免费毕设ASP.NET基于Ajax+Lucene构建搜索引擎的设计和实现(源代码+论文)
Posted 帮我毕业网
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了免费毕设ASP.NET基于Ajax+Lucene构建搜索引擎的设计和实现(源代码+论文)相关的知识,希望对你有一定的参考价值。



4.1 搜索引擎模型
模型包括爬虫、索引生成、查询以及系统配置部分。爬虫包括:网页抓取模块、网页减肥模块、爬虫维持模块。索引生成包括:基于文本文件的索引、基于数据库的索引。查询部分有Ajax、后台处理、前台界面模块。如图4所示。
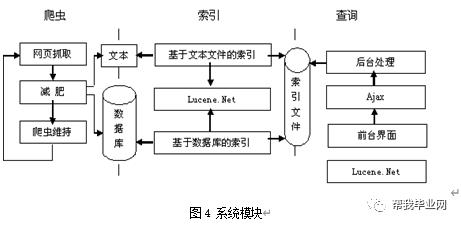
4.2 数据库的设计
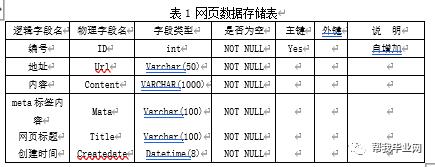
本课题包含一张用于存放抓取回来的网页信息如表1。
4.3模块设计
该模型按照功能划分为三个部分,一是爬虫抓取网页部分,二是从数据库建立索引部分,三是从前台页面查询部分。系统的功能流程(如图5.1和5.2)。
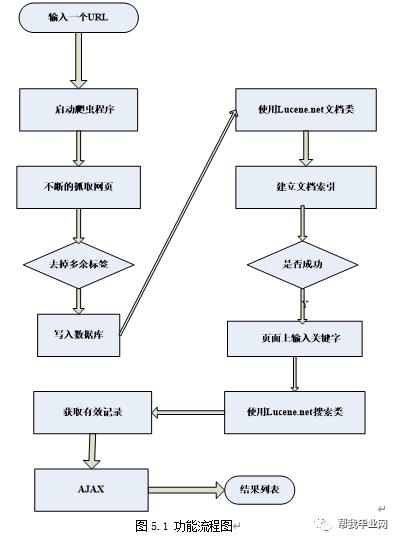
该系统用3个模块来实现搜索引擎的主要功能。流程如上图所示。
让爬虫程序能继续运行下去,就得抓取这个网页上的其它URL,所以要用正则将这个网页上的所有URL都取出来放到一个队列里。用同样的方法继续抓取网页,这里将运用到多线程技术。
为了对文档进行索引,Lucene提供了五个基础的类,他们分别是Document,Field,IndexWriter,Analyzer,Directory Document是用来描述文档的,这里的文档可以指一个html页面,一封电子邮件,或者是一个文本文件。一个Document对象由多个Field对象组成的。可以把一个Document对象想象成数据库中的一个记录,而每个Field对象就是记录的一个字段。在一个文档被索引之前,首先需要对文档内容进行分词处理,这部分工作就是由Analyzer来做的。Analyzer类是一个抽象类,它有多个实现。针对不同的语言和应用需要选择适合的Analyzer。Analyzer把分词后的内容交给IndexWriter来建立索引。
所有的搜索引擎的目标都是为了用户查询。通过查询页面,输入关键字,提交给系统,程序就开始处理,最后把结果以列表的形式显示出来。在用Lucene的搜索引擎中,用到了Lucene提供的方法,可从所建立的索引文档中获得结果。
开发平台的选择:本系统的开发平台选择微软公司的.NET,开发工具采用ASP.NET。.NET是Microsoft面向Web服务的平台,由框架、Web服务、.NET企业服务器等几部分组成,提供涉及面较广、功能较全面的解决方案。数据库选择:根据需求分析选择了MSSQL Server 2000。
5.2 关键代码详解
5.2.1代码结构
如图6:
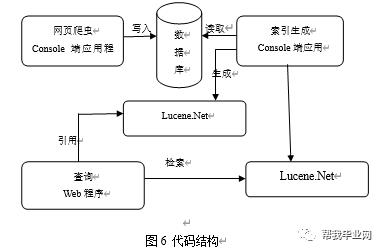
在网页爬虫Console端应用程序里输入一个有效的URL后这部份就开始从第一个URL开始遍历相关的链接并把相关的信息写入到网页数据存储数据库里,然后就由索引生成程序读取网页数据存储数据库,对每条记录生成索引记录,存放于生成的索引库文件里。生成索引需要调用Lucene.Net类。索引生成后在查询部分就能够在网页上输入关键字,对刚才抓取的信息的查询。并可以定位到信息的出处。下面对各部分关键代码进行详解。
这部份的功能就是从输入的URL开始遍历各个相关的网页,它包括三个功能模块:网页抓取模块、网页减肥模块、爬虫维持模块。
首先定义一些变量用于保存抓取到的网页信息,urlList用于保存当前页面上的URL集合。然后根据全局变量url抓取此URL的网页信息到字节流变量里,经过转码后读取到变量PageString里,下步通过函数GetHttpUrl(PageString)对PageString中的URL标记进行提取并返回到urlList变量里,函数GetTitle(PageString)、parseScript(PageString)、parseHtml(PageString)、parseChar(Content)分别对网页信息变量获取标题、去除脚本块、去除HTML标记、去除特殊字符操作。再下步就是对获取到的标题、网页内容、链接等信息调用数据库操作通用类DAI保存到数据库里,这就实现了一个网页的抓取。再下步就是循环的对获取到的URL列表创建线程,针对每个URL来循环的执行上面的网页信息的抓取操作。具体代码如下:
private staticvoid UrlThread()
{
String title="";
String Content="";
String mata="";
string URL="";
string[] urlArr = null;
StringBuilder urlList = newStringBuilder();
System.Net.WebClient Client=newSystem.Net.WebClient();
try
{
Streamstrm=null;
try
{//读取一个URL的信息到流变量里
Stream strm=Client.OpenRead(url);
}
catch
{
console.WriteLine("url无法找到!");
return;
}
StreamReadersr=new StreamReader(strm,Encoding.GetEncoding("gb2312"));
StringPageString=sr.ReadToEnd();//从流中读取网页信息到字符串变量中
strm.Close();
urlList= GetHttpUrl(PageString);
title=GetTitle(PageString);
Content= parseScript(PageString); //去掉脚本的网页文本
Content=parseHtml(PageString); //得到去了HTML标签的网页文本
URL=url;
mata="";
Content= parseChar(Content);
if((title!= "" || title != string.Empty) && URL != "")
{
DAI.RunSqlNonQuery("insert intoWebContent(url,content,title,mata) values('"+URL+"','"+Content+"','"+title+"','"+mata+"')");
Console.WriteLine("对url:"+URL+"相关信息写入数据库成功!");
}
else
{
Console.WriteLine("对url:"+URL+"相关信息写入数据库失败!");
}
urlArr=urlList.ToString().Split('|');
//对前面获取的URL列表循环的创建线程再执行本方法实现爬虫的维持
for(inti=0;i<urlArr.Length;i++)
{
url=urlArr[i];
if(url == "" || url == null ||url == string.Empty)
continue;
Thread th = new Thread(new ThreadStart(UrlThread));
th.Start();
}
}
catch{}
}
这部分包含对文本的索引生成以及对数据库数据的索引生成,下面只对数据库索引生成的关键代码进行介绍:
下面这段代码实现对数据库里存储的记录创建索引。主要通过Lucene提供的方法来协助实现。
publicIndexer(string indexDir)
{
#region Lucene Code
首先通过标准分词定义了一个索引写入器
IndexWriter writer = newIndexWriter(indexDir, new StandardAnalyzer(), true);
在创建索引库时,会合并多个Segments文件。此方式有助于减少索引文件数量,减少同时打开的文件数量。
writer.SetUseCompoundFile(false);
//删除以前生成的索引文件。
System.IO.Directory.Delete(iDexDir,true);
#endregion
DateTimestart = DateTime.Now;
DoIndexByDB(writer);//
DateTime end= DateTime.Now;
int docNum =writer.DocCount();
Console.WriteLine("IndexFinished. {0} Documents takes {1} second.",
docNum,((TimeSpan)(end - start)).TotalSeconds);
writer.Optimize();
writer.Close();
}
使用Lucene提供的方法对数据库中的每条记录建立索引实现如下:
Document doc= new Document();
Console.WriteLine("Indexing{0} ", row["title"].ToString());
doc.Add(Field.Text("contents",row["content"].ToString()));
doc.Add(Field.Keyword("title",row["title"].ToString()));
doc.Add(Field.Keyword("mata",row["mata"].ToString()));
doc.Add(Field.Keyword("CreateDate",row["CreateDate"].ToString()));
doc.Add(Field.Keyword("Url",row["Url"].ToString()));
doc.Add(Field.Keyword("ID",row["ID"].ToString()));
writer.AddDocument(doc);
5.2.4页面查询
这部分主要完成的功能是获取前台表单中输入的关键字,在程序中获取查询结果,最后把列表显示在前台页面。
Ajax在此部分中被使用到,它完成的功能是部分刷新页面,不需整个页面的重新加载。为了方便的在程序中使用Ajax,此系统引用了封装完善的Ajax类库。在程序中注册后,在html里就可以使用javascript来调用后台的程序。选取部分代码来说明:
首先在页面后台程序中进行Ajax注册,代码如下:
private voidPage_Load(object sender, System.EventArgs e)
{
//ajax注册
AjaxPro.Utility.RegisterTypeForAjax(typeof(Search));
}
如果前台Javascript需要调用某个方法,那就在那个函数前加上[AjaxPro.AjaxMethod],表示此方法属于ajax应用。
[AjaxPro.AjaxMethod]
publicstring SearchResult(string keywords,string pageNo)
{
其中,前台所存在的文字的代码如下:
StringBuilder sb = new StringBuilder();
sb.Append("<tr><td>结果数:"+result+" 所用时间:"+t+"毫秒</td></tr>");
前台显示结果记录的代码,动态生成table标签,如下:
for(int i = startNum ; i < endNum;i++)
{
在显示内容中,仍然使用到了Lucene提供的类,可以方便的从所建立的索引文档中获取网址,网页标题,内容,时间。
Document doc = hits.Doc(i);
content=doc.Get("contents");
content=content.Replace(keywords,"<fontcolor=red>"+keywords+"</font>");
sb.Append("<trclass="+c+">");
sb.Append("<td><ahref="+doc.Get("Url")+">"+doc.Get("title")+"</a></td>");
sb.Append("</tr>");
sb.Append("<trclass="+c+">");
sb.Append("<td>"+content+"<br>"+doc.Get("CreateDate")+"</td>");
sb.Append("</tr>");
}
}



详情请关注小编继续了解,免费赠送源代码与论文哦!
计算机毕业设计(源程序+论文+开题报告+文献综述+翻译+答辩稿)
联系QQ:2932963541进行咨询
以上是关于免费毕设ASP.NET基于Ajax+Lucene构建搜索引擎的设计和实现(源代码+论文)的主要内容,如果未能解决你的问题,请参考以下文章
毕设作品基于Ajax+Lucene构建搜索引擎的设计与实现(源代码+论文)免费下载
免费毕设asp.net基于工作流引擎的系统框架设计开发(源代码+论文)
毕设作品asp.net基于工作流引擎的系统框架设计开发(源代码+论文)免费下载
论文参考基于Ajax+Lucene构建搜索引擎的设计与实现(源代码+论文)免费下载