在 AWS EMR 上使用 Spark 访问关系数据库
Posted AWS 架构师之旅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在 AWS EMR 上使用 Spark 访问关系数据库相关的知识,希望对你有一定的参考价值。
最近看到一篇 Twilio 团队如何利用 Spark 将每天数成百上千万的 API 调用记录从 mysql 同步到数据湖,支持他们的用户可以导出历史调用记录的能力,如果他一个客户一天调用一百万次 Twilio 的 API,那么一年就有 3.65 亿次(条)调用日志,该团队最终采用了 Spark 以及它基于列值的并行查询特性来满足这样一个大数据处理的需求;
从架构实践来说,解决这样一个问题:使客户随时可以导出沉淀下来的 API 调用日志,原始日志保存在 MySQL 中;可以有哪些架构选择呢?
保留数据在 MySQL 中,按需从只读副本查询和导出数据; 比如 Amazon Athena 最新的联合查询,支持查询多种数据源,包括支持 JDBC接口的 MySQL,DynamoDB,HBase,Redshift,Redis等等;
定期同步 MySQL 数据到数据湖; 比如很多基于 Binlog 的 CDC(Change Data Capture )解决方案,AWS DMS,Canal/Debezium 等工具;还有就是基于数据的复制,比如利用 Spark 直接读取数据同时并行处理提升效率,或者类似 Sqoop 这样的开源工具;
本文从两个好奇点出发,第一如何利用 Spark 处理 JDBC 相关的操作,第二,Spark 的并行如何工作以及效率;基于 AWS 进行了一系列的动手实践:
构建一个 Spark 的运行环境,这里选择 托管的 AWS EMR 集群,非常成熟,可以快速起步,而且可以利用竞价实例控制实验成本
Spark 应用的开发调试环境,Jupyter Notebook 是一个不错的选择
Spark JDBC 相关代码开发和执行,观察分区并行执行的情况
- 1 -
Spark on Amazon EMR
由于实验中,我引入了竞价实例来降低实验成本,EMR 集群由于竞价资源池的动态市场供应特性,有可能会被中断,因此,第一时间,我需要更加自动化方式来管理集群创建和环境配置,这里我采用 AWS CLI 命令方式来创建一个包含 Spark 的 EMR 集群:
集群至少包含 Spark,Hadoop,Livy(支持 REST 提交 Spark 任务的一个组件)
在主节点上,自动下载安装 MySQL Connector Driver 供后续 Spark 访问 MySQL 数据库使用
集群包含三个节点,全部是竞价实例,比如使用 m5.8xlarge (32 vCPU,128GB内存)的竞价实例,N. Virginia 区域的每小时单价在0.55~0.59 美金之间,一天 8小时算,单节点实验集群的总成本在 4.72 美金左右
为了简化整个基础环境,实验的 EMR 集群我们会在默认的 VPC 的公有子网中进行创建,因为节点需要访问外网下载 MySQL 驱动,使用的角色也都是系统默认,首先,查询该区域默认 VPC 和 子网信息:
export vpcId=$(aws ec2 describe-vpcs --filters Name="isDefault",Values="true" | jq -r ".Vpcs[0] | .VpcId")
export subnetIds=$(aws ec2 describe-subnets --filters Name="vpc-id",Values=$vpcId | jq -r "[.Subnets [].SubnetId]")
export subnet4EMR=$(echo $subnetIds | jq '.[0]')
echo $subnet4EMR
然后开始创建 Spark 实验环境(AWS EMR 集群)为了简单,实验环境创建了一个单节点集群,在实际环境中不建议:
aws emr create-cluster --name "SparkDevOnEMR" --release-label emr-5.30.1 --use-default-roles --visible-to-all-users \
--applications Name=Spark Name=Hadoop Name=Livy \
--ec2-attributes SubnetIds=[$subnet4EMR] \
--bootstrap-actions Path="s3://elasticmapreduce/bootstrap-actions/run-if",Args=["instance.isMaster=true","wget -S -T 10 -t 5 https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-8.0.21.tar.gz && tar -xzf mysql-connector-java-8.0.21.tar.gz && sudo mkdir -p /usr/lib/spark/jars/ && sudo cp ./mysql-connector-java-8.0.21/mysql-connector-java-8.0.21.jar /usr/lib/spark/jars/"] \
--instance-groups InstanceGroupType=MASTER,InstanceType=m5.8xlarge,InstanceCount=1,BidPrice=OnDemandPrice
上面的 AWS CLI 脚本中,我们利用 bootstrap-actions 以及官方的 run-if 脚本,在主节点上,下载和配置 mysql 的驱动供后续 Spark 应用使用,整个创建和初始化过程需要 5~6 分钟;
- 2 -
Spark 开发测试环境
Jupyter Notebook 是大数据处理和机器学习领域被广泛使用的一个工具,环境的创建有多种选择,手工自行安装,直接使用 EMR 里面自带的 Jupyter Hub 应用等等,本文采用一个托管的免费的 Notebook 服务 Amazon ERM Notebooks,包含预定义的Spark 环境,支持 Spark magic kernels,允许用户在 EMR 集群上提交 Spark 任务,支持 PySpark/Spark SQL/Spark R/Scala等各种语言;还有一个好处是,Spark 的代码/文件自动保存在 Amazon S3 中,工作结果不怕丢失;
创建过程一非常简单,登陆 AWS 控制台,选择你 ERM 集群同样的区域比如 us-east-1,转到 Amazon EMR 页面,左侧菜单中你会看到 Notebooks 一栏:
很快就创建出一个 Spark 工作测试 Jupyter 环境,如下图所示,点击浏览器打开 Jupyter就可以开始 Spark 之旅了:
- 3 -
Spark 读取 MySQL
我们假设你已经创建一个 MySQL 实例,比如 Amazon RDS MySQL,访问的 URL 类似 jdbc:mysql://sampledb.xxx.us-east-1.rds.amazonaws.com:3306/ecommercedb,数据库的用户名和密码简化为 admin 和 12345678;
JDBC Spark 网上有很多教程,我们从最基础的开始:
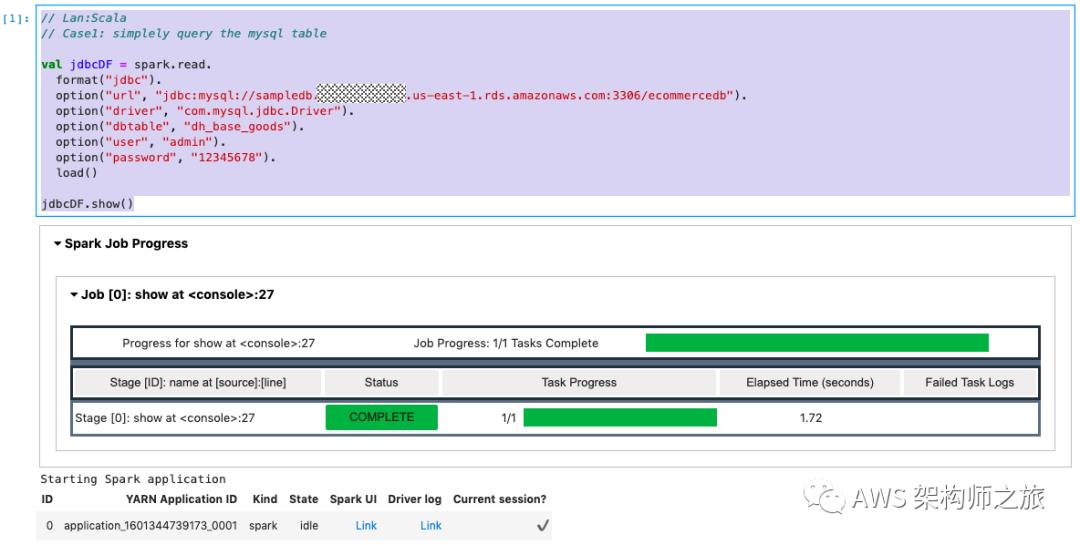
// Lan:Scala
// Case1: simplely query the mysql table
val jdbcDF = spark.read.
format("jdbc").
option("url", "jdbc:mysql://sampledb.xxx.us-east-1.rds.amazonaws.com:3306/ecommercedb").
option("driver", "com.mysql.jdbc.Driver").
option("dbtable", "dh_base_goods").
option("user", "admin").
option("password", "12345678").
load()
jdbcDF.show()
再进一步,优化和重用数据库链接参数,以及使用自定义的 SQL 语句:
/* Lan: Scala
* Case2: db config reuse using map object and query the table by specify sql
*/
var dbConfig = Map("url"->"jdbc:mysql://sampledb.xxx.us-east-1.rds.amazonaws.com:3306/ecommercedb",
"driver"->"com.mysql.jdbc.Driver",
"user"->"admin",
"password"->"12345678")
val jdbcDF2 = spark.read.
format("jdbc").
option("dbtable", "(select * from dh_base_goods) AS goods").
options(dbConfig).
load()
jdbcDF2.show()
对于大数据处理场景,并行处理对于效能非常重要,接下来我们重点体验下如何进行 JDBC Spark 的并行处理
- 4 -
JDBC Spark 并行读取 MySQL 的数据
Spark SQL 中可以利用分区概念,针对数据表的某个具体的数字型列计算 SQL 查询范围,自动构建多条 SQL 语句并行处理;
因此,Spark SQL 引入了 4个参数,分别是 partitionColumn,numberOfPartitions,lower and upper bounds 基于这四个参数,就可以计算出分区的步长stride = (upperBound-lowerBound/numberOfPartition), 假设 lowerBound = 0, upperBound = 9, numOfPartitions = 9 那步长就是 1:
SELECT * FROM my_table WHERE partition_column IS NULL OR partition_column < 1
SELECT * FROM my_table WHERE partition_column >= 1 AND partition_column < 2
SELECT * FROM my_table WHERE partition_column >= 2 AND partition_column < 3
SELECT * FROM my_table WHERE partition_column >= 4 AND partition_column < 5
SELECT * FROM my_table WHERE partition_column >= 6 AND partition_column < 7
SELECT * FROM my_table WHERE partition_column >= 7 AND partition_column < 8
SELECT * FROM my_table WHERE partition_column >= 8
需要强调的是, upperBound 和 lowerBound 仅仅用来计算步长,不会真正用来限制返回的表数据,也就是说如果不在 SQL 层面限制返回数据量,默认是返回表中所有的行
/* Lan: Scala
* Case3: Using Spark SQL partitions to parallel processing
*/
val lowerBound = 0
val upperBound = 9
val numberOfPartitions = 9
val jdbcDF3 = spark.read.
format("jdbc").
options(dbConfig).
option("numPartitions",numberOfPartitions).
option("partitionColumn","id").
option("lowerBound",lowerBound).
option("upperBound",upperBound).
option("dbtable", s"(select * from dh_base_goods LIMIT 9) AS goods").
load()
jdbcDF3.select("id").
foreachPartition(partitionRows => {
val shops = partitionRows.map(row => row.getAs[Int]("id")).toSet
assert(shops.size == 0 || shops.size == 9)
})
样例3 中,我们定义了步长为 1 的分区策略,对应到开头提到的 SQL 语句分片算法,Spark 会分成 9个 SQL 语句并行执行,而由于本实验中分区列的最小值是6940,而 lowerBound 设置成 0 , 并且原始 SQL 通过 LIMIT 限制了返回最大条目数量为 9,因此前面 8个SQL语句都没有结果返回,最后一句的条件是 id >=8 返回了所有的 9条数据;而 assert 语句执行也符合我们的判断。
/* Lan: Scala
* Case4: Using Spark SQL partitions to parallel processing
* 步长为 2,链接数控制在 5 (number of partitions)
*/
val lowerBound = 6940 // 数据表里面,id 的最小值就是 6940
val upperBound = 6950
val numberOfPartitions = 5
val jdbcDF4 = spark.read.
format("jdbc").
options(dbConfig).
option("numPartitions",numberOfPartitions).
option("partitionColumn","id").
option("lowerBound",lowerBound).
option("upperBound",upperBound).
option("dbtable", s"(select * from dh_base_goods) AS goods").
load()
jdbcDF4.select("id").
foreachPartition(partitionRows => {
val shops = partitionRows.map(row => row.getAs[Int]("id")).toSet
assert(shops.size == 2 || shops.size > 2)
})
jdbcDF4.write.
format("json").
mode("append").
save("s3://jxlabs/spark/p20/")
样例4,我们修改了分区参数,并且去掉了 SQL 查询中的 LIMIT 限制,因此 DataFrame 会返回该表中所有数据,5个分区 SQL 查询,前面4个 SQL 每个可以返回 2 条数据,最后一个分区 SQL 查询会返回剩下的所有数据;最后一段我们也演示了如何将数据写到数据湖 Amazon S3中的方法;
- 5 -
总结
Spark 在客户侧使用的场景越来越广泛,而数据库的数据处理是其中非常基本和常见的,本文总结和实践了如何在 Amazon EMR 上玩转 Spark 的开发和测试,作为学习 Spark 编程的一个起步 (Hello Spark)!
参考资料
How to export millions of records from Mysql to AWS S3?
申明
本站点所有文章,仅代表个人想法,不代表任何公司立场,所有数据都来自公开资料,转载请注明出处
以上是关于在 AWS EMR 上使用 Spark 访问关系数据库的主要内容,如果未能解决你的问题,请参考以下文章
在 AWS EMR 上设置 Spark Thrift 服务器以建立 JBDC/ODBC 连接
我的 spark 作业在 aws EMR 集群上长时间处于接受模式