缓存策略了解一下(完整版)
Posted 二进制人生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了缓存策略了解一下(完整版)相关的知识,希望对你有一定的参考价值。
内容整理自网络,如有侵权联系删除。
前言
缓存就是数据交换的缓冲区(称作:Cache)。
缓存这个概念最初应该诞生于硬件。比如众所周知,高速缓存是用来协调CPU与主存之间存取速度的差异而设置的。一般CPU工作速度高,但内存的工作速度相对较低,为了解决这个问题,通常使用高速缓存,高速缓存的存取速度介于CPU与主存之间。系统将一些CPU在最近几个时间段经常访问的内容存在高速缓存,这样就在一定程度上缓解了由于主存速度低造成的CPU“停工待料”的情况。
软件意义的缓存是指:
通过在内存中存储被访问过的数据(或者运算结果)供后续访问时使用,以此来达到提速的效果。
软件意义上的缓存比如:
✔ 操作系统磁盘缓存 ——> 减少磁盘机械操作。
✔ 数据库缓存——>减少文件系统IO。
✔ 应用程序缓存——>减少对数据库的查询。
✔ Web服务器缓存——>减少应用服务器请求。
✔ 客户端浏览器缓存——>减少对网站的访问。
其实除了缓存的作用之外,缓存还有另外2个重要的运用方式:预读取和延迟写。
预读取
预读取就是预先读取将要载入的数据,也可以称作“缓存预热”,它是在系统中先将硬盘中的一部分数据加载到内存中,然后再对外提供服务。
如果说“预读取”是在“数据出口”加了一道前置的缓冲区的话,那么下面要说的“延迟写”就是在“数据入口”后面加了一道后置的缓冲区。
延迟写
它是预先将需要写入到磁盘或者数据库的数据,暂时写入到内存,然后就返回成功,再定时将内存中的数据批量写入到磁盘或者数据库。
举个我在实际工作中遇到的例子。
嵌入式设备的用户配置参数以xml的形式存于flash中,在开机启动时会将xml的数据读取到全局变量中。在用户进行配置时,先将参数写到全局变量,然后再跟新至xml。因为参数的读取是比较频繁的,如果每次都到flash中去读,会增加io开销。在这里,全局变量是在内存中的,相当于起到了缓存的作用,无形之中运用了缓存的思想。
正文
小刘今天去某大厂面试。
面试官:请做个自我介绍吧。
小刘:巴拉巴拉……
面试官:我们来聊聊缓存算法吧,你知道常用的缓存算法有哪些吗?
面试官:那你能给我讲讲FIFO的具体实现原理吗?
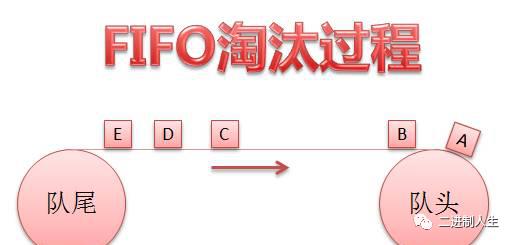
小刘:FIFO(First in First out),先进先出。在FIFO Cache设计中,核心原则就是:如果一个数据最先进入缓存中,则应该最早淘汰掉。新访问的数据插入FIFO队列尾部,数据在FIFO队列中顺序移动,在队列满的时候插入新数据,只能淘汰头部数据了。
面试官:你继续和我讲讲LRU算法。
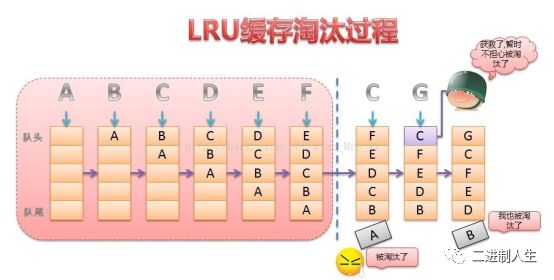
小刘:LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
面试官:同样讲讲具体实现。
小刘:
具体实现步骤
1、利用一个链表将要缓存的数据组织起来。
2、当来了新的数据之后遍历链表,查找它是否在链表里,如果没有,则添加到链表末尾,添加之前检查链表是否满了(缓存的数据量等于设定大小),满了则把链表头部数据删除。
3、如果待添加数据已经在链表里了,则将它移动到链表末尾
4、在访问数据的时候,如果链表中存在该数据的话,则返回对应的value值。
面试官:流程总结得很清晰,我问你几个问题。第一,你会选择单向链表还是双向链表?如果我使用双向链表有什么好处?
小刘心想,双向链表肯定比单向链表好,因为将新的数据添加到链表的末尾时可以通过头结点的前向指针快速找到链表尾结点,如果用单向链表的话还得从头遍历到尾部,浪费时间。
面试官:你这缓存算法效率并不高啊,我每次插入一个新的数据,还得遍历整个链表查找它是否已经在缓存里,这个操作的复杂度是O(n),你有什么改进方案,顺便写下伪代码。
小刘心想,只能借助哈希表了,这样可以做到O(1)的查找效率。所以他给出了下面的方案:
假设缓存的是key-value这样的值对数据。
struct list_head {
struct list_head *next, *prev;
};
typedef struct data{
char key[20];
char value[20];
struct list_head list;
}DATA;
我用结构体DATA表示一个key-value数据值对。
定义一个hashTable,里面有100条链表,插入一个数据时,根据它的key按照某种方法计算出一个index,这里将该方法记录为f,将其插入到head[f(key)]链表里头。
struct hashTable{
struct list_head data_head[100];
}htable;
严格上来说达不到O(1)的效率,因为哈希表的大小为100,计算出来的索引肯定会有冲突,导致每条链表上的元素个数可能会大于1。但相比于前面单纯用链表的实现方法,有了一定优化。
面试官内心:这小伙子还不错,对链表和哈希表有一定认识。继续考察下:你可以再对上面的算法做一些优化吗?
小刘问道:您指哪方面的优化?
面试官做了提示:当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
小刘:我知道了,您想说的是LRU-K算法。LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。LRU-K的主要目的是为了解决LRU算法“缓存污染”的问题,其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。
相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。只有当数据的访问次数达到K次的时候,才将数据放入缓存队列。当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据。
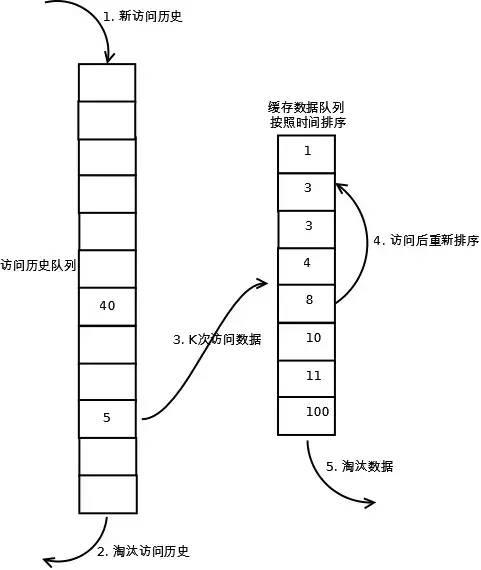
详细实现如下:
1. 数据第一次被访问,先查询是否在缓存队列里,没有则加入到访问历史队列的尾部;
2. 如果在缓存队列里,像处理LRU一样,将数据移动至缓存队列末尾
3. 如果添加新数据前,访问队列已经满了,可以将队列的头部数据(也就是最早访问的数据)删除。
4. 当队列中的数据访问次数达到K次后,将数据从历史队列迁移到缓存队列中。
5. 需要淘汰缓存数据时,淘汰缓存队列排在头部的数据,即:淘汰“倒数第K次访问离现在最久”的数据。
LRU-K具有LRU的优点,同时能够避免LRU的缺点,实际应用中LRU-2是综合各种因素后最优的选择,LRU-3或者更大的K值命中率会高,但需要容量更大的历史访问队列。
面试官:既然知道了LRU-K的优点,说说它的缺点吧。
小刘:由于LRU-K还需要记录那些被访问过、但还没有放入缓存的对象,因此内存消耗会比LRU要多;当数据量很大的时候,内存消耗会比较可观。由于维护了两个队列,算法复杂度也比较高。
穿插题外话
2Q算法
Two queues(以下使用2Q代替)算法类似于LRU-2,2Q算法有两个队列,一个是FIFO队列,一个是LRU队列。
实现
当数据第一次访问时,2Q算法将数据缓存在FIFO队列里面,当数据第二次被访问时,则将数据从FIFO队列移到LRU队列里面,两个队列各自按照自己的方法淘汰数据。详细实现如下:
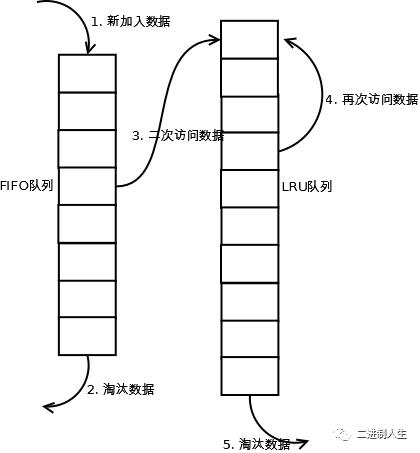
1. 新访问的数据插入到FIFO队列;
2. 如果数据在FIFO队列中一直没有被再次访问,则最终按照FIFO规则淘汰;
3. 如果数据在FIFO队列中被再次访问,则将数据移到LRU队列头部;
4. 如果数据在LRU队列再次被访问,则将数据移到LRU队列头部;
5. LRU队列淘汰末尾的数据。
注:上图中FIFO队列比LRU队列短,但并不代表这是算法要求,实际应用中两者比例没有硬性规定。
面试官内心:看来这小伙子有认真学习过,再考察一下。追问道:
面试官提示很明显,小刘稍作思考,心中有了答案:
您想说的是MQ算法,Multi Queue。MQ算法根据访问频率将数据划分为多个队列,不同的队列具有不同的访问优先级,其核心思想是:优先缓存访问次数多的数据。
它的具体实现:
如上图,算法详细描述如下:
1. 新插入的数据放入Q0;
2. 每个队列按照LRU管理数据;
3. 当数据的访问次数达到一定次数,需要提升优先级时,将数据从当前队列删除,加入到高一级队列的头部;
4. 为了防止高优先级数据永远不被淘汰,当数据在指定的时间里访问没有被访问时,需要降低优先级,将数据从当前队列删除,加入到低一级的队列头部;
5. 需要淘汰数据时,从最低一级队列开始按照LRU淘汰;每个队列淘汰数据时,将数据从缓存中删除,将数据索引加入Q-history头部;
6. 如果数据在Q-history中被重新访问,则重新计算其优先级,移到目标队列的头部;
7. Q-history按照LRU淘汰数据的索引。
MQ需要记录每个数据的访问时间,需要定时扫描所有队列,代价比LRU要高。
注:虽然MQ的队列看起来数量比较多,但由于所有队列之和受限于缓存容量的大小,因此这里多个队列长度之和和一个LRU队列是一样的,因此队列扫描性能也相近。
面试官:今天的面试就到这里结束,你有什么要问的吗?
小刘终于松了一口气,此刻他只想尽快溜之大吉。
补充
LFU(Least frequently used)其实现算法的原理根据数据的历史访问频率来进行数据淘汰。
其核心思想“如果数据过去被访问多次,那么将来被访问的频率也更高”。
LFU的每个数据块都有一个引用计数,所有数据块按照引用计数排序,具有相同引用计数的数据块则按照时间排序。
其具体实现步骤原理如下:
1. 新加入数据插入到队列尾部(因为引用计数为1);
2. 队列中的数据被访问后,引用计数增加,队列重新排序;
3. 当需要淘汰数据时,将已经排序的列表最后的数据删除。
以上是关于缓存策略了解一下(完整版)的主要内容,如果未能解决你的问题,请参考以下文章