探索如何更可靠地运行Kubernetes
Posted 分布式实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了探索如何更可靠地运行Kubernetes相关的知识,希望对你有一定的参考价值。
我们最近在Kubernetes之上开发了一个分布式cron[1]作业调度系统。Kubernetes目前非常流行,是一个非常棒的容器编排平台,而且有很多新功能,其中一个就是工程师们不需要知道应用运行在哪台虚机上。
分布式系统其实很复杂,而管理分布式系统则是运维团队面临的更复杂问题。在生产环境中引入新软件并学会如何可靠使用是很严肃的问题。例如:为什么学会操作Kubernetes很重要就是一个例子,有一个由Kubernetes bug引起一个小时系统瘫痪问题的事后总结。

Kubernetes是在集群内调度应用的分布式系统。如果通知Kubernetes运行某个应用的五个实例,Kubernetes则会动态在工作节点上调度起它们。通过自动化调度容器可以增加硬件设备的利用率并且节省费用,强大部署能力使得开发者可以细粒度更新代码,安全上下文和网络策略则使得多租户工作流更加安全运行。
每个项目都会从一个业务需求开始。我们的目的是提高已有的基于cron作业系统的可靠性和安全性。需求如下:
需要由小团队运维(本项目只有两个全职员工)。
需要在20台设备内调度大约500个不同作业。
我们选择Kubernetes作为基础的原因是:
希望采用开源系统
Kubernetes有一套内置分布式cron作业调度器,我们不需要重新写一个
Kubernetes很活跃,并且乐于接受代码贡献
Kubernetes用Go开发(比较易于学习)。几乎所有bug修复都是有我们团队不专业的Go开发者提交的
如果我们可以顺利操作Kubernetes,我们未来就可以在其上开发(例如,我们现在在Kubernetes之上训练机器学习模型)。
以前我们使用Chronos作为cron作业调度系统,但是目前不能满足我们的需求,而且不可维护(活跃度很低)因此我们决定不再采用它。
我们有三种主要目标:
99.99%的cron工作需要在被调度后20分钟之内运行,20分钟是很宽的窗口,但是客户并没有更精确的需求。
作业应该占据99.99%的调度时间片(不被干扰)
迁移到Kubernetes不应引起任何客户端问题
这意味着:
Kubernetes API短期故障时可以容忍的(如果出现十分钟的故障,只要五分钟之内恢复就是可以容忍的)。
调度bugs(当一个cron作业无法运行)是不可接受的。这是一个很严重的问题。
需要关注Pod退出和安全停止方式,以便作业不会频繁被终止。 因此我们需要一个细致的迁移方案。
创建第一个Kubernetes集群最基本方法就是从零开始而不是使用例如kubeadm或者kops之类的工具。我们通过Puppet提供配置,这是一个常用的配置管理工具。从零建立有两个原因:能够深度整合Kubernetes到既有架构,并且深入理解其内部机制。
从零开始可以帮助我们更好将Kubernetes整合到现存架构。我们想无缝地整合到日志、认证管理、网络安全、监控、AWS实例管理、部署、数据库代理、内部DNS服务、配置管理等系统中,看起来需要不少精力,但是整体上看比尝试使用kubeadm/kops这些工具来实现目标要容易一些。
因为我们对这些现有系统已经很熟悉了,希望继续在Kubernetes集群中使用它们。例如,安全认证管理一般是一个难点,总是会有这样那样的问题。我们不应该因为采用了Kubernetes而尝试采用一种全新的CA系统。
刚开始Kubernetes集成时,团队里没有人用过,如何才能从“小白”到“高手”呢?
策略0:与其他公司用户沟通
我们经常会与其他使用过Kubernetes的公司讨论,他们也都会在不同场合下使用Kubernetes(在物理机、或者Google Kubernetes Engine上运行HTTP服务,等等)。与这些有着实际经验的,运行大型或者复杂系统的公司沟通后,才会认识到自己使用场景的关键点,建立自己的经验,建立使用的信心,最终做决定。不能只是因为读了这篇博客就认为“好吧,Stirpe成功使用了Kubernetes,因此对我们应该也适用”。
以下是我们跟一些采用Kubernetes集群架构的公司沟通后学到的经验:
重点工作要放在etcd集群可靠性上(etcd是存储所有Kubernetes集群状态的地方)。
某些Kubernetes功能并不很完善,因此使用alpha版本功能时要很小心。有些公司会以慢一个或几个发行版的方式来采用稳定版本的功能。
假设使用hosted Kubernetes系统,例如GKE/AKS/EKS项目,从零开始配置一个高可用Kubernetes集群有大量工作要做,对于这些项目AWS目前还没有一个成熟Kubernetes服务,因此并不适合我们。
另外还需要非常当心overley网络、软件定义网络带来的延迟。
当然与其他公司的沟通并不能解决我们自己的问题,但是会给我们更多的启发,并去关注重要的事情。
策略1:读代码
我们会依赖Kubernetes的cronjob控制器组件,它目前还是alpha状态,使得我们很担心,尽管在测试系统上使用了,但是如何能够保证在生产上不出问题呢?
幸亏cronjob控制器的代买只有区区400行Go语言代码,可以快速读完代码,并且可以看出:
cronjob控制器是一个无状态服务(和其它非etcd组件类似)
每十秒钟,控制器调用syncAll服务:go wait.Until(jm.syncAll, 10*time.Second, stopCh)
syncAll服务从Kubernetes API中获取所有cronjobs,检索列表,决定下一个运行那个作业,并启动它。
核心逻辑很简单,但是最重要的是我们觉得,如果有什么bug,我们应该能够修复。
策略2:压力测试
开始创建集群前,我们做了不少压力测试。我们并不担心Kubernetes集群能够处理多少节点(我们计划部署大约20个节点),但是我们很关注Kubernetes能处理多少cron作业(我们计划至少每分钟50个)。
我们在三节点集群上测试,创建了1000个每分钟运行一次的cron作业。这些作业简单运行bash -c 'echo hello world',只是为了测试集群调度和编排能力,而不是测试计算资源消耗。
策略3:重点在高可用etcd集群
运行Kubernetes集群最重要的事情还是运行etcd。etcd是Kubernetes集群心脏,所有集群相关数据都存放在这里,除了etcd之外的都是无状态量。如果etcd失效,尽管服务还在运行,但是无法对Kubernetes集群修改。
下图展示的是etcd如何作为核心部件起效的:API服务器作为在etcd前端,提供无状态、认证服务,其他组件都通过API服务器跟etcd沟通。
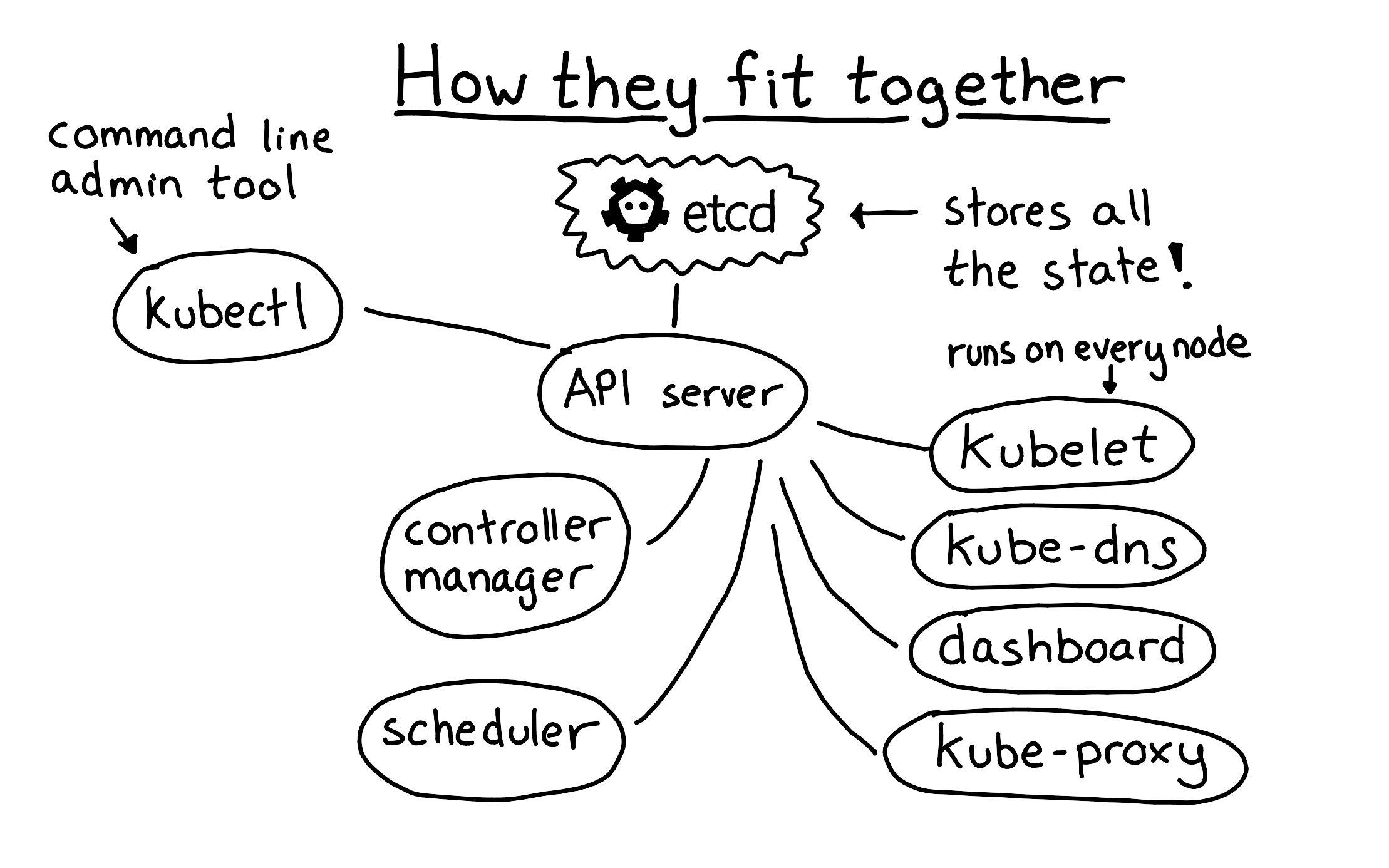
运行时,有两个重要的观念:
为了避免集群节点故障,必须配置副本replication。目前我们有三个副本。
确保有足够IO带宽。我们使用的etcd版本有个问题,当某个节点因为fsync造成延迟时会触发持续的选举,造成集群不稳定。通过确保每个节点有足够的IO带宽(比etcd些操作要多)解决了这个问题
设置副本并不是一个一蹴而就的事情,我们通过仔细调整此参数最终实现丢失一个节点,集群可以很稳健地恢复。
以下是我们对etcd所做的操作:
设置副本
监控etcd服务是否有效
写一个简单工具可以很容易激活新etcd节点,并将它们加入集群
改写etcd使得一个生产系统可以有多套etcd集群运行
测试从etcd备份中恢复
测试0时间重建集群
很高兴我们在早期就做了这些测试。某个周五早上,某套生产系统的一个etcd节点停止服务,我们收到预警,停止了此节点,启动了新节点,加入集群,k8s并没因为这个故障影响服务。非常棒!!
迁移过程中需要避免出现服务停止。迁移成功的秘诀不是如何避免犯错,而是如何设计迁移策略减少错误带来的影响。
幸运的是我们有很多作业要迁移到新集群上,因此可以先从低优先级的作业开始,一般它们出现一到两个错误是可以接受的。
以下是我们所采用的迁移策略:
对优先级进行设置
将某些作业重复地迁移到Kubernetes,如果发现问题,就回滚,修复问题,再次尝试。
项目开始前我们制定了一些准则,如果Kubernetes发现异常,需要查明原因,然后修正问题。
查找原因非常消耗时间但是很值得。如果只是绕过Kubernetes系统带来的问题,对未来采用更大规模集群只能是心怀恐惧。
采用此策略后,我们发现了Kubernetes中一些bug(我们能够修复)。
作业名长于52个字符的Cronjobs自动失败
挂起状态的Pod有时候会彻底阻塞
调度器每三个小时会崩坍一次
Flanel维护的hostgw后端并不覆盖过期的路由表
修复这些bugs使得我们对Kubernetes项目更加有信心,不只是解决了问题,而且还因为它们接受了我们的补丁以及有一套很好的跟踪修复流程。
跟其他软件一样,Kubernetes肯定有各种bugs。特别地,我们严重依赖调度器(因为我们的cron作业会经常创建新Pod),调度器使用的缓存会经常出现bugs,回退或者崩坍。缓存是个难点,但是因为可以访问源码,因此我们可以自己处理这些问题。
另外一个值得讨论的问题是Kubernetes Pod采用的eviction迁移逻辑。Kubernetes有一个模块叫节点控制器,负责当某个节点失效时将其上运行的Pods迁移到其它节点上。有可能所有节点暂时无响应(例如,因为网络或者配置问题),此时Kubernetes会将集群内所有Pods都终止。我们测试早期就发现了这个问题。
如果运行大规模集群,就要仔细阅读节点控制器文档[4],考虑配置,压力测试。每次当修改这些配置(例如--pod-eviction-timeout),进行测试时,总是有惊讶的事情发生。所以尽早在测试环境中发现问题总比在凌晨三点生产系统出问题好。
策略6:故意引入Kubernetes集群问题进行演练
在Stripe会经常举行演练“game day excises[5]”,现在仍然再继续。这个想法是设想一个未来会发生的场景(例如,Kubernetes API服务器失效了),故意在生产系统中造成这种问题,确保能够处理这种问题。
我们经常做的演练包括:
终止某个Kubernetes API服务器
终止所有API服务器,再恢复它们
终止etcd节点
从API服务器端中断与工作节点的通讯,此节点上所有Pod被迁移到其它节点上去
很高兴看到Kubernetes能够很好处理这些问题,Kubernetes设计思路就是对错误提供弹性,有一个etcd集群存储所有状态,一个API服务器提供简单REST接口访问数据库,以及一系列无状态控制器协调整个集群运行。
如果某个组件出问题,重启后会从etcd中读取状态,然后继续无缝运行。这是一套经验证没问题的工作机制。
我们在测试中发现了一些问题:
真奇怪,这里居然没有通知我。需要看看监控哪里出了问题
当我们重启API服务器时,需要人工干预,需要解决这个问题
有时候做etcd切换时,API服务器会出现超时错,除非重启
通过这些实验,我们解决了这些发现的问题:提高了监控能力,修复了配置上的问题,记录了Kubernetes中的bugs。
总结一下如何做到这点:
name: job-name-here
kubernetes:
schedule: '15 */2 * * *'
command:
- ruby
- "/path/to/script.rb"
resources:
requests:
cpu: 0.1
memory: 128M
limits:
memory: 1024M
我们并没有太多创新,只是写了一个简单的程序将格式转化成Kubernetes cron作业的配置文件,kubectl可以调用它而已。
我们也写了测试包确保作业名不会太长(不能超过52个字符),以及作业名是唯一的。我们现在不用cgroups强制内存限制,但是未来可能会尝试它。
这个简单的格式易于使用,因为在Chronos和Kubernetes之间采用同样的定义格式,在他们之间切换非常方便。这也是一个成功的地方。当Kubernetes中出现问题,可以很快使用简单命令修改并生效。
监控Kubernetes内部状态是很成功的尝试。我们使用kube-state-metrics包监控,使用一个很轻的Go程序叫做veneur-prometheus从Prometheus中抓取数据,发布到我们自己监控系统中。
例如,下图是集群中上一个小时挂起的Pods示意图。挂起意味着等待被调度到某个工作节点上运行。可以看到在11am时有个峰值,因为很多cron作业都是在这个时间运行的。
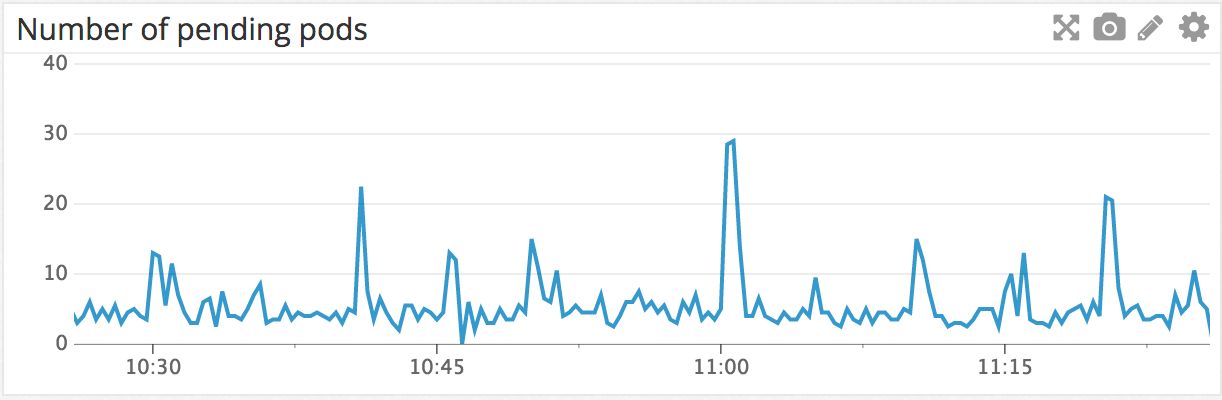
我们也有一个监控工具检查是否有Pod会在挂起状态卡死,我们会每五分钟检查一次启动的Pod是否已经在节点上运行,如果有卡死的情况则发出警告。
从决定采用Kubernetes,到我们建立了满意的生产系统,并将所有cron作业都移到新系统上花费了三个工程师五个月的时间,我们还期望Kubernetes能够在Stripe内部更多地方派上用场。
以下是我们总结出来的Kubernetes使用宝典:
定义清晰的Kubernetes项目业务原因,理解业务会使得项目进展更加容易
缩小项目规模。我们会避免使用很多Kubernetes功能,简化集群。这使得我们进度更快。
花更多的时间在如何更好运转Kubernetes集群。
如果能够遵守这些准则,则可以更加自信在生产中使用Kubernetes。我们会持续使用Kubernetes技术。例如,我们会关注AWS的EKS。我们正在完成一个机器学习模型,希望将HTTP服务部分转换到Kubernetes上来。随着我们更多在生产中使用Kubernetes,期望以这种方式更多反馈到开源项目中来。
相关链接:
https://en.wikipedia.org/wiki/Cron
https://www.youtube.com/watch?v=HlAXp0-M6SY
https://vimeo.com/173610242
https://kubernetes.io/docs/concepts/architecture/nodes/#node-controller
https://stripe.com/blog/game-day-exercises-at-stripe
原文链接:https://stripe.com/blog/operating-kubernetes
以上是关于探索如何更可靠地运行Kubernetes的主要内容,如果未能解决你的问题,请参考以下文章
原生Kubernetes容器云平台应用部署WordPress