小白都能看懂的缓存入门
Posted Hollis
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小白都能看懂的缓存入门相关的知识,希望对你有一定的参考价值。
缓存是程序员必须了解的技术,无论是前端、后端还是客户端,大到复杂的系统架构,小到 CPU 或是芯片,都少不了缓存的影子。
下面只需 5 分钟,带你入门缓存技术。
什么是缓存?
缓存(Cache)本意是指可以进行高速数据交换的存储器,通俗点来说,就是通过将数据提前存放到内存,以提高访问速度。
在我们设计程序或算法时,有两个基本指标,即时间复杂度和空间复杂度。有时,我们的程序无法同时满足二者,就只能以时间换空间,或者以空间换时间。缓存是以空间换时间思想的典型应用,牺牲一部分内存空间,能够得到数百倍的读取性能提升。
缓存最常见的数据结构是键值对(Key/Value),类似字典,即一个 Key 对应一个 Value,访问缓存时通过 Key 获取 Value。
为什么需要缓存?
最简单的后端系统只需要一个应用服务(比如 Tomcat)和持久化存储数据的数据库(如 mysql),对于一个访问量很小的系统来说,这样的架构就足够了。
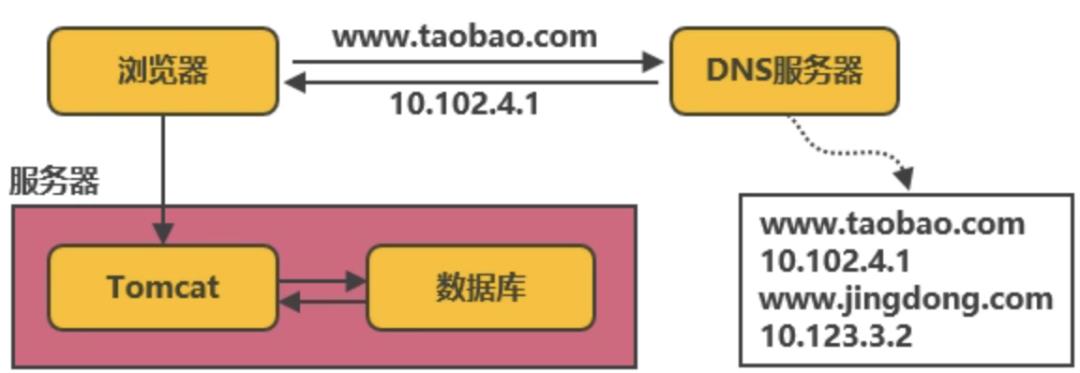
但随着系统的用户数和访问量的提升,数据库会收到越来越多的并发请求。由于数据库是从磁盘中读取数据,性能较低,随着请求数的增多,数据库受到的压力会越来越大。由于应用访问数据库的连接数有限,当数据库的处理能力跟不上请求数时,新的请求将排队等待,从而导致我们的后台程序也会阻塞。当并发请求数持续增大时,数据库甚至会挂掉!欧豁,完蛋。
因此,我们需要性能更高的读取数据方式,能够帮助数据库分担压力,缓存登场了。

可以在数据库之上增加一层缓存,当后台程序首次读取数据时,将得到的数据存入缓存中,那么后续的请求要读取相同数据时,只需从缓存中读取即可。由于缓存是将数据存入内存中,读取速度非常快,在成功提升性能的同时,替数据库分担了大量的压力。
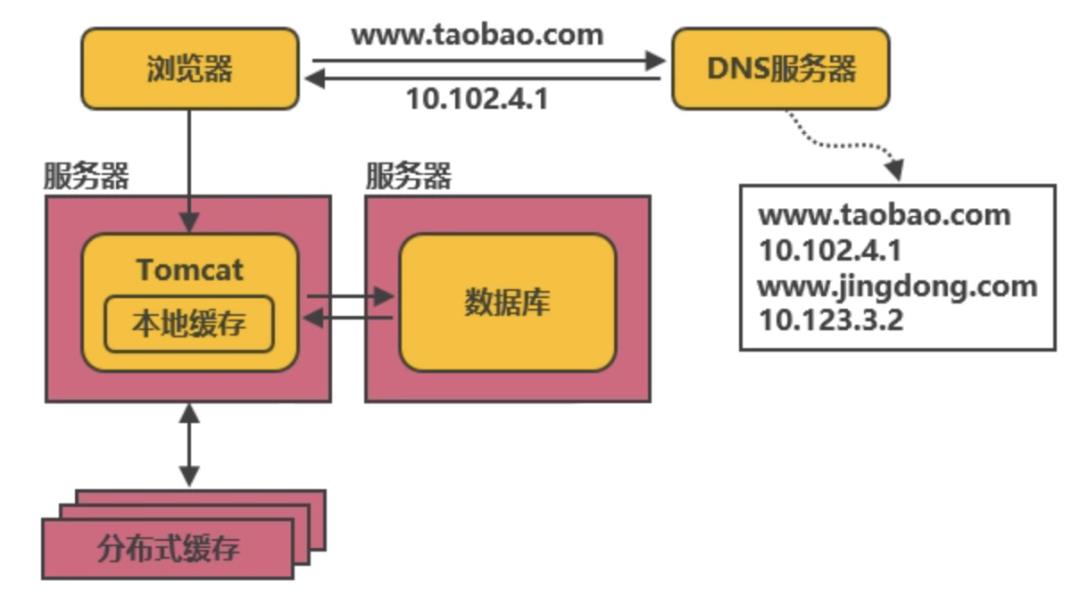
因此想要提升系统的整体性能,缓存是不可或缺的。
缓存类别
可以将缓存分为两种类型。
本地缓存
直接运行在应用程序本地的缓存组件。
比如 JVM 中的 Map 数据结构,可以作为最简单的数据缓存:
class LocalCache {private static Map<String, Object> cache = new HashMap<>();private LocalCache() {}public static void put(String key, Object value) {cache.put(key, value);}public static Object get(String key) {return cache.get(key);}}
如果你的应用程序只需要运行在一台服务器上,并且多个应用程序之间不需要共享缓存的数据(比如用户 token),可以直接采用本地缓存,访问缓存时不需要通过网络传输,非常地方便迅速。
但是本地缓存会和你的应用程序强耦合,应用程序停止,本地缓存也就停止了。而且如果是在分布式场景下,多个机器都要使用缓存,此时如果在每个服务器上单独维护一份本地缓存,不仅无法共享数据,而且非常浪费内存(因为每台机器可能缓存了相同的数据)。
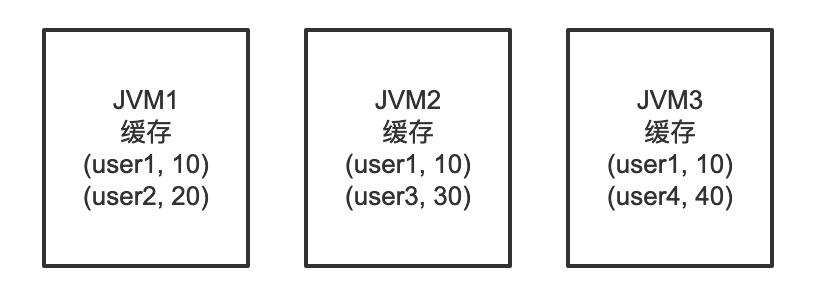
为解决缓存数据共享的问题,可以使用分布式缓存。
分布式缓存
分布式缓存是指独立的缓存服务,不和任何一个具体的应用耦合,可以独立运行并搭建缓存集群。类似数据库,所有的应用程序都可以连接同一个缓存服务以获取相同的缓存数据。
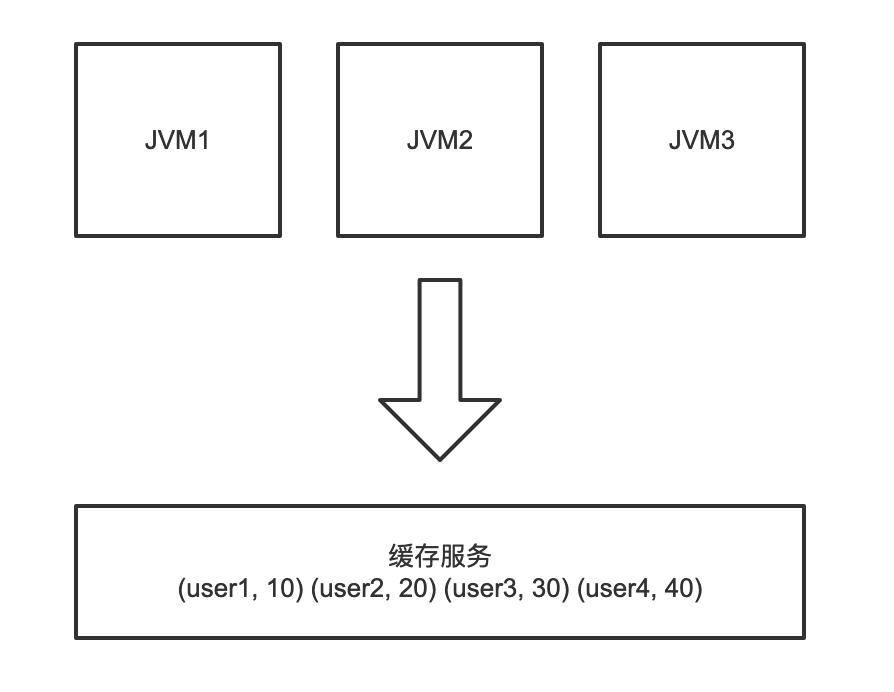
除了数据共享外,分布式缓存的优点还有很多。比如不需要每台机器单独维护缓存、可以集中管理缓存和整体管控分析、便于扩展和容错等。但是应用必须要通过网络访问分布式缓存服务,会产生额外的网络开销成本;并且每台机器都有可能会对整个分布式缓存服务产生影响,而一旦分布式缓存挂了,所有的应用都可能出现瘫痪(缓存雪崩)。
多级缓存
上述两种缓存没有绝对的优劣,要根据实际的业务场景进行选型。其实还可以将本地缓存与分布式缓存相结合,形成多级缓存服务,架构如下:
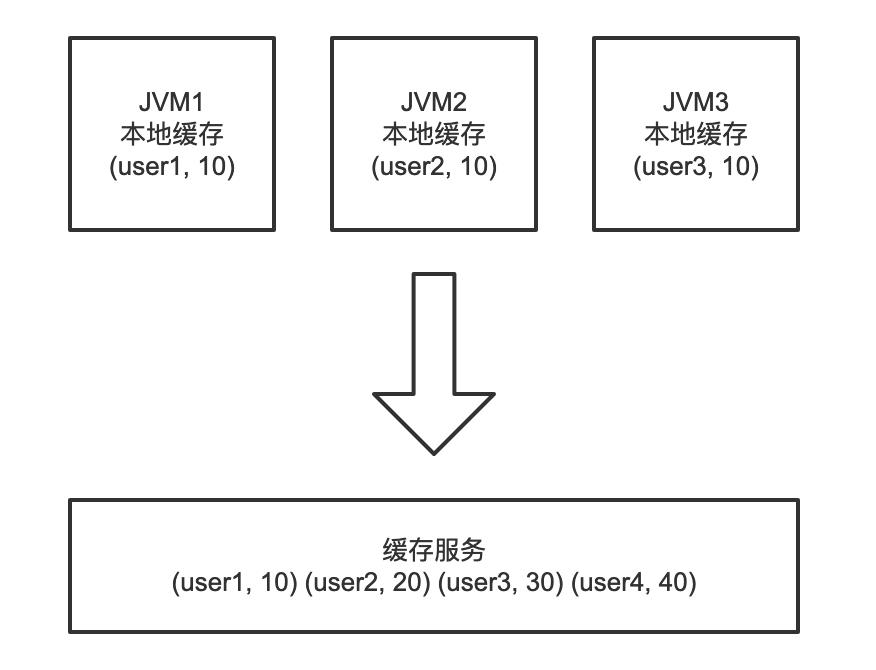
当首次查询时(不存在缓存),会同时将数据写入本地缓存和分布式缓存。之后的查询优先查询分布式缓存,而如果分布式缓存宕机,则从本地缓存获取数据。通过多级缓存机制,能够起到兜底的作用,即使缓存挂掉,也能支撑应用运行一段时间。
缓存淘汰策略
下面我们思考一个问题,如何去实现一个本地缓存呢?
刚刚提到的 Map 数据结构是一个思路,但是和我们自己的电脑存储文件、或者是和 JVM 存储对象一样,内存当然不是无限的。因此在实现缓存时,必须要设计一套缓存淘汰策略,按照某种机制回收缓存占用的内存,保证缓存数据不会无限地增长直到撑爆内存。
下面介绍几种常见的缓存淘汰策略,关键问题就是当缓存空间已满时,应该选择哪些缓存进行删除。
LRU 最近最少使用
LRU(Least Recently Used)是最经典的内存淘汰策略,其设计原则是 “如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小”。即根据数据的最近访问时间来进行淘汰。缺点是可能会由于一次冷数据的批量查询而误删除大量的热点数据。
近似 LRU 算法
类似 LRU 算法,只是每次随机选择一批数据进行 LRU 淘汰,而不是全量 LRU 运算,牺牲部分准确度,以提升算法执行效率。
Redis 3.0 之后对其进行了优化,维护了一个侯选池,将随机选择的数据放入侯选池中进行 LRU 运算。当侯选池放满后,新随机的数据会替换掉池中最近被访问的数据。
TTL 超时时间
TTL(Time To Live)是指用户为缓存设置的过期时间,当前时间到达过期时间时,将删除缓存;如果缓存空间已满,则优先淘汰最接近过期时间的数据。
LFU 最少使用
LFU(Least Frequently Used)策略会记录每个缓存数据的最近访问次数(频率),并优先清除使用次数较少的数据。这种算法存在的显著缺点是,最新写入的数据由于访问次数少,常常刚被缓存就删除了。
FIFO 先进先出
FIFO(First In First Out)先进先出策略会将数据按照写入缓存的顺序进行排队,当缓存空间不足时,最先进入缓存的数据会被优先删除。是一种比较死板的策略,不考虑数据热度,可能会淘汰大量的热点数据,但是实现起来相对容易。

Second-Chance
对 FIFO 算法的改进,给每个缓存数据添加一个引用标志,当数据被访问时,设置其标志位为 1。
当缓存空间不足时,会检测队列首部(最先写入缓存)数据的引用标志位,如果为 1,表示被访问过,则重置标志位为 0 并且重新加入队列尾部;如果为 0,表示未被访问过,直接淘汰。
相对 FIFO 算法来说,更加灵活,降低了淘汰热点数据的风险。
Random 随机
随机淘汰策略,没啥好说的,一般不建议使用。
还有一些其他的策略,比如优先淘汰占用空间最大的数据等,不再赘述。
缓存实现
要想自己设计一个优秀的缓存,还是有难度的,不止是用一个 Java 的数组或者集合类那么简单。幸运的是,有很多现成的类库、框架和中间件可供我们直接使用。下面介绍一些优秀的缓存实现。
Caffeine
Caffeine 是基于 Java8 的近似最佳的高性能本地缓存库。提供了灵活的构造器 API,能够轻松地创建缓存对象,并且组合各种特性。可谓是进程缓存之王。
Guava Cache
Guava 是 Google 开源的 Java 工具包,而 Guava Cache 是其中的本地缓存实现,提供了 time-based、size-based 等多种缓存淘汰策略,使用起来非常方便。
Ehcache
Ehcache 是 Java 实现的开源缓存框架,特性齐全,成熟轻量,并且支持通过 RMI 等方式实现可扩展的分布式缓存。
Memcached
开源的高性能分布式内存 K/V 缓存系统,支持主流语言的 API,适合存储小块的数据,可以利用多核 CPU。缺点是不支持持久化。
Redis
知名的 K/V 存储系统,适用于分布式缓存,支持多种数据结构、读写性能极高,并且可以搭建高可用集群、易扩展、支持持久化。还能通过 Lua 脚本实现原子性。
Spring Cache
Spring Cache 提供了抽象的缓存接口,帮助我们更好地使用缓存,底层可以选择不同的缓存实现,比如 Caffine 或者 Guava Cache。
没有银弹
缓存虽然具有很多优点,但也不是万能的。引入缓存后,还要考虑到缓存删除、缓存更新、缓存穿透、缓存击穿、缓存雪崩等问题。引入的缓存级数越多,数据不一致的风险就越大。因此,在架构设计时,要根据实际的业务需求来是否使用缓存、选用何种缓存。
毕竟,没有银弹。
有道无术,术可成;有术无道,止于术
好文章,我在看❤️
以上是关于小白都能看懂的缓存入门的主要内容,如果未能解决你的问题,请参考以下文章