论文参考基于Ajax+Lucene构建搜索引擎的设计与实现(源代码+论文)免费下载
Posted 计算机校园角
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文参考基于Ajax+Lucene构建搜索引擎的设计与实现(源代码+论文)免费下载相关的知识,希望对你有一定的参考价值。
目录:

需求分析:
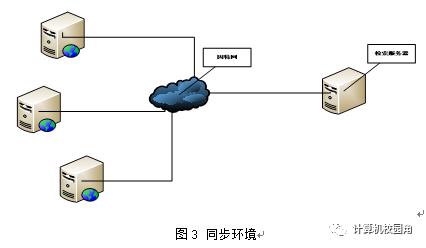
3.1 同步环境
4 方案设计
结合前面的同步原理,以及需求的介绍,下面给出同步的方案设计。
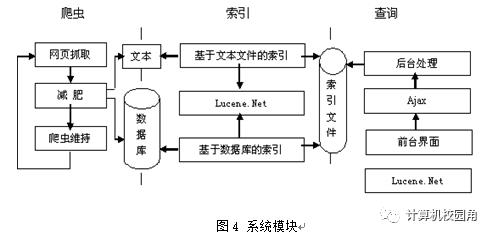
4.1 搜索引擎模型
4.2 数据库的设计
本课题包含一张用于存放抓取回来的网页信息如表1。
表1 网页数据存储表
逻辑字段名 |
物理字段名 |
字段类型 |
是否为空 |
主键 |
外键 |
说 明 |
编号 |
ID |
int |
NOT NULL |
Yes |
自增加 |
|
Url |
Varchar(50) |
NOT NULL |
||||
内容 |
Content |
VARCHAR(1000) |
NOT NULL |
|||
meta标签内容 |
Mata |
Varchar(100) |
NOT NULL |
|||
网页标题 |
Title |
Varchar(100) |
NOT NULL |
|||
创建时间 |
Createdate |
Datetime(8) |
NOT NULL |
5.2.2爬虫部分
这部分的功能就是从输入的URL开始遍历各个相关的网页,它包括三个功能模块:网页抓取模块、网页减肥模块、爬虫维持模块。
首先定义一些变量用于保存抓取到的网页信息,urlList用于保存当前页面上的URL集合。然后根据全局变量url抓取此URL的网页信息到字节流变量里,经过转码后读取到变量PageString里,下步通过函数GetHttpUrl(PageString)对PageString中的URL标记进行提取并返回到urlList变量里,函数GetTitle(PageString)、parseScript(PageString)、parsehtml(PageString)、parseChar(Content)分别对网页信息变量获取标题、去除脚本块、去除HTML标记、去除特殊字符操作。再下步就是对获取到的标题、网页内容、链接等信息调用数据库操作通用类DAI保存到数据库里,这就实现了一个网页的抓取。再下步就是循环的对获取到的URL列表创建线程,针对每个URL来循环的执行上面的网页信息的抓取操作。具体代码如下:
private staticvoid UrlThread()
{
String title="";
String Content="";
String mata="";
string URL="";
string[] urlArr = null;
StringBuilder urlList = newStringBuilder();
System.Net.WebClient Client=newSystem.Net.WebClient();
try
{
Streamstrm=null;
try
{//读取一个URL的信息到流变量里
Stream strm=Client.OpenRead(url);
}
catch
{
console.WriteLine("url无法找到!");
return;
}
StreamReadersr=new StreamReader(strm,Encoding.GetEncoding("gb2312"));
StringPageString=sr.ReadToEnd();//从流中读取网页信息到字符串变量中
strm.Close();
urlList= GetHttpUrl(PageString);
title=GetTitle(PageString);
Content= parseScript(PageString); //去掉脚本的网页文本
Content=parseHtml(PageString); //得到去了HTML标签的网页文本
URL=url;
mata="";
Content= parseChar(Content);
if((title!= "" || title != string.Empty) && URL != "")
{
DAI.RunSqlNonQuery("insertinto WebContent(url,content,title,mata) values('"+URL+"','"+Content+"','"+title+"','"+mata+"')");
Console.WriteLine("对url:"+URL+"相关信息写入数据库成功!");
}
else
{
Console.WriteLine("对url:"+URL+"相关信息写入数据库失败!");
}
urlArr=urlList.ToString().Split('|');
//对前面获取的URL列表循环的创建线程再执行本方法实现爬虫的维持
for(inti=0;i<urlArr.Length;i++)
{
url=urlArr[i];
if(url == "" || url == null ||url == string.Empty)
continue;
Thread th = new Thread(new ThreadStart(UrlThread));
th.Start();
}
}
catch{}
}
END
联系我
获取更多资源
学习更上一层楼
以上是关于论文参考基于Ajax+Lucene构建搜索引擎的设计与实现(源代码+论文)免费下载的主要内容,如果未能解决你的问题,请参考以下文章