如何用 Kubernetes 管理超过 2500 个节点的集群
Posted K8sMeetup
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何用 Kubernetes 管理超过 2500 个节点的集群相关的知识,希望对你有一定的参考价值。
| 为 | 容 | 器 | 技 | 术 | 而 | 生 |
翻译:夏天
校对:郭维
两年来,我们一直在使用 Kubernetes 进行深度学习方面的研究。虽然我们大量的 workloads 可以直接运行在云虚拟机上,但是因为 Kubernetes 目前仍在快速迭代,而且拥有比较好的扩展性,也没有过多的约束,因此 Kubernetes 成为了我们最理想的集群管理工具。目前,我们已经有好几个正在运行的 Kubernetes 集群了(有些运行在云虚拟机上,有些则直接运行在物理机上)。其中最大的一个集群运行在 Azure 上,由 D15v2 和 NC24 两种类型的虚拟机组成,目前已经超过 2500 个节点。
在达到 2500 节点规模的过程中,许多的系统组件都出现了问题,包括 etcd,Kube Master,Docker 拉取镜像,网络,Kube DNS,机器上的 ARP 缓存。接下来将分享我们所遇到的问题和解决方案,希望对大家有所帮助。
etcd
在集群中添加了超过 500 个节点的时候,我们的研究人员发现使用 kubectl 操作集群的时候会发生超时的情况。于是我们尝试添加更多的 Kube Master 节点(运行 kube-apiserver 的节点)。这样做临时解决了这个问题,但当我们添加了 10 个 Master 节点后,我们发现这只是在表面上解决问题,并没有找到这个问题的根本原因(作为对比,GKE 只使用了一台 32 核的虚拟机作为 Master 就能管理 500 个节点。
etcd 存储了 Kubernetes 集群的所有状态数据,因此我们强烈怀疑是 etcd 集群出现了问题。通过查看 Datadog,我们发现虽然我们的每台机器都使用了支持 5000 IOPS 的 P30 SSD,但是运行了 etcd 的 DS15v2 虚拟机的写延迟在某些时间段猛增至数百毫秒。
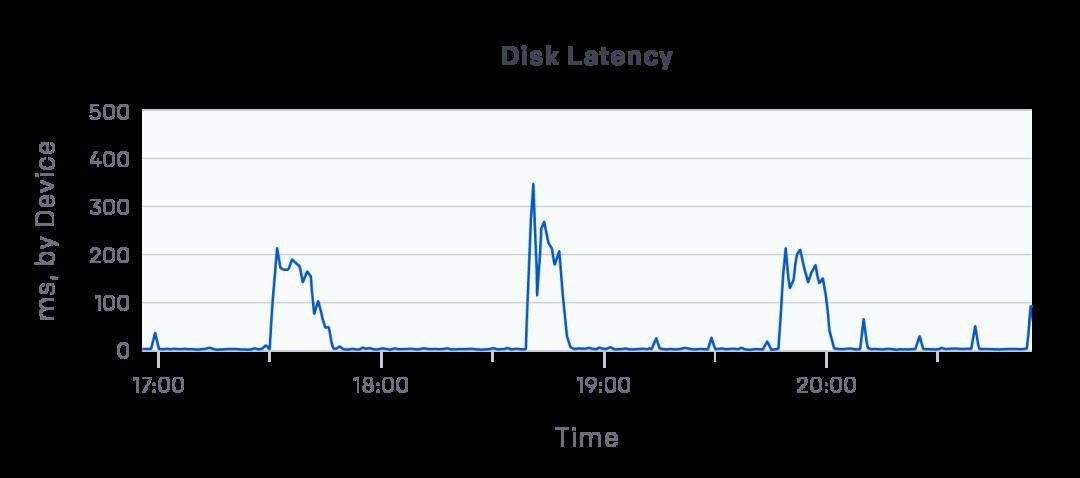
这么高的写延迟阻塞了整个集群!
在使用 fio 进行性能测试之后,我们发现 etcd 的 I/O 性能只能达到 I/O 上限的 10% 左右 。这主要是因为单次写延迟为 2ms,而 etcd 又使用了串行 I/O,导致 I/O 之间的延迟叠加(latency-bound)。
然后,我们将每个节点上的 etcd 的目录从网络磁盘移到本地 SSD 磁盘上。移动之后,写延迟降低到了 200 微秒,etcd 终于正常了。
我们的集群一直运行良好,直到我们增加到了 1000 个节点。这个时候我们再次发现 etcd 出现了很高的延迟。这一次,我们注意到 kube-apiservers 从 etcd 读取数据的速度超过了 500MB/s。我们搭建了 Prometheus 用于监控 kube-apiservers,还设置了 --audit-log-path 和 --audit-log-maxbackup 选项来保存更多的日志数据。通过日志,我们发现了许多慢查询请求和大量的对 Events 的 List API 的请求。
我们找到了问题的根本原因,我们发现部分程序会频繁去 kube-apiservers 查询各种信息(比如 Fluentd 和 Datdog 会去 kube-apiservers 查询每个节点信息)。我们修改了这些程序的设置,降低它们对 kube-apiservers 的查询频率,然后 kube-apiservers 的负载就降下来了:
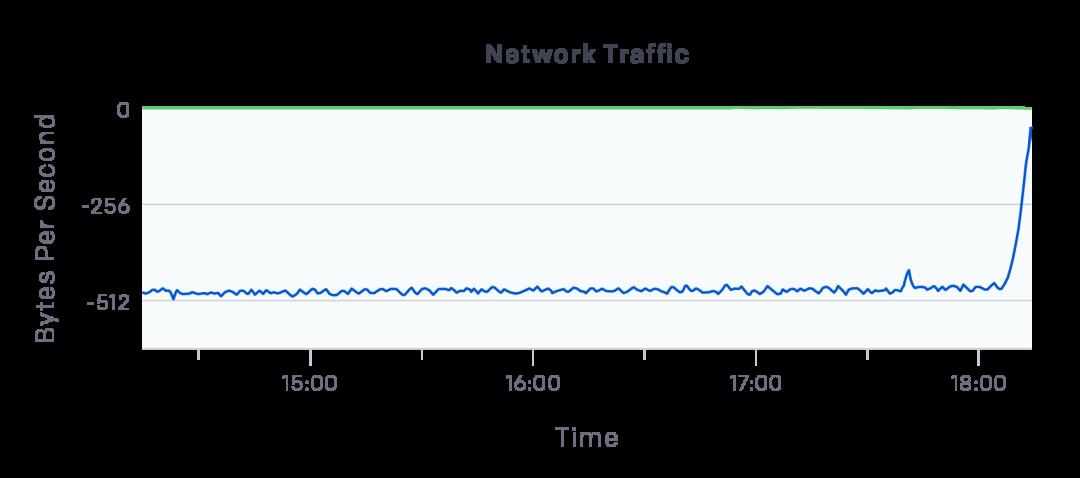
etcd 的出口速度从 500MB/s 左右降低到了接近 0MB/s(上图中负值表示出口速度)
另一个有效的改动是把 Kubernetes Events 存储在一个单独的 etcd 集群里,这样对 Events 的操作就不会影响到主 etcd 集群的正常工作。要想能做到这一点,我们只需要将这 --etcd-servers-overrides 设置为

另一个超过 1000 节点后的故障是触发了 etcd 的硬盘存储上限(默认是 2GB),于是 etcd 不再接受写请求。这直接导致了一连串的问题:所有 kube node 的健康检查都失败了,我们的 autoscaler 决定删除所有的 workers。于是我们通过 etcd 的 --quota-backend-bytes 增大了存储大小。另外还让 autoscaler 支持基础(sanity)检查,在发现要终止集群里超过 50% 的 workers 的时候,放弃这个操作。
Kube Master
我们在同一台机器上安装了 kube-apiserver,kube-controller-manager 和 kube-scheduler processes。为了高可用,我们一直有至少两个 masters,并将 --apiserver-count 设置为我们正在运行的 apiservers 数量(否则 Prometheus 可能会混淆这些实例)。
我们主要使用 Kubernetes 作为批量调度系统,并依靠 autoscaler 动态地伸缩我们的集群。这使我们可以显著地降低空闲节点的成本,在快速迭代的同时提供低延迟。默认的 kube-scheduler 策略是将负载均匀分散在节点之间,但这与我们的期望相悖,我们希望可以终止未使用的节点,同时也可以快速调度大的 pod。所以我们切换到下面的策略:

我们使用 KubeDNS 实现服务发现,但是在我们使用新的调度策略后,很快它就出现了一些可靠性问题。我们发现故障只在 KubeDNS 的 Pods 中出现。在新的调度规则影响下,有些机器上运行了十多个 KubeDNS 实例,这就导致了这些机器成为了热点,它们收到的 DNS 查询超过了 200 QPS(这是 Azure 虚拟机对 DNS 查询的上限值)。
Docker 拉取镜像
我们的 Dota 项目刚开始运行在 Kubernetes 上的时候,一旦它开始扩容,我们就注意到一些新的节点上有很多 Pods 处于 Pending 状态,而且持续很长时间。Dota 的镜像大小为 17GB,把这个镜像拉取到一个新的节点上需要大约 30 分钟的时间。因此我们知道了 Dota 的 Pod 处于 Pending 的原因,但是同一个节点上的其他比较小的 Pod 也出现了相同的情况。
随着调查的深入,我们发现 kubelet 的 --serialize-image-pulls 默认为 true,这意味着拉取 Dota 镜像的时候,其他镜像的拉取都会被阻塞住。把这个选项修改为 false 需要让 Docker 使用 overlay2 文件系统而不是 AUFS。为了加快拉取速度,我们把 Docker 的根存储目录迁移到了机器的本地 SSD 上,就像 etcd 那样。
在优化了拉取速度之后,我们仍然发现 Pods 出现了奇怪的错误:error message: rpc error: code = 2 desc = net/http: request canceled。由于进度不足,Kubelet 和 Docker 的日志里也指出了镜像拉取被取消了。我们究其根源,发现当有很多积压的镜像拉取任务,或者有些大镜像花费很长的时间都没有完成拉取和解压工作的时候,就会出现这种错误。为了解决这个问题,我们将 Kubelet 的 --image-pull-progress-deadline 设置为 30 分钟, 并且设置了 Docker 的 max-concurrent-downloads 为 10。(第二个选项不会加速大镜像的解压工作,但是可以让拉取镜像的工作并行执行 。)
我们最后的 Docker 镜像拉取问题源自 Google Container Registry。默认情况下, Kubelet 会自动从 gcr.io 拉取一个特殊的镜像(可由 --pod-infra-container-image 控制),这个镜像用于启动新的容器。如果拉取失败,这个节点就不能启动任何 Pod 。由于我们的节点没有公网 IP,只能通过 NAT 访问 gcr.io,一旦超过了单个 IP 的配额上限,就会拉取失败。为了解决这个问题,我们通过预加载镜像直接将镜像部署到机器上。通过 docker image save -o /opt/preloaded_docker_images.tar 和 docker image load -i /opt/preloaded_docker_images.tar 完成这个工作。为了提升性能,我们对其他公共镜像比如 OpenAI-internal 和 Dota 镜像也做了相同的事情。
联网
随着我们的实验越来越大,我们的系统也逐渐变成了重度依赖网络的复杂的分布式系统。当我们第一次开始分布式实验的时候,立即就发现了我们的网络不是很好。机器之间的吞吐量大约在 10-15Gbit/s, 但是我们基于 Flannel 的 Pods 之间的最大吞吐量仅仅只有 2Gbit/s。
Machine Zone 的公开性能测试也显示了类似的结果,这意味着这个问题未必是由配置不好导致的,很有可能是我们的环境中隐藏了一些问题(机器上的 Flannel 应该不会增加这么大的开销)。
为了解决这个问题,用户可以使用两个不同的设置来让 Pods 绕过 Flannel 的网络:hostNetwork 设置为 true,dnsPolicy 设置为 ClusterFirstWithHostNet(在做这件事情之前请先阅读 Kubernetes 中的警告)。
ARP 缓存
这个修改在 HPC 集群中非常常见,而此时在 Kubernetes 中这个选项也非常重要,因为每个 Pod 都有自己的 IP,而每个 IP 都需要占用 ARP 缓存空间。
参考文献:
https://blog.openai.com/scaling-kubernetes-to-2500-nodes/?utm_source=digg
推荐阅读:
END
线上课堂
1 月 31 日的 K8sMeetup 中国社区【线上课堂】开始报名!
时间:2018 年 1 月 31 日 20:00
话题:《容器集群性能优化之路》
讲师:华为 CloudBU 资深工程师 钟成
以上是关于如何用 Kubernetes 管理超过 2500 个节点的集群的主要内容,如果未能解决你的问题,请参考以下文章
2.5T及以上的硬盘如何使用如何用parted创建分区安装CentOS7