CPU缓存了解下?
Posted Bella的技术轮子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CPU缓存了解下?相关的知识,希望对你有一定的参考价值。
这是Bella酱的第 79 期分享
来源|知乎
一.前言
不同存储技术的访问时间差异很大,从 计算机层次结构 可知,通常情况下,从高层往底层走,存储设备变得更慢、更便宜同时体积也会更大,CPU 和内存之间的速度存在着巨大的差异,此时就会想到计算机科学界中一句著名的话:计算机科学的任何一个问题,都可以通过增加一个中间层来解决。
二.引入缓存层
为了解决速度不匹配问题,可以通过引入一个缓存中间层来解决问题,但是也会引入一些新的问题。现代计算机系统中,从硬件到操作系统、再到一些应用程序,绝大部分的设计都用到了著名的局部性原理,局部性通常有如下两种不同的形式:
时间局部性:在一个具有良好的时间局部性的程序当中,被引用过一次的内存位置,在将来一个不久的时间内很可能会被再次引用到。
空间局部性:在一个具有良好的空间局部性的程序当中,一个内存位置被引用了一次,那么在不久的时间内很可能会引用附近的位置。
有上面这个局部性原理为理论指导,为了解决二者速度不匹配问题就可以在 CPU 和内存之间加一个缓存层,于是就有了如下的结构:
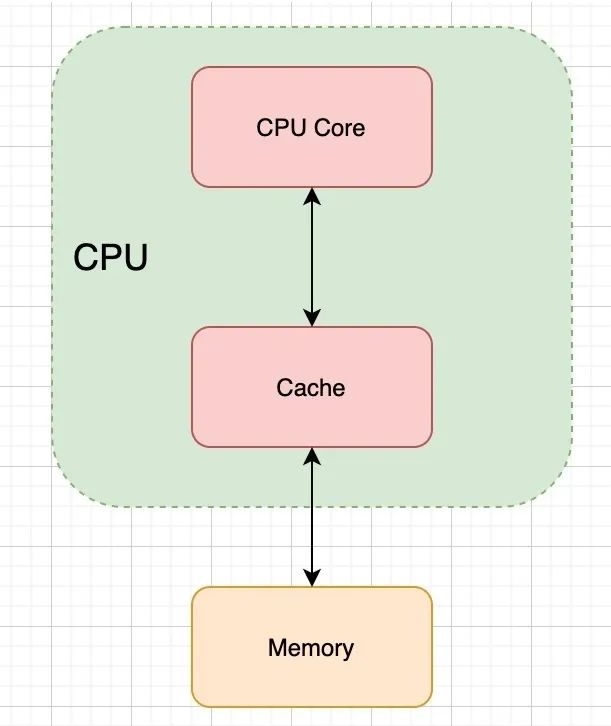
三.何时更新缓存
在 CPU 中引入缓存中间层后,虽然可以解决和内存速度不一致的问题,但是同时也面临着一个问题:当 CPU 更新了其缓存中的数据之后,要什么时候去写入到内存中呢?比较容易想到的一个解决方案就是,CPU 更新了缓存的数据之后就立即更新到内存中,也就是说当 CPU 更新了缓存的数据之后就会从上到下更新,直到内存为止,英文称之为write through,这种方式的优点是比较简单,但是缺点也很明显,由于每次都需要访问内存,所以速度会比较慢。还有一种方法就是,当 CPU 更新了缓存之后并不马上更新到内存中去,在适当的时候再执行写入内存的操作,因为有很多的缓存只是存储一些中间结果,没必要每次都更新到内存中去,英文称之为write back,这种方式的优点是 CPU 执行更新的效率比较高,缺点就是实现起来会比较复杂。
上面说的在适当的时候写入内存,如果是单核 CPU 的话,可以在缓存要被新进入的数据取代时,才更新内存,但是在多核 CPU 的情况下就比较复杂了,由于 CPU 的运算速度超越了 1 级缓存的数据 IO 能力,CPU 厂商又引入了多级的缓存结构,比如常见的 L1、L2、L3 三级缓存结构,L1 和 L2 为 CPU 核心独有,L3 为 CPU 共享缓存。
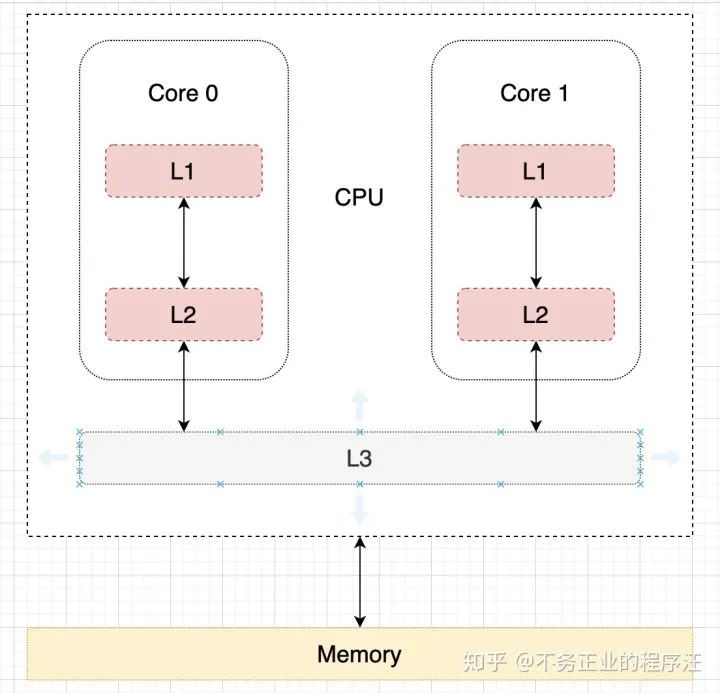
如果现在分别有两个线程运行在两个不同的核 Core 1 和 Core 2 上,内存中 i 的值为 1,这两个分别运行在两个不同核上的线程要对 i 进行加 1 操作,如果不加一些限制,两个核心同时从内存中读取 i 的值,然后进行加 1 操作后再分别写入内存中,可能会出现相互覆盖的情况,解决的方法相信大家都能想得到,第一种是只要有一个核心修改了缓存的数据之后,就立即把内存和其它核心更新。第二种是当一个核心修改了缓存的数据之后,就把其它同样复制了该数据的 CPU 核心失效掉这些数据,等到合适的时机再更新,通常是下一次读取该缓存的时候发现已经无效,才从内存中加载最新的值。
四.缓存一致性协议
不难看出第一种需要频繁访问内存更新数据,执行效率比较低,而第二种会把更新数据推迟到最后一刻才会更新,读取内存,效率高(类似于懒加载)。缓存一致性协议(MESI) 就是使用第二种方案,该协议主要是保证缓存内部数据的一致,不让系统数据混乱。MESI 是指 4 种状态的首字母。每个缓存存储数据单元(Cache line)有 4 种不同的状态,用 2 个 bit 表示,状态和对应的描述如下:

下面看看基于缓存一致性协议是如何进行读取和写入操作的, 假设现在有一个双核的 CPU,为了描述方便,简化一下只看其逻辑结构:
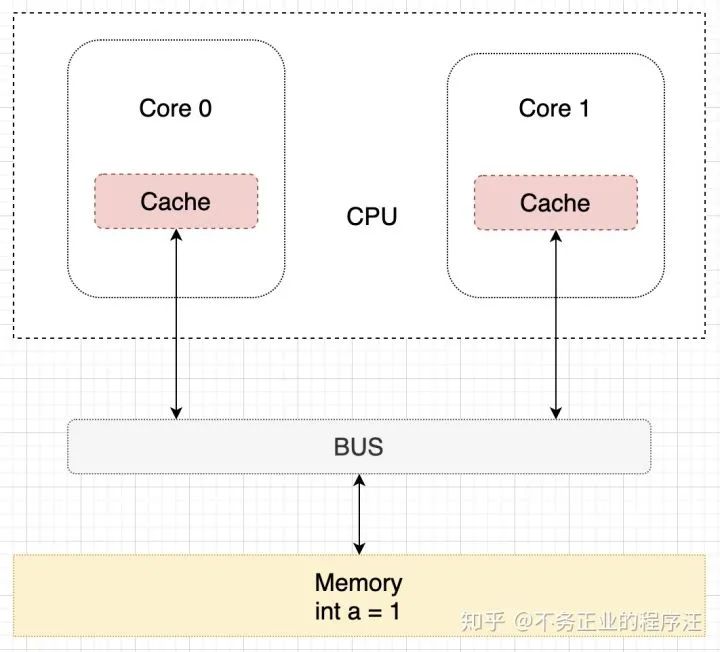
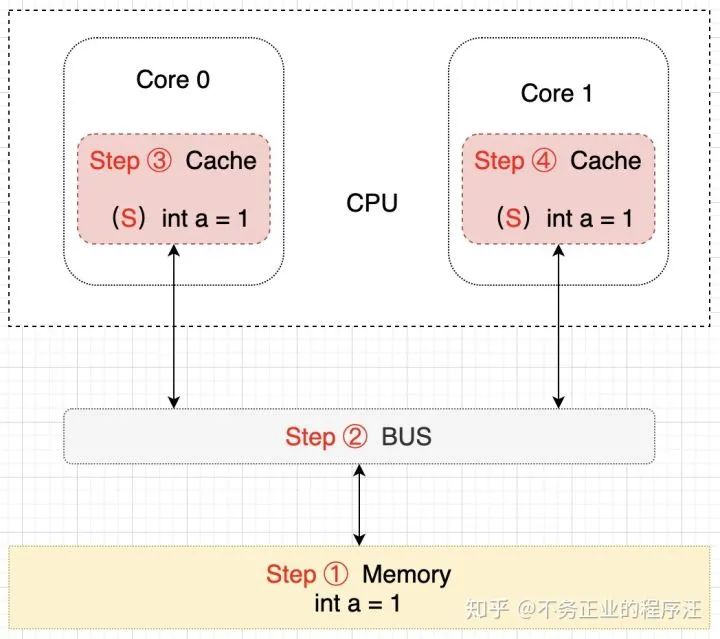
单核读取步骤:Core 0 发出一条从内存中读取 a 的指令,从内存通过 BUS 读取 a 到 Core 0的缓存中,因为此时数据只在 Core 0 的缓存中,所以将 Cache line 修改为 E 状态(独享),该过程用示意图表示如下:
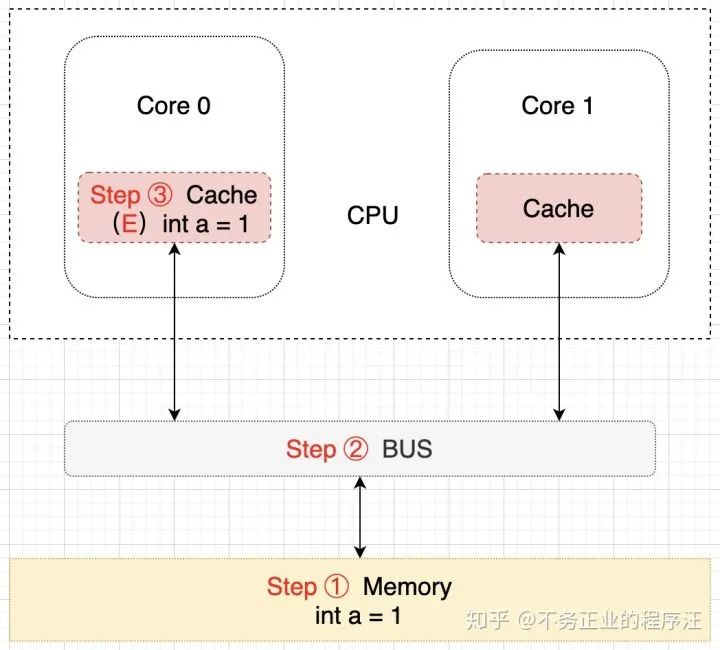
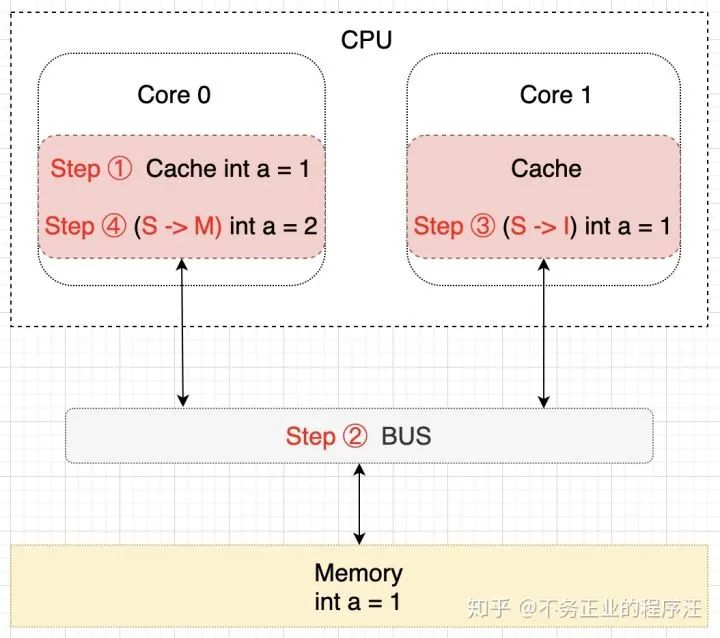
假设此时 Core 0 核心需要对 a 进行修改了,首先 Core 0 会将其缓存的 a 设置为 M(修改)状态,然后通知其它缓存了 a 的其它核 CPU(比如这里的 Core 1)将内部缓存的 a 的状态置为 I(无效)状态,最后才对 a 进行赋值操作。该过程如下所示:
细心的朋友们可能已经注意到了,上图中内存中 a 的值(值为 1)并不等于 Core 0 核心中缓存的最新值(值为 2),那么要什么时候才会把该值更新到内存中去呢?就是当 Core 1 需要读取 a 的值的时候,此时会通知 Core 0 将 a 的修改后的最新值同步到内存(Memory)中去,在这个同步的过程中 Core 0 中缓存的 a 的状态会置为 E(独享)状态,同步完成后将 Core 0和 Core 1 中缓存的 a 置为 S(共享)状态,示意图描述该过程如下所示:
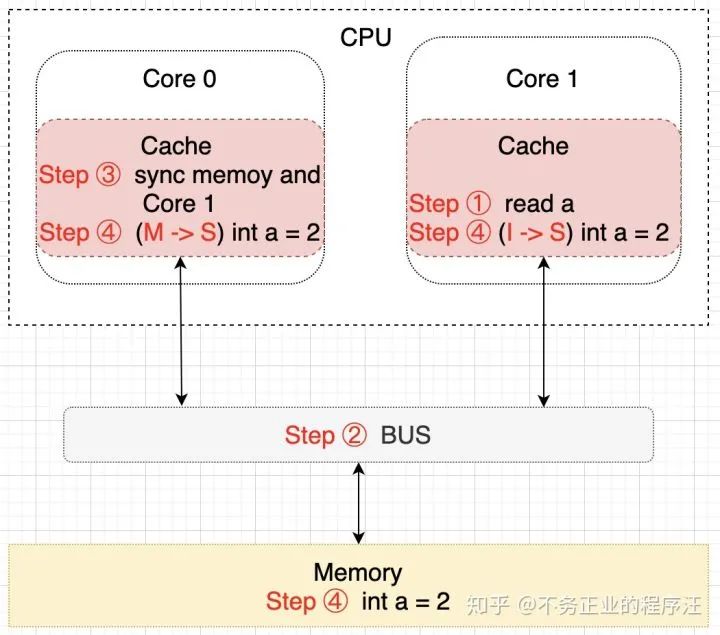
至此,变量 a 在 CPU 的两个核 Core 0 和 Core 1 中回到了 S(共享)状态了,以上只是简单的描述了一下大概的过程,实际上这些都是在 CPU 的硬件层面上去保证的,而且操作比较复杂。
五.总结
现在很多一些实现缓存功能的应用程序都是基于这些思想设计的,缓存把数据库中的数据进行缓存到速度更快的内存中,可以加快我们应用程序的响应速度,比如我们使用常见的 Redis 数据库可能是采用下面这些策略:
① 首先应用程序从缓存中查询数据,如果有就直接使用该数据进行相应操作后返回,如果没有则查询数据库,更新缓存并且返回。
② 当我们需要更新数据时,先更新数据库,然后再让缓存失效,这样下次就会先查询数据库再回填到缓存中去,可以发现,实际上底层的一些思想都是相通的,不同的只是对于特定的场景可能需要增加一些额外的约束。基础知识才是技术这颗大树的根,我们先把根栽好了,剩下的那些枝和叶都是比较容易得到的东西了。
-END-
更多精彩文章
1.
2.
3.
4.
5.
6.
团队招人,欢迎一起来做同事呀~
如果你喜欢本文
请长按二维码,关注 Bella的技术轮子
喜欢就点个在看吧
以上是关于CPU缓存了解下?的主要内容,如果未能解决你的问题,请参考以下文章
从底层了解JVM的volatile实现,CPU Cache缓存一致性MESIStore BufferInvalidate Queue等知识
从底层了解JVM的volatile实现,CPU Cache缓存一致性MESIStore BufferInvalidate Queue等知识