直接选择排序到堆排序做的那些改进
Posted Python与算法社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了直接选择排序到堆排序做的那些改进相关的知识,希望对你有一定的参考价值。
主要推送关于对算法的思考以及应用的消息。坚信学会如何思考一个算法比单纯地掌握100个知识点重要100倍。本着严谨和准确的态度,目标是撰写实用和启发性的文章,欢迎您的关注,让我们一起进步吧。
01
—
你会学到什么?
彻底弄明白常用的排序算法的基本思想,算法的时间和空间复杂度,以及如何选择这些排序算法,确定要解决的问题的最佳排序算法,上个推送总结了,下面总结直接选择排序到堆排序的改进,后面再继续总结插入排序、希尔排序、归并排序和基数排序。
02
—
讨论的问题是什么?
各种排序算法的基本思想;讨论各种排序算法的时间、空间复杂度;以及算法的稳定性;算法是如何改进的,比如冒泡排序如何改进成了目前最常用的快速排序的,直接选择排序到堆排序的改进,正是接下来要讨论的对象。
03
—
相关的概念和理论
内部排序
若整个排序过程不需要访问外存便能完成,则称此类排序问题为内部排序。
外部排序
若参加排序的记录数量很大,整个序列的排序过程不可能在内存中完成,则称此类排序问题为外部排序。
就地排序
若排序算法所需的辅助空间并不依赖于问题的规模n,即辅助空间为O(1),称为就地排序。
稳定排序
假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序后,这些记录的相对次序保持不变,即在原序列中 ri=rj, ri 在 rj 之前,而在排序后的序列中,ri 仍在 rj 之前,则称这种排序算法是稳定的;否则称为不稳定的。
排序序列分布
排序需要考虑待排序关键字的分布情况,这会影响对排序算法的选择,通常我们在分析下列算法时都考虑关键字分布是随机分布的,不是按照某种规律分布的,比如正态分布等。
待排序序列
排序序列中,剩余即将要排序的序列部分。
已排序序列
排序序列中,已经排序好的序列部分。
04
—
直接选择排序
直接选择排序,英文名称 :Straight Select Sorting,是一个直接从未排序序列选择最值到已排序序列的过程。
基本思想
第一次从R[0]~R[n-1]中选取最小值,与R[0]交换;
第二次从R[1]~R[n-1]中选取最小值,与R[1]交换,....,
第 i 次从R[i-1]~R[n-1]中选取最小值,与R[i-1]交换,.....,
总共通过n-1次,得到一个按关键码从小到大排列的有序序列。
升序排序的例子
我们仍然用上节冒泡排序和快速排序举的例子。待排序列
3 2 5 9 2
演示如何用直接选择排序得到升序序列。
第一轮,从所有关键码中选择最小值与 R[0]交换,3与2交换,如下图所示,
第二轮,从 R[1]~R[n-1]中选择最小值与R[1]交换,3与2交换;
第三轮,从 R[2]~R[n-1]中选择最小值与R[2]交换,5与3交换;
第四轮,从 R[3]~R[n-1]中选择最小值与R[3]交换,9与5交换;
终止。
算法评价
在直接选择排序中,共需要进行 n-1 轮,每轮必发生一次交换,每轮需要进行 n-i 次比较 (1<=i<=n-1),总的比较次数等于
(n-1) + (n-2) + ... + ( n-(n-1) )
化简后等于 n + (n-1)(n-2)/2
由此可知,直接选择排序的时间复杂度为 O(n^2) ,空间复杂度为 O(1) 。注意到,直接选择排序在最好和最坏情况下都是 O(n^2) 。
一般地,排序算法的时间复杂度为 O(n^2)是不令人满意的排序算法,在选择排序算法的思想下,有一种选择排序算法提升了时间性能,它就是堆排序,接下来我们就看下堆排序。
05
—
直接选择的优化版之堆排序
堆排序,英文名称 Heapsort,利用二叉树(堆)这种数据结构所设计的一种排序算法,是一种对直接选择排序的一种改建算法。在逻辑结构上是按照二叉树存储结构,正是这种结构优化了选择排序的性能,在物理存储上是连续的数组存储,它利用了数组的特点快速定位指定索引的元素。这么巧妙的算法又是哪位科学家发明的呢?
这个算法是计算机先驱奖获得者、斯坦福大学计算机科学系教授罗伯特·弗洛伊德(Robert W.Floyd)和威廉姆斯(J.Williams)在1964年共同发明的堆排序算法,我们重点认识下弗洛伊德。

没错,就是这位,第一眼看上去是搞艺术创作的,没错他的确是在芝加哥大学读的文学,后来因为苦于找不上工作,改行去西屋电气公司当了二年计算机操作员,发现他对计算机非常感兴趣。
于是他下定决心要弄懂它,掌握它,于是他借了有关书籍资料在值班空闲时间刻苦学习钻研,有问题就虚心向程序员请教。白天不值班,他又回校去听讲有关课程,逐渐从计算机的门外汉变成计算机的行家里手。
1956年他离开西屋电气公司,到芝加哥的装甲研究基金会(Armour Research Foundation),开始还是当操作员,后来就当了程序员。1962年他被马萨诸塞州的Computer Associates公司聘为分析员。1965年他应聘成为卡内基—梅隆大学的副教授,3年后转至斯坦福大学,1970年被聘任为教授。
之所以能这样快地步步高升,关键就在于弗洛伊德通过勤奋学习和深入研究,是一位自学成才的计算机科学家。
堆排序的基本概念
n个关键字序列 Kl,K2,…,Kn 称为堆(Heap),当且仅当该序列满足如下性质:
Ki <= K( 2i + 1 )且 Ki <= K( 2i + 2 ) ( 0≤i≤ (n/2)-1),称为小根堆;
Ki >= K( 2i + 1) 且 Ki >= K( 2i +2 ) ( 1≤i≤ (n/2)-1), 称为大根堆。
堆排序的算法思想
堆分为大根堆和小根堆,是完全二叉树。大根堆的要求是每个节点的值都不大于其父节点的值,即 R[PARENT[i]] >= R[i]。在数组的非降序排序中,需要使用的就是大根堆,因为根据大根堆的要求可知,最大的值一定在堆顶。小根堆与之类似,每个节点的值都不小于父节点的值,最小值出现在树根处。
堆排序利用了大根堆(或小根堆)堆顶记录的关键字最大(或最小)这一特征,使得在当前无序区中选取最大(或最小)关键字的记录变得简单。
堆排序是如何工作的
以大根堆排序为例,即要得到非降序序列。
先将初始文件R[0..n-1]建成一个大根堆,此堆为初始的无序区。
再将关键字最大的记录R[0](即堆顶)和无序区的最后一个记录R[n-1]交换,由此得到新的无序区 R[0..n-2] 和有序区 R[n-1],且满足 R[0..n-2] ≤ R[n-1]
由于交换后新的根R[0]可能违反堆性质,故应将当前无序区R[0..n-2]调整为堆。然后再次将R[0..n-2]中关键字最大的记录R[0]和该区间的最后一个记录R[n-2]交换,由此得到新的无序区R[0..n-3] 和 有序区R[n-2..n-1],且仍满足关系R[0..n-3] ≤ R[n-2..n-1]。
重复步骤2和步骤3,直到无序区只有一个元素为止。
堆排序算法涉及到的两个主要操作正如上算法所描写的那样,先构建一个初始堆,然后堆顶不断地和当前无序区的最后一个元素交换,交换可能会导致初始构建的大根堆不再是大根堆,所以需要再次调整堆(这个实际上还是构建一个初始堆的函数),简单来说:
构建堆
交换堆顶和无序区的最后一个元素,再次构建大根堆;
重复步骤2的操作,直至无序区只剩下一个元素为止。
应用堆排序得到升序排序的例子
我们仍然用那个待排序列
3 2 5 9 2
第一步,我们需要构建大根堆,为了构建大根堆,我们再温习下刚才的堆排序的基础知识,首先以上待排序列的物理存储结构和逻辑存储结构的示意图如下所示,
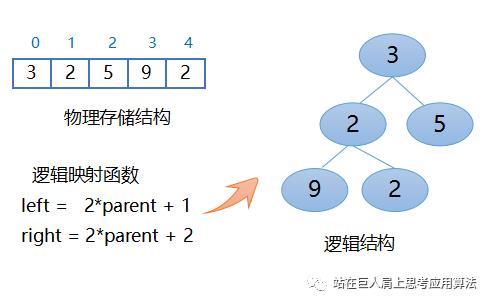
构建初始堆是从length/2 - 1,即从索引1处关键码等于2开始构建,2的左右孩子等于9, 2,它们三个比较后,父节点2与左孩子9交换,如下图所示:
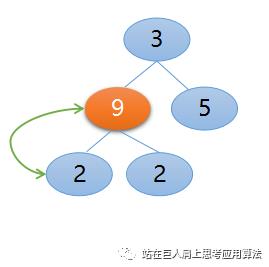
接下来从索引1减1等于0处,即元素3开始与其左右孩子比较,比较后父节点3与左孩子节点9交换,如下所示:
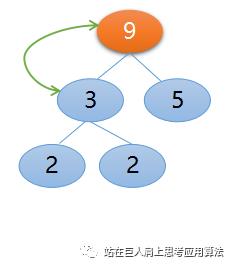
因为索引等于 0 了,所以构建堆结束,得到大根堆,第一步工作结束,下面开始第二步调整堆,也就是不断地交换堆顶节点和未排序区的最后一个元素,然后再构建大根堆,下面开始这步操作,交换栈顶元素9(如上图所示)和未排序区的最后一个元素2,如下图所示,现在排序区9成为了第一个归位的,
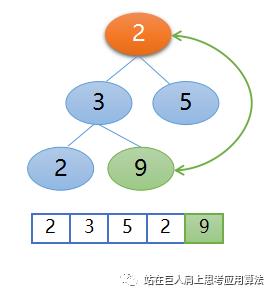
接下来拿掉元素9,未排序区变成了2,3,5,2,然后从堆顶2开始进行堆的再构建,比较父节点2与左右子节点3和5,父节点2和右孩子5交换位置,如下图所示,这样就再次得到了大根堆,
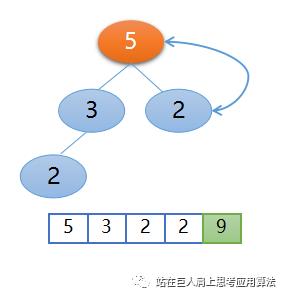
再交换堆顶5和未排序区的最后一个元素2,这样5又就位了,这样未排序区变为了2,3,2,已排序区为 5,9,交换后的位置又破坏了大根堆,已经不再是大根堆了,如下图所示,
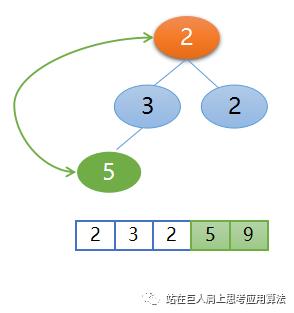
所以需要再次调整,然后堆顶2和左孩子3交换,交换后的位置如下图所示,这样二叉树又重新变为了大根堆,再把堆顶3和此时最后一个元素也就是右孩子2交换,
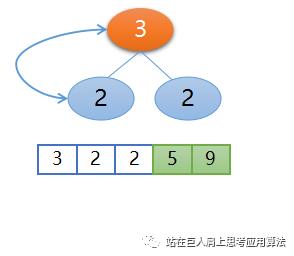
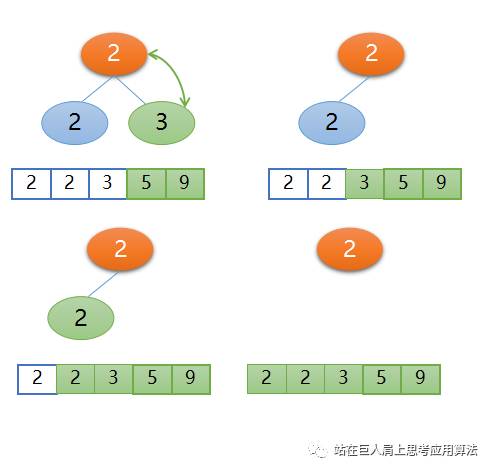
接下来再构建堆,不再赘述,见下图。
算法评价
堆排序的时间,主要由建立初始堆和反复重建堆这两部分的时间开销构成,堆排序的平均时间复杂度是O(nlogn) 。堆排序是就地排序,空间复杂度为O(1)。
通过上面的例子,可以看到两个关键码2的相对位置会发生变化,所以堆排序是不稳定的排序方法。
由于建初始堆所需的比较次数较多,所以堆排序不适宜于记录数较少的文件。
06
—
总结
直接排序算法是时间复杂度为O(n^2)的不稳定排序算法,为了改进它的时间复杂度,flody等人借助二叉树的形,巧妙地选择最值,通过堆这种逻辑结构,将时间复杂度提升到了O(nlogn)。
因此,同样是选择排序的算法,直接选择和堆选择时间差别还是不小,但是堆排序算法不大适宜数据量较少的情况,因为光构建初始堆就要进行很多次比较。
接下来,总结插入算法涉及的直接插入排序和希尔排序,加油!
以上是关于直接选择排序到堆排序做的那些改进的主要内容,如果未能解决你的问题,请参考以下文章