一致性哈希算法---负载均衡
Posted Flytiger1220
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一致性哈希算法---负载均衡相关的知识,希望对你有一定的参考价值。
目录
场景一:业务服务器
负载的概念就是希望把不同区域的用户(客户端)分发到不同的服务器上,让每个服务器都尽量均衡的接受同等数量的客户端请求,把压力分散于不同的服务器中,所以前面就需要有一台反向代理服务器,也叫负载均衡器。像我们用的nginx、lvs都是非常强大的负载均衡器,有反向代理功能。负载均衡算法就属于一致性哈希算法。
轮询算法:第一个请求给server1,第二个请求给server2,第三个请求给server3,按权重比配置权重,基于这种权重的负载算法,有四个请求到来,其中会给server1和server3分别分配一个,其中两个会分配到server2。
最少连接算法:负载均衡器里面要记录和每一台服务器创建的连接,每次在分发请求的时候和哪台服务器创建的连接越少则先分发给哪台服务器,因为和哪台服务器创建的连接越少,就说明这台服务器对应的压力是最小的,那么新来的请求就给到压力最小的服务器。
普通的哈希算法:和前面学的哈希表的除留余数法一样,比如里面有3台服务器,来一个请求就给它模上3,就得到0,1,2其中的一个值,对应哪个服务器的下标就把这个请求给到哪台服务器。
这些算法虽然简单,但是在我们大规模分布式集群环境中,有致命的缺陷,比如要求:

如果用普通哈希算法,不同的客户端ip地址不一样,或者在同一台机器上操作的话端口号不一样。哈希算法得有一个输入参数和输出参数,这里输入参数就选的是ip地址+端口号。客户端的请求过来以后,我们可以从它的传输层TCP报文里面取出来ip地址和端口号,在这里我们普通的哈希做的是除留余数法,采用md5哈希函数处理完后得到一个整数,再模上服务器个数N就得到了0~N-1其中一个整数,得到哪个数字就意味着客户端请求分发到哪台服务器上。

比如一个ip地址+端口号经过md5处理后得到的是22,22%3=1,就意味着这个客户端发来的请求永远被映射到1号机器上。
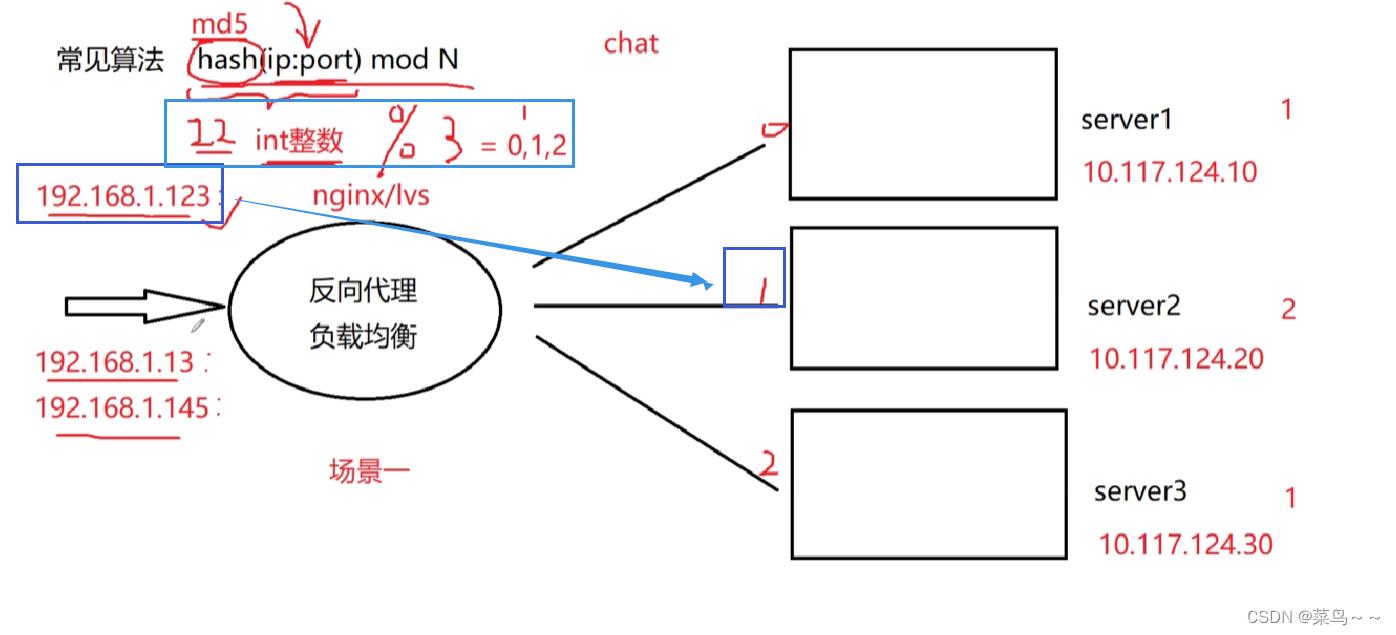
同一个客户端永远被映射到一台指定的server上。因为客户端的IP地址和端口号不变,经过md5哈希以后,得到的都是同一个整数。有效地解决会话共享的问题。
会话共享问题:比如两个客户端zhangsan和lisi。zhangsan的ip地址和端口号作为md5函数的输入参数,处理完再模上服务器个数永远是一个固定的数(比如1),那么zhangsan从刚开始登录的时候就登录到1号服务器上,会写一些它的用户名和密码来验证客户端是否登录成功,在1号服务器上就会记录zhangsan所有的会话session,会话里面就包含了zhangsan的登录状态、connection连接信息等等,比如我们消息聊天就必须保证是常连接,因为客户端不仅仅会给服务端发送消息,服务端还会给客户端主动推送消息,这就需要保持这种常连接。lisi这个客户端经过处理后比如是2,那么它的会话就存储在2号服务器上,这台服务器也包含了lisi的登录状态、connection连接信息等等都是和客户端相关的信息,存储的是业务上实现相关功能需要的信息。
假如说客户端每一次的请求没有被映射到一台指定的server上,而是每一次发来的请求都跳到不同的服务器上,可能会出现zhangsan第一次的请求被映射到1号服务器上,那么在1号服务器做业务处理以后,判断zhangsan输入的id号、用户名、密码都是正确的,则登录成功,在这台服务端就记录了它的session,下一次zhangsan重新发了一个请求,这个请求没有被映射到1号服务器,被映射到0号服务器了,但是zhangsan的session在服务器1上记录的,0号服务器并没有记录。当然每一次请求被映射到不同的服务器端也不是不可以,我们需要相应的办法来解决这个问题,那就是把不同服务器上所有的会话都放在统一的redis里面,每一次根据用户的id取当前用户的状态,不要从当前用户的内存取,而是从远程的缓存服务器去取。
登录成功以后,客户端和这个服务器还有一些连接,我们希望后续它所做的所有的请求都是在这台服务器上,因为这台服务器保持了和这个客户端的常连接。
这种普通哈希算法的设计,我们有效的解决了会话共享的问题,也就保证了客户端永远落在一台服务器上。
我们考虑这么一个问题:假如说1号机器挂掉了,按理来说只影响1号机器上登录成功的用户,而不应该影响0和2号机器上登录的用户,但是实际上影响了,为什么?
因为现在后续所有客户端发来的请求,经过md5处理以后,在nginx或者lvs都是可以动态识别后端服务器的故障的,那么识别故障以后就不是模3而是模2了,原来模上3到达0和2号服务器的客户端,现在由于1号服务器挂掉了,再去发后续请求的话,经过md5哈希函数处理以后,现在不是模3而是模2,原来模上3达到0和2服务器,现在模上2不可能再到达0和2服务器了,肯定会变的。
用普通的哈希算法遇到的问题是:当我们一个机器挂掉了后,原本在其他机器上正常登录的客户端,后续的请求就不一定达到原先的服务器。
或者是增加了1台服务器,3号服务器,可以让后续新登录的用户给这个3号服务器上负载一些。原来登录在0,1,2上的服务器的用户就不用变,后续的请求就还是登录到之前的0,1,2号服务器,那么现在不是这样,动态增加1台服务器后,nginx(lvs)会感知到,同样的客户端,同样的IP地址端口号经过md5哈希函数后模上4了!!!就全乱了!!!
场景二:缓存服务器
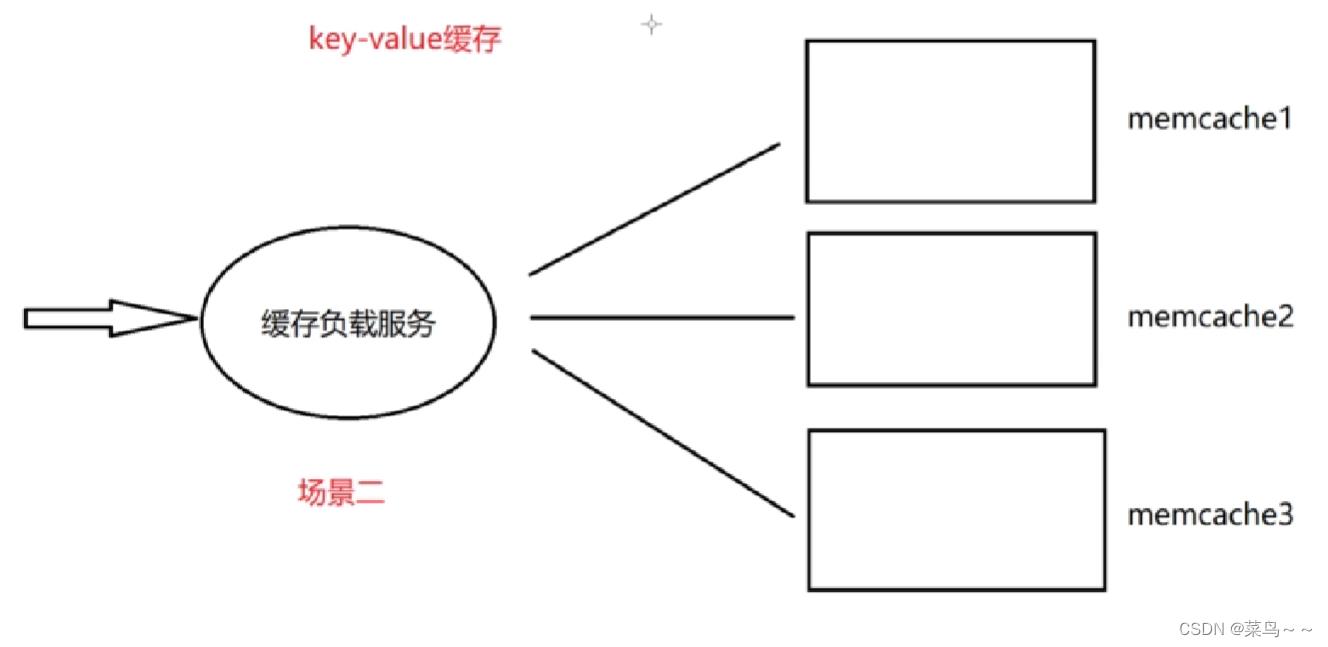
服务端要增删改查数据,能不能直接操作数据库,可以是可以,但是做不到高并发,因为数据库本身是受限于磁盘操作的,磁盘IO速度是非常慢的,虽然可以通过索引做一些优化,但是索引如果大了,索引本身也是要在磁盘上存储的,读索引也是要花费磁盘IO的,永远没有从内存上来的快。所以我们做后台开发的,要把一些热点数据储存在缓存上,我们拿用户的ID(key),先在缓存上(Redis,memcache)查,查不到再去DB数据库上查,查完了,先把数据往缓存上放,然后返回给服务层,服务器处理完业务把结果返回给用户。
其次,在高并发大流量的场景下,缓存服务器本身也要集群。
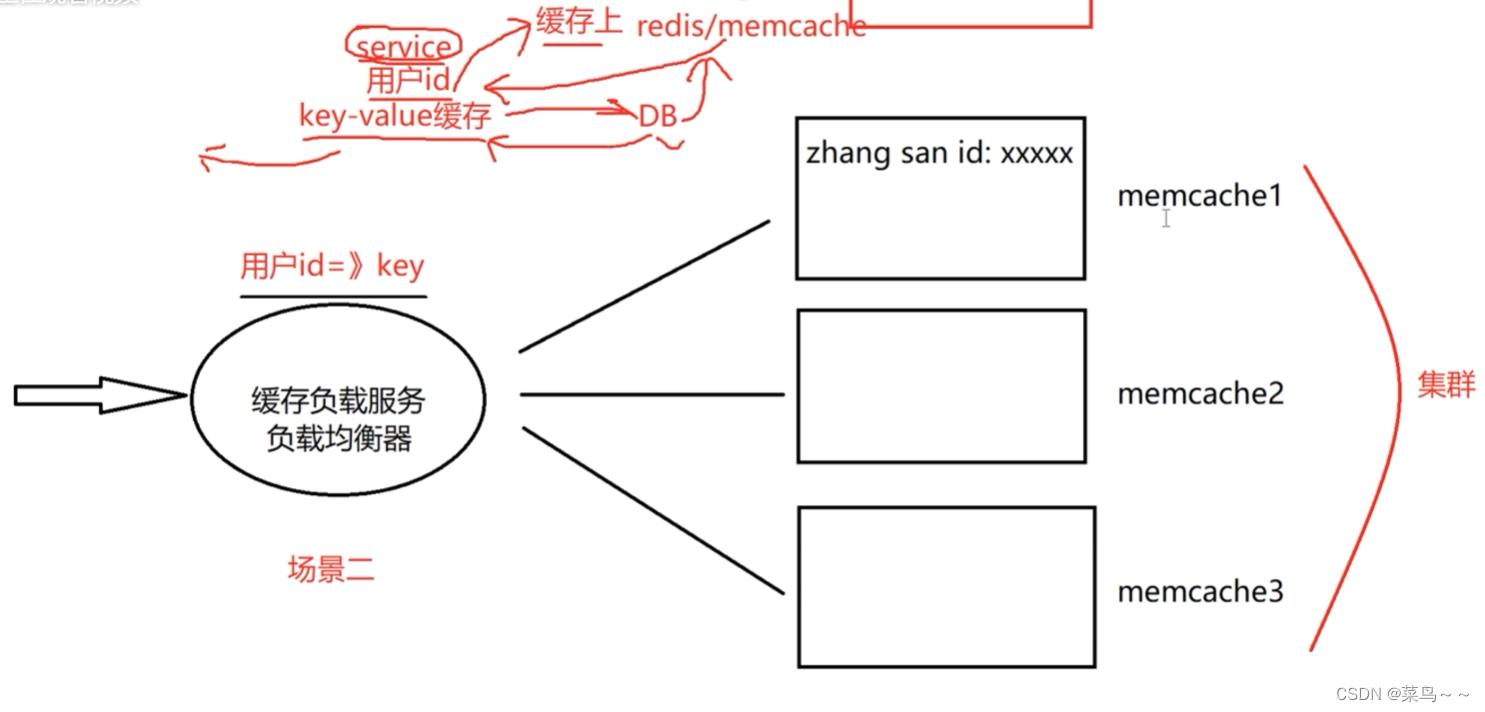
根据普通哈希算法,把用户ID传入md5哈希函数,1个用户永远到1台memcach服务器上。
此时,memcach3挂掉了,按照普通的哈希算法,模上的数字改了,原来用户的后续请求落在了不同的memcach服务器上了,导致查询不到,然后到DB上找,DB上找来了以后又存到了不同的memcach上,导致有多台memcach服务器存储了同一个用户的信息。
假如memcach1上存储了10万用户的ID信息。这10万用户经过模数的更改,找不到缓存,然后都从DB上查,DB一下子就懵了,然后又重新落在了其他的memcach服务器上。
同样的再增加1台memcach服务器,模数也改了,结果也是不能接受的。
原本有100万数据,90万从缓存读取,10万由于缓存没查到落到DB,如果因为一台服务器的挂掉或者增加,模数改变,然后没查到,把90万数据都转到了DB,就严重了。
挂掉了服务器3,我们的理想是,得让原来落在服务器1和服务器2的用户,永远落在他们最初落在的服务器上,其他的新用户的请求进行新的模数取余负载分发。

这个是普通的哈希算法无法解决的。这就需要我们的一致性哈希算法,会弥补普通的哈希算法这些问题。
一致性哈希算法

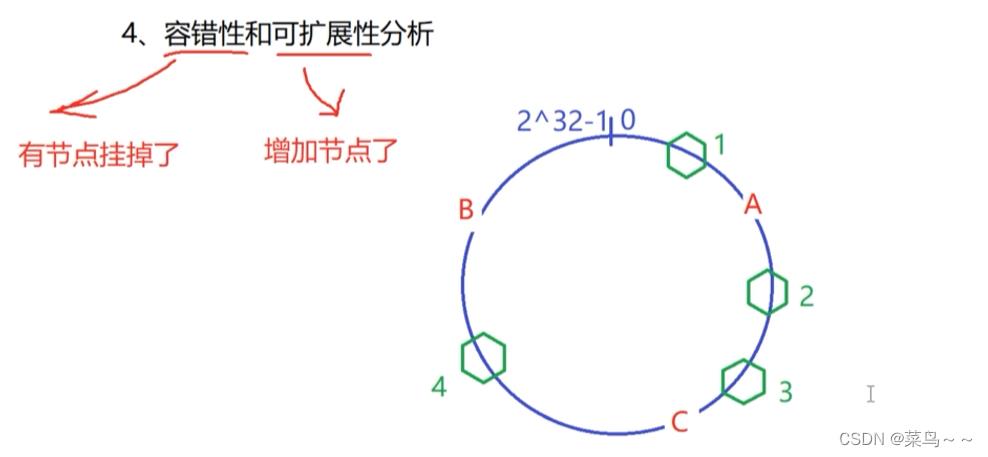
一致性哈希算法描述:
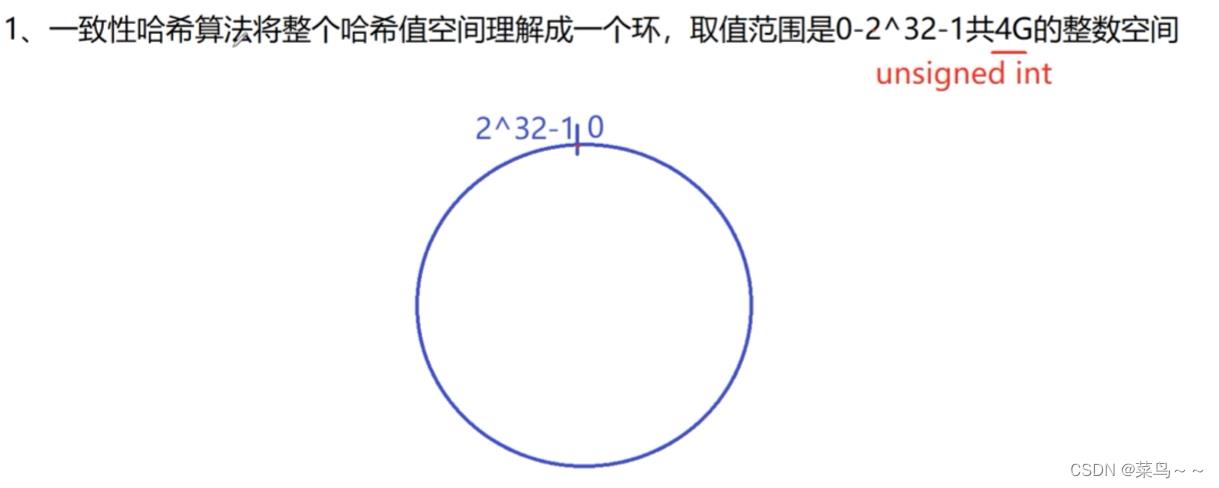
这个环就是一堆整数的取值方位,代表的数字。
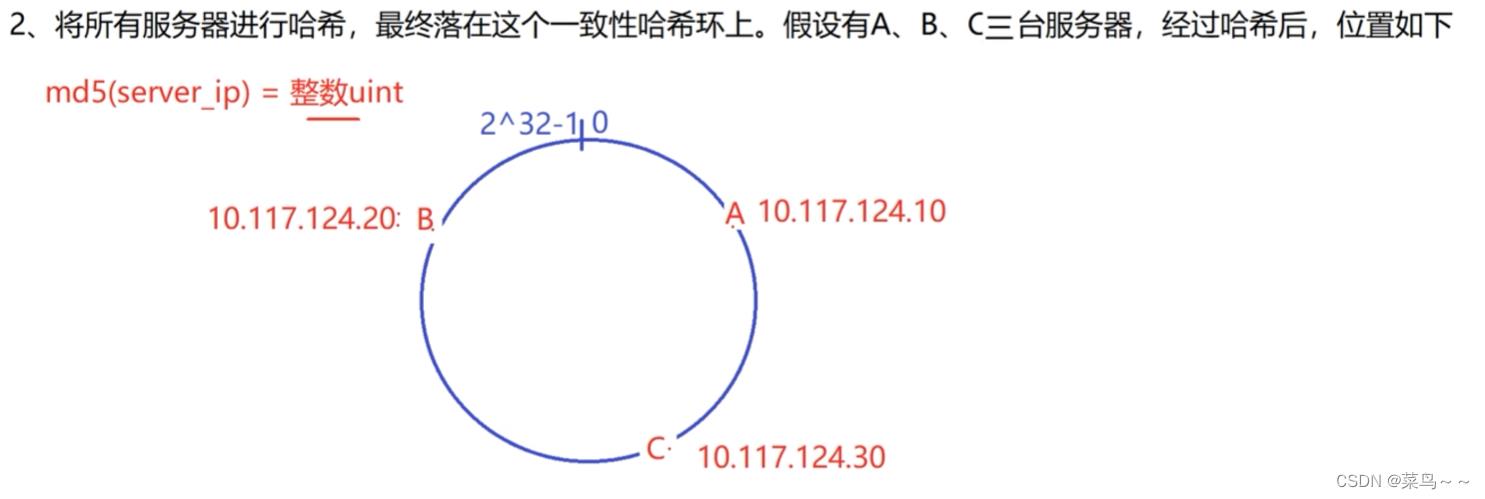
A,B,C落在3个不同的地方,代表md5算出的3个不同的数字
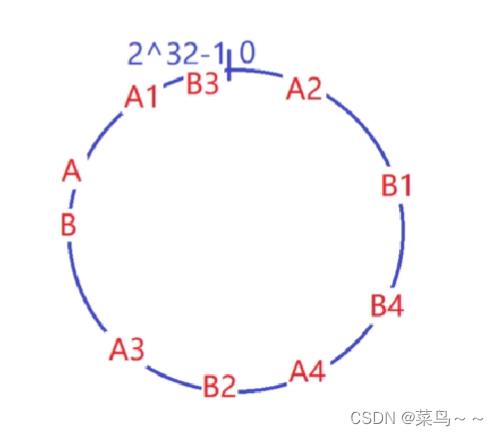
假设现在有4个客户请求进来了,这4个客户都有自己的IP和端口,我们把IP+端口作为输入值,经过md5处理后得到4个整数,分别落在了一致性哈希环上的4个位置。
在这个一致性哈希环上,沿着顺时针,遇到的第一台服务器就是最终负载到的服务器。
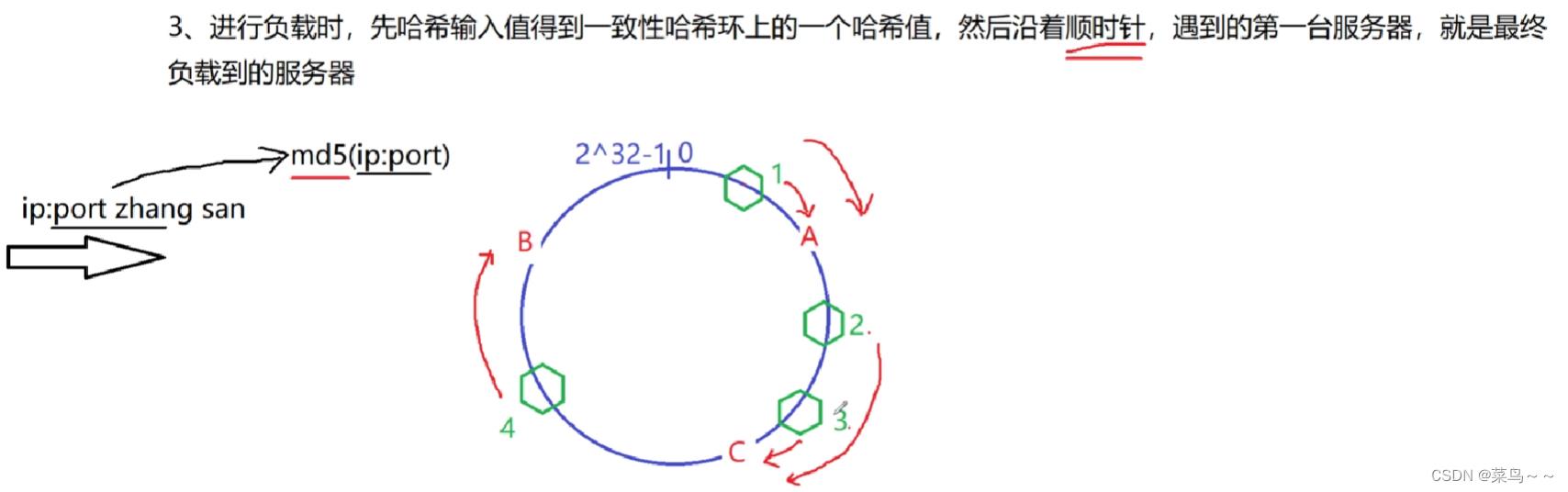
假如现在客户端的请求来了(zhangsan的请求来了),zhangsan的IP地址+端口号作为输入值,进行md5的哈希,算出的哈希值,位于一致性哈希环上的1号位置,那么zhangsan请求最终落在了A服务器上。
客户2和客户3的请求就落在C服务器上。
客户4的请求就落在B服务器上。
这样到底有没有解决普通哈希算法存在的问题?

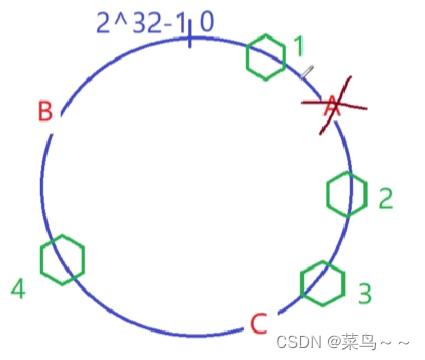
假如服务器3挂掉了,那么原来在1和2上工作的客户端依然在1和2上,由于3宕机了,原来在3上工作的客户被重新分发到1和2上就可以了。
另外如果又增加了一台服务器,原来在1、2和3上的客户端依然在1、2和3上,只不过后期我们负载均衡器负载算法就会把后续的新的请求落在4上。
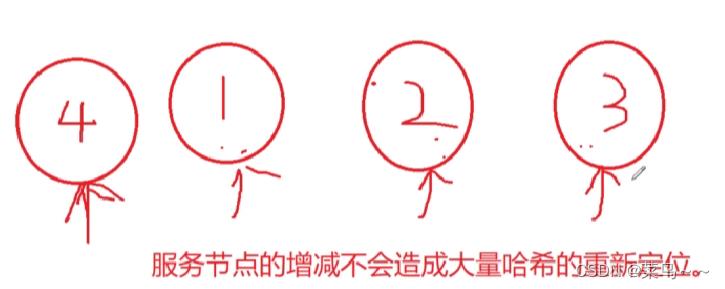
不管是增加还是减少节点,服务器请求、负载的变化、重新哈希的结果应该做到最少的改动,有利于服务端业务运行的稳定。
假如说现在A挂了,不会影响原来在B和C上的客户端,因为根据一致性哈希算法的处理,2和3最终沿着在哈希环上的顺序访问还是落在C机器上,4最终还是落在B机器上,只会影响A服务器上的客户端。
如果现在增加一个D服务器,首先把D服务器的IP地址作为输入参数,传给md5哈希函数,得出整数值,就是落在一致性哈希环上的位置。
增加一个服务器节点,只影响这个服务器节点按逆时针遇到的上一台服务器的之间的请求。做到最少的改动。
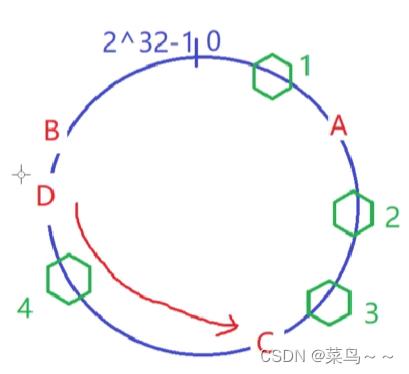
这个确实可以达到

可以用一个set,底层是红黑树,只存key来实现这个环。

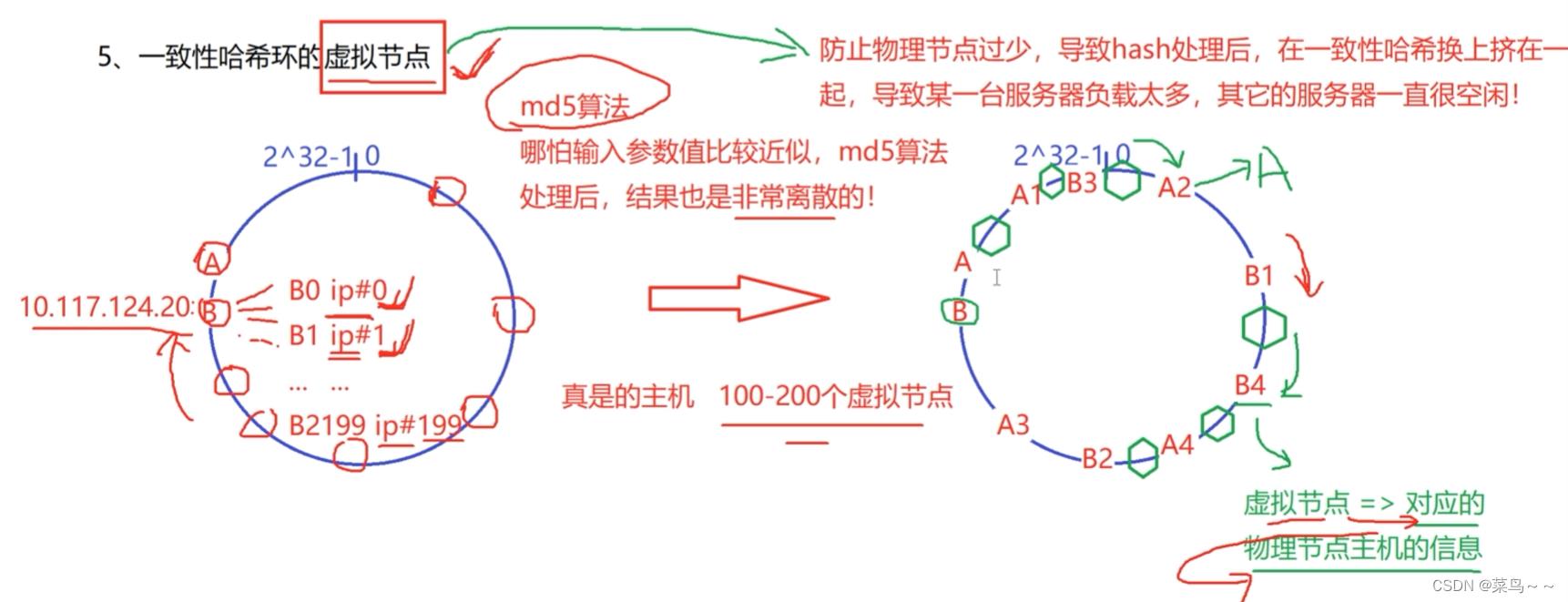
为了达到每一个服务器的负载能力都比较均衡,尽量让它们分散一些,收到的客户的请求就均衡一些,趋于平均。
下面这个图就不好
可以用虚拟节点来解决。虚拟节点:把一个机器虚拟的看成很多台机器
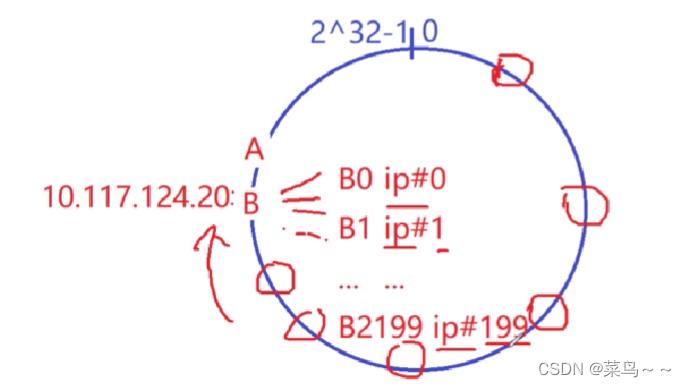
ip虽然相同,但是后面的#数字不同,我们就可以在哈希环上得到不同位置的散列值。md5算法特点:哪怕输入参数值比较近似,md5算法处理后,结果也是非常离散的。
在实际中,我们给真实的主机放100-200个虚拟节点,A和B在md5计算后的结果非常近,但是我们把物理主机想象成各自有100-200个虚拟主机,在环上就相对离散。
虚拟节点保存其对应的物理节点的主机的信息,请求是落在虚拟节点对应的物理主机上。
一致性哈希算法有哪些需要我们在代码上表示的

参考
以上是关于一致性哈希算法---负载均衡的主要内容,如果未能解决你的问题,请参考以下文章