听说,加缓存能提高性能?
Posted 前端向后
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了听说,加缓存能提高性能?相关的知识,希望对你有一定的参考价值。
写在前面
、、、……如果这些扩展手段全都上了,数据响应依旧越来越慢,还有什么解决办法吗?
有,加缓存。利用缓存层来吸收不均匀的负载和流量高峰:
Popular items can skew the distribution, causing bottlenecks. Putting a cache in front of a database can help absorb uneven loads and spikes in traffic.
一.在哪加?
理论上,在数据层之前的任意一层加缓存都能够阻挡流量,减少最终抵达数据库的操作请求:
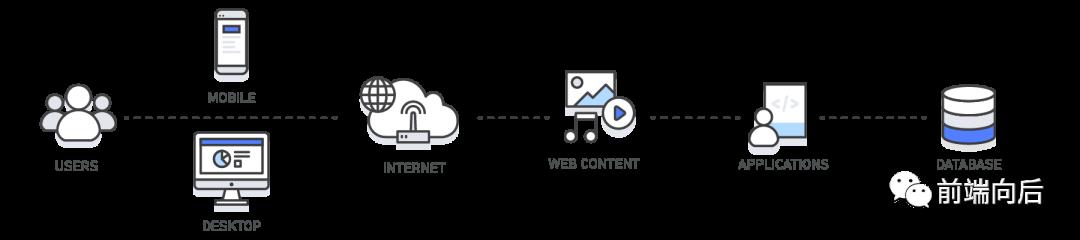
按缓存所处位置分为 4 种:
客户端缓存:包括、浏览器缓存等
Web 缓存:例如、等
应用层缓存:例如Memcached、Redis等
数据库缓存:一些数据库提供了内置的缓存支持,比如查询缓存(query cache)
为了减轻数据库的负载,我们在应用程序和数据存储之间加个键值存储作为缓冲层:
A cache is a simple key-value store and it should reside as a buffering layer between your application and your data storage.
通过内存中缓存的数据来响应一部分请求,而不必实际执行查库操作,从而提升数据响应速度
二.存什么?
常见的有两种缓存模式:
Cached Database Queries:缓存原始查库结果
Cached Objects:缓存应用程序中的数据模型,比如重新组装过的数据集,或者整个数据模型类实例
缓存原始查库结果
根据查询语句生成key,将查库结果缓存起来,例如:
key = "user.%s" % user_id
user_blob = memcache.get(key)
if user_blob is None:
user = mysql.query("SELECT * FROM users WHERE user_id="%s"", user_id)
if user:
memcache.set(key, json.dumps(user))
return user
else:
return json.loads(user_blob)
这种模式的主要缺陷在于难以处理缓存过期,因为数据与key(即查询语句)之间并没有明确的关联,数据发生变化后,很难精确地删掉缓存中的所有相关条目。试想,一个单元格发生变化,会影响哪些查询语句?
尽管如此,这仍然是最常用的缓存模式,因为可以做出妥协,比如:
只缓存与查询语句有直接关联的数据,排序、统计、筛选之类的计算结果统统都不存了
不求精确,把所有可能受影响的缓存条目都删掉
缓存数据对象
另一种思路是将应用程序中的数据模型对象缓存起来,这样原始数据与缓存之间就有了逻辑关联,从而轻松解决缓存更新的难题
无论数据是如何查询,如何加工转换的,只把最终得到的数据模型对象缓存起来,原始数据发生变化时,直接把相应的数据对象整个移除
对应用程序而言,数据对象比原始数据更容易管理和维护,因此,建议缓存数据对象,而不是原始数据
三.怎么查?
常见的缓存数据访问策略有 6 种:
Cache-aside/Lazy loading:预留缓存
Read-through:直读式
Write-through:直写式
Write-behind/Write-back:回写式
Write-around:绕写式
Refresh-ahead:刷新式
Cache-aside
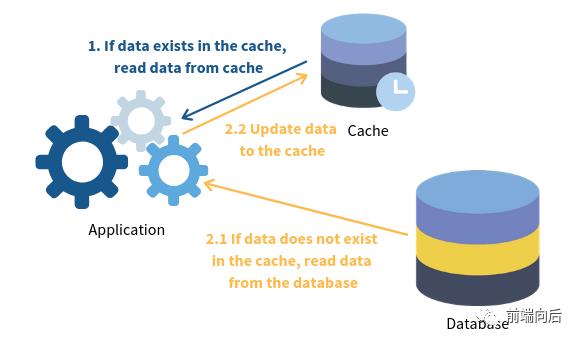
预留缓存模式下,缓存与数据库之间没有直接关系(缓存位于一旁,所以叫 Cache-aside),由应用程序将需要的数据从数据库中读出并填充到缓存中
数据请求优先走缓存,未命中缓存时才查库,并把结果缓存起来,所以缓存是按需的(Lazy loading),只有实际访问过的数据才会被缓存起来
主要问题在于:
未命中缓存时需要 3 步,延迟不容忽视(对于冷启动可以手动预热)
缓存可能会变旧(一般通过设置 TTL 来强制更新)
Read-through
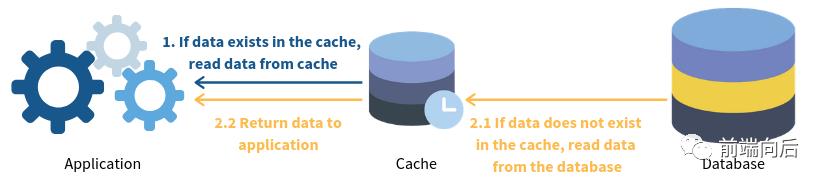
直读模式下,缓存挡在数据库之前,应用程序不与数据库直接交互,而是直接从缓存中读取数据
未命中缓存时,由缓存负责查库,并自己缓存起来。与预留缓存唯一的区别在于查库的工作由缓存来完成,而不是应用程序
Write-through
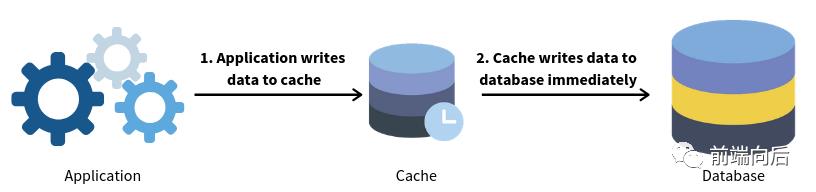
类似于直读模式,缓存也挡在数据库之前,数据先写到缓存,再写入数据库。也就是说,所有写操作必须先经过缓存
一般与直读式缓存相结合,虽然写操作多过一层缓存(存在额外的延迟),但保证了缓存数据的一致性(避免缓存变旧)。此时,缓存就像数据库的代理,读写都走缓存,缓存再查库或将写操作同步到数据库
Write-behind/Write-back
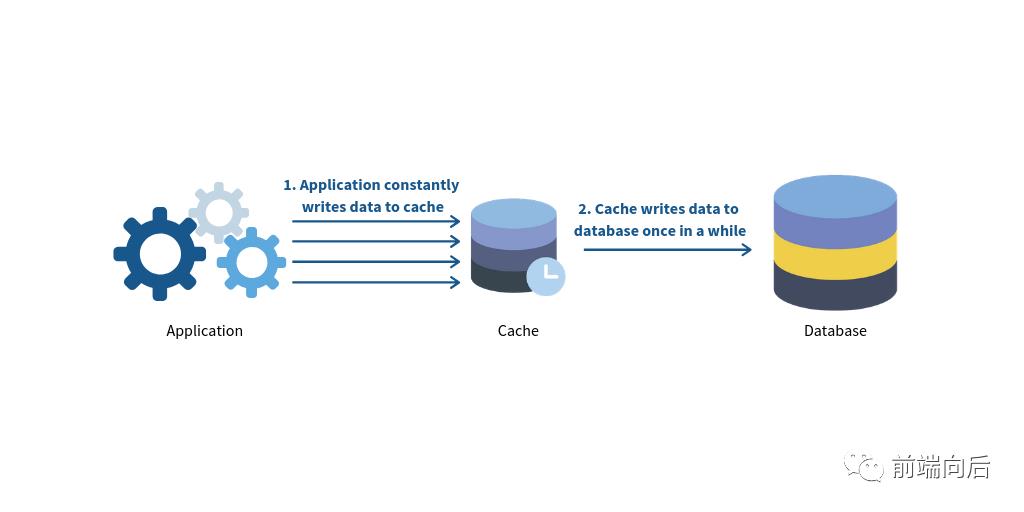
回写式缓存与直写式很像,写操作同样要先经过缓存,唯一的区别在于异步写入数据库,进而允许批处理以及写操作合并
同样能够与直读式缓存结合使用,而且不存在直写式中写操作的性能问题,但仅保证最终一致性
Write-around
所谓绕写式缓存就是写操作不经过(绕过)缓存,由应用程序直接写入数据库,仅缓存读操作。可与预留缓存或直读缓存结合使用:
Refresh-ahead
提前刷新,在缓存过期之前,自动刷新(重新加载)最近访问过的条目。甚至可以通过预加载来减少延迟,但如果预测不准反而会导致性能下降
四.塞满了怎么办?
当然,缓存空间是极其有限的,所以还要有逐出策略(Eviction Policy),从缓存中剔除一些不太可能用到的条目,常用策略如下:
LRU(Least Recently Used):最常用的一种策略,根据程序运行时的局部性原理,在一段时间内,大概率访问相同的数据,所以将最近没有用到的数据剔除出去,比如订机票,一段时间内大概率查询同一路线
LFU(Least Frequently Used):根据使用频率,将最不常用的数据剔除出去,比如输入法大多是根据词频联想的
MRU(Most Recently Used):在有些场景下,需要删掉最近用过的条目,比如已读、不再提醒、不感兴趣等
FIFO(First In, First Out):先进先出,剔除最早访问过的数据
这些策略还可以结合使用,比如 LRU + LFU 综合考虑,取决于具体场景
参考资料
Caching Overview
Scalability for Dummies – Part 3: Cache
Things You Should Know About Database Caching
All things caching- use cases, benefits, strategies, choosing a caching technology, exploring some popular products
以上是关于听说,加缓存能提高性能?的主要内容,如果未能解决你的问题,请参考以下文章