分布式缓存组件故障分析及监控优化
Posted IT那活儿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式缓存组件故障分析及监控优化相关的知识,希望对你有一定的参考价值。
PaaS平台缓存组件采用电信集体自研分布式缓存ctg-cache产品,部署在“天翼云”资源池,为多个能力中心提供服务,如外部客户统一认证平台(UAM)、CPCP增量(CPC1)、CPCP工作台(CPC1WEB)、综合资源(RM)、销售门户,计费等,目前支撑大约为每分钟10万的业务访问缓存请求。CRM集群部署了10组Redis实例节点,以及4个“接入机”节点,如表一、图一所示。
表格 1 CRM集群节点信息
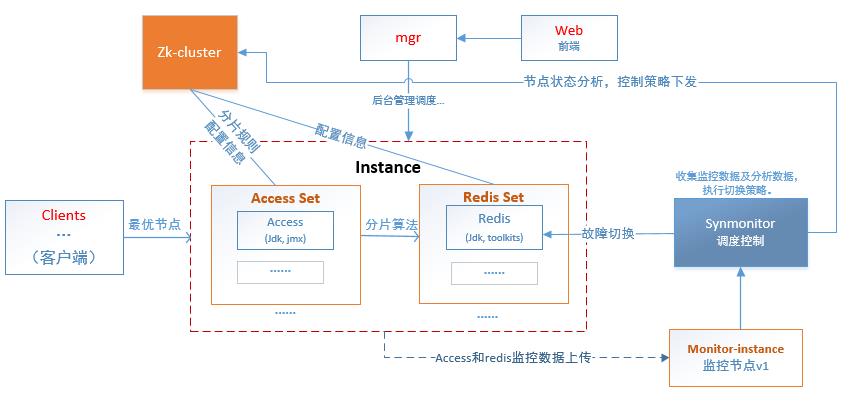
图表 1 分布式缓存部署拓扑图
IT运维与安全体系的落地关键在于解决问题的快慢,归根结底是客户感知,巡检是必要手段之一。通过巡检,一方面可检查服务可用性,保障服务的平稳运行,另一方面可发现潜在的隐患,及时做出对应的整改措施。我们对于巡检的不断优化和改善,就是为了更快地修复、杜绝和预防故障,达成客户能够获得良好的感知的最终目的。
目前PaaS平台组主要通过监控告警和定期巡检来保障分布式缓存的服务健康性。分布式缓存实行每日巡检制,巡检主要分为3个时间段,第一个时间段是早上7点到7点半,进行PaaS平台所有组件的统一晨检,保障营业厅营业前服务的健康性;第二个时间段是上班时间由平台组每隔2小时巡检一次,在保障组件正常运行的同时,还要关注监控曲线的波动幅度是否正常、CPU/内存使用率是否偏高、应用执行缓存操作的报错率等,便于及时发现隐患;第三个时间段是晚上9点到9点半,进行PaaS平台所有组件的统一巡检。
此前PaaS平台组对于分布式缓存的巡检主要是检查管理页面组件的运行状态,但在分布式缓存一次故障处理过程中,运维人员在收到告警后立刻着手进行处理,当时管理页面组件运行状态正常,运维人员在问题定位上耗费了较长时间,因此没有快速解决故障。
故障现象
(1)运维人员收到缓存的各类告警邮件,包括宕机告警、服务告警等告警邮件。
(2)平台测试程序和应用调用缓存报错:READONLYyou can’t write against a read only salve,大量写入操作失败。

图表 2 分布式缓存“READONLY”报错
故障分析
(1)在10.145.***.7、10.145.***.11接入机上出现网络状态波动,使得监控端口探测失效、应用连接失败、应用报错。
(2)10.145.***.7、10.145.***.11 机器网络恢复后,期间发生的Redis主从切换没有写入zookeeper,zookeeper判断主从错误,同时,10.145.***.11的“接入机”出现故障,表象为正在运行但实际却不可用,导致应用继续报错,延长了故障发生时间。
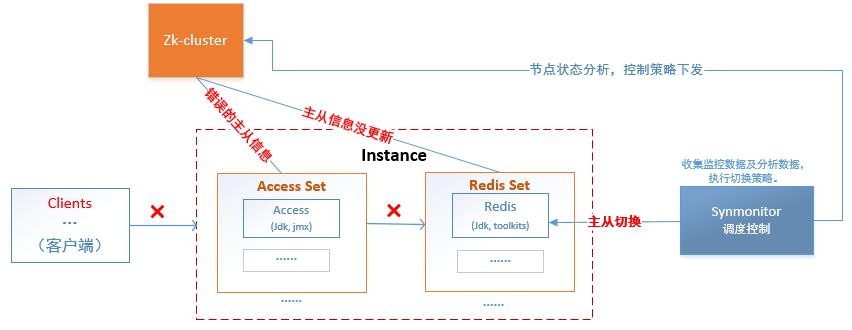
图表 3 分布式缓存故障过程示意图
故障处理
(1)在机器网络恢复后,运维人员检查管理页面,发现Redis节点和“接入机”的运行状态全部正常,但执行平台测试程序,报“READONLY”错,原因是网络波动期间发生的Redis主从切换没有写入zookeeper,于是进行了Redis主从切换。
(2)整个CRM集群的所有Redis节点主从切换完毕后,验证测试程序依然在报错,而此时zookeeper中Redis主从信息与实际信息已经全部一致。运维人员查看客户端监控发现有一台“接入机”的报错显著地高于其他接入机,于是重启了该接入机,之后测试程序不再报错。

图表 4 服务恢复后的可用性测试
为了更快定位问题并解决,我们优化了巡检方案。巡检的优化方案主要为增加缓存组件的巡检项目,包括Redis主从切换状态检测和服务可用性探测,从而能够快速判断问题产生的环节,加快故障修复的操作流程。
主从切换状态检测
举例:
实际为10.145.***.5:**00为主,10.145.***.4:**00为从
/app/ctgcache/cache_apps/redisEntites/redis/src/redis-cli-h 10.145.***.5 -p **00 -a VI9IAMzX info replication
 图表 5 Redis主从信息
图表 5 Redis主从信息
那么master{$seq} 前的connUrl就应该是10.145.***.5:**00,如果不是,则判断为异常。
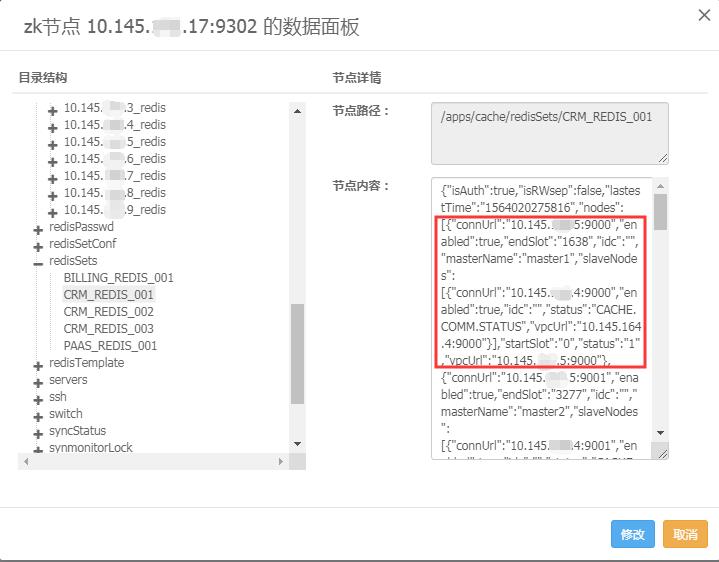 图表 6 Zookeeper中Redis的主从信息
图表 6 Zookeeper中Redis的主从信息
可用性探测
一、探测逻辑设计
a)连续探测60次读、写,记录成功失败次数;
b) 读操作连续失败10次或者写操作连续失败10次,则停止退出探测。
二、程序配置说明
a)env变量配置环境标识;result_path变量配置结果文件目录;
b)不同的环境添加对应的配置信息,实际情况是4个环境,对应4个接入机;
c)启动时依次加载不同环境配置,并行探测,探测结束,探测程序自动退出。

图表 7 不同环境的配置文件
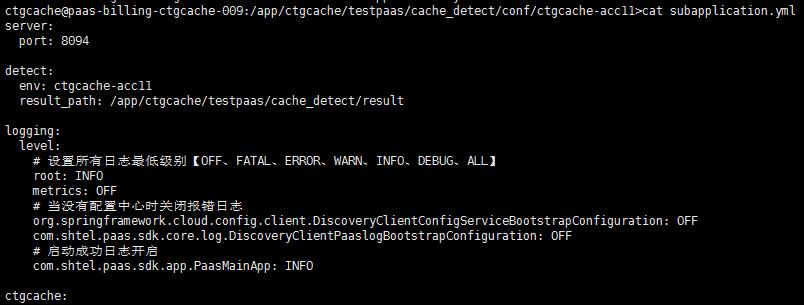
图表 8 探测程序配置信息
结果文件说明
每个环境都会生成对应的探测结果文件(文件名:环境标识),结果包含读操作成功数/失败数、写操作成功数/失败数
图表 9 不同环境生成结果文件
图表 10 结果信息
以上是关于分布式缓存组件故障分析及监控优化的主要内容,如果未能解决你的问题,请参考以下文章