如何优化缓存中百万级并发的KEY
Posted 奋斗吧_攻城狮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何优化缓存中百万级并发的KEY相关的知识,希望对你有一定的参考价值。
引言
这个问题实际上就是热点key问题,其实热点key问题说来也很简单,就是瞬间有几十万上百万,甚至更大的请求去访问redis上某个固定的key,从而压垮缓存服务的情情况。
其实生活中也是有不少这样的例子,比如XX明星结婚。那么关于XX明星的Key就会瞬间增大,就会出现热点数据问题。PS:hot key和big key问题,大家一定要有所了解,非常重要。
本文预计分为如下几个部分:
-
热点key问题
-
如何发现
-
业内方案
正文
热点Key问题
上面提到,所谓热点key问题就是,突然有几十万甚至更大的请求去访问redis上的某个特定key。那么,这样会造成流量过于集中,达到Redis单实例瓶颈(一般是10W OPS级别),或者物理网卡上限,从而导致这台redis的服务器Hold不住。
那接下来这个key的请求,就会压垮你的服务。
怎么发现热key
方法一:凭借业务经验,进行预估哪些是热key
其实这个方法还是挺有可行性的。比如某商品在做秒杀,那这个商品的key就可以判断出是热key。缺点很明显,并非所有业务都能预估出哪些key是热key。
方法二:在客户端进行收集
这个方式就是在操作redis之前,加入一行代码进行数据统计。那么这个数据统计的方式有很多种,也可以是给外部的通讯系统发送一个通知信息。缺点就是对客户端代码造成入侵。
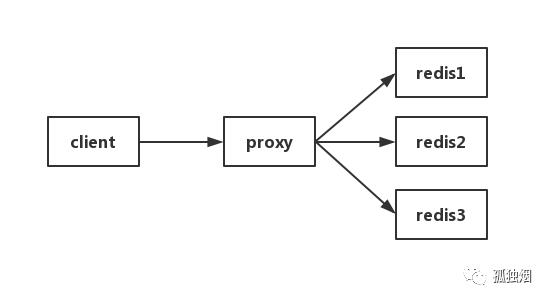
方法三:在Proxy层做收集
有些集群架构是下面这样的,Proxy可以是Twemproxy,是统一的入口。可以在Proxy层做收集上报,但是缺点很明显,并非所有的redis集群架构都有proxy。
方法四:用redis自带命令
(1)monitor命令,该命令可以实时抓取出redis服务器接收到的命令,然后写代码统计出热key是啥。当然,也有现成的分析工具可以给你使用,比如redis-faina。但是该命令在高并发的条件下,有内存增暴增的隐患,还会降低redis的性能。
(2)hotkeys参数,redis 4.0.3提供了redis-cli的热点key发现功能,执行redis-cli时加上–hotkeys选项即可。但是该参数在执行的时候,如果key比较多,执行起来比较慢。
方法五:自己抓包评估
Redis客户端使用TCP协议与服务端进行交互,通信协议采用的是RESP。自己写程序监听端口,按照RESP协议规则解析数据,进行分析。缺点就是开发成本高,维护困难,有丢包可能性。
以上五种方案,各有优缺点。根据自己业务场景进行抉择即可。那么发现热key后,如何解决呢?
如何解决
目前业内的方案有两种:
(1)二级缓存(推荐)
比如利用ehcache,或者guava-cache,或者一个HashMap或者List都可以。在你发现热key以后,把热key加载到JVM中(可以是堆内,也可以是堆外)。针对这种热key请求,会直接从JVM中取,而不会走到redis层。
假设此时有十万个针对同一个key的请求过来,如果没有本地缓存,这十万个请求就直接怼到同一台redis上了。现在假设,你的应用层有10台机器,OK,你也有jvm缓存了。这十万个请求平均分散开来,每个机器有10000个请求,会从JVM中取到value值,然后返回数据。避免了十万个请求怼到同一台redis上的情形。
(2)备份热点key
这个方案也很简单。不要让key走到同一台redis上不就行了。我们把这个key,在多个redis上都存一份不就好了。接下来,有热key请求进来的时候,我们就在有备份的redis上随机选取一台,进行访问取值,返回数据。
假设redis的集群数量为N,步骤如下图所示:
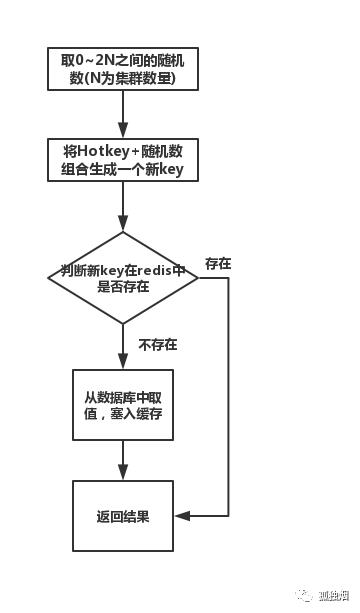
说明: 不一定是2N,你想取4N,8N都可以,看要求。伪代码如下:
const M = N * 2
//生成随机数
random = GenRandom(0, M)
//构造备份新key
bakHotKey = hotKey + “_” + random
data = redis.GET(bakHotKey)
if data == NULL
data = GetFromDB()
redis.SET(bakHotKey, expireTime + GenRandom(0,5))
说明:这种方案有一个很明显的缺点,就是缓存的维护代价非常大。假设有100个备份KEY,那么在删除或者更新时,也需要更新100个KEY,所以这种方案不是很推荐。
业内方案
OK,其实看完上面的内容,大家可能会有一个疑问。
有办法在项目运行过程中,自动发现热点key,然后程序自动处理么?
嗯,好问题,那我们来讲讲业内怎么做的。其实只有两步:
-
监控热点key
-
通知系统做处理
正巧,前几天有赞出了一篇《有赞透明多级缓存解决方案(TMC)》,里头也有提到热点key问题,我们刚好借此说明。
(1) 监控热点key
在监控热点key方面,有赞用的是方式二:在客户端进行收集。
在《有赞透明多级缓存解决方案(TMC)》中有一句话提到
TMC 对原生jedis包的JedisPool和Jedis类做了改造,在JedisPool初始化过程中集成TMC“热点发现”+“本地缓存”功能Hermes-SDK包的初始化逻辑。
也就说人家改写了jedis原生的jar包,加入了Hermes-SDK包。
那Hermes-SDK包用来干嘛?
OK,就是做热点发现和本地缓存。
从监控的角度看,该包对于Jedis-Client的每次key值访问请求,Hermes-SDK 都会通过其通信模块将key访问事件异步上报给Hermes服务端集群,以便其根据上报数据进行“热点探测”。
当然,这只是其中一种方式,有的公司在监控方面用的是方式五: 自己抓包评估。具体是这么做的,先利用flink搭建一套流式计算系统。然后自己写一个抓包程序抓redis监听端口的数据,抓到数据后往kafka里丢。
接下来,流式计算系统消费kafka里的数据,进行数据统计即可,也能达到监控热key的目的。
(2) 通知系统做处理
在这个角度,有赞用的是上面的解决方案一:利用二级缓存进行处理。
有赞在监控到热key后,Hermes服务端集群会通过各种手段通知各业务系统里的Hermes-SDK,告诉他们:"老弟,这个key是热key,记得做本地缓存。"
于是Hermes-SDK就会将该key缓存在本地,对于后面的请求。Hermes-SDK发现这个是一个热key,直接从本地中拿,而不会去访问集群。
除了这种通知方式以外。我们也可以这么做,比如你的流式计算系统监控到热key了,往zookeeper里头的某个节点里写。然后你的业务系统监听该节点,发现节点数据变化了,就代表发现热key。最后往本地缓存里写,也是可以的。
通知方式各种各样,大家可以自由发挥。本文只是提供一个思路。
总结
希望通过本文,大家明白如何处理生产上遇到的热key问题。
以上是关于如何优化缓存中百万级并发的KEY的主要内容,如果未能解决你的问题,请参考以下文章