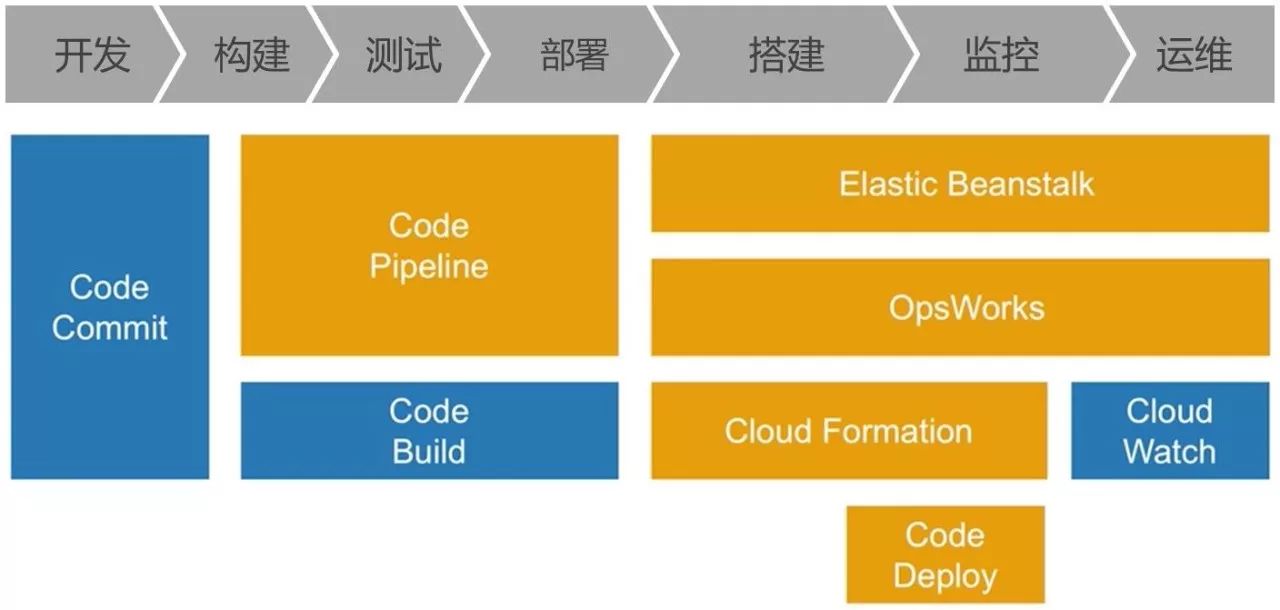
大家对DevOps也比较清楚了,我们不希望研发人员直接把代码丢给运维,再让运维去做,因为代码的发布是一次发布成千上万个,如果出现问题,我们不知道怎么去修改,我们的希望是让整个代码发布、整个运维更加顺畅。所以在亚马逊,DevOps需要管理很多很多方面的问题:包括了基础设施、IT自动化和配置管理、版本控制的集成、持续集成和持续交付、持续部署、应用和基础设施的版本管理、监控和日志管理等。
亚马逊的DevOps故事
1、亚马逊开发流程的演进
传统应用发布的4个阶段:冗长的周期和复杂的协作

亚马逊作为一家非常庞大的电商公司,最早进行开发时也有很多的团队,把它分在一个代码里去发布,然后在开发时会用一种很传统的源码编译、特色生产的过程去做。
亚马逊开发形式的转变:2001-2009
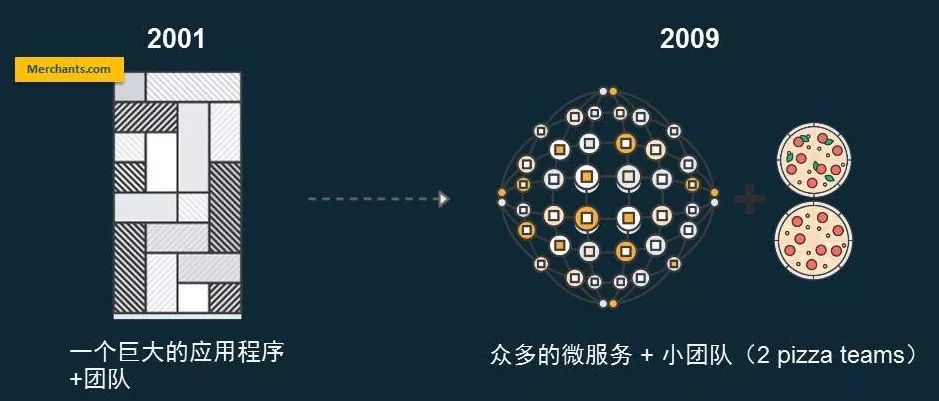
这个过程持续了很久,直到2001年,我们的创始人跟一个巨大的运维团队将里面越来越多的开发运维进行了改善,所做的就是把整个亚马逊的服务拆成很多微小的服务。当时在内部有个说法,可以看到就是上图中的2 pizza teams,即我们希望用两张披萨饼就可以喂饱每一个承担这些微服务的团队,这一点在亚马逊内部是贯穿始终的。两个披萨饼、一顿午饭,大概就是说2到10来个人的团队,这个情况下每个团队都是在这么小的一个范围内,他们能对外提供一个统一的标准化的接口,内部也可以用自己的方法去构建自己的服务,去保证整体的服务是一个统一的整体。

这样的情况下,我们通过构造一个巨型的面向服务的架构,单一地通过不同的APL调用,把整个亚马逊的各种服务进行一个高度的解耦,最后达到的效果就是每一个团队都有自己的持续集成、持续交付、持续发布的灵活情况。
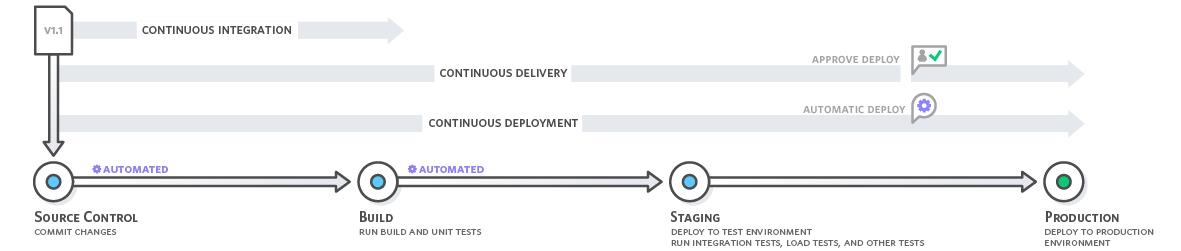
软件生命期新的管道
这个情况可达到怎么样的效果呢?可以达到一年5千万次的部署,如果按工作日来算,就是平均下来一年里每11秒就可能会有一个小版本部署上去,这个版本部署可能只有几十行代码的修改,然后2 pizza teams会针对这个版本做自己的回归测试、单元测试,保证自己提供出去的APL是稳定可靠的。


总体通过一个巨型的架构,利用中间的微服务APL调用来保证我们整体去做,所以可以同时部署在很多不同的服务器、应用上,这是亚马逊今天能够做到的。

我们屏蔽了以前旧的软件交付方式,可能要用很多不同的版本,甚至用十几个介质来配适我们的客户,包括在亚马逊AWS上的客户,他们已经可以很好地用新的这种交付方式去做。这里,亚马逊想到,除了能够让我们自身的团队变成这样,其实能不能为我们的客户去做到这样一个微服务的架构或持续集成的架构,于是就有了亚马逊AWS服务体系的诞生。
接下来我会介绍AWS这部分DevOps方向的一些服务,通过这个服务去看到我们如何能够在一个云端非常敏捷地实现DevOps,同时也会介绍到一些DevOps的框架和工具。
基于AWS服务实现DevOps的框架和工具
1、AWS对DevOps的全面支持
首先AWS对DevOps是全面支持的,包括从代码的提交到各种的FreeWork Test,然后会有SDK去调用我们的APL,去使用平台的各种基础设施,建立流畅的自动交互渠道,下图是我们整个持续流程的模型。

这个模型也包括了我们整个域名服务。域名服务很多情况下跟我们整个DevOps的服务是一个最基础的入口,因为访问是通过域名去进入的,那么,我们在域名这一端通过一个智能DNS可以做到蓝绿发布这样一些动作,然后通过我们的基础服务来获得基础服务提供的这些服务。这个基础服务旁边是各种的源代码库,还有项目管理库会用去构造不同的服务,去自动化地持续集成到我们实际的服务里去。
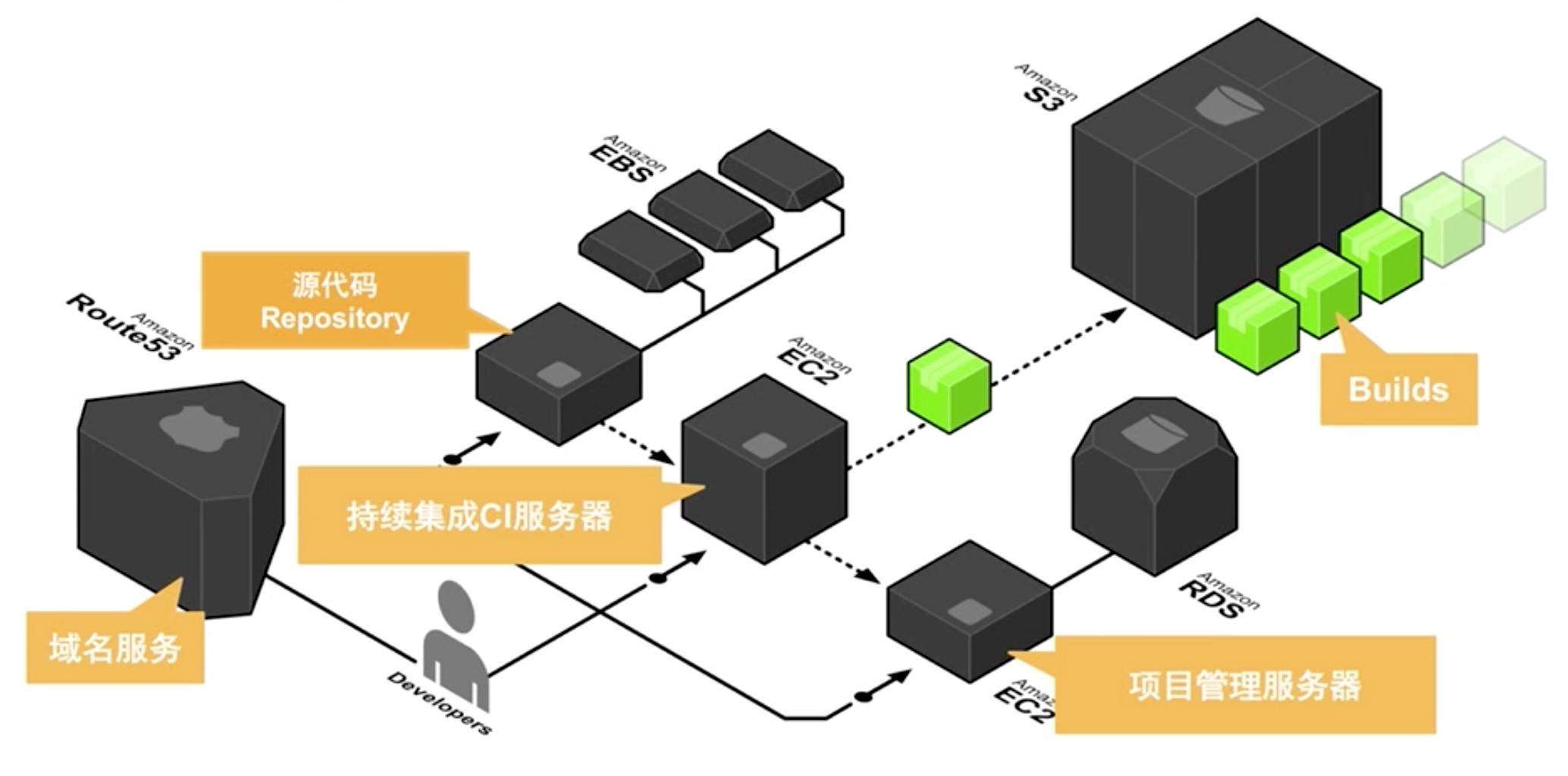
持续集成模型
2、AWS CodeCommit
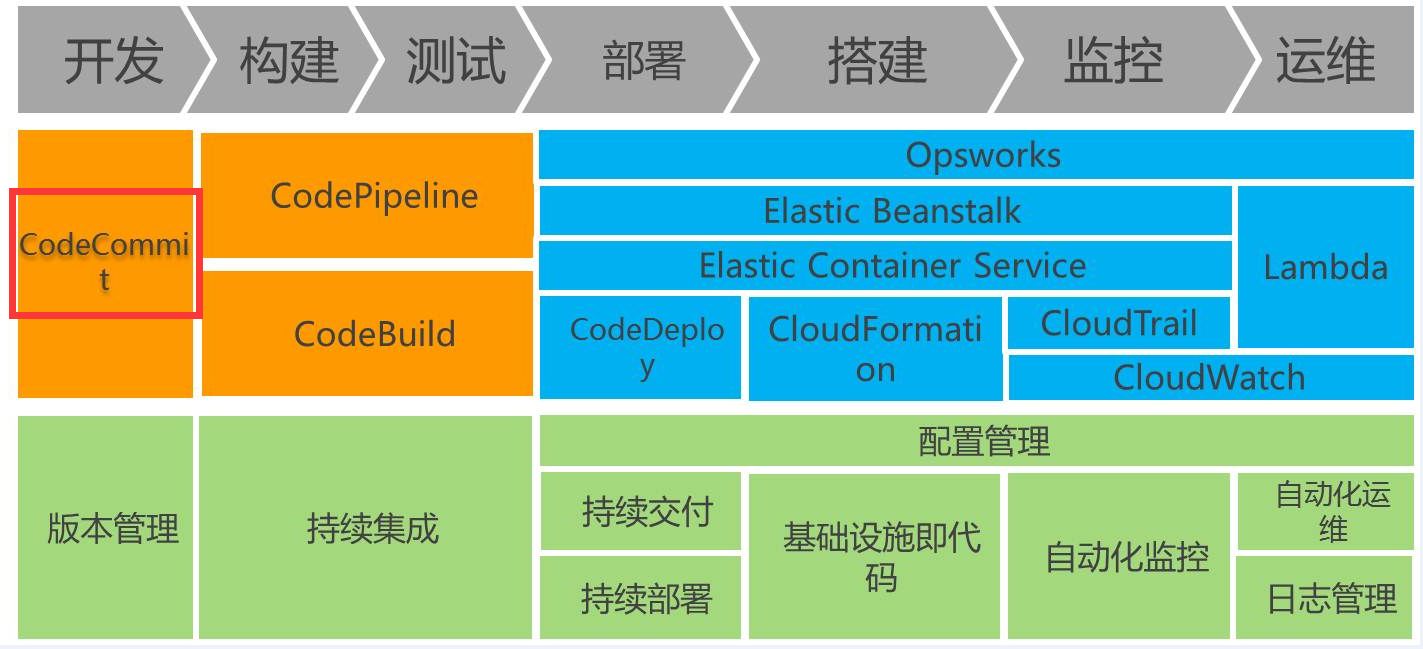
第一步接触到的是AWS的Codecommit,你可以认为它是一个代码管理库,它在整个AWS Devops服务体系中是处于最左边的位置,就是在我们的开发、版本管理这个方向,那么它能够提供一个怎样的东西呢?

它其实是一个Git的服务,就像现在大家都会使用Github去管理自己的代码,那么在AWS的Codecommit,它是一个典型AWS微服务的结合,它会用到AWS S3这样的对象储存服务去储存代码实际的部分。因为在这种情况下,相比传统的磁盘,S3会有一个更好的方式去储存一些大文件。作为一个海量的代码库,它对一些大的分区或者大尺寸文件的储存会有更好的优势,而后我们会使用Amazon的NoSQL服务去作为它的元数据管理。这个在Git里面,我们的版本控制、各种分支的控制,都可以在这边去做到,我们也可以通过KMS去加密存在AWS的代码,因为相信对很多公司来说,做好自己源代码的保密性是非常重要的。
有了这样一个Git的服务之后,我们就很容易会去构造企业私有化的一些仓库。众所周知,如果我们使用Github的方式去管理,它的私有化仓库是要付费的,那在CodeCommit这样的方式里,我们是可以提供免费的私有化仓库,只需要出少量的储存费用就可以去做,所以这个本身也是一个由亚马逊自身微服务组合而成的一个组合型服务。
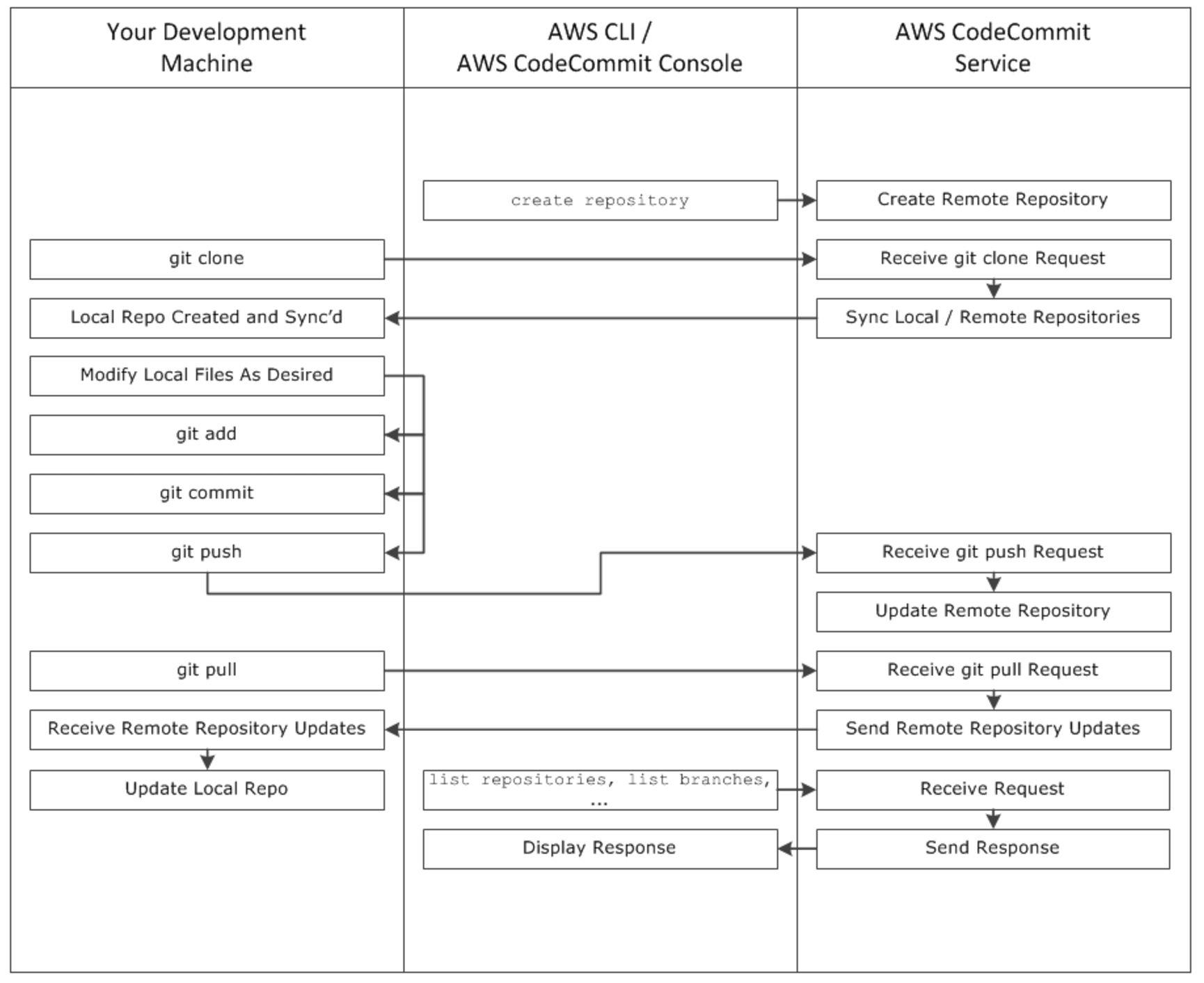
AWS CodeCommit使用方式
对于Git的使用方式,这里就不多说了,我们跟GtiHub的操作方式是一样的,可以通过亚马逊的APL去创建自己的产品库,前后包括分支这些东西,就用传统Git的方式去做,而在最近的一两个星期,我们的Codecommit也加入了类似Github pull这样的方式去管理各种不同的分支,可以让我们不同的团队通过Pull的方式来操作代码。
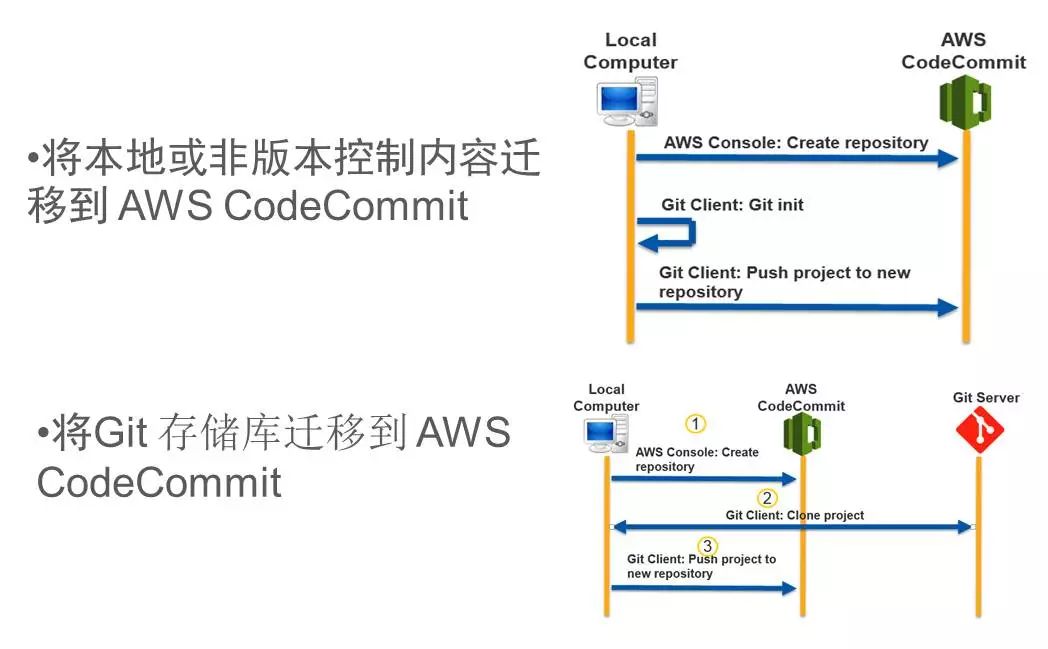
关于Git的提交大家也都很熟悉了,其实可以把Codecommit作为我们最常见的一种方式,因为Git的仓库其实是平行的,所以Codecommit作为我们的远程仓库,它可以跟本地一些分发的仓库平行地去做,可以把需要做云端的Devops的部分作为一个特殊的Commit权限,或者叫Push的权限放到云端去,同时本地还可以维护这样的Git仓库。
3、AWS CodePipeline
有了这个代码以后,就需要在云端去构造一个Pipeline流程,或者说一个持续集成的流程,我们可以通过CodePipeline这样的可视化工具去调动云端的服务,去进行各种自动化的持续集成工作。
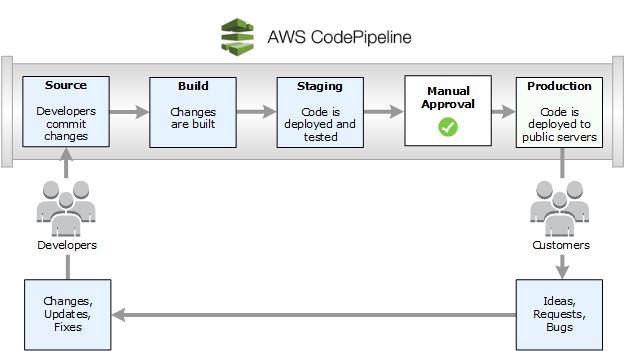
AWS CodePipeline管道流程
这个持续集成的工作通常包括了好几块,会有代码、构建、各种的Staging,我们需要在不同的Staging里面去做不同的测试,可能我们有些项目里需要一些人工的审批,确定是否去不到我们实体的生产环境里去,这一部分无论是自动化的流程还是人工审批的流程,我们都能可视化地构建在Codepipeline流程里,去让它很完善地流动起来,数据也就可以很好地在这上面去做。

这个是CodePipeline界面的截屏,我们可以把Source、Beta阶段、QA阶段通过一个很好的可视化工具去做,相信在座的各位应该用过Jenkins,或者别的一些开源工具,都能够构造出一个很好的Pipeline。在AWS上面,大家可以沿用自己传统的一些使用工具或已经非常熟悉的工具去做,这些都是支持的,包括我们的Codecommit,也会有相应的Jenkins插件去集成。如果是初创企业或者新的研发团队直接使用云端的资源,也可以大大节省学习成本和部署成本。
4、AWS CodeBuild
有了CodePipeline和CodeCommit以后,我们就有了流程,有了源代码,这时可能就需要一个很重要的编译。编译环境在很多的开发团队或者说在DevOps过程里是非常重要的,很多团队可能会使用Jenkins或者别的一些工具去构造这样的编译流程,但AWS CodeBuild是在具有弹性的云端编译工具和环境中,它会预先帮大家构造好一些成熟、常见的编译环境,比如安卓、Java、Golang等各种的编译,当然JS不算是一种编译了,但JS的项目通常也需要打包,所以我们就无需重头去建立这样的一个编译环境。
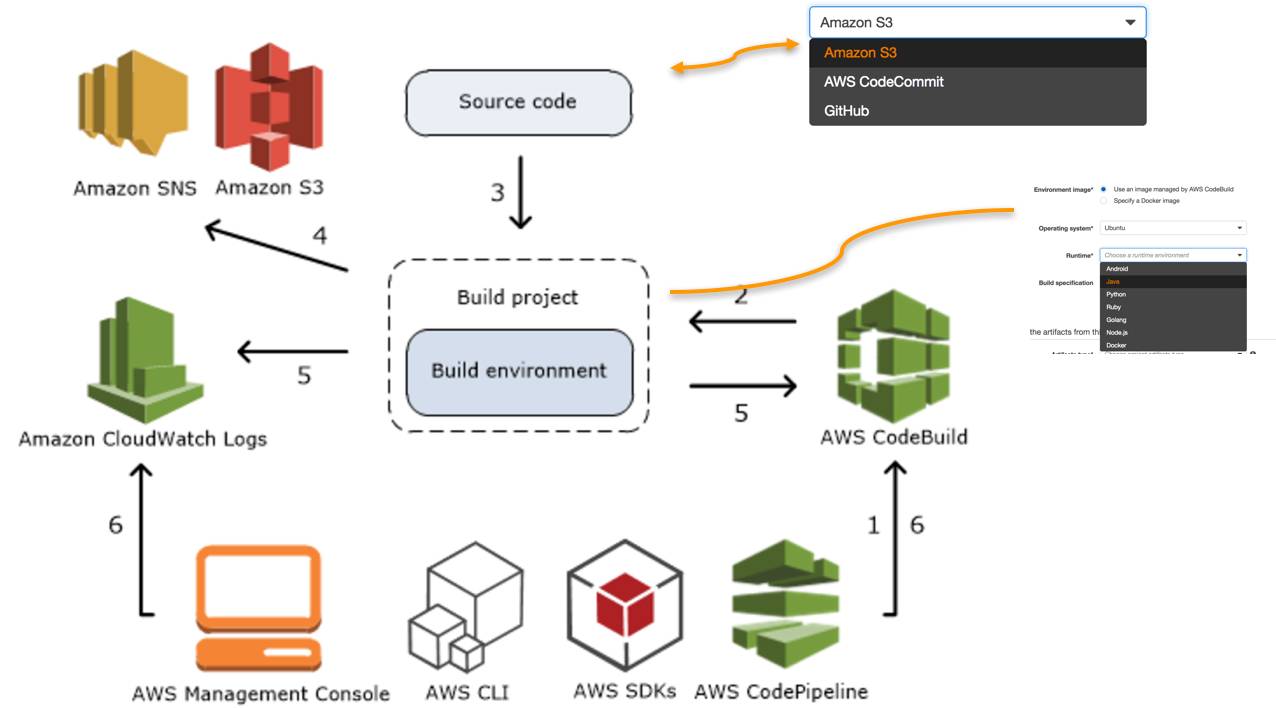
AWS CodeBuilde工作流程
另外还有个非常重要的事情,在很多已经很成熟的团队里,可能公司内部已经构造了一些很好的编译环境,这些我们也已经搭建了,但没办法避免的一件事就是我们的本地资源是有限的,很有可能在不同的团队下面,我们可能刚好有一个大的发版情况,比如说在双11前我们会集中式地去做一些开发,这时可能同时有好几个团队都在编译,这种情况下,我们的资源就很有可能会不足。但在AWS CodeBuild的过程中,每一个团队去创建一个CodeBuild实例时,它其实都是在云端申请了一段新的资源,这时它的资源永远是不会跟别的团队去竞争的,这个情况可以大大保证我们的开发团队整个开发的过程,而不会因为一些开发流程的竞争而导致实际工作被阻塞,这个是云端一个非常大的好处。我们在云端去构造比如Jenkins这样的环境时,其实也很难去构造一个完全弹性的环境,而CodoBuild里是有一些已经内置好的,当然如果有一些自己的发布情况,也可以把自己打包成一个Docker的镜像,作为一个Customers的Codobuild镜像发布上去。
有了CodePipeline、CodeCommit、CodeBuild以后,我们就能在云端很容易地构造一个持续集成的完整链条。我们的代码Commit以后,有一个很常见的开发过程,比如说我们本地有一个开发团队,他们本地可能使用Gitlab建了自己的一个开发的Git仓库,本地仓库进行完一个简单的单元测试以后,它就可以通过这个团队的管理员,比如说他是有权限去把这个代码Push到远端的CodeCommit的仓库,那么这个代码一旦进到Codecommit仓库,后面的流程就完全自动化,CodePipeline会发现Codecommit的一些改动,然后会把这个代码拖下来,启动一个Codebuild的环境进行一个编译,接下来我们还可以持续地结合一些测试的工具进行一个代码测试,步入单元测试,或者说一个QA的测试,而生成的代码我们可以放在S3上面,这样就完成了一个持续集成的过程。
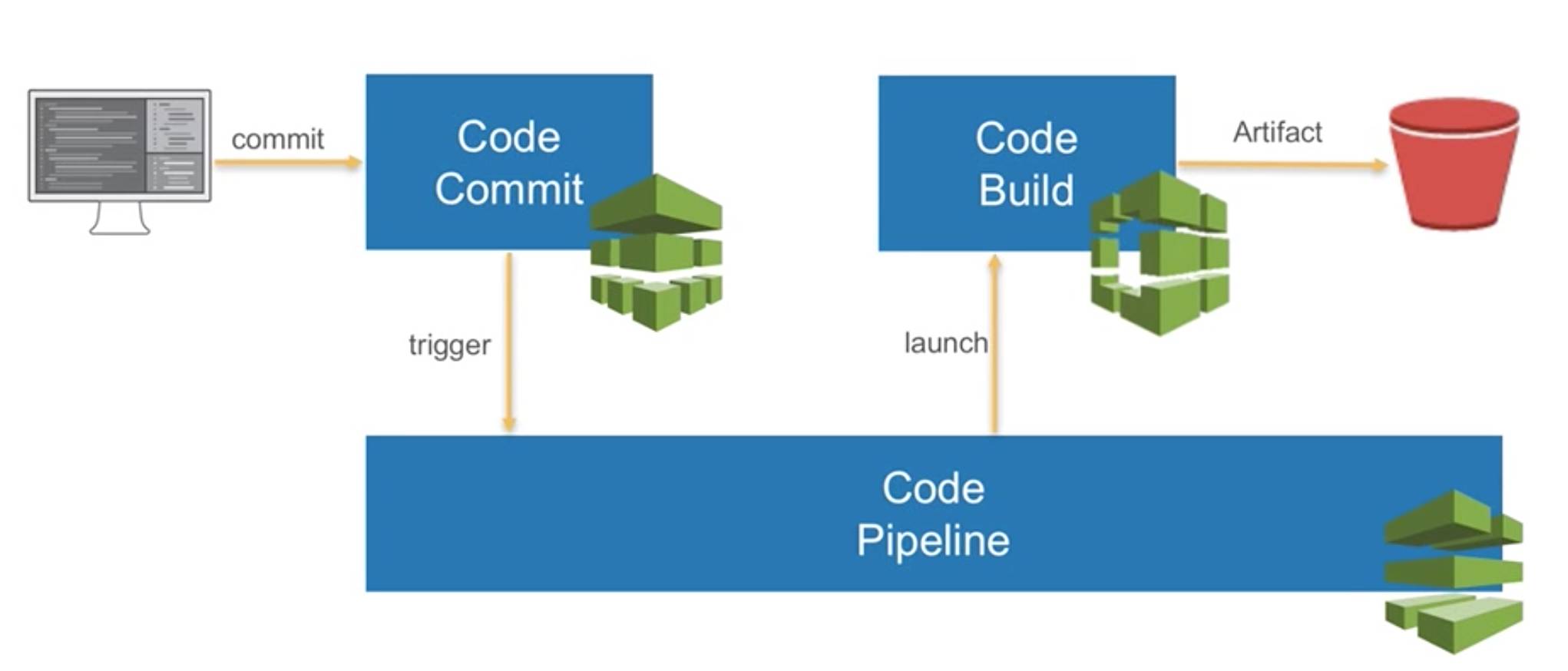
AWS 持续集成
这是一个在云端很顺畅的过程,当然,即使我的一些客户他们也在云端构建了类似的过程,他们也不一定要使用到亚马逊的服务,最重要一点是,在云端的一些资源,因为都是弹性的,在不适用时,Build服务器其实不会占着我们的使用费用或开机费用,CodePipeline也会在后面默默地等待Codecommit的存储,所以在整个开发的过程中,如果我们很多时候可能都没有动到这一块,它整个过程是没有产生任何费用的,只需稍微给一些代码存储的费用,只有当我们的代码真正进入到远端的分支以后,它才会开始启动AWS云端的服务,去产生这样的一个实际的集成。有了持续集成以后,我们就要进行持续地部署了。相比持续交付,持续部署更多的一个情况在于部署过程中,会把人工化尽可能地减少,逐步地做到完全自动化的部署。
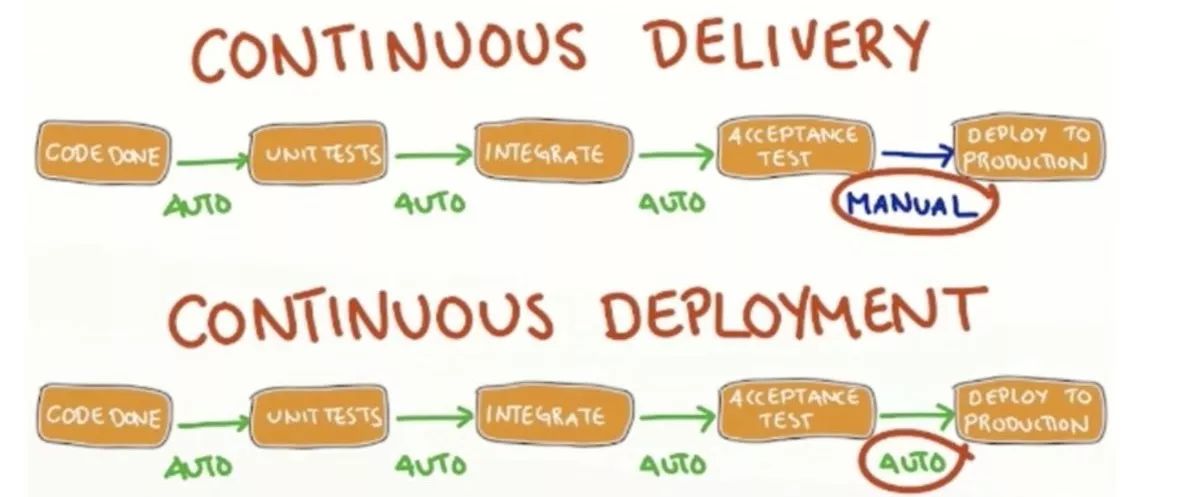
持续交付与持续部署的区别
5、AWS CodeDeploy
我们会有CodeDeploy这样一个服务,CodeDeploy的服务其实是处于AWS整个Devops体系中一个承上启下的作用,它往后会跟我们的CodePipeline去做集成。
当CodePipeline做了一个测试以后,它就可以往前去调用我们的各种基础设施,去生成一些真正的生产环境或者说蓝绿测试的环境,去部署我们的软件包在上面,并且调用一些测试的过程。CodeDeploy能够很容易地通过一个很可视化的部署,去把我们的实际的软件包发布到不同的环境里,比如说我们有开发的环境、测试的环境,还有生产的环境,它可以集中化地控制成千上万台不同的服务器,然后做滚动的发布等各种情况。
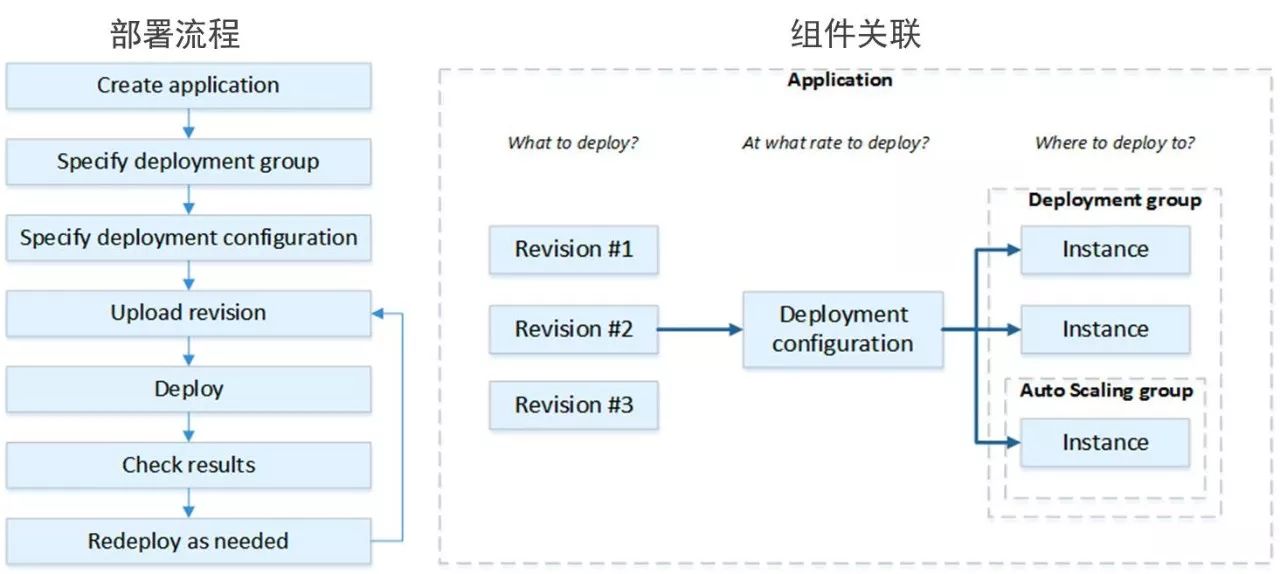
这是一个很典型的部署流程,我们可以通过自动化部署直接发布到实际的应用里面去,比如说Instance,在亚马逊上面就是我们实际的实例,可以通过Auto-scaling group去按照我们实际的一个业务流量去扩展这个实例,并且这些扩展也是可以被自动关联起来的。

这个是CodeDeploy的一些语法,它使用YAML的方式去定义一个实际的版本控制,在整个Deploy的过程中,我们可以控制它的代码在什么地方,安装包在什么地方,安装成功前后,我们都可以做不同的Staging动作。
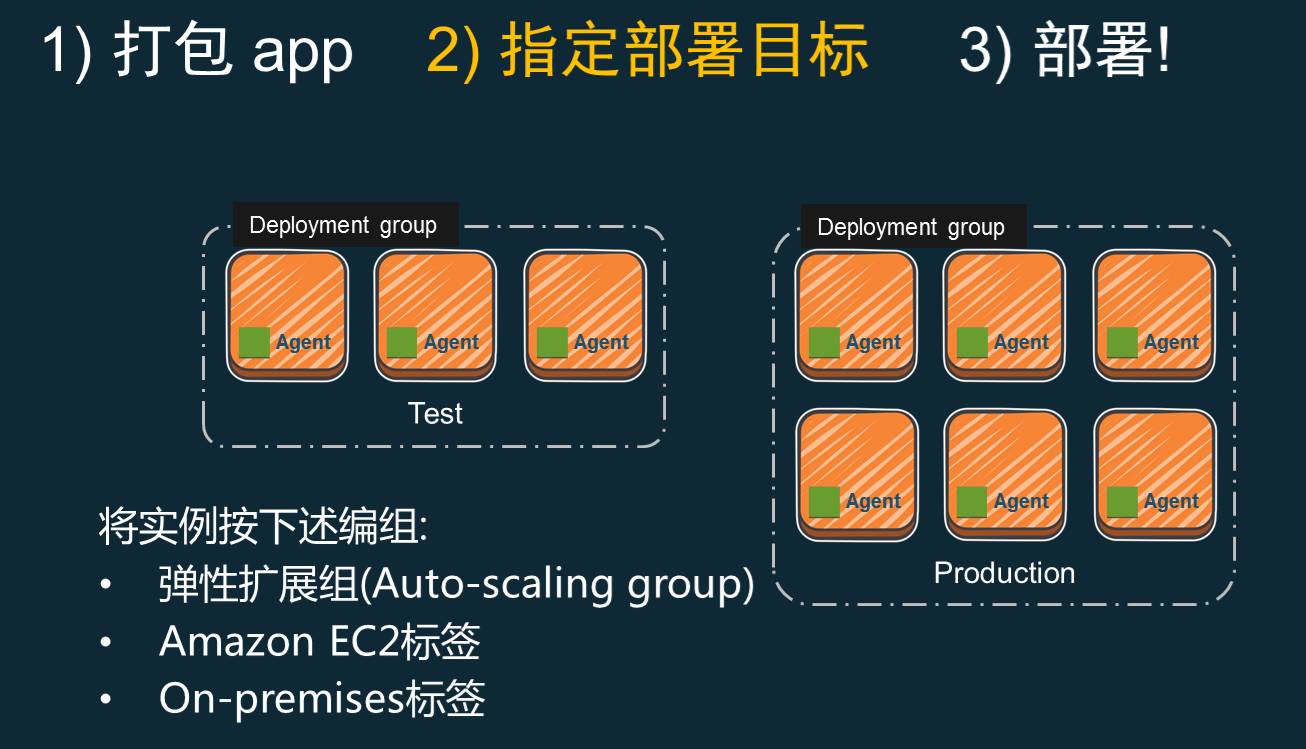
此外,我们可以去编排不同的目标组,因为不同的目标组可能会有不同的实例大小,或者实例组。

这个其实在很多的团队里都会用到,他们开发的环境会有这样的一些环境,在我们的生产环境会有更多、更强劲的服务器去做,这些东西我们都可以通过CodeDeploy的一个描述把他们全部描述完成,有了这样的部署以后,现在一键就可以去创造整个部署的目标,包括CodePipeline也可以直接调用这样的CodeDeploy去做。
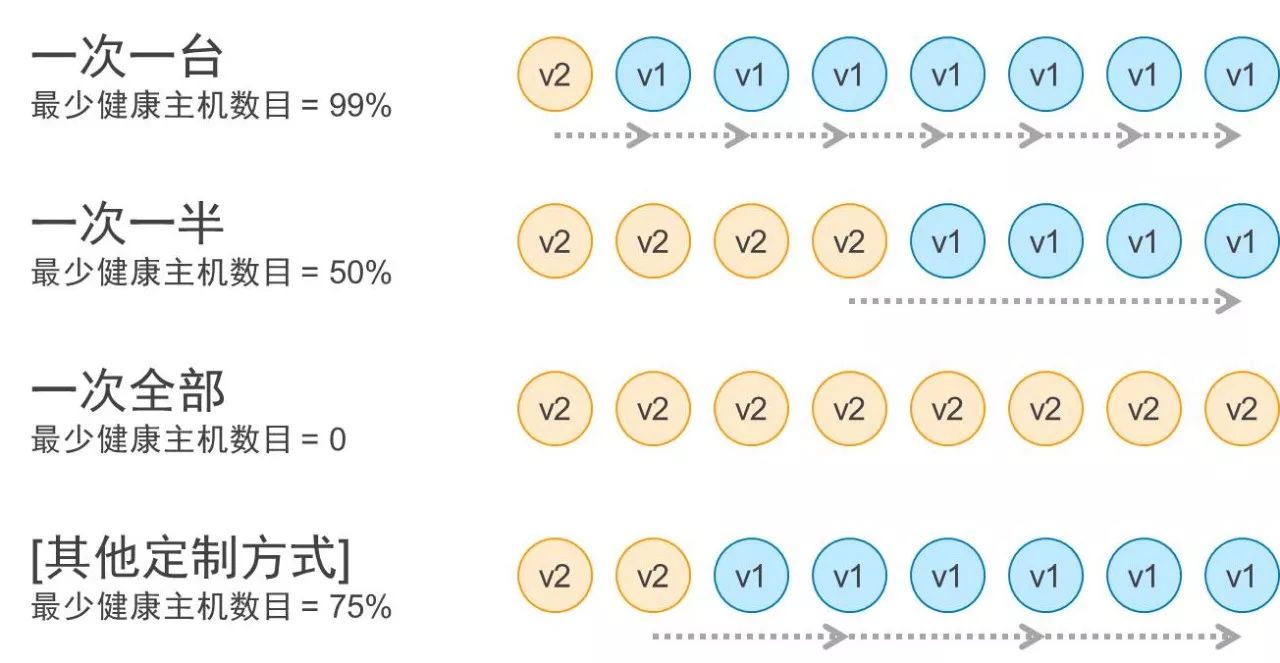
还有很重要的一点,就是我们可以在云端很好地去调用云端弹性的资源,去构造不同的发布方式。比如说我们在云端希望保证一个数据的可用性,可以把它变成一次一台的发布、一次一半的发布或者一次全部的发布。
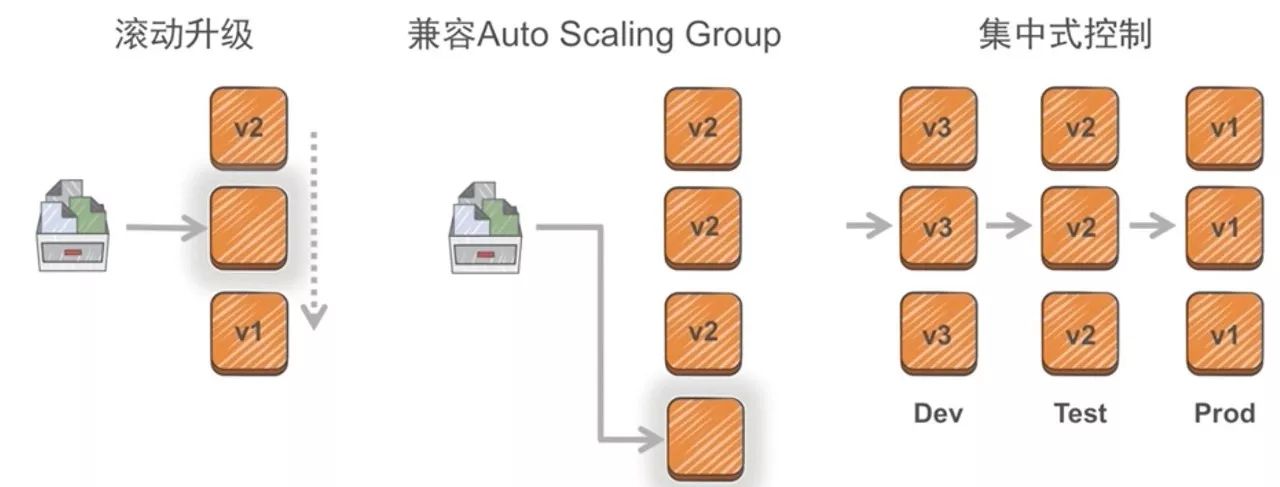
图:Codedeploy如何工作
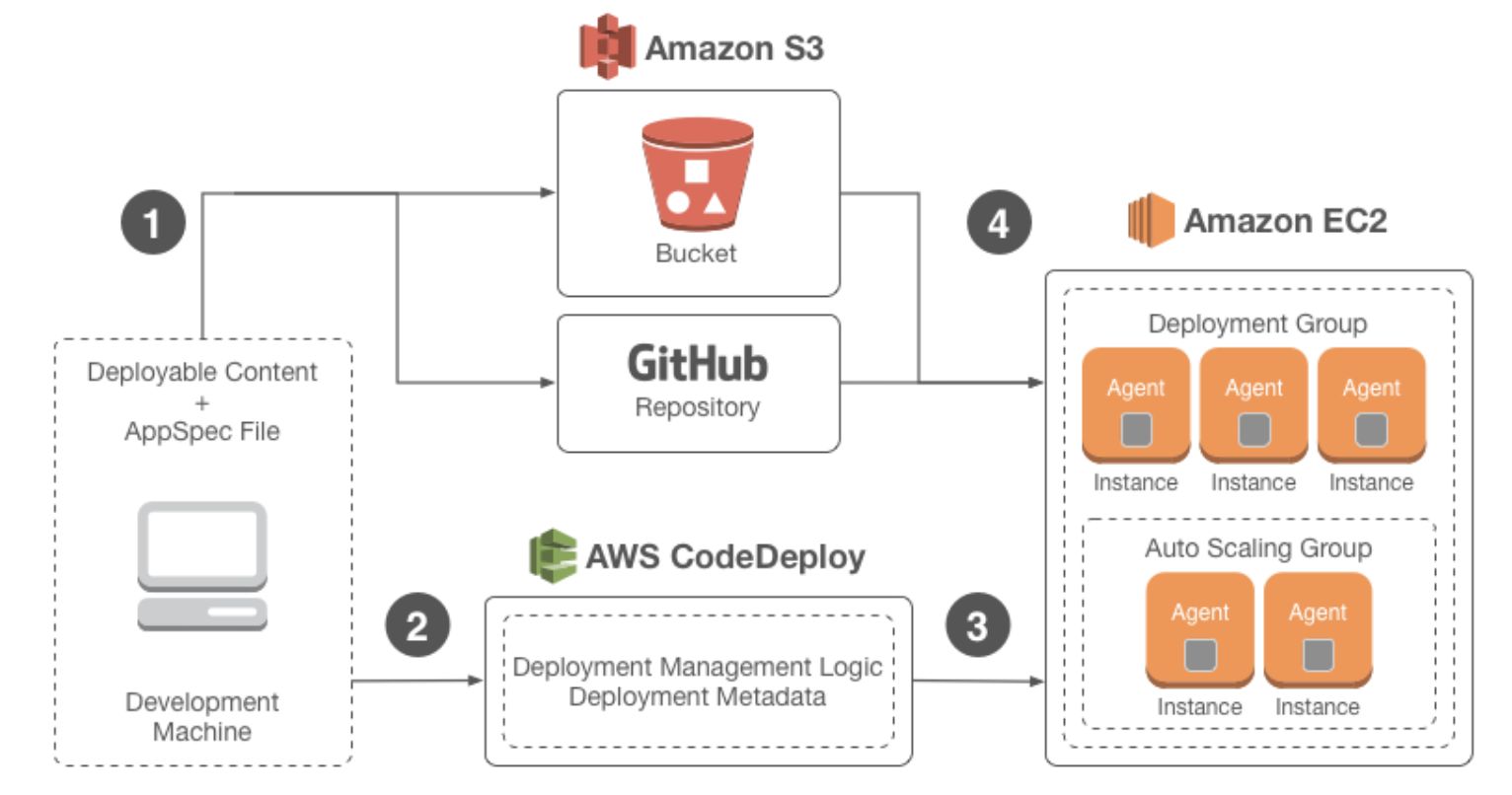
图:CodeDeploy就地部署
其实在云端还有一些更好的发布方式,因为一般来说,云端的资源像开水龙头一样,您可以认为它是无限的,所以我们的Auto Scaling Group会去做一个折算的弹性发布。比如说我们原来的业务在生产系统里面本来是有三台机器的,然后需要去扩展我们业务或者发布一个新版本时,我们可以在很短的时间内在云端产生一台新的机器,把我们实际的新的版本放到这台新的机器上面去,再通过刚才说过的域名方式或AWS负载兼容器的方式,把一部分的流量往这个地方去发布,这个情况其实构成了一个蓝绿的发布。
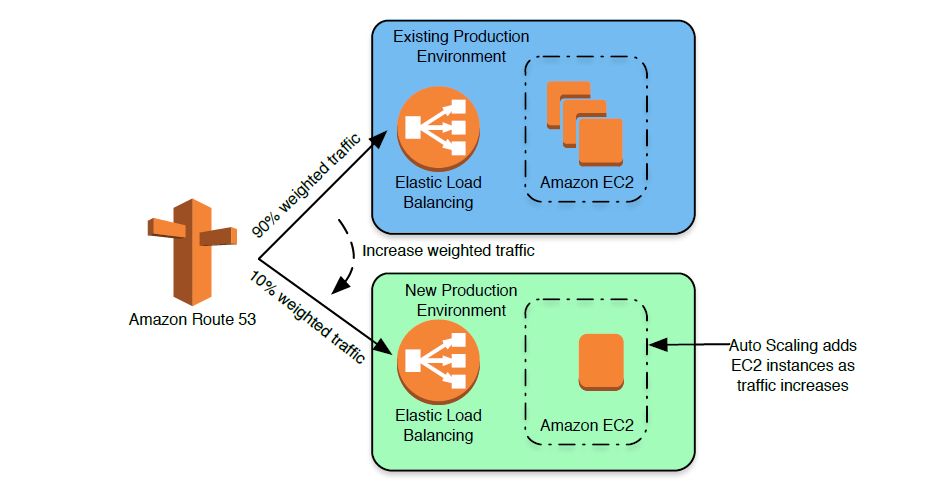
这个蓝绿发布在绿的部分完全是一个新的机器,不会干预到我们实际的生产环境的机器,我们通过这样域名的方式去把一部分的流量引入到绿方的新发布里去,然后通过云端的工具去监控绿方这边的动作。刚才说到的,我们可能会监控它的错误码、订单下载量等,发现这个绿的部分情况完全没有问题后,我们可以在云端逐步地增加绿这边的流量和它实际的机器数量,最终我们发现在新的版本环境已经完全可以支撑服务了,我们再移步把蓝方这边旧的环境全部给切换掉,把机器也关闭掉,这里成本几乎是没有增加的,增加的只是在这几个小时的发布过程中一个双倍机器的成本,之后我们还是用一样的机器去支撑一样的服务,这是一个在云端蓝绿发布非常好的实践。
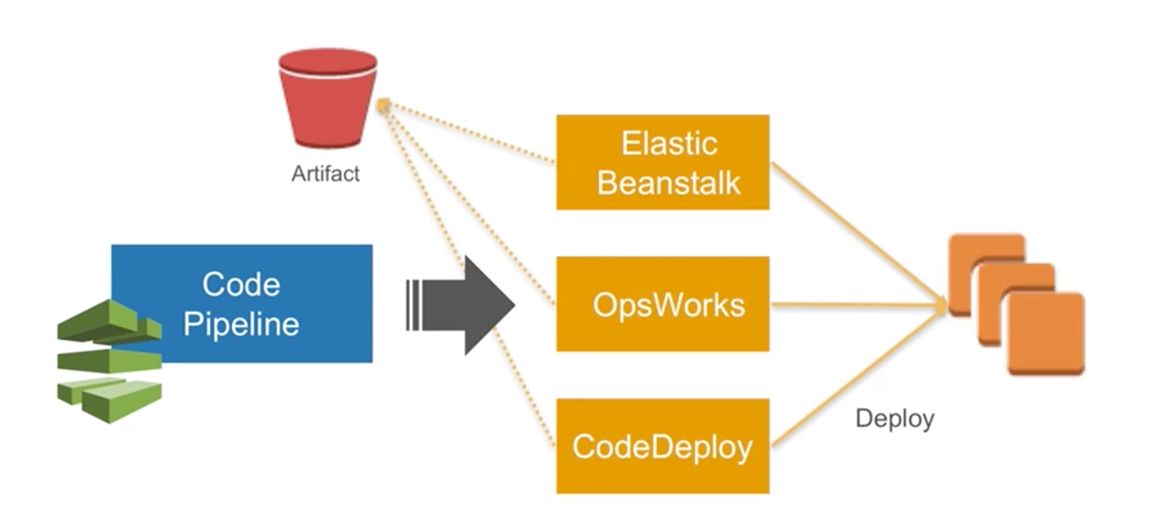
所以,当CodePipeline加上CodeDeploy,我们就可以很好地控制持续部署的流程,后面我还会介绍OpsWorks和Elastic Beanstalk,折算子的基础设施即代码的服务。这个也是我们希望做到的一点。
6、基础架构代码化
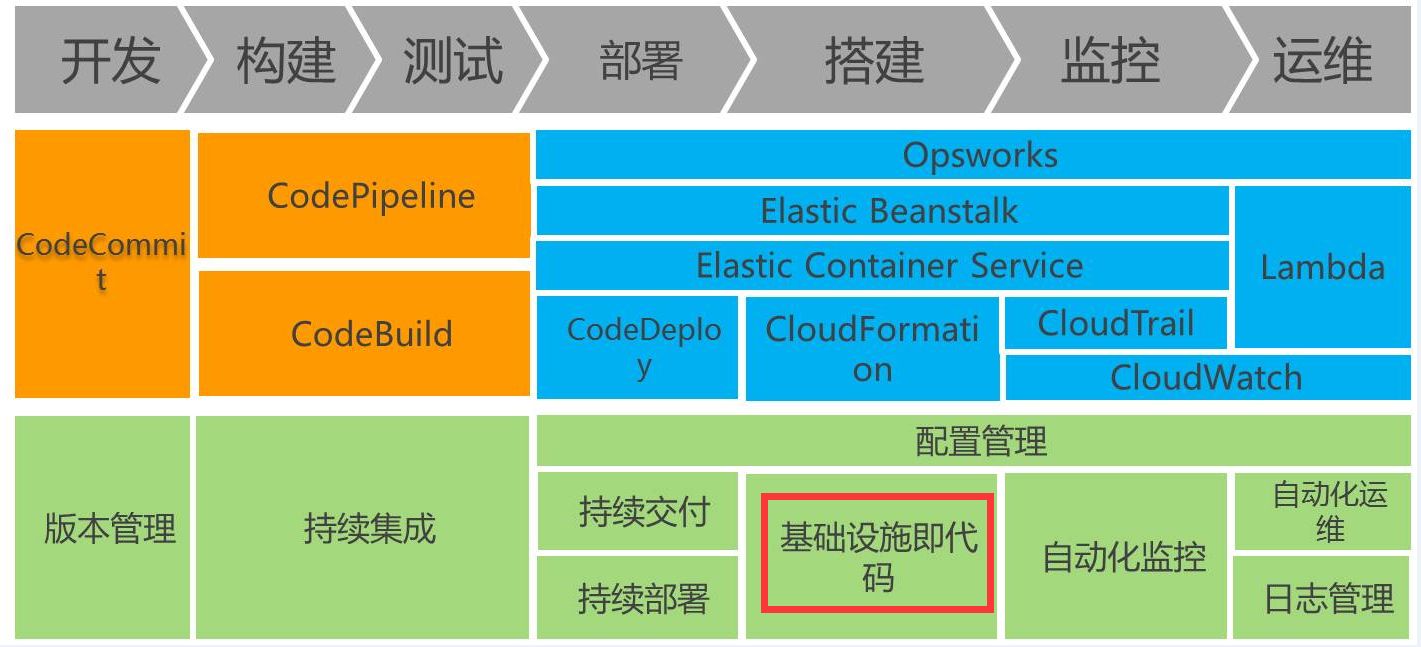
刚才说到了AWS其实是亚马逊微服务化的过程中的一个产物,在这个过程中我们发现这种经验不仅仅可以帮助到自己,也可以帮助到我们的客户,所以我们在2006年就发明了这样一个公有云的服务。这个公有云服务一个很重要的过程,就是说我们希望公有云上面的一切东西都是一个API,有了这个API以后我们就可以用代码去描述我们在公有云上的每一项服务。所以在AWS DevOps服务的右手边,包括部署、搭建、监控、运维等,这都是一些基础设施即代码的服务,这里面包括了我们的Elastic Beanstalk,就是说如果我们的团队仅仅是开发一个php的集成环境或Tomcat的集成环境,我们并不需要很复杂的互相访问架构,这时就可以使用Beanstalk;如果是需要描述一些很复杂的互联方关系,可以使用CloudFormation这样一个YAML或者JSON放入描述语言,去快速地构造云端的整个基础设施。
当然,如果你的团队在Chef这方面有很深的研究,也可以使用我们的OpsWorks,按照Chef的方式去定义整个环境的各种Layer,而且我们可以直接使用在社区各种Chef的Code去调用AWS的环境。

图:操作AWS服务的三种方式
首先这是AWS服务的三种服务方式,很多人刚刚接触AWS时,第一个接触到的一定是左手边的Web控制台,Web控制台是很重要的一个用户界面,我们可以在Web控制台上控制大部分的AWS服务,但其实这些Web的控制台上面的每一项功能,后面都会对应着一个DevOps API或SDK,然后可以通过我们的开发或命令行去操作这样的DevOps工具,有了这样的基础以后,就能做到各种基础设施即代码的服务。
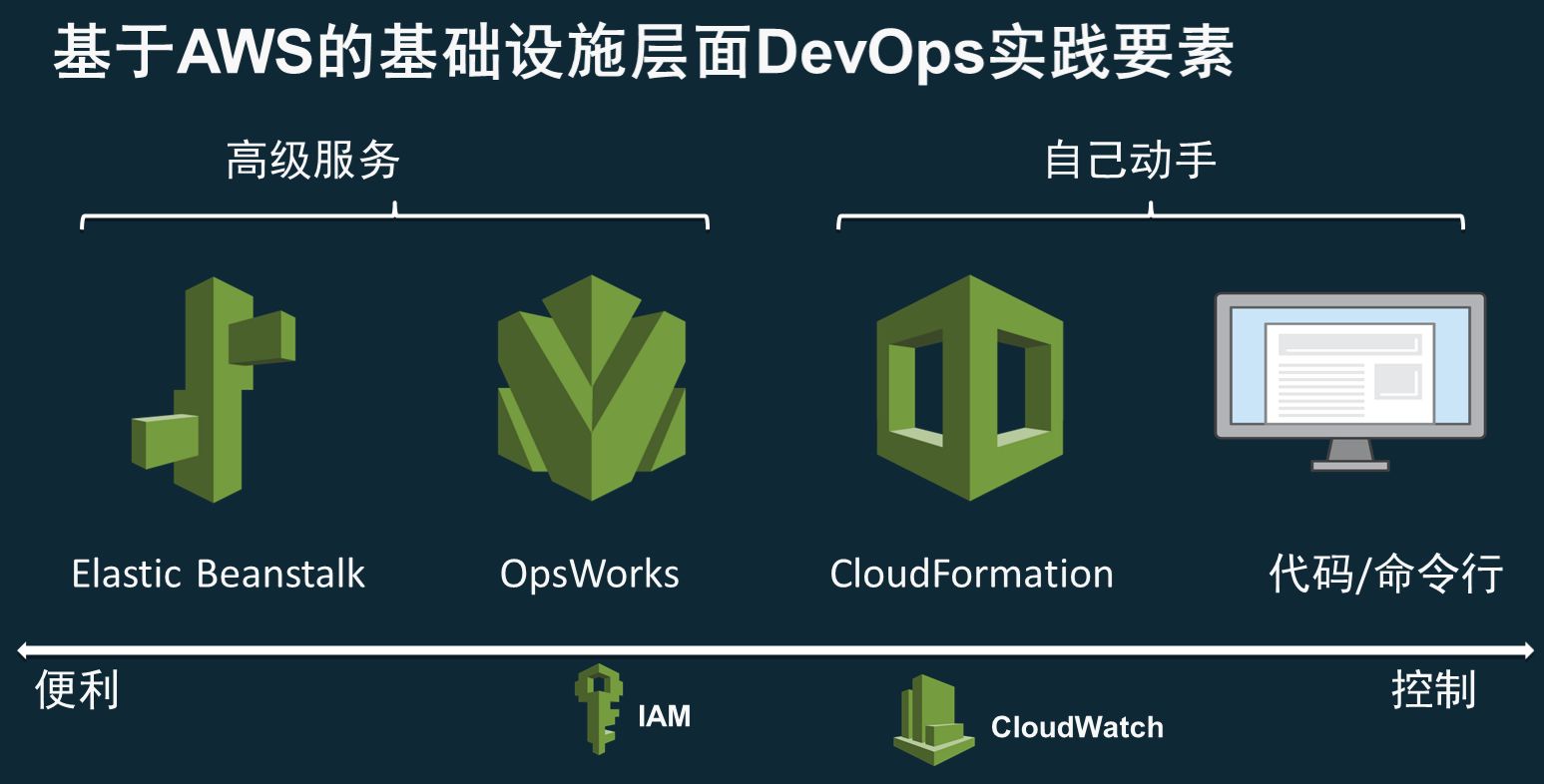
7、Elastic Beanstalk
最简单最傻瓜的版本就是Elastic Beanstalk。如果我们新建的创业团队有一个电商或者互联网的项目需要构造跟微信的对接,会使用一些特定的技术栈,比如我们会使用PHP、mysql这样的方式。而现在你只需要在Elastic Beanstalk上面选择一个这样的技术栈,一键就能帮你去做出这样一个完整的环境,里面包括了的语言比如PHP,还有底层的一些数据库服务,都会安装好。这样的情况下团队马上就可以投入到开发的工作,而不需要担心各种的基础设施的问题。同时我们的应用部署可以自动扩展,可以去跟各种的ID做结合,这样的情况下,代码人员纯写代码就可以运行到这样的一个环境。
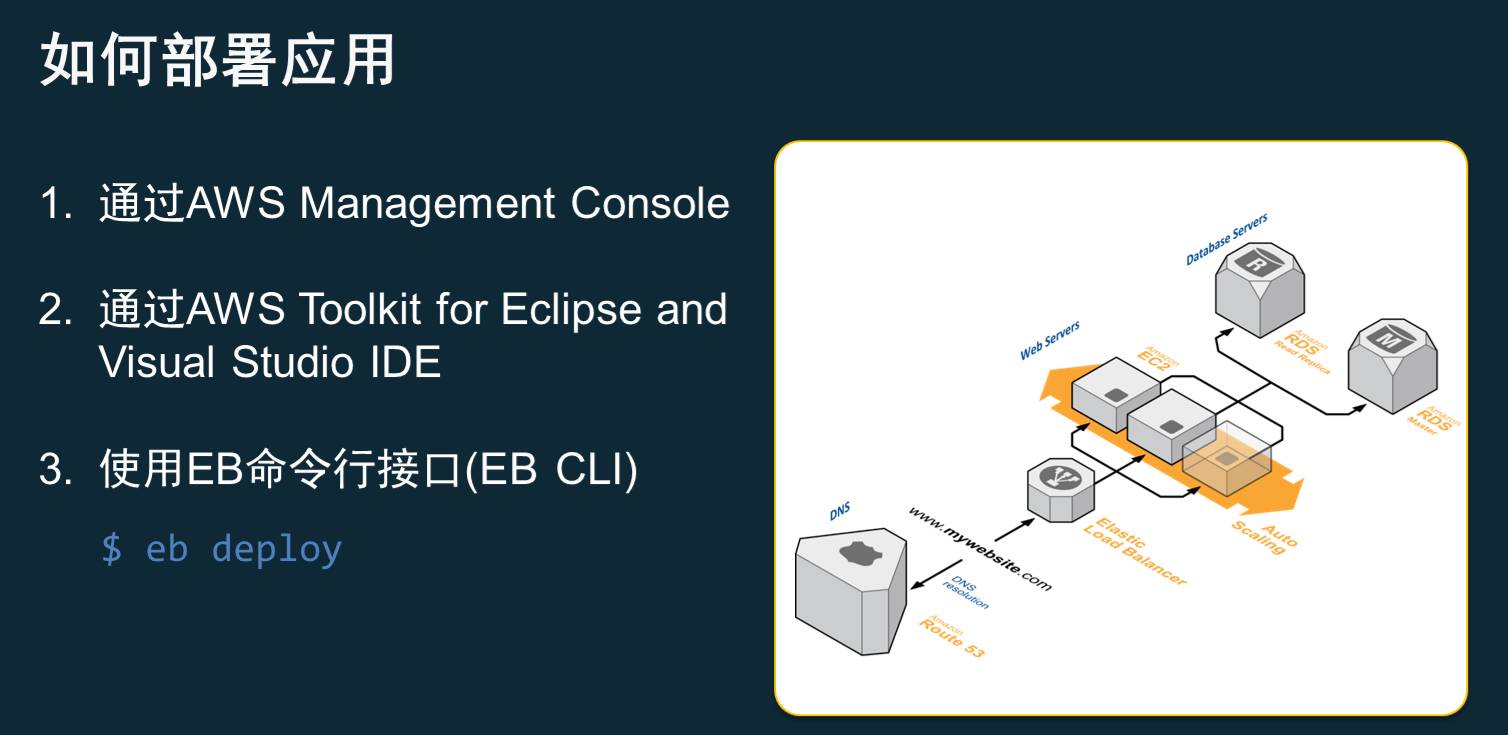
AWS自身的环境包括了Java、PHP等这些东西,Golang也可以用到。我们一样可以通过Elastic Beanstalk部署到在持续集成里,而当经常面对到不同的环境时,比如说我们会有测试、Staging的环境、生产的环境,他们之间可以通过不同的版本去发布,而不会去互相地影响到,我们也可以调一部分环境去测试。
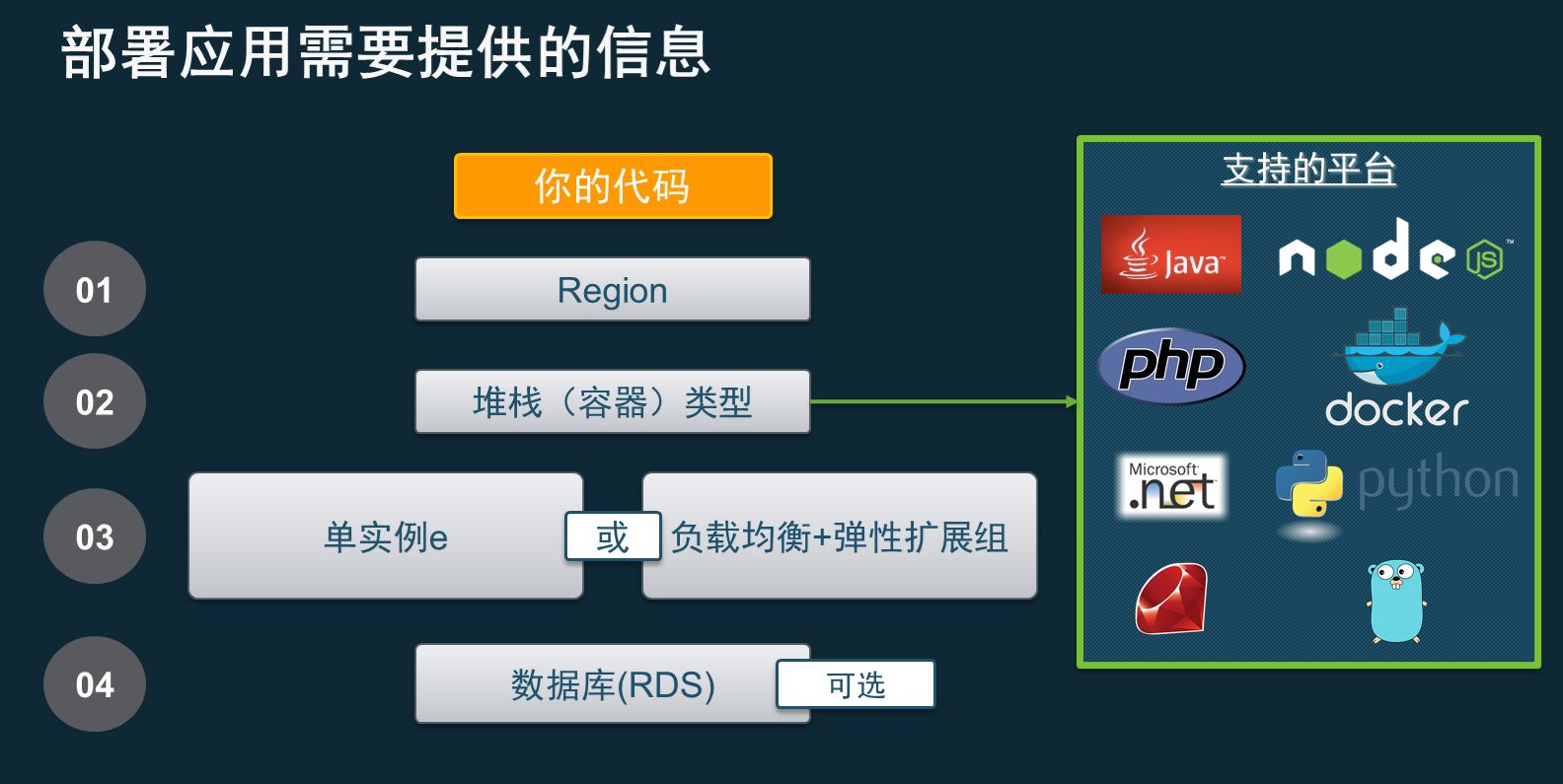
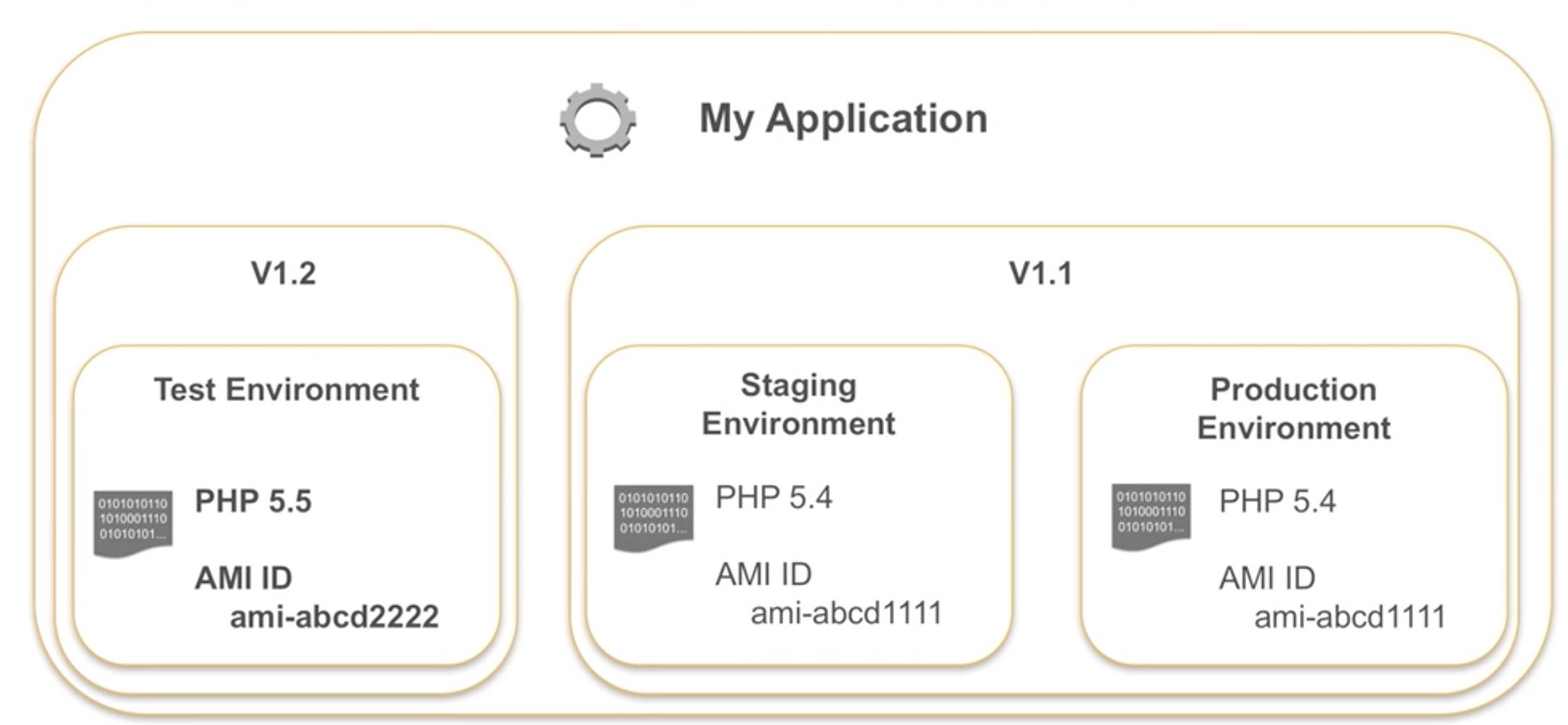
图:Elastic Beanstalk构建不同版本环境
8、Cloudformation
接下来如果要构造一些更详细的服务,我们可以使用CloudFormation。刚才说到AWS所有的资源,无论大小,它在提供时一定会提供API,而且我们会有SDK,在这个基础上,我们构造了CloudFormation这样一个组建的工具,可以通过JSON或者YAML的方式去描述你在AWS上面任何一项资源。
这个资源我们是可以通过变量去控制的,比如说常见的一些生产环境和测试环境,它们绝大部分的结构是一样的,但他们需要的JSON的大小可能不一样,我们可以通过一个JSON文件或YAML文件去备注一下他们的关联关系,然后通过不同的参数去启动不同的环境,一旦这个模块文件产生了改变,我们后台的程序也会自动根据你的模板程序的改进,去改变你们使用的一些资源跟它们的依赖关系。可以这样理解,JSON文件是一个类,它跟模本的程序产生每一个堆栈,这个堆栈就是这个类产生的实例,然后刚刚提到的变量,根据这个变量,这个实例的大小就会不一样。如果你的类改变,它的实例也会跟着做一定的改变。
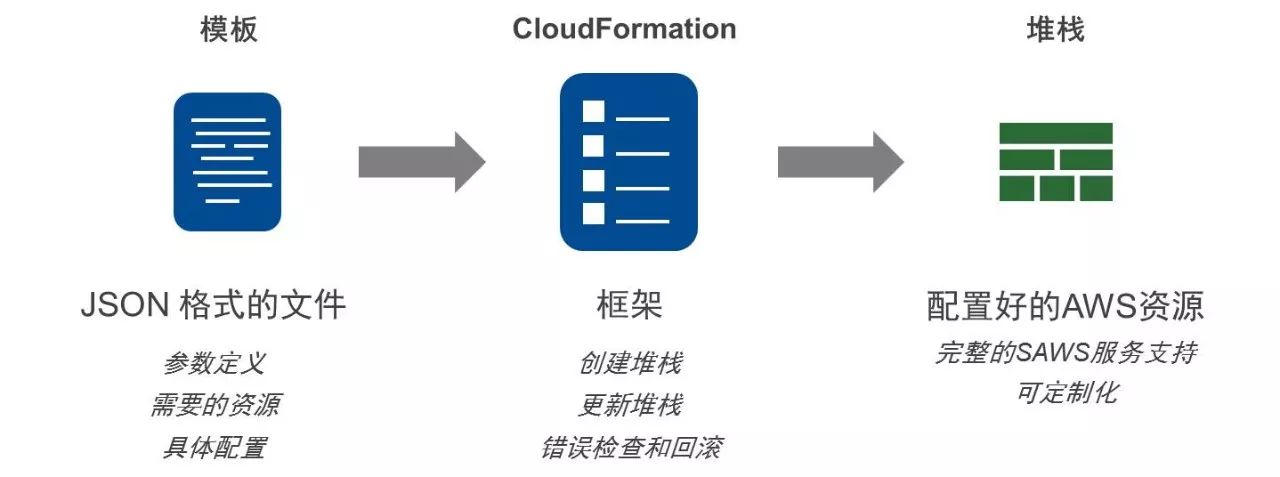
图:CloudFormation组件和技术实现
这样的情况下,我们就可以做到整个基础设施平台的模板化,这对于DevOps是非常有用的,也就是说整个基础设施可以非常好地管理起来,比如说可以使用AWS的各种代码管理工具去管理我们的基础设施。
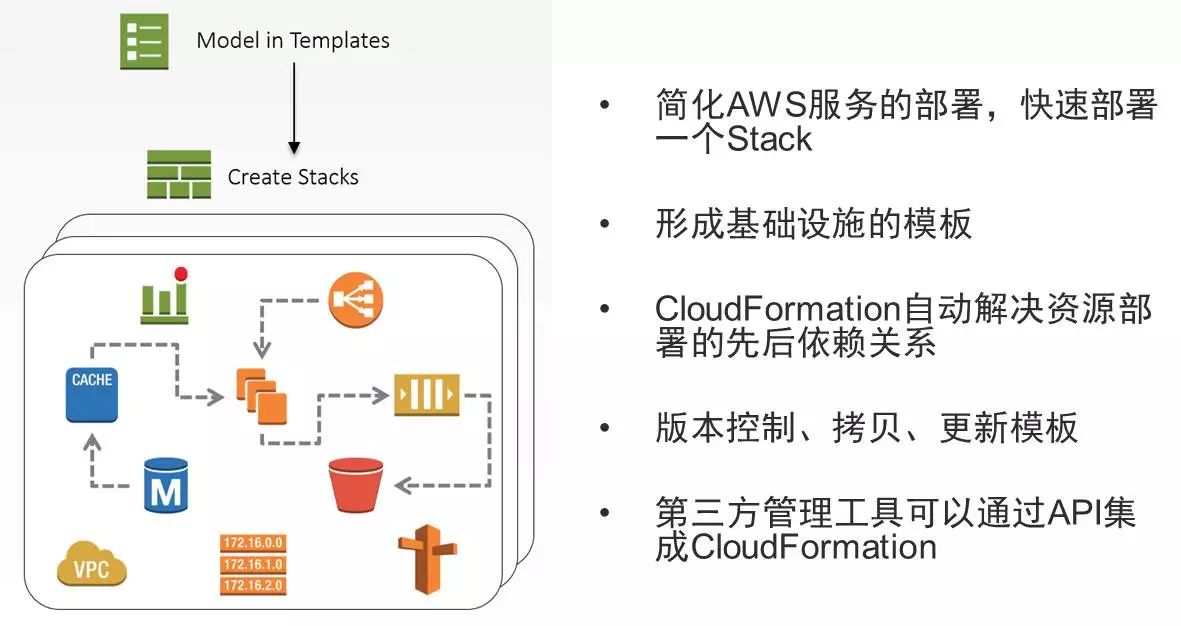
图:基础平台模板化
比如下图中的这个服务器,原来只是Application到数据库的,现在要在中间增加一个Redis作为缓存,基础设施的这种改变,可以完全用代码的方式描述起来,并且这个改变也可以被Commit到我们的代码库里,因此我们能够知道这个改变是什么时候产生的,为什么要这样产生,可以很好地去做这样一个动作。
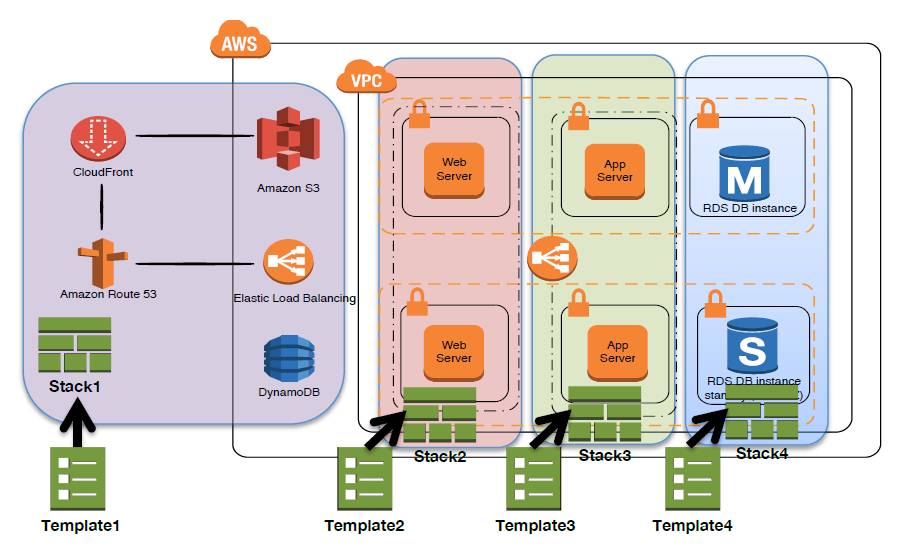
图:基于模板的快速部署
基于这样的模板就可以产生不同的环境,这些环境可以去做不同的改变,然后我们也可以做到不同的生产测试环境与蓝绿部署。
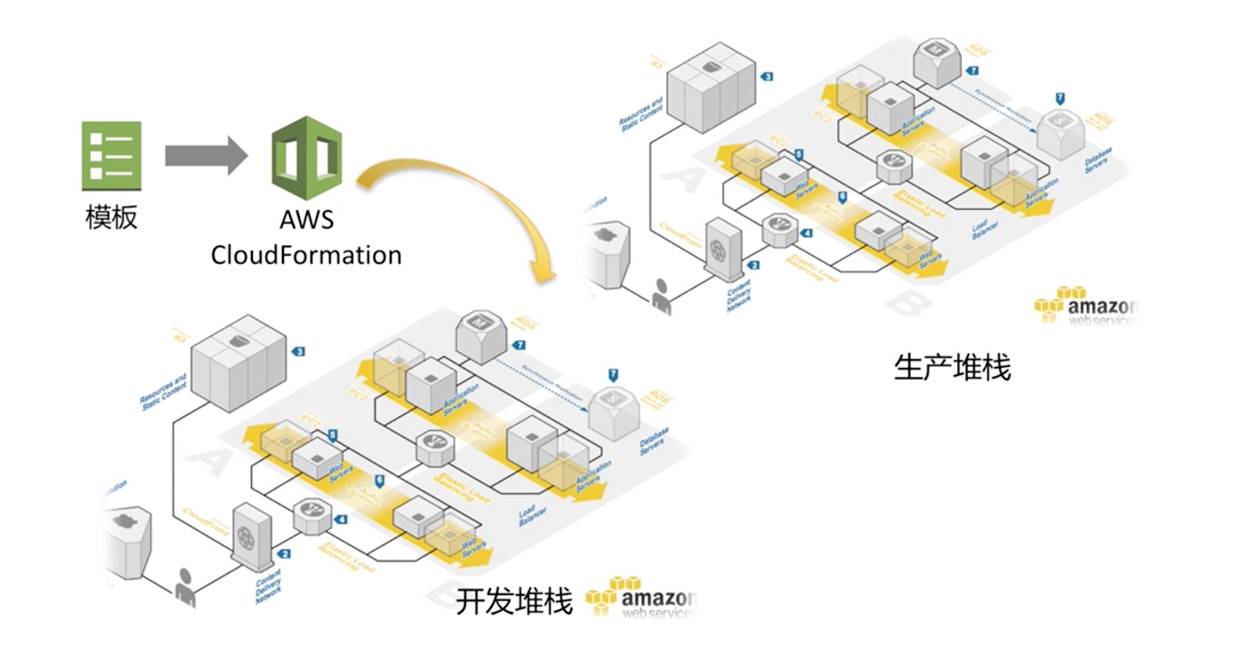
图:Cloudformation一键部署全站
这个也是CloudFormation目前能够做到的事情,特别是对很多团队来说,当在中国的业务做大了后、想往海外发展时,我们可以利用在中国积累的经验,很容易地应用AWS的基础设施快速地部署到10-20个不同的海外区域,如欧洲、美国、中东甚至东南亚这些地方,这些均可通过一个代码、一套代码,去一次部署完整个的服务。
9、Opsworks
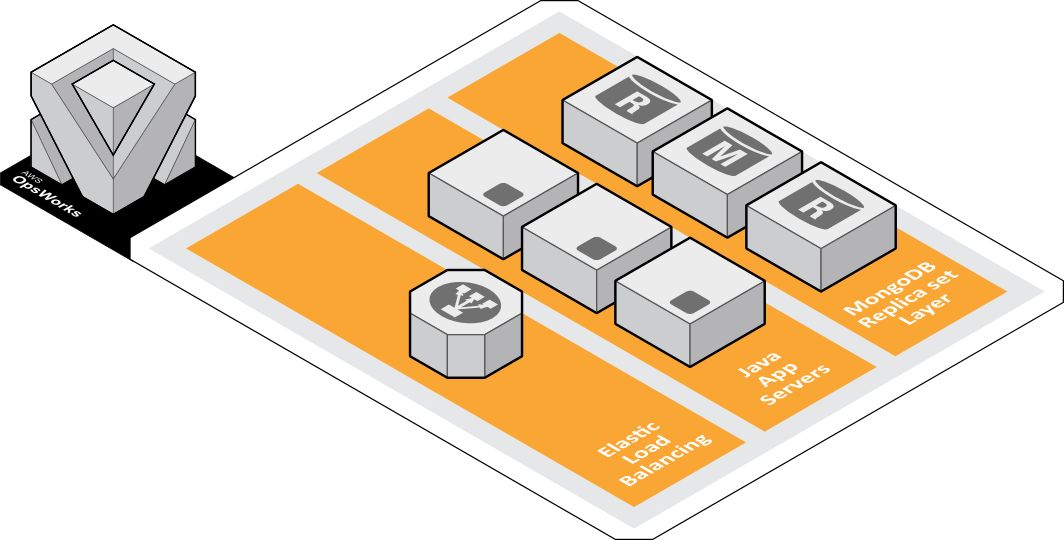
Opsworks大家可能不太熟悉,但说到Chef,各位可能多少都听过。Opsworks其实就是AWS提供的一个托管Chef的工具,它完全跟Chef一样,能把AWS实际的一些资源抽象化成Chef里面不同的Layer并给大家提供到服务,所以我们就可以利用它在Chef方面的一些经验去控制到我们在AWS上的这些资源,包括了它的Step以及不同的Layer,比如说数据库的Layer,No banners这一部分的Layer,还有我们实际Application计算资源的Layer,都可以被控制到。
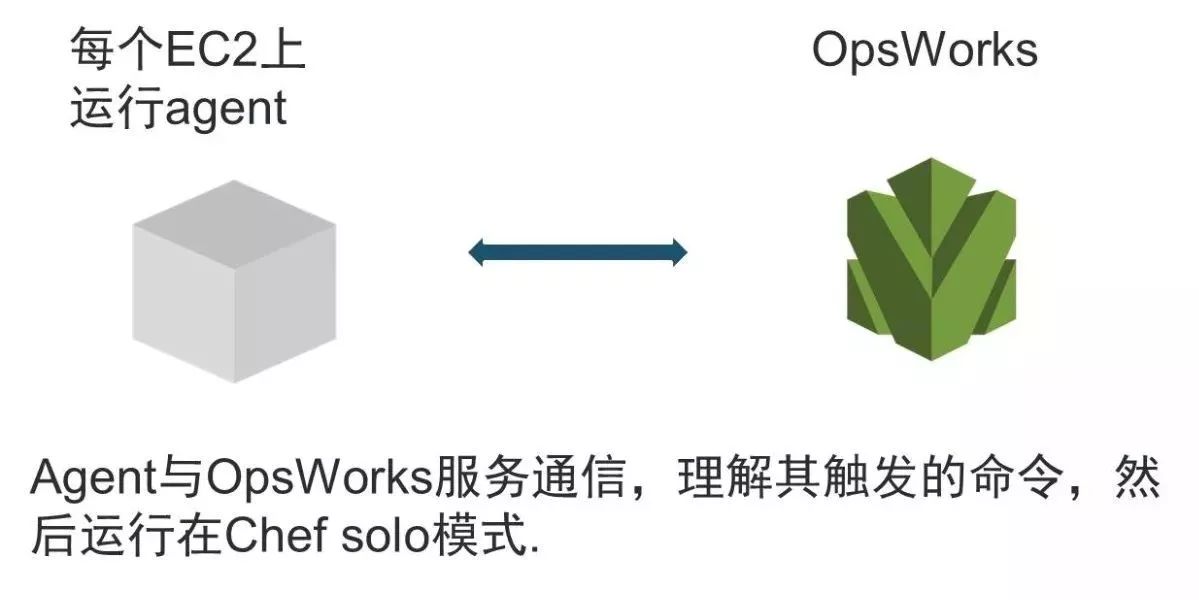
然后AWS就可以通过每个用户的Chef Code去产生实际的计算资源,它可能比传统机房的Chef会更有效,因为对于传统机房,如果你要把这些Layer抽象化出来,你的机器实际上是开在那里的,首先你要付出购买机器这个成本,然后你可能还有接电的成本、电费等。但在云端,你在你的Layer真正产生实例化之前,你是不需要付这个费用的,只需去编写这些Code就可以了。还有一点很重要的是,本地的资源有可能不足,万一发现Layer不够时,我们还要去采购新的资源,这是个漫长的流程。
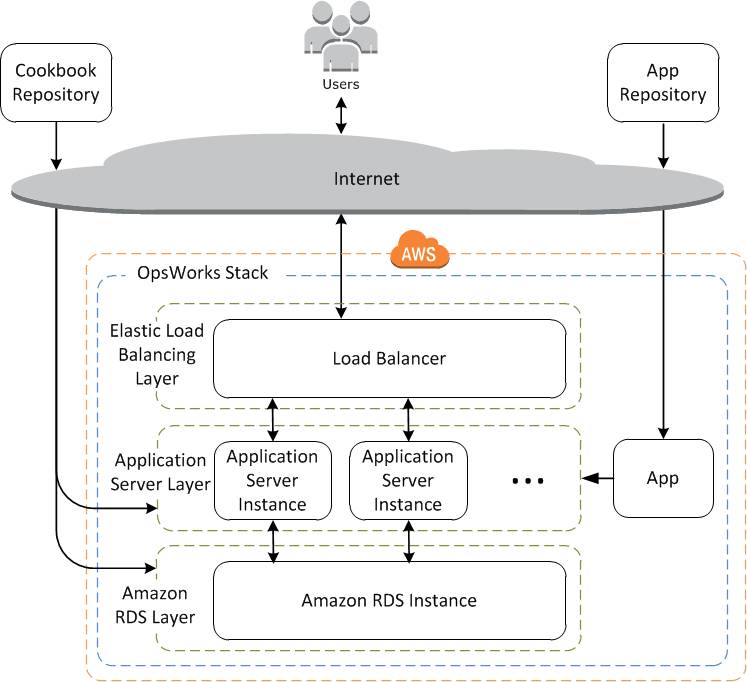
图:OpsWorks工作原理
相信很多Opsworks的团队,都会有这样的深切体验,我们的整个业务可能来不及去支撑发展,而我们的运维也来不及支撑业务的发展,但这个在云端是能够进行改善的,Opsworks就是这样的一个情况,它可以改造这样不同的Layer,可以通过我们已经积累的Code知识去构造Chef的Layer,所以我们能够部署整个Setup、Configure、Deploy、undeploy和shutdown各种不同的阶段,这是我们Chef的一个界面的截图,大家有兴趣可以去看到。
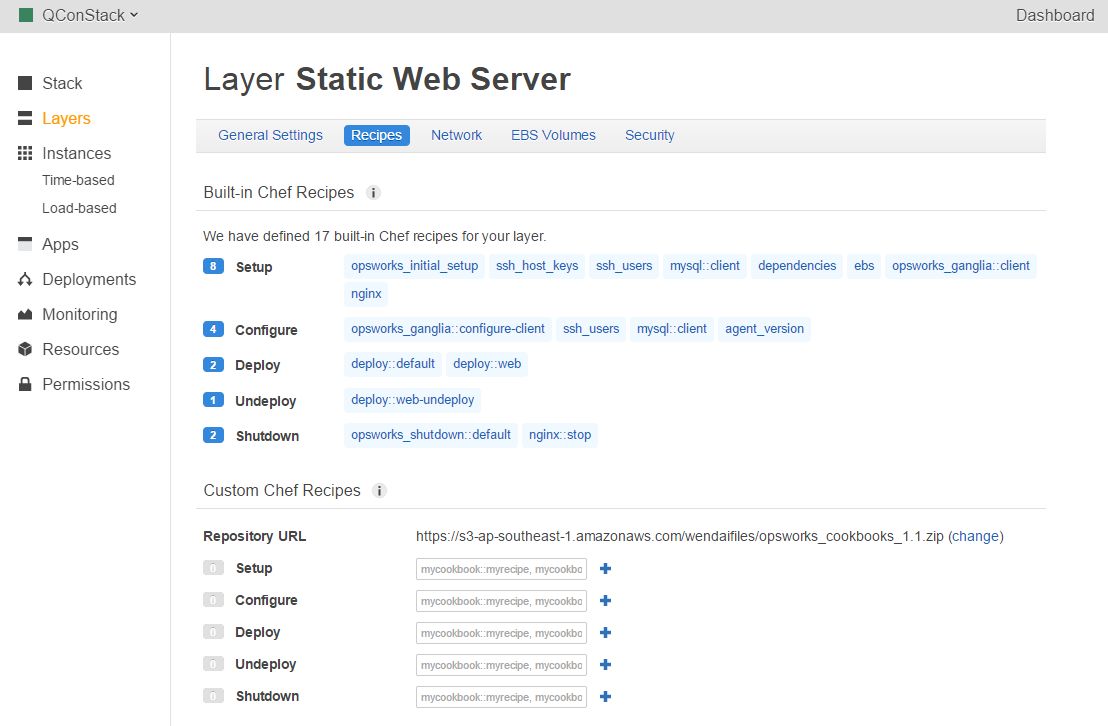
图:使用内置Chef Recipe或定制Chef Recipes配置应用
第三方工具集成

前面也反复说过了,我们的团队现在已有很多DevOps方面的知识了,比如我们可能已在用Github去管理代码,可能部署了Jenkins,可能部署了Pipie各种的环境、Chef,这些东西已有现成的经验,可以不急于丢弃掉,我们云端的资源完全支持大家把现有的经验往云端去集成,而缺乏经验的部分,也可以拿云端的一些资源直接使用起来,这是我们的情况。
10、贯穿始终的安全与监控
安全是非常重要的,在云端,我们只要用好了服务,其安全性很有可能会比在本地更加安全,这里就好比钱存在自己钱包里安全还是存在银行安全一样。但存在银行里是要遵守一定的守则,都会有一些安全的最佳实践。
11、无服务器优化
DevOps,刚才我们说到了从代码开始的持续集成、持续发布,到基础设施即代码,这整个部分都是一个过程,最终实现的目的是希望我们的开发人员可以直接去支撑到业务,这个是非常重要的,我们的运维人员可能是隐身的、自动化的,这是最好的情况,那有没有可能达到这样的过程呢?我们觉得是有机会的,目前AWS也在做这一方面的尝试,就是无服务器的优化。
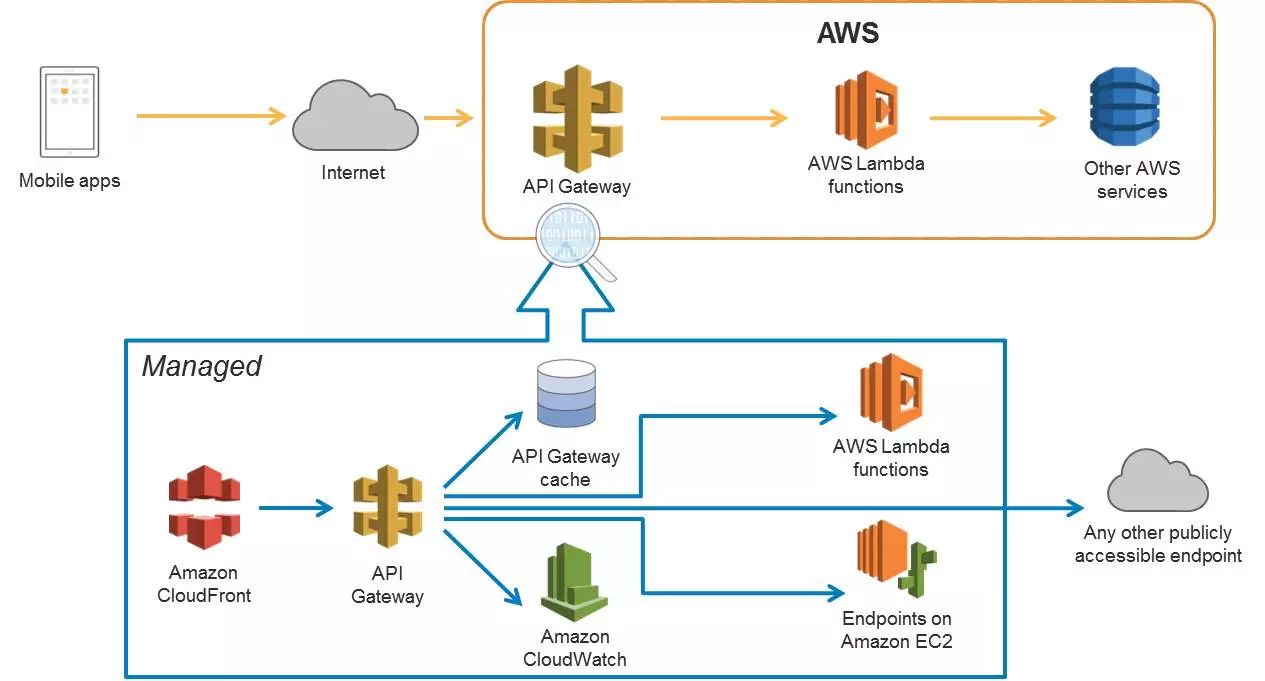
在无服务器方面,大家接触最多的大概说我们不需要去看到服务器资源,希望能够自动化的,首先大家都知道Docker,这里AWS也提供相应的Docker的服务,叫Elastic Container Service的服务,它算是一个Docker的管理器,会同时帮你管理AWS上的云资源去跟你各种不同的Docker镜像的一个编排,最重要的一点就是最右边的这个Lambda。
它是一个无服务器架构的函数(就是说它希望达到的一个状态),实际上它已经实现出来了,现在开发人员只需要去编写一段代码,就是一个事件响应的代码,开发人员响应了代码以后,我们只需要把事件部署上去,就可以在这个事件触发时运行这个代码,而不需要去管理这个代码运行在哪,也不需要管理这个代码是否会有成千上万个并发,这些东西甚至不需要运维了,AWS的基础设施会自动帮你去扩展。

举个例子,假设我现在有一个服务,Java或者ios这种开发,它通过Internet去访问一个API,这个API Gateway是可以通过我们Swagger的方式去描述一个API标准的API,这个API并不需要连接到真正的服务器,而是连接到Lambda上,刚刚也说了,它就是一段代码,就是一个事件相应的结构,你可以用Java编写,可以去JS的方式去编写,然后它可以调用其它AWS服务,比如数据库,直接产生一个响应,这个情况下我们在这个流程中根本没有接触到任何的服务器,所以也没有很详细的运维可言,这是未来的方向,当然它不能替代所有的产品,因为还是存在一些情况。

API Gateway这里也稍微说一下。你可以认为它是一个AWS无服务器化的一部分,作为一个API Gateway,它在AWS端是运维了这样的服务器,但它可以通过你的编写生成一个近乎无线扩展能力的API,这里面包括了各种的指标监控,去调动Lambda的动作。
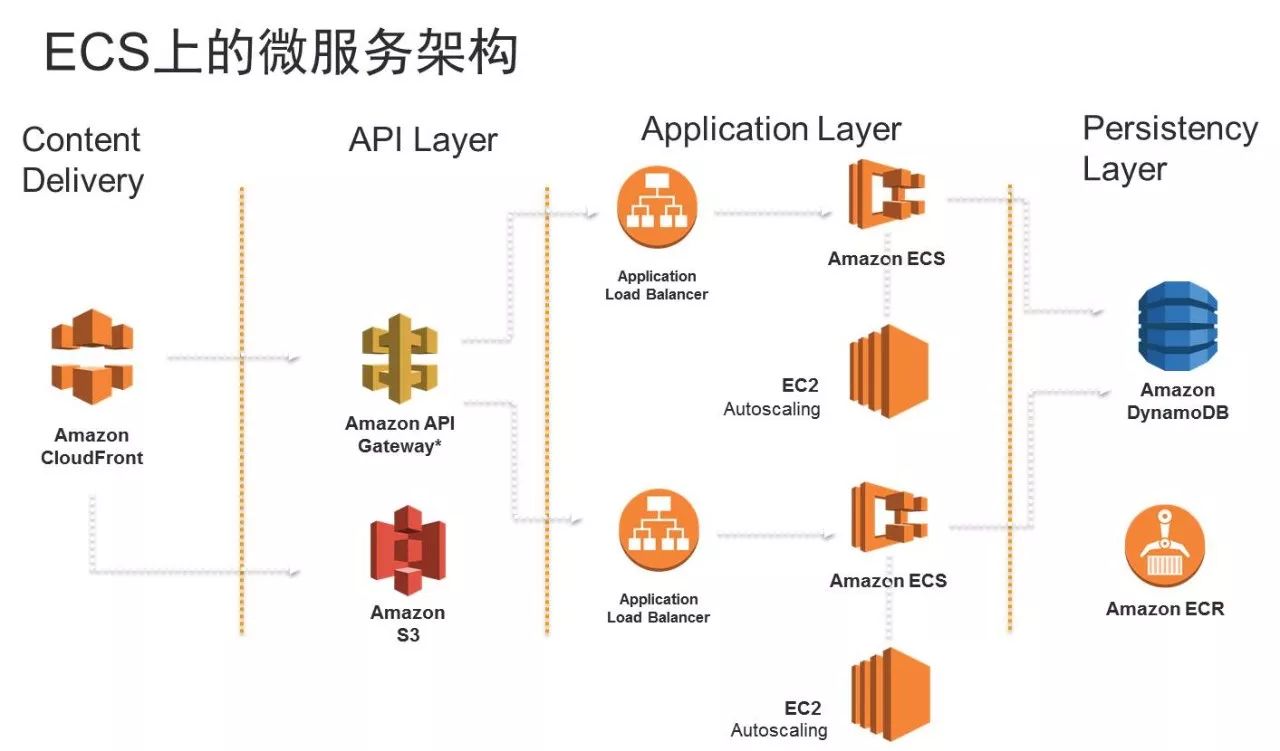
再举个例子来说,我们很多的手机厂商都会做这样的相册服务,会涉及到上传,我们可以使用Lambda的方式去做一个当S3上传后自动触发的一个动作,比如说这个相册可能做人脸检测,或者是变大小、变颜色,甚至是各种自动美颜优化,这个东西都可以自动触发地需做,我们放入开发人员可能只需要写的这部分的代码,实现里面的逻辑,中间的运维阶段可以完全把它屏蔽掉,这就是未来或者说现已实现的无服务器化的方向。
小结
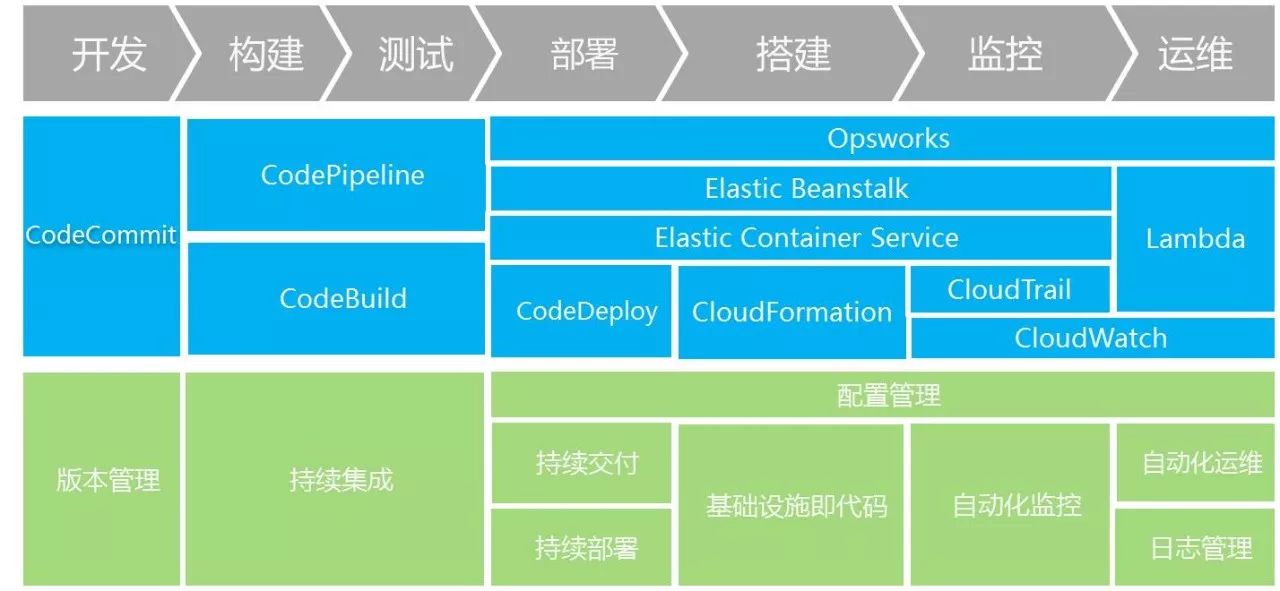
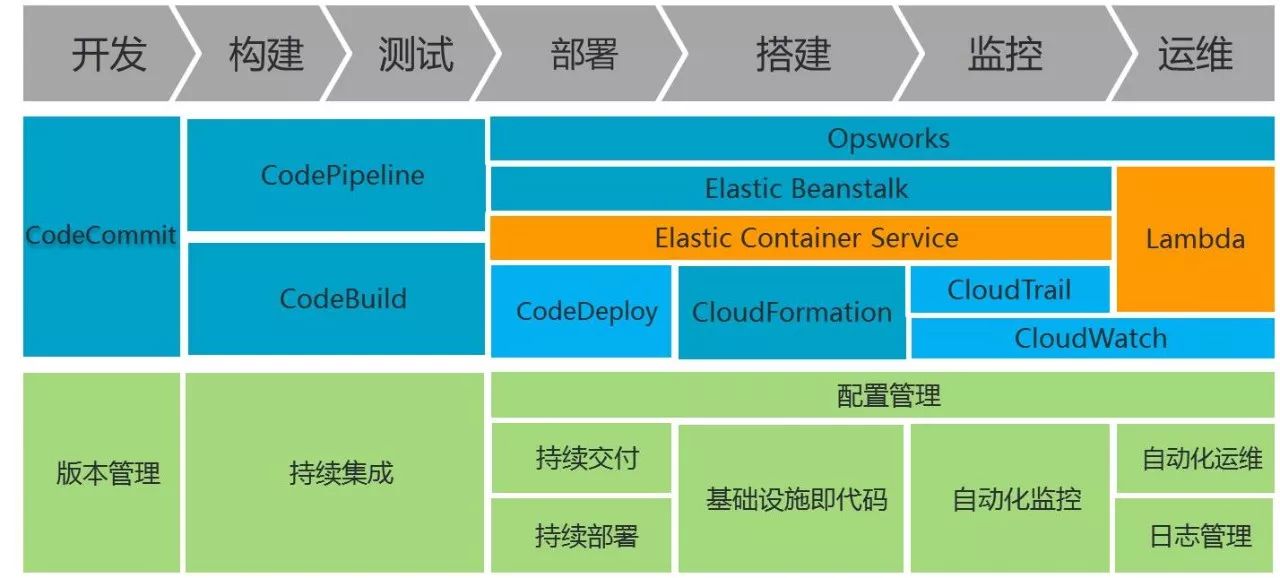
这就是今天介绍的整体的内容, AWS DevOps服务的总体框架其实包括了从开发、构建、部署,搭建、监控、运维的整个范围,所以在座的各位,可以很容易地注册到一个AWS的帐号,开始去试用这样的服务,在云端试用的成本是非常低的,包括您和您的团队,都可以去试用云端的这种方法。
而今天我介绍的这个服务,未必是马上可以适应你的团队,你们可以先把团队现有的一些经验往云端去搬迁,这种情况下云端最大的优势就是它的资源是弹性的,弹性会包括两个方面,第一个就是试错的成本会变得非常低,比如说现在有一些AI的团队需要一些很庞大的GPU资源,但购买这样的GPU资源非常贵,在云端可能只需要几块钱、十几块钱的成本,就可以用它一个小时,你可以把你的模型在上面跑,在DevOps的环境也是一样,我们马上就可以去测试云端的东西是否适合我,如果真的不适合,你付出的可能只是几块钱的成本,但如果适合,我们马上就可以把整个团队的敏捷性大大地提高,这个就是我们开发运维的DevOps的经验,这里面涉及到了整个公司文化、组织这方面的理念,AWS在DevOps上面的实践也非常多,欢迎大家一起探讨这方面的问题。我今天的分享就到这里,谢谢大家!
相关专题:
↓↓↓点这里下载本文干货PPT
以上是关于AWS DevOps实践:一年5000万次部署是怎样一种概念?的主要内容,如果未能解决你的问题,请参考以下文章
架构部署AWS MasterClass:DevOps with AWS Command Line Interface (CLI)