一文搞懂负载均衡中的一致性哈希算法
Posted 占小狼的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文搞懂负载均衡中的一致性哈希算法相关的知识,希望对你有一定的参考价值。
一致性哈希算法在很多领域有应用,例如分布式缓存领域的 MemCache,Redis,负载均衡领域的 nginx,各类 RPC 框架。不同领域场景不同,需要顾及的因素也有所差异,本文主要讨论在负载均衡中一致性哈希算法的设计。
友情提示:阅读本文前,最好对一致性哈希算法有所了解,例如你最好听过一致性哈希环这个概念,我会在基本概念上缩短篇幅。
一致性哈希负载均衡介绍
负载均衡这个概念可以抽象为:从 n 个候选服务器中选择一个进行通信的过程。负载均衡算法有多种多样的实现方式:随机、轮询、最小负载优先等,其中也包括了今天的主角:一致性哈希负载均衡。一致性哈希负载均衡需要保证的是“相同的请求尽可能落到同一个服务器上”,注意这短短的一句描述,却包含了相当大的信息量。“相同的请求” — 什么是相同的请求?一般在使用一致性哈希负载均衡时,需要指定一个 key 用于 hash 计算,可能是:
请求方 IP
请求服务名称,参数列表构成的串
用户 ID
“尽可能” —为什么不是一定?因为服务器可能发生上下线,所以少数服务器的变化不应该影响大多数的请求。这也呼应了算法名称中的“一致性”。
同时,一个优秀的负载均衡算法还有一个隐性要求:流量尽可能均匀分布。
综上所述,我们可以概括出一致性哈希负载均衡算法的设计思路。
尽可能保证每个服务器节点均匀的分摊流量
尽可能保证服务器节点的上下线不影响流量的变更
哈希算法介绍
哈希算法是一致性哈希算法中重要的一个组成部分,你可以借助 Java 中的 inthashCode()去理解它。 说到哈希算法,你想到了什么?Jdk 中的 hashCode、SHA-1、MD5,除了这些耳熟能详的哈希算法,还存在很多其他实现,详见 HASH 算法一览。可以将他们分成三代:
第一代:SHA-1(1993),MD5(1992),CRC(1975),Lookup3(2006)
第二代:MurmurHash(2008)
第三代:CityHash, SpookyHash(2011)
这些都可以认为是广义上的哈希算法,你可以在 wiki 百科 中查看所有的哈希算法。当然还有一些哈希算法如:Ketama,专门为一致性哈希算法而设计。
既然有这么多哈希算法,那必然会有人问:当我们在讨论哈希算法时,我们再考虑哪些东西?我大概总结下有以下四点:
实现复杂程度
分布均匀程度
哈希碰撞概率
性能
先聊聊性能,是不是性能越高就越好呢?你如果有看过我曾经的文章 《该如何设计你的 PasswordEncoder?》,应该能了解到,在设计加密器这个场景下,慢 hash 算法反而有优势;而在负载均衡这个场景下,安全性不是需要考虑的因素,所以性能自然是越高越好。
优秀的算法通常比较复杂,但不足以构成评价标准,有点黑猫白猫论,所以 2,3 两点:分布均匀程度,哈希碰撞概率成了主要考虑的因素。
我挑选了几个值得介绍的哈希算法,重点介绍下。
MurmurHash 算法:高运算性能,低碰撞率,由 Austin Appleby 创建于 2008 年,现已应用到 Hadoop、libstdc++、nginx、libmemcached 等开源系统。2011 年 Appleby 被 Google 雇佣,随后 Google 推出其变种的 CityHash 算法。官方只提供了 C 语言的实现版本。Java 界中 Redis,Memcached,Cassandra,HBase,Lucene 都在使用它。 在 Java 的实现,Guava 的 Hashing 类里有,上面提到的 Jedis,Cassandra 里都有相关的 Util 类。
Ketama 算法:将它称之为哈希算法其实不太准确,称之为一致性哈希算法可能更为合适,其他的哈希算法有通用的一致性哈希算法实现,只不过是替换了哈希方式而已,但 Ketama 是一整套的流程,我们将在后面介绍。
以上三者都是最合适的一致性哈希算法的强力争夺者。
一致性哈希算法实现
一致性哈希的概念我不做赘述,简单介绍下这个负载均衡中的一致性哈希环。首先将服务器(ip+端口号)进行哈希,映射成环上的一个节点,在请求到来时,根据指定的 hash key 同样映射到环上,并顺时针选取最近的一个服务器节点进行请求(在本图中,使用的是 userId 作为 hash key)。
当环上的服务器较少时,即使哈希算法选择得当,依旧会遇到大量请求落到同一个节点的问题,为避免这样的问题,大多数一致性哈希算法的实现度引入了虚拟节点的概念。
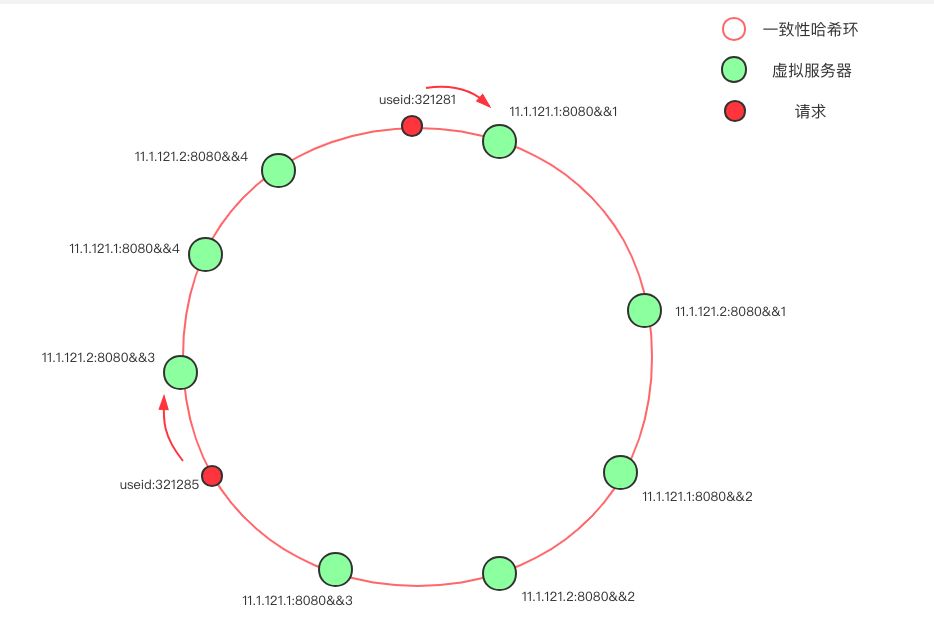
在上图中,只有两台物理服务器节点:11.1.121.1 和 11.1.121.2,我们通过添加后缀的方式,克隆出了另外三份节点,使得环上的节点分布的均匀。一般来说,物理节点越多,所需的虚拟节点就越少。
介绍完了一致性哈希换,我们便可以对负载均衡进行建模了:
public interface LoadBalancer {
Server select(List<Server> servers, Invocation invocation);
}
下面直接给出通用的算法实现:
public class ConsistentHashLoadBalancer implements LoadBalancer{
private HashStrategy hashStrategy = new JdkHashCodeStrategy();
private final static int VIRTUAL_NODE_SIZE = 10;
private final static String VIRTUAL_NODE_SUFFIX = "&&";
@Override
public Server select(List<Server> servers, Invocation invocation) {
int invocationHashCode = hashStrategy.getHashCode(invocation.getHashKey());
TreeMap<Integer, Server> ring = buildConsistentHashRing(servers);
Server server = locate(ring, invocationHashCode);
return server;
}
private Server locate(TreeMap<Integer, Server> ring, int invocationHashCode) {
// 向右找到第一个 key
Map.Entry<Integer, Server> locateEntry = ring.ceilingEntry(invocationHashCode);
if (locateEntry == null) {
// 想象成一个环,超过尾部则取第一个 key
locateEntry = ring.firstEntry();
}
return locateEntry.getValue();
}
private TreeMap<Integer, Server> buildConsistentHashRing(List<Server> servers) {
TreeMap<Integer, Server> virtualNodeRing = new TreeMap<>();
for (Server server : servers) {
for (int i = 0; i < VIRTUAL_NODE_SIZE; i++) {
// 新增虚拟节点的方式如果有影响,也可以抽象出一个由物理节点扩展虚拟节点的类
virtualNodeRing.put(hashStrategy.getHashCode(server.getUrl() + VIRTUAL_NODE_SUFFIX + i), server);
}
}
return virtualNodeRing;
}
}
对上述的程序做简单的解读:
Server 是对服务器的抽象,一般是 ip+port 的形式。
public class Server {
private String url;
}
Invocation 是对请求的抽象,包含一个用于 hash 的 key。
public class Invocation {
private String hashKey;
}
使用 TreeMap 作为一致性哈希环的数据结构, ring.ceilingEntry 可以获取环上最近的一个节点。在 buildConsistentHashRing 之中包含了构建一致性哈希环的过程,默认加入了 10 个虚拟节点。
计算方差,标准差的公式:
public class StatisticsUtil {
//方差s^2=[(x1-x)^2 +...(xn-x)^2]/n
public static double variance(Long[] x) {
int m = x.length;
double sum = 0;
for (int i = 0; i < m; i++) {//求和
sum += x[i];
}
double dAve = sum / m;//求平均值
double dVar = 0;
for (int i = 0; i < m; i++) {//求方差
dVar += (x[i] - dAve) * (x[i] - dAve);
}
return dVar / m;
}
//标准差σ=sqrt(s^2)
public static double standardDeviation(Long[] x) {
int m = x.length;
double sum = 0;
for (int i = 0; i < m; i++) {//求和
sum += x[i];
}
double dAve = sum / m;//求平均值
double dVar = 0;
for (int i = 0; i < m; i++) {//求方差
dVar += (x[i] - dAve) * (x[i] - dAve);
}
return Math.sqrt(dVar / m);
}
}
其中, HashStrategy 是下文中重点讨论的一个内容,他是对 hash 算法的抽象,我们将会着重对比各种 hash 算法给测评结果带来的差异性。
public interface HashStrategy {
int getHashCode(String origin);
}
测评程序
前面我们已经明确了一个优秀的一致性哈希算法的设计思路。这一节我们给出实际的量化指标:假设 m 次请求打到 n 个候选服务器上
统计每个服务节点收到的流量,计算方差、标准差。测量流量分布均匀情况,我们可以模拟 10000 个随机请求,打到 100 个指定服务器,测试最后个节点的方差,标准差。
记录 m 次请求落到的服务器节点,下线 20% 的服务器,重放流量,统计 m 次请求中落到跟原先相同服务器的概率。测量节点上下线的情况,我们可以模拟 10000 个随机请求,打到 100 个指定服务器,之后下线 20 个服务器并重放流量,统计请求到相同服务器的比例。
public class LoadBalanceTest {
static String[] ips = {...}; // 100 台随机 ip
/**
* 测试分布的离散情况
*/
@Test
public void testDistribution() {
List<Server> servers = new ArrayList<>();
for (String ip : ips) {
servers.add(new Server(ip));
}
ConsistentHashLoadBalancer chloadBalance = new ConsistentHashLoadBalancer();
// 构造 10000 随机请求
List<Invocation> invocations = new ArrayList<>();
for (int i = 0; i < 10000; i++) {
invocations.add(new Invocation(UUID.randomUUID().toString()));
}
// 统计分布
AtomicLongMap<Server> atomicLongMap = AtomicLongMap.create();
for (Invocation invocation : invocations) {
Server selectedServer = chloadBalance.select(servers, invocation);
atomicLongMap.getAndIncrement(selectedServer);
}
System.out.println(StatisticsUtil.standardDeviation(atomicLongMap.asMap().values().toArray(new Long[]{})));
}
/**
* 测试节点新增删除后的变化程度
*/
@Test
public void testNodeAddAndRemove() {
List<Server> servers = new ArrayList<>();
for (String ip : ips) {
servers.add(new Server(ip));
}
List<Server> serverChanged = servers.subList(0, 80);
ConsistentHashLoadBalancer chloadBalance = new ConsistentHashLoadBalancer();
// 构造 10000 随机请求
List<Invocation> invocations = new ArrayList<>();
for (int i = 0; i < 10000; i++) {
invocations.add(new Invocation(UUID.randomUUID().toString()));
}
int count = 0;
for (Invocation invocation : invocations) {
Server origin = chloadBalance.select(servers, invocation);
Server changed = chloadBalance.select(serverChanged, invocation);
if (origin.getUrl().equals(changed.getUrl())) count++;
}
System.out.println(count / 10000D);
}
不同哈希算法的实现及测评
最简单、经典的 hashCode 实现:
public class JdkHashCodeStrategy implements HashStrategy {
@Override
public int getHashCode(String origin) {
return origin.hashCode();
}
}
FNV132HASH 算法实现:
public class FnvHashStrategy implements HashStrategy {
private static final long FNV_32_INIT = 2166136261L;
private static final int FNV_32_PRIME = 16777619;
@Override
public int getHashCode(String origin) {
final int p = FNV_32_PRIME;
int hash = (int) FNV_32_INIT;
for (int i = 0; i < origin.length(); i++)
hash = (hash ^ origin.charAt(i)) * p;
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
hash = Math.abs(hash);
return hash;
}
}
CRC 算法:
public class CRCHashStrategy implements HashStrategy {
@Override
public int getHashCode(String origin) {
CRC32 crc32 = new CRC32();
crc32.update(origin.getBytes());
return (int) ((crc32.getValue() >> 16) & 0x7fff & 0xffffffffL);
}
}
Ketama 算法:
public class KetamaHashStrategy implements HashStrategy {
private static MessageDigest md5Digest;
static {
try {
md5Digest = MessageDigest.getInstance("MD5");
} catch (NoSuchAlgorithmException e) {
throw new RuntimeException("MD5 not supported", e);
}
}
@Override
public int getHashCode(String origin) {
byte[] bKey = computeMd5(origin);
long rv = ((long) (bKey[3] & 0xFF) << 24)
| ((long) (bKey[2] & 0xFF) << 16)
| ((long) (bKey[1] & 0xFF) << 8)
| (bKey[0] & 0xFF);
return (int) (rv & 0xffffffffL);
}
/**
* Get the md5 of the given key.
*/
public static byte[] computeMd5(String k) {
MessageDigest md5;
try {
md5 = (MessageDigest) md5Digest.clone();
} catch (CloneNotSupportedException e) {
throw new RuntimeException("clone of MD5 not supported", e);
}
md5.update(k.getBytes());
return md5.digest();
}
}
MurmurHash 算法:
public class MurmurHashStrategy implements HashStrategy {
@Override
public int getHashCode(String origin) {
ByteBuffer buf = ByteBuffer.wrap(origin.getBytes());
int seed = 0x1234ABCD;
ByteOrder byteOrder = buf.order();
buf.order(ByteOrder.LITTLE_ENDIAN);
long m = 0xc6a4a7935bd1e995L;
int r = 47;
long h = seed ^ (buf.remaining() * m);
long k;
while (buf.remaining() >= 8) {
k = buf.getLong();
k *= m;
k ^= k >>> r;
k *= m;
h ^= k;
h *= m;
}
if (buf.remaining() > 0) {
ByteBuffer finish = ByteBuffer.allocate(8).order(
ByteOrder.LITTLE_ENDIAN);
// for big-endian version, do this first:
// finish.position(8-buf.remaining());
finish.put(buf).rewind();
h ^= finish.getLong();
h *= m;
}
h ^= h >>> r;
h *= m;
h ^= h >>> r;
buf.order(byteOrder);
return (int) (h & 0xffffffffL);
}
}
测评结果:
| 方差 | 标准差 | 不变流量比例 | |
|---|---|---|---|
| JdkHashCodeStrategy | 29574.08 | 171.97 | 0.6784 |
| CRCHashStrategy | 3013.02 | 54.89 | 0.7604 |
| FnvHashStrategy | 792.02 | 28.14 | 0.7892 |
| KetamaHashStrategy | 1147.08 | 33.86 | 0.80 |
| MurmurHashStrategy | 634.82 | 25.19 | 0.80 |
其中方差和标准差反映了均匀情况,越低越好,可以发现 MurmurHashStrategy,KetamaHashStrategy,FnvHashStrategy 都表现的不错,其中 MurmurHashStrategy 最为优秀。
不变流量比例体现了服务器上下线对原有请求的影响程度,不变流量比例越高越高,可以发现 KetamaHashStrategy 和 MurmurHashStrategy 表现最为优秀。
我并没有对小集群,小流量进行测试,样本偏差性较大,仅从这个常见场景来看,MurmurHashStrategy 似乎是最优的选择。
至于性能测试,MurmurHash 也十分的高性能,我并没有做测试(感兴趣的同学可以对几种 strategy 用 JMH 测评一下),这里我贴一下 MurmurHash 官方的测评数据:
OneAtATime - 354.163715 mb/sec
FNV - 443.668038 mb/sec
SuperFastHash - 985.335173 mb/sec
lookup3 - 988.080652 mb/sec
MurmurHash 1.0 - 1363.293480 mb/sec
MurmurHash 2.0 - 2056.885653 mb/sec
扩大虚拟节点可以明显降低方差和标准差,但虚拟节点的增加会加大内存占用量以及计算量
Ketama 一致性哈希算法实现
Ketama 算法有其专门的配套实现方式
public class KetamaConsistentHashLoadBalancer implements LoadBalancer {
private static MessageDigest md5Digest;
static {
try {
md5Digest = MessageDigest.getInstance("MD5");
} catch (NoSuchAlgorithmException e) {
throw new RuntimeException("MD5 not supported", e);
}
}
private final static int VIRTUAL_NODE_SIZE = 12;
private final static String VIRTUAL_NODE_SUFFIX = "-";
@Override
public Server select(List<Server> servers, Invocation invocation) {
long invocationHashCode = getHashCode(invocation.getHashKey());
TreeMap<Long, Server> ring = buildConsistentHashRing(servers);
Server server = locate(ring, invocationHashCode);
return server;
}
private Server locate(TreeMap<Long, Server> ring, Long invocationHashCode) {
// 向右找到第一个 key
Map.Entry<Long, Server> locateEntry = ring.ceilingEntry(invocationHashCode);
if (locateEntry == null) {
// 想象成一个环,超过尾部则取第一个 key
locateEntry = ring.firstEntry();
}
return locateEntry.getValue();
}
private TreeMap<Long, Server> buildConsistentHashRing(List<Server> servers) {
TreeMap<Long, Server> virtualNodeRing = new TreeMap<>();
for (Server server : servers) {
for (int i = 0; i < VIRTUAL_NODE_SIZE / 4; i++) {
byte[] digest = computeMd5(server.getUrl() + VIRTUAL_NODE_SUFFIX + i);
for (int h = 0; h < 4; h++) {
Long k = ((long) (digest[3 + h * 4] & 0xFF) << 24)
| ((long) (digest[2 + h * 4] & 0xFF) << 16)
| ((long) (digest[1 + h * 4] & 0xFF) << 8)
| (digest[h * 4] & 0xFF);
virtualNodeRing.put(k, server);
}
}
}
return virtualNodeRing;
}
private long getHashCode(String origin) {
byte[] bKey = computeMd5(origin);
long rv = ((long) (bKey[3] & 0xFF) << 24)
| ((long) (bKey[2] & 0xFF) << 16)
| ((long) (bKey[1] & 0xFF) << 8)
| (bKey[0] & 0xFF);
return rv;
}
private static byte[] computeMd5(String k) {
MessageDigest md5;
try {
md5 = (MessageDigest) md5Digest.clone();
} catch (CloneNotSupportedException e) {
throw new RuntimeException("clone of MD5 not supported", e);
}
md5.update(k.getBytes());
return md5.digest();
}
}
稍微不同的地方便在于:Ketama 将四个节点标为一组进行了虚拟节点的设置。
| 方差 | 标准差 | 不变流量比例 | |
|---|---|---|---|
KetamaConsistent HashLoadBalancer |
911.08 | 30.18 | 0.7936 |
实际结果并没有太大的提升,可能和测试数据的样本规模有关。
总结
优秀的哈希算法和一致性哈希算法可以帮助我们在大多数场景下应用的高性能,高稳定性,但在实际使用一致性哈希负载均衡的场景中,最好针对实际的集群规模和请求哈希方式进行压测,力保流量均匀打到所有的机器上,这才是王道。
不仅仅是分布式缓存,负载均衡等等有限的场景,一致性哈希算法、哈希算法,尤其是后者,是一个用处很广泛的常见算法,了解它的经典实现是很有必要的,例如 MurmurHash,在 guava 中就有其 Java 实现,当需要高性能,分布均匀,碰撞概率小的哈希算法时,可以考虑使用它。
分享一份蛮不错的《Java核心知识点整理.pdf》,覆盖了JVM、锁、高并发、反射、Spring原理、微服务、Zookeeper、数据库、数据结构等等。
近期热文:
以上是关于一文搞懂负载均衡中的一致性哈希算法的主要内容,如果未能解决你的问题,请参考以下文章