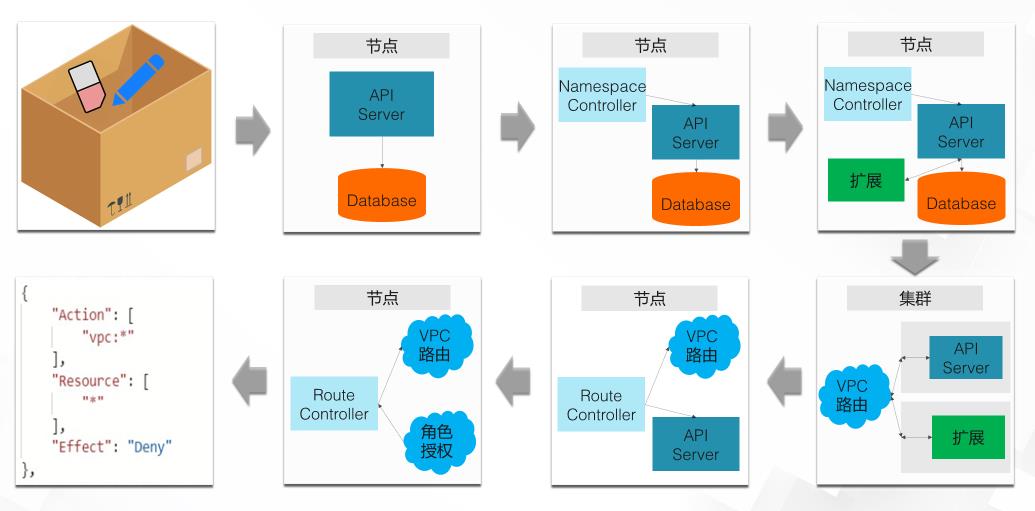
第二个例子,我们来看一个真实问题的排查过程。这个问题是一个命名空间不能被删除的问题。问题稍微有点复杂,我们一步一步来看。 命名空间是 Kubernetes 集群的 一个收纳盒机制,就像这里的第一张图片一样。这个盒子就是命名空间,它里边收纳了橡皮和铅笔。 命名空间可以被创建或者删除。我们经常会遇到不能删除命名空间的问题。遇到这个问题,我们如果完全不知道怎么排查。第一步我们可能会想到,研究一下 API Server 是怎么处理这个删除操作的,因为 API Server 就是集群的 管理入口。 API Server 本身是一个应用,我们可以通过提升这个应用的日志级别,来深入理解它的操作流程。在这个问题里,我们会发现,API Server 收到删除命令,但是就没有其他信息了。 这里我们需要稍微理解下命名空间的删除过程,用户在删除命名空间的时候,其实命名空间并不会被直接删除掉,而会被改成“删除中”的状态。这个时候命名空间控制器就会看到这个状态。 为了理解命名空间控制器的行为,我们同样可以把控制器的日志级别提高来查看详细的日志。这个时候呢,我们会发现,控制器正在尝试去获取所有的 API 分组。 到这里我们需要去理解两个事情。一个是为什么删除命名空间,控制器会去获取 API 分组。第二个是 API 分组到底是什么。 我们先看第二个问题,API 分组到底是什么。简单来说,API 分组就是集群 API 的分类机制,比如网络相关的 API 就在 networking 这个组里。而通过网络 API 分组创建出来的资源就属于这个组。 那为什么命名空间控制器会去获取 API 分组呢?是因为在删除命名空间的时候,控制器需要删除命名空间里的所有资源。这个操作不像我们删除文件夹一样,会把里边的文件都一起删掉。 命名空间收纳了资源,实际上是这些资源用类似索引的机制,指向了这个命名空间。集群只有遍历所有的 API 分组,找出指向这个命名空间的所有资源,才能逐个把它们删除掉。 而遍历 API 组这个操作呢,会使得集群的 API Server 和它的扩展进行通信。这是因为 API Server 的扩展,也可以实现一部分 API 分组。所以想知道被删除的命名空间里是不是有包括这个扩展定义的资源,API Server 就必须和扩展通信。 到这一步之后,问题实际上变成 API Server 和他的扩展之间通信的问题。也就是删除资源的问题就变成了网络问题。 阿里云的 Kubernetes 集群,是在 VPC 网络,也就是虚拟局域网上创建的。默认情况下, VPC 的只认识 VPC 网段的地址,而集群里边的容器,一般会使用和 VPC 不同的网段。比如 VPC 使用 172 网段,那容器可能就使用 192 网段。 我们通过在 VPC 的路由表里,增加容器网段的路由项,可以让容器使用 VPC 网络进行通信。 在右下角这张图,我们有两个集群节点,他们的地址是 172 网段,那我们给路由表里增加 192 网段的路由项,就可以让 VPC 把发给容器的数据转发到正确的节点上,再由节点发给具体的容器。 而这里的路由项,是在节点加入集群的时候,由路由控制器来添加的。路由控制器在发现有新节点加入集群之后,会立刻做出反应,给路由表里增加一条路由项。 添加路由项这个操作,其实是对 VPC 的一次操作。这个操作是需要使用一定的授权的,这是因为这个操作跟线下一台机器访问云上资源是差不多的,肯定需要授权。 这里路由控制器使用的授权,是以 RAM 角色的方式绑定到路由控制器所在的集群节点上的。而这个 RAM 角色,正常会有一系列的授权规则。 最后,我们通过检查,发现用户修改了授权规则,所以导致了这个问题。

 福利来了
福利来了 

