彻底弄懂浏览器缓存策略
Posted QQ音乐前端团队
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了彻底弄懂浏览器缓存策略相关的知识,希望对你有一定的参考价值。
导语
浏览器缓存策略对于前端开发同学来说不陌生,大家都有一定的了解,但如果没有系统的归纳总结,可能三言两语很难说明白,甚至说错,尤其在面试过程中感触颇深,很多候选人对这类基础知识竟然都是一知半解,说出几个概念就没了,所以重新归纳总结一下,温故而知新
Web缓存介绍
Web缓存是指一个Web资源(如html页面,图片,js,数据等)存在于Web服务器和客户端(浏览器)之间的副本。
缓存会根据进来的请求保存输出内容的副本;当下一个请求来到的时候,如果是相同的URL,缓存会根据缓存机制决定是直接使用副本响应访问请求,还是向源服务器再次发送请求。
Web缓存的好处
减少网络延迟,加快页面打开速度
减少网络带宽消耗
降低服务器压力
...
HTTP的缓存机制
简化的流程如下
根据什么规则缓存
新鲜度(过期机制):也就是缓存副本有效期。一个缓存副本必须满足以下条件,浏览器会认为它是有效的,足够新的:
含有完整的过期时间控制头信息(HTTP协议报头),并且仍在有效期内;
浏览器已经使用过这个缓存副本,并且在一个会话中已经检查过新鲜度;
校验值(验证机制):服务器返回资源的时候有时在控制头信息带上这个资源的实体标签Etag(Entity Tag),它可以用来作为浏览器再次请求过程的校验标识。如果发现校验标识不匹配,说明资源已经被修改或过期,浏览器需求重新获取资源内容。
HTTP缓存的两个阶段
浏览器缓存一般分为两类:强缓存(也称本地缓存)和协商缓存(也称弱缓存)
本地缓存阶段
浏览器发送请求前,会先去缓存里查看是否命中强缓存,如果命中,则直接从缓存中读取资源,不会发送请求到服务器。否则,进入下一步。
协商缓存阶段
当强缓存没有命中时,浏览器一定会向服务器发起请求。服务器会根据Request Header中的一些字段来判断是否命中协商缓存。如果命中,服务器会返回304响应,但是不会携带任何响应实体,只是告诉浏览器可以直接从浏览器缓存中获取这个资源。如果本地缓存和协商缓存都没有命中,则从直接从服务器加载资源。
启用&关闭缓存
按照本地缓存阶段和协商缓存阶段分类: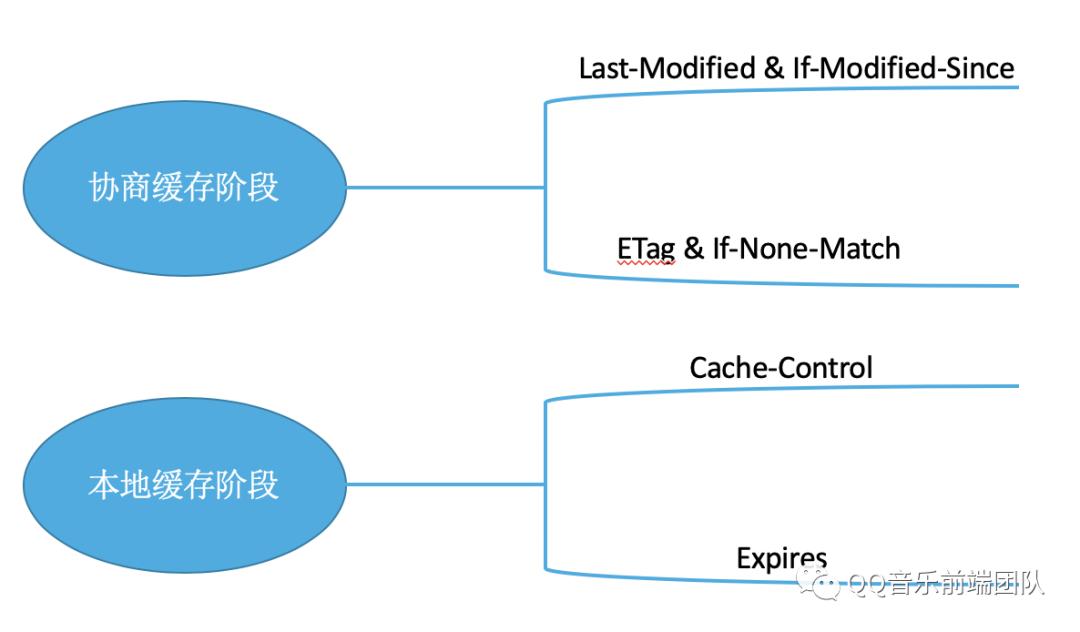
使用HTML Meta 标签
Web开发者可以在HTML页面的节点中加入标签,如下:
上述代码的作用是告诉浏览器当前页面不被缓存,事实上这种禁用缓存的形式用处很有限:a. 仅有IE才能识别这段meta标签含义,其它主流浏览器仅识别“Cache-Control: no-store”的meta标签。
b. 在IE中识别到该meta标签含义,并不一定会在请求字段加上Pragma,但的确会让当前页面每次都发新请求(仅限页面,页面上的资源则不受影响)。
使用缓存有关的HTTP消息报头这里需要了解HTTP的基础知识。一个URI的完整HTTP协议交互过程是由HTTP请求和HTTP响应组成的。有关HTTP详细内容可参考《Hypertext Transfer Protocol — HTTP/1.1》、《HTTP权威指南》等。
在HTTP请求和响应的消息报头中,常见的与缓存有关的消息报头有: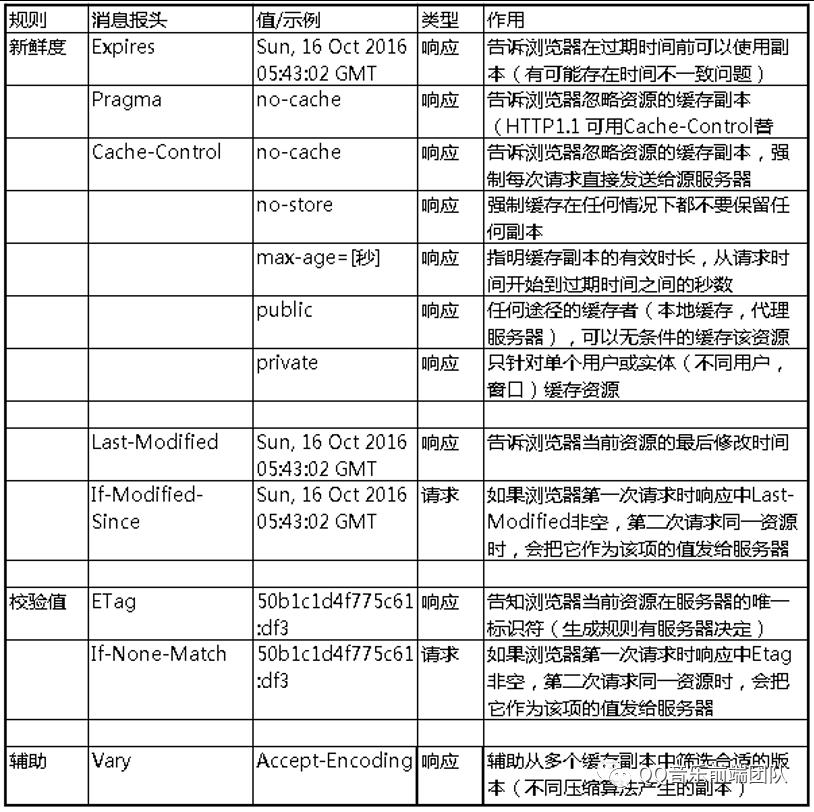
上图中只是常用的消息报头,下面来看下不同字段之间的关系和区别:
Cache-Control与Expires
max-age:功能和Expires类似,但是后面跟一个以“秒”为单位的相对时间,来供浏览器计算过期时间。
no-cache:提供了过期验证机制。
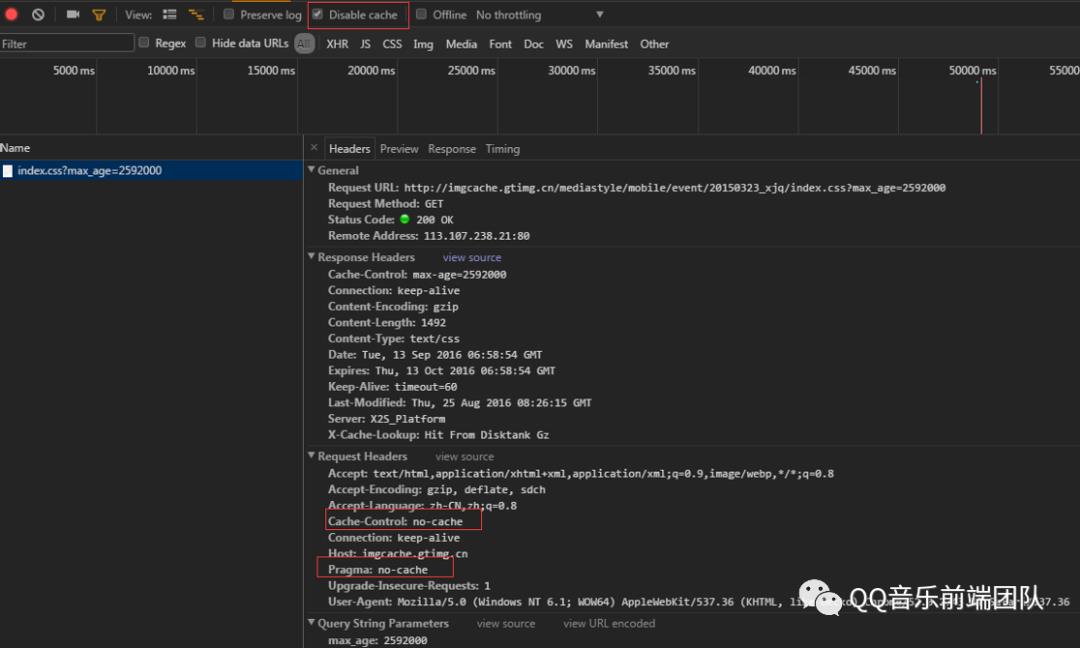 (在 Chrome 的 devtools中勾选 Disable cache 选项,发送的请求会去掉If-Modified-Since这个 Header。同时设置Cache-Control:no-cache Pragma:no-cache,每次请求均为200 )
(在 Chrome 的 devtools中勾选 Disable cache 选项,发送的请求会去掉If-Modified-Since这个 Header。同时设置Cache-Control:no-cache Pragma:no-cache,每次请求均为200 )no-store:表示当前请求资源禁用缓存。
public:表示缓存的版本可以被代理服务器或者其他中间服务器识别。
private:表示只有用户自己的浏览器能够进行缓存,公共的代理服务器不允许缓存。
Cache-Control:HTTP1.1提出的特性,为了弥补 Expires 缺陷加入的,提供了更精确细致的缓存功能。详细了解 详细看几个常见的指令:
Expires:HTTP1.0的特性,标识该资源过期的时间点,它是一个绝对值,格林威治时间(Greenwich Mean Time, GMT),即在这个时间点之后,缓存的资源过期
优先级:Cache-Control优先级高于Expires,为了兼容,通常两个头部同时设置
浏览器默认行为:其实就算Response Header中沒有设置Cache-Control和Expires,浏览器仍然会缓存某些资源,这是浏览器的默认行为,是为了提升性能进行的优化,每个浏览器的行为可能不一致,有些浏览器甚至没有这样的优化。
Last-Modified与ETag
Last-Modified(Response Header)与If-Modified-Since(Request Header)是一对报文头,属于http 1.0。If-Modified-Since是一个请求首部字段,并且只能用在GET或者HEAD请求中。Last-Modified是一个响应首部字段,包含服务器认定的资源作出修改的日期及时间。当带着If-Modified-Since头访问服务器请求资源时,服务器会检查Last-Modified,如果Last-Modified的时间早于或等于If-Modified-Since则会返回一个不带主体的304响应,否则将重新返回资源。
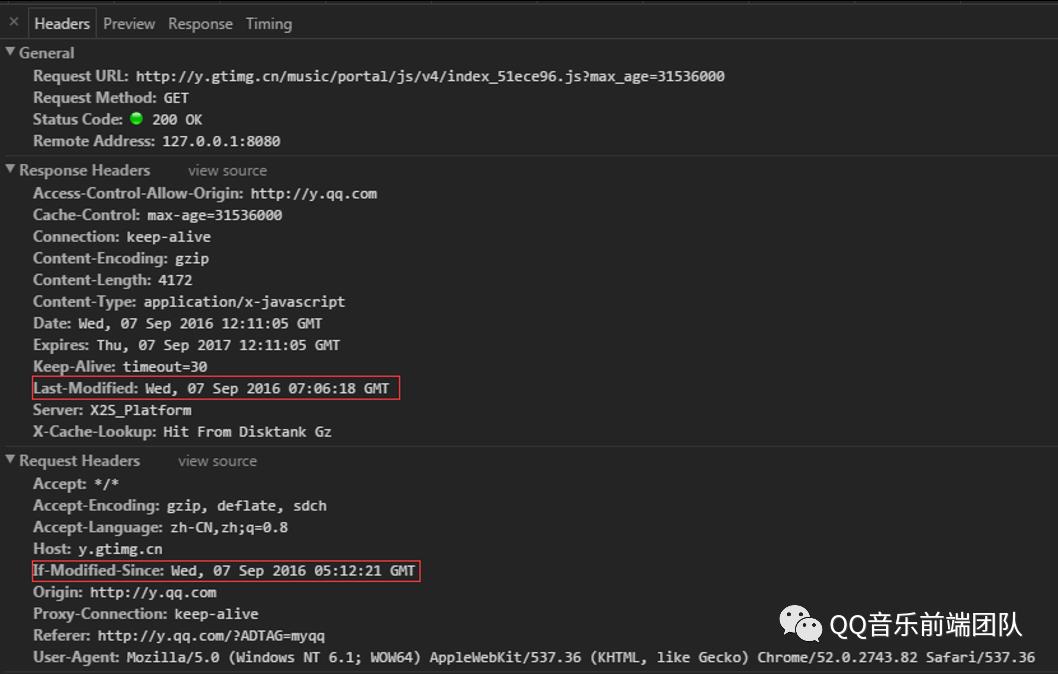 (注意:在 Chrome 的 devtools中勾选 Disable cache 选项后,发送的请求会去掉If-Modified-Since这个 Header。)
(注意:在 Chrome 的 devtools中勾选 Disable cache 选项后,发送的请求会去掉If-Modified-Since这个 Header。)ETag与If-None-Match是一对报文头,属于http 1.1。ETag是一个响应首部字段,它是根据实体内容生成的一段hash字符串,标识资源的状态,由服务端产生。If-None-Match是一个条件式的请求首部。如果请求资源时在请求首部加上这个字段,值为之前服务器端返回的资源上的ETag,则当且仅当服务器上没有任何资源的ETag属性值与这个首部中列出的时候,服务器才会返回带有所请求资源实体的200响应,否则服务器会返回不带实体的304响应。
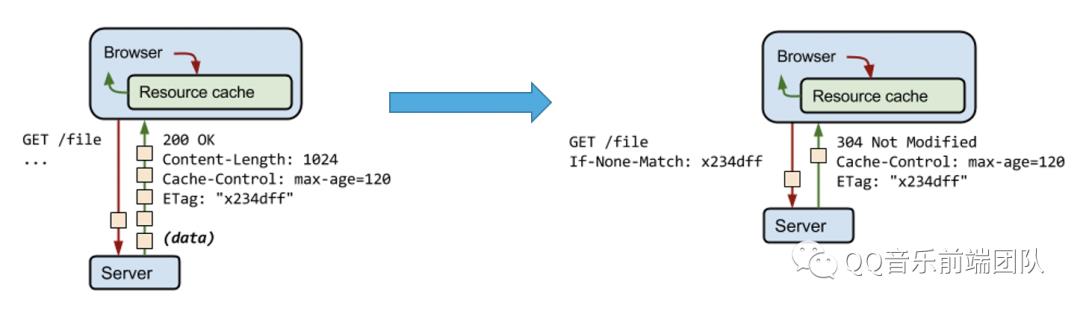
ETag能解决什么问题?
a. Last-Modified标注的最后修改只能精确到秒级,如果某些文件在1秒钟以内,被修改多次的话,它将不能准确标注文件的新鲜度
b. 某些文件也许会周期性的更改,但是他的内容并不改变(仅仅改变的修改时间),但Last-Modified却改变了,导致文件没法使用缓存
c. 有可能存在服务器没有准确获取文件修改时间,或者与代理服务器时间不一致等情形
优先级:ETag优先级比Last-Modified高,同时存在时会以ETag为准。
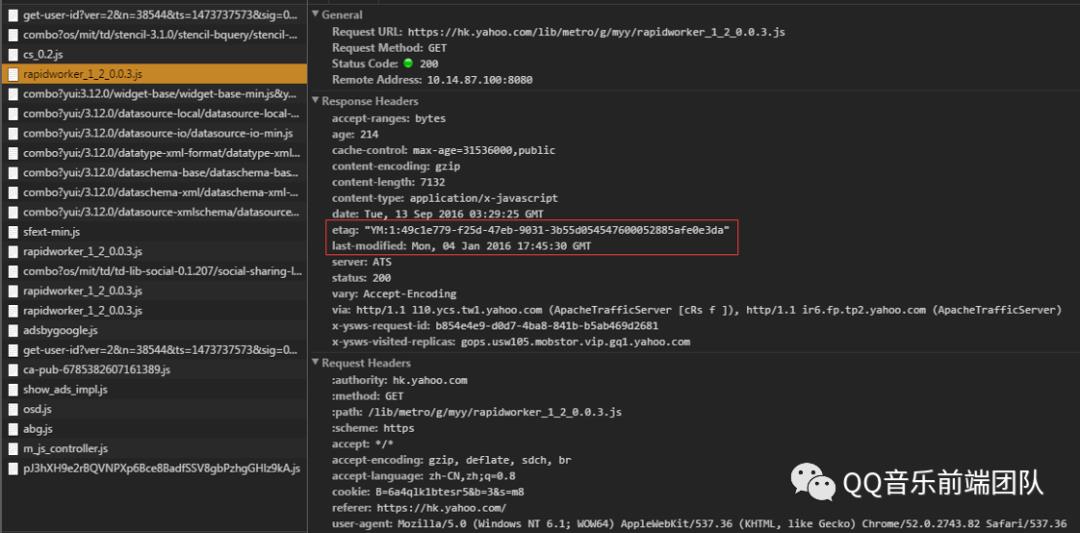
缓存位置
浏览器可以在内存、硬盘中开辟一个空间用于保存请求资源副本。我们经常调试时在DevTools Network里看到Memory Cache(內存缓存)和Disk Cache(硬盘缓存),指的就是缓存所在的位置。请求一个资源时,会按照优先级(Service Worker -> Memory Cache -> Disk Cache -> Push Cache)依次查找缓存,如果命中则使用缓存,否则发起请求。这里先介绍 Memory Cache 和 Disk Cache。
200 from memory cache
表示不访问服务器,直接从内存中读取缓存。因为缓存的资源保存在内存中,所以读取速度较快,但是关闭进程后,缓存资源也会随之销毁,一般来说,系统不会给内存分配较大的容量,因此内存缓存一般用于存储较小文件。同时内存缓存在有时效性要求的场景下也很有用(比如浏览器的隐私模式)。
200 from disk cache
表示不访问服务器,直接从硬盘中读取缓存。与内存相比,硬盘的读取速度相对较慢,但硬盘缓存持续的时间更长,关闭进程之后,缓存的资源仍然存在。由于硬盘的容量较大,因此一般用于存储大文件。
下图可清晰看出差别: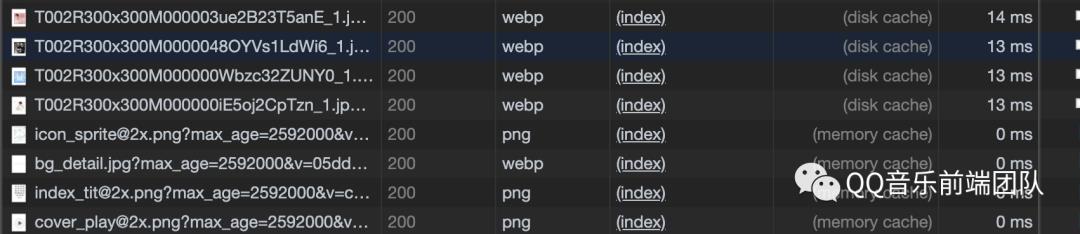
200 from prefetch cache
在preload或prefetch的资源加载时,两者也是均存储在http cache,当资源加载完成后,如果资源是可以被缓存的,那么其被存储在http cache中等待后续使用;如果资源不可被缓存,那么其在被使用前均存储在memory cache;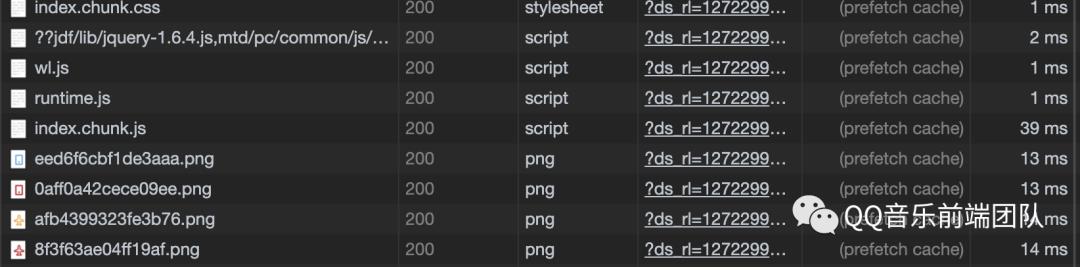
CDN Cache
以腾讯CDN为例 X-Cache-Lookup:Hit From MemCache 表示命中CDN节点的内存 X-Cache-Lookup:Hit From Disktank 表示命中CDN节点的磁盘 X-Cache-Lookup:Hit From Upstream 表示没有命中CDN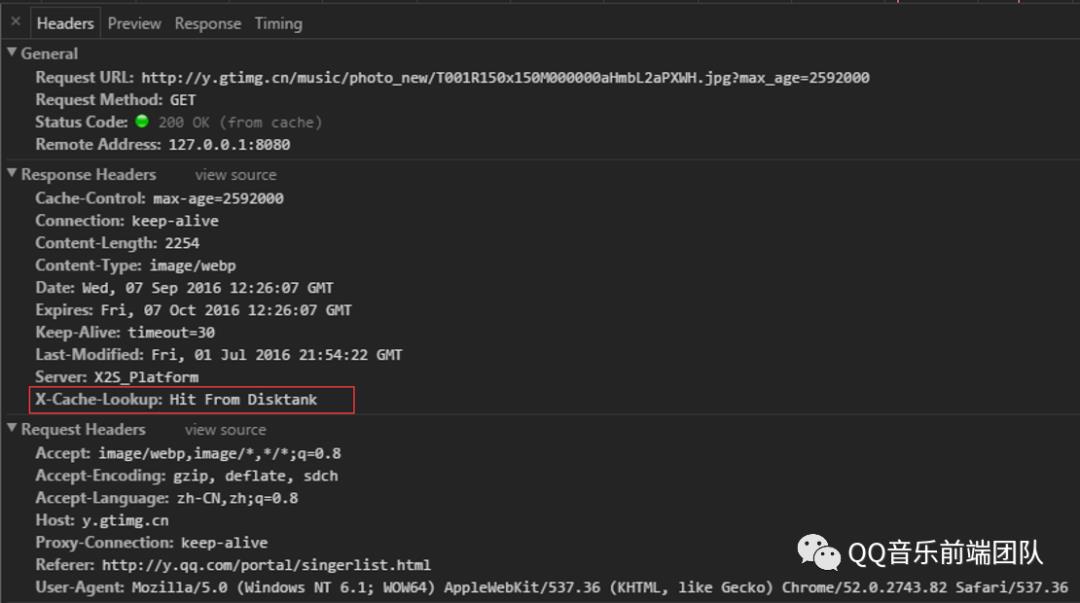
整体流程
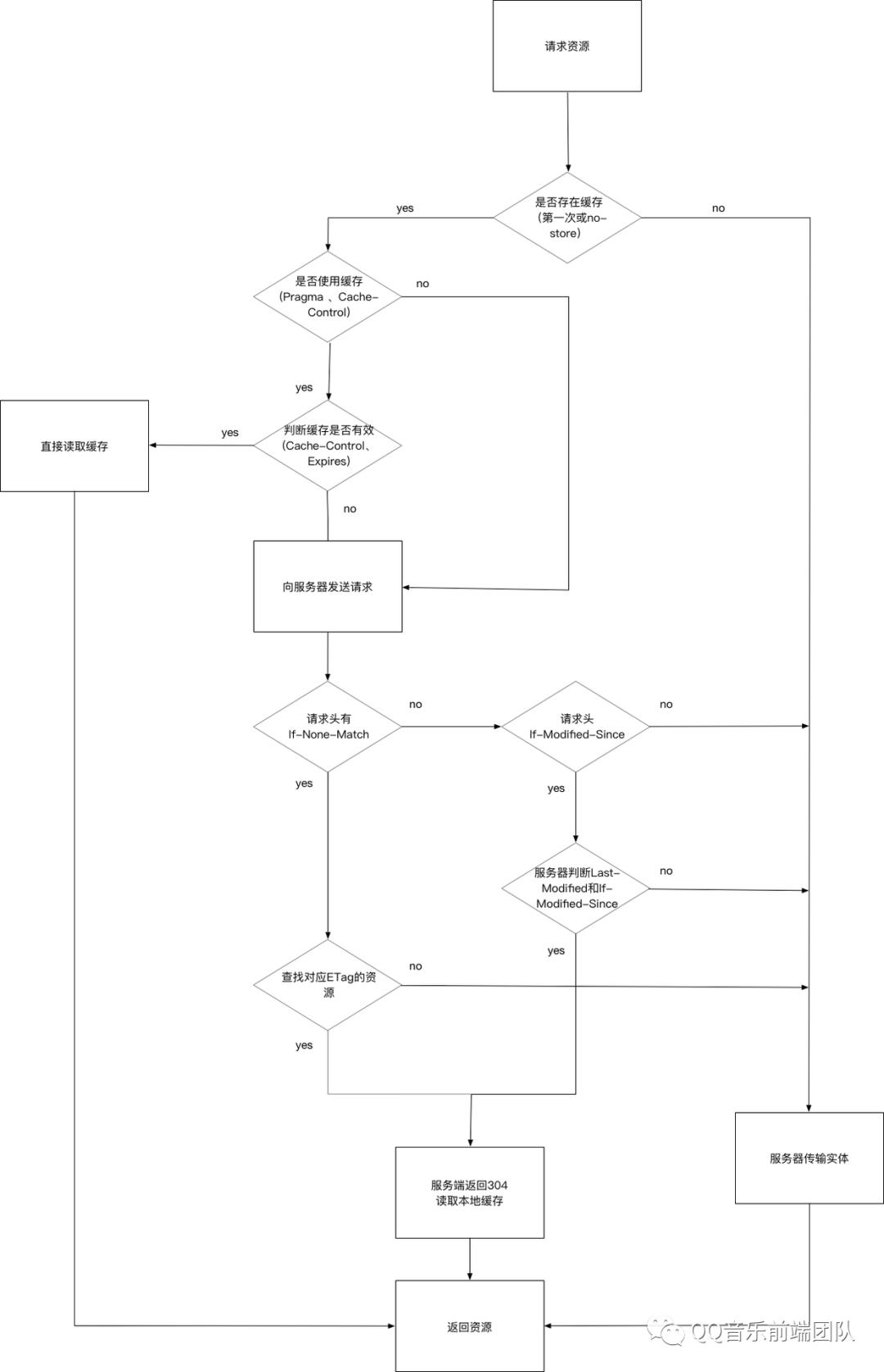
从上图能感受到整个流程,比如常见两种刷新场景:
当 F5 刷新网页时,跳过强缓存,但是会检查协商缓存;
当 Ctrl + F5 强制刷新页面时,直接从服务器加载,跳过强缓存和协商缓存
其他Web缓存策略
IndexDB
IndexedDB 就是浏览器提供的本地数据库,能够在客户端存储可观数量的结构化数据,并且在这些数据上使用索引进行高性能检索的API。异步 API 方法调用完后会立即返回,而不会阻塞调用线程。要异步访问数据库,要调用 window 对象 indexedDB 属性的 open() 方法。该方法返回一个 IDBRequest 对象 (IDBOpenDBRequest);异步操作通过在 IDBRequest 对象上触发事件来和调用程序进行通信。常用异步API如下:在16年曾基于IndexDB做过一整套缓存策略,有不错的优化效果
Service Worker
SW从2014年提出的草案到现在已经发展很成熟了,基于SW做离线缓存,让用户能够进行离线体验,消息推送体验,离线缓存能力涉及到Cache和CacheStorage的概念,篇幅有限,不展开了
LocalStorage
localStorage 属性允许你访问一个 Document 源(origin)的对象 Storage 用于存储当前源的数据,除非用户人为清除(调用 localStorage api 或则清除浏览器数据), 否则存储在 localStorage 的数据将被长期保留
SessionStorage
sessionStorage 属性允许你访问一个 session Storage 对象,用于存储当前会话的数据,存储在 sessionStorage 里面的数据在页面会话结束时会被清除。页面会话在浏览器打开期间一直保持,并且重新加载或恢复页面仍会保持原来的页面会话。
定义最优缓存策略
使用一致的网址:如果您在不同的网址上提供相同的内容,将会多次获取和存储该内容。注意:URL区分大小写!。
确定中继缓存可以缓存哪些资源:对所有用户的响应完全相同的资源很适合由 CDN 或其他中继缓存进行缓存。
确定每个资源的最优缓存周期:不同的资源可能有不同的更新要求。审查并确定每个资源适合的max-age。
确定网站的最佳缓存层级:对 HTML 文档组合使用包含内容特征码的资源网址以及短时间或 no-cache 的生命周期,可以控制客户端获取更新的速度。
更新最小化:有些资源的更新比其他资源频繁。如果资源的特定部分(例如 JS 函数或一组 CSS 样式)会经常更新,应考虑将其代码作为单独的文件提供。这样,每次获取更新时,剩余内容(例如不会频繁更新的库代码)可以从缓存中获取,确保下载的内容量最少。
确保服务器配置或移除ETag:因为Etag跟服务器配置有关,每台服务器的Etag都是不同的。
善用HTML5的缓存机制:合理设计启用LocalStorage、SessionStorage、IndexDB、SW等存储,会给页面性能带来明显提升。
结合Native的强大存储能力:善于利用客户端能力,定制合适的缓存机制,打造极致体验。
结语
通过了解浏览器各种缓存机制和存储能力特点,结合业务制定合适的缓存策略,善用缓存是基本功,可以用于时常审查负责的业务,可能就会发现个别业务并没有运用到位,共勉。
参考资料
https://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html#sec14.9
https://www.digitalocean.com/community/tutorials/web-caching-basics-terminology-http-headers-and-caching-strategies
https://developers.google.com/web/fundamentals/performance/optimizing-content-efficiency/http-caching?hl=en
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Caching_FAQ
https://developer.mozilla.org/zh-CN/docs/Web/API/IndexedDB_API
https://juejin.im/post/5a673af06fb9a01c927ed880
https://developers.google.com/web/fundamentals/performance/optimizing-content-efficiency/http-caching?hl=zh-cn
以上是关于彻底弄懂浏览器缓存策略的主要内容,如果未能解决你的问题,请参考以下文章