热点缓存—30W以上并发热点缓存,如何优化你的缓存架构
Posted 蟋蟀得不像砖家派
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了热点缓存—30W以上并发热点缓存,如何优化你的缓存架构相关的知识,希望对你有一定的参考价值。
什么是缓存集群、什么是热点缓存
当一个系统需要用内存支撑用户访问来取代磁盘支撑的时候,最好的方式就是用缓存,缓存架构有很多种,
单点缓存、分布式缓存[基于全量分布式多节点、基于数据规则拆分均匀节点]、基于读写分摊的多主多从分布式缓存。
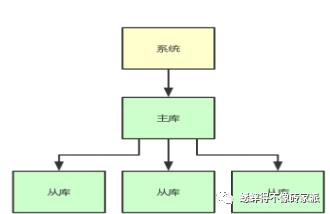
如下图,就是一个简单的分布式缓存轮廓图。
缓存集群的并发能力是很高的,而且读缓存的性能也是很高的,举一个例子:
如果每秒有2W个请求,其中80%都是读请求,那么每秒1.6W请求都是在读取一些变化度不是很高的数据,而不是更新数据。那么可以基于以下的方式来进行缓存集群构建【用从库来扛读请求,主库进行写】
(不过存在写单点,后续可以基于多主多从)
回到热点缓存上,当出现大量用户访问同一条缓存数据时。此时就出现热点问题了,譬如
某明星出轨导致新浪服务器崩溃,就是一个典型的热点缓存问题。【每秒都有超过上千万的用户去查某明星跟某某的出轨新闻数据...】
那么这条新闻就是一个缓存。假设这条数据是按照规则存放在某一个服务器里面,此时就会存在一台缓存机器瞬间流量大增。资源利用率飙高的风险。
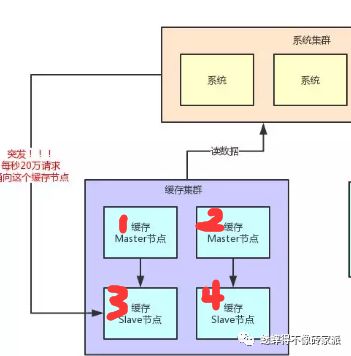
如果此时3号服务器出现了宕机,对于读取端发现读不到数据,就会从DB进行回填元数据。然后此数据会回填到4号机器上,那么下一波读取流量来后,4号机器也会出现3号服务器的情况,最终 DB和缓存服务器都趴了,此时系统全盘崩溃。呵呵...
怎么解决热点缓存问题?
首先,出现问题不可怕,可怕在发生之前能发现它,并对之进行干预,然后采取快速操作。
那么我们如何发现热点缓存数据呢。
一般出现缓存热点问题时,对于网络入口web层所有请求URL肯定是很高的,那么可以在此处进行URL统计,设定一个阀值,当某个URL读取请求大于这个阀值时,采取措施。
此时就有两个操作:
1,有损干预操作:限流、直接返回某静态数据等等
2,无损干预操作:当发现某条热点数据后,启动应用端本地缓存方式进行加载,并随机设置某个范围的过期时间,此时分布式多应用端的本地缓存直接进行召回。减少分布式缓存的压力。为何要“随机设置过期时间”?各位可以想想...
还有一种解决思路,当识别到热点数据的时候,此时守护进程或其他应用快速把此条数据进行副本部署,请求路由适配到基于规则的方式来进行缓存节点命中。【复杂度较高】
总结:
缓存设计千万种,实现复杂的缓存热点优化架构,还需要看你们的系统有没有这种场景。
但是如果没有的话,别过度设计,不然会出现其他更加复杂的问题。
架构是需要平衡的,满足当前场景和未来可扩展场景前提下设计架构是一种比较靠谱的方法。
以上是关于热点缓存—30W以上并发热点缓存,如何优化你的缓存架构的主要内容,如果未能解决你的问题,请参考以下文章