案例:HDFS分布式文件系统
Posted L宝宝聊IT
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了案例:HDFS分布式文件系统相关的知识,希望对你有一定的参考价值。
Hadoop是apache软件基金会的开源分布式计算平台hadoop集群包括两种角色Mater和Slave。一个HDFS集群由一个运行于Master上的NameNode和若干个运行于Slave节点的DataNode组成。NameNode负责管理文件系统命名空间和客户端对文件系统的访问操作;DataNode管理存储的数据。文件以块形式在DataNode中存储,假如一个块大小设置为50MB,块的副本数为3(通过设置块的副本数来达到冗余效果,防止单个DataNode磁盘故障后数据丢失),一个40MB的文件将被存储在一个块中,然后将相同的3个块存储在3个DataNode中实现冗余。大文件将被切成小块存储。
一、实验要求及目的
搭建hadoop的HDFS,通过DataNode节点的添加与删除实现HDFS空间动态增加与减少,以及HDFS文件系统的基本管理。
二、实验环境
三、实验步骤
1、准备环境
1)master、slave1-3上配置域名解析与主机名

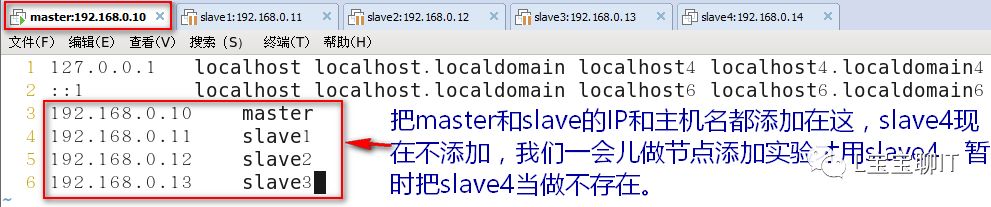



192.168.0.11主机:



192.168.0.12主机:



192.168.0.13主机:



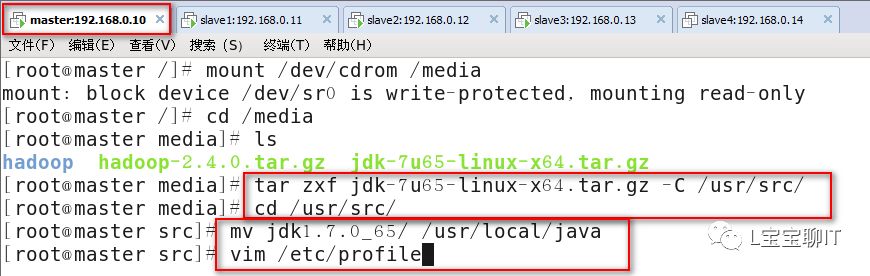
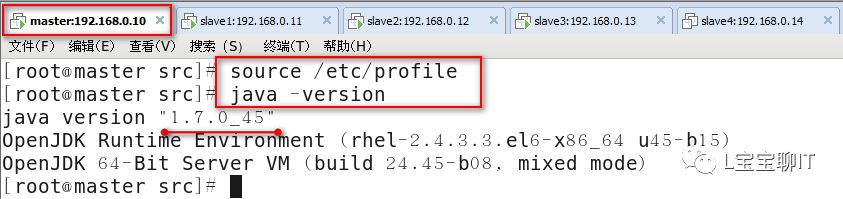
2)JDK安装

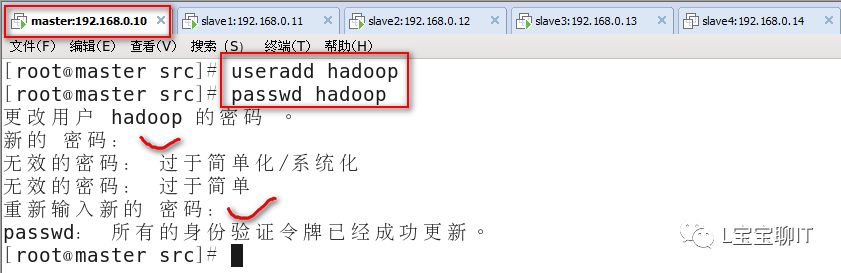
3)添加hadoop运行用户
在slave1-slave3上重复步骤2)和步骤3),这里就不在截图。
2、配置SSH密钥对
要求master免密码登录各slave,用于开启相应服务。
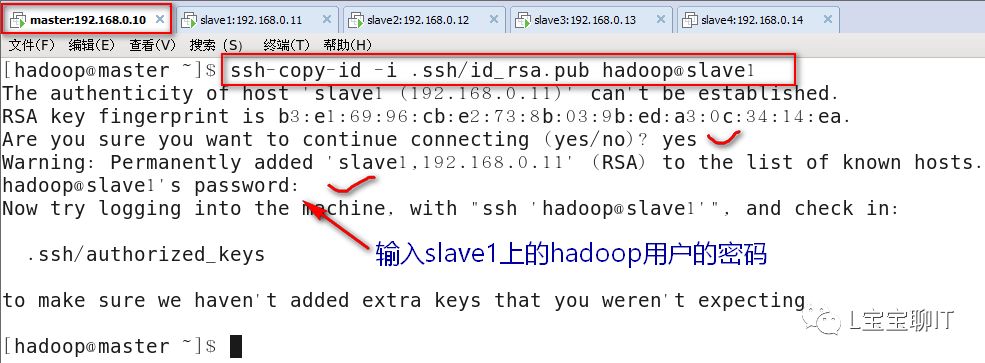
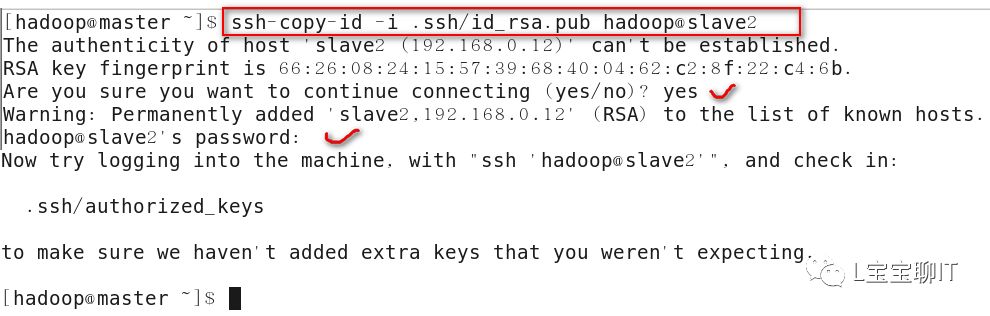
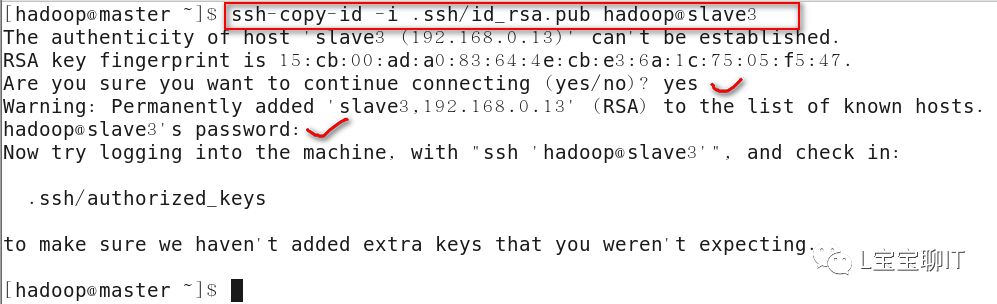
Master无密码连接slave,先切换hadoop用户,用ssh-keygen按照默认配置直接按Enter键生成密钥对,通过ssh-copy-id将公钥复制至3个slave主机中,复制过程需要输入slave主机的hadoop用户密码,作用是master远程启动slave。

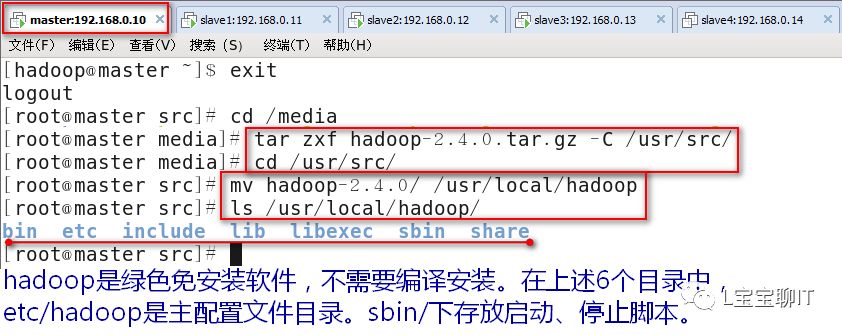
3、安装hadoop,在master和slave上配置环境变量。
1)安装hadoop

2)配置环境变量


执行source /etc/profile
3)配置hadoop


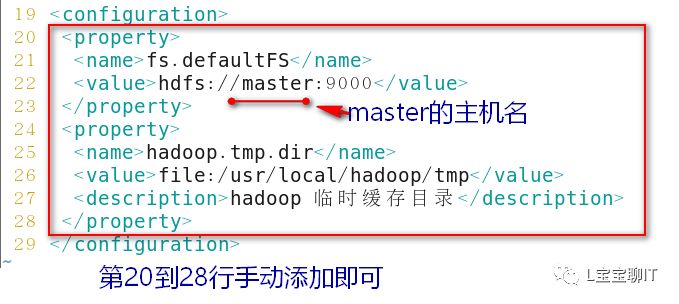

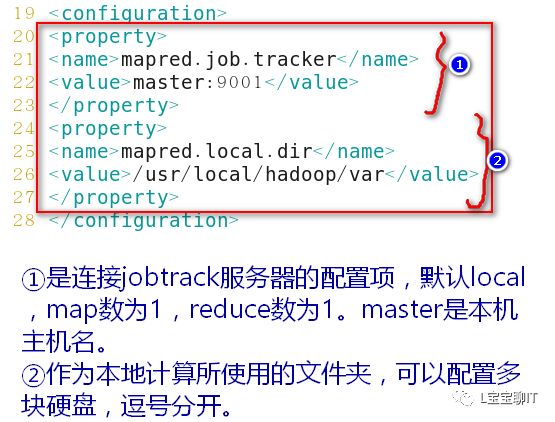

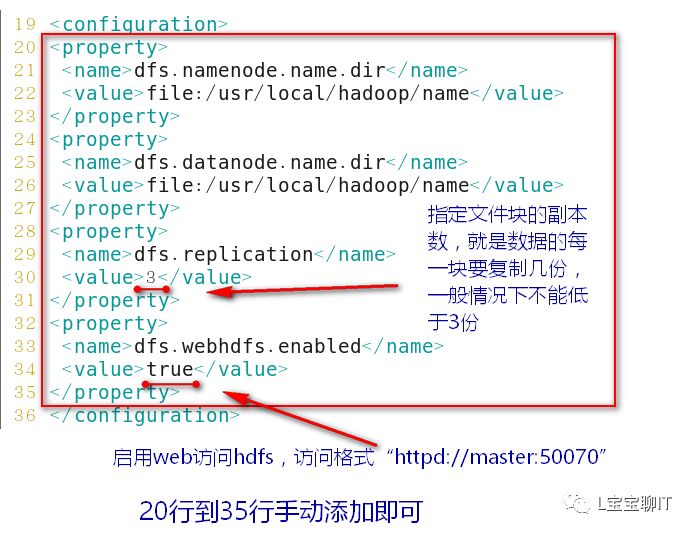



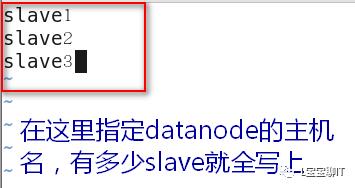
每个slave主机重复步骤1)和步骤2)(即它们也需要安装hadoop并设置环境变量),等前两步完成了再由master通过SSH安全通道把刚才配置的6个文件复制给每个slave。
每个slave主机上重复1)和2)步骤的截图这里省略,请参考上面去做,命令全部一样



4、使用HDFS初始化master
1)格式化HDFS文件系统

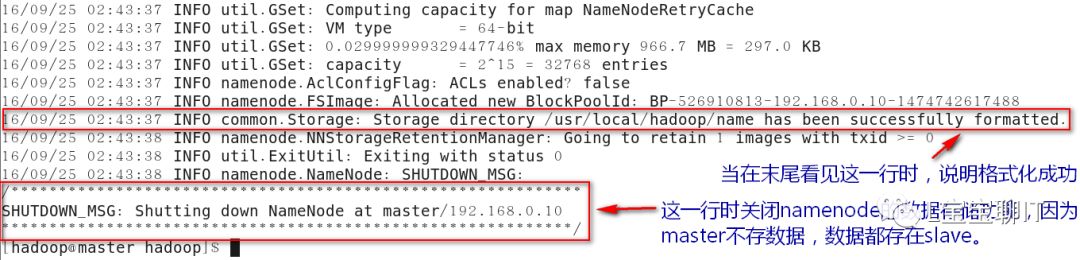
2)检查新生成的目录

3)启动hadoop群集(开机hadoop的冗余功能)
启停hadoopde的管理命令位于$HADOOP_HOME/sbin下,以start-*或stop-*开头;单独启动HDFS分布式文件系统可使用start-dfs.sh,也可以使用以下命令启动整个hadoop集群。
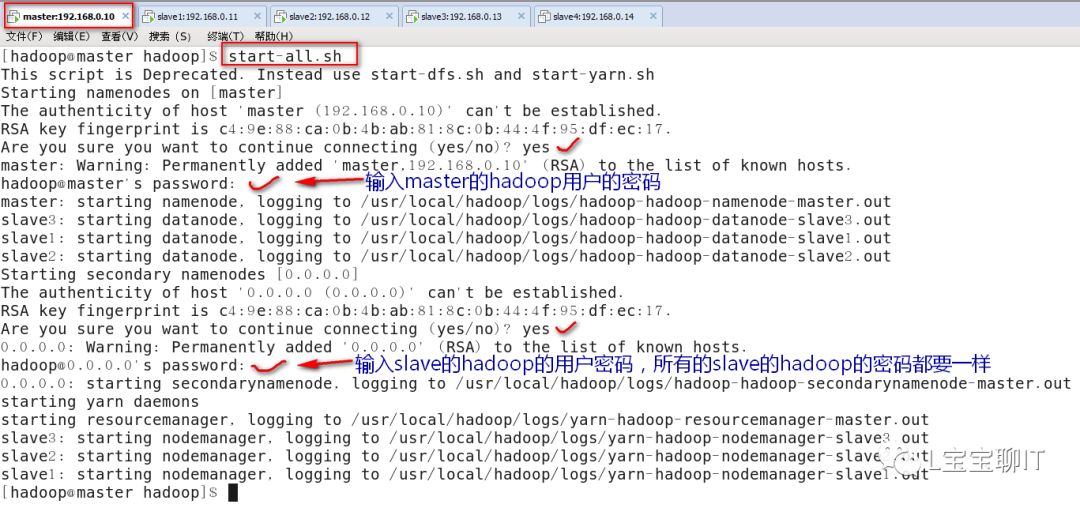
4)验证访问
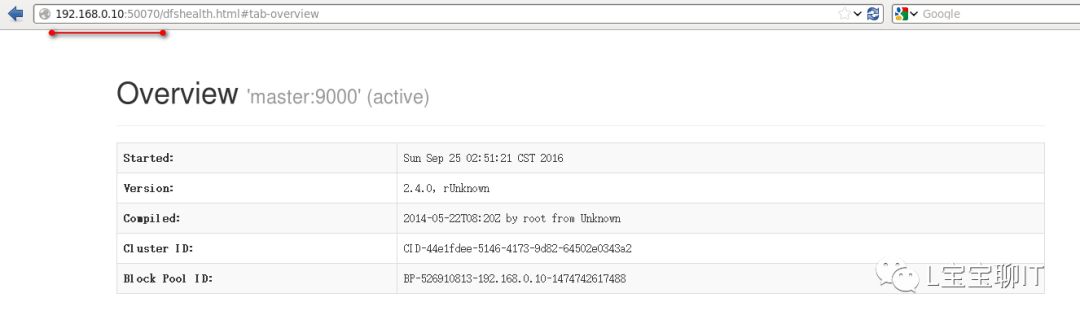
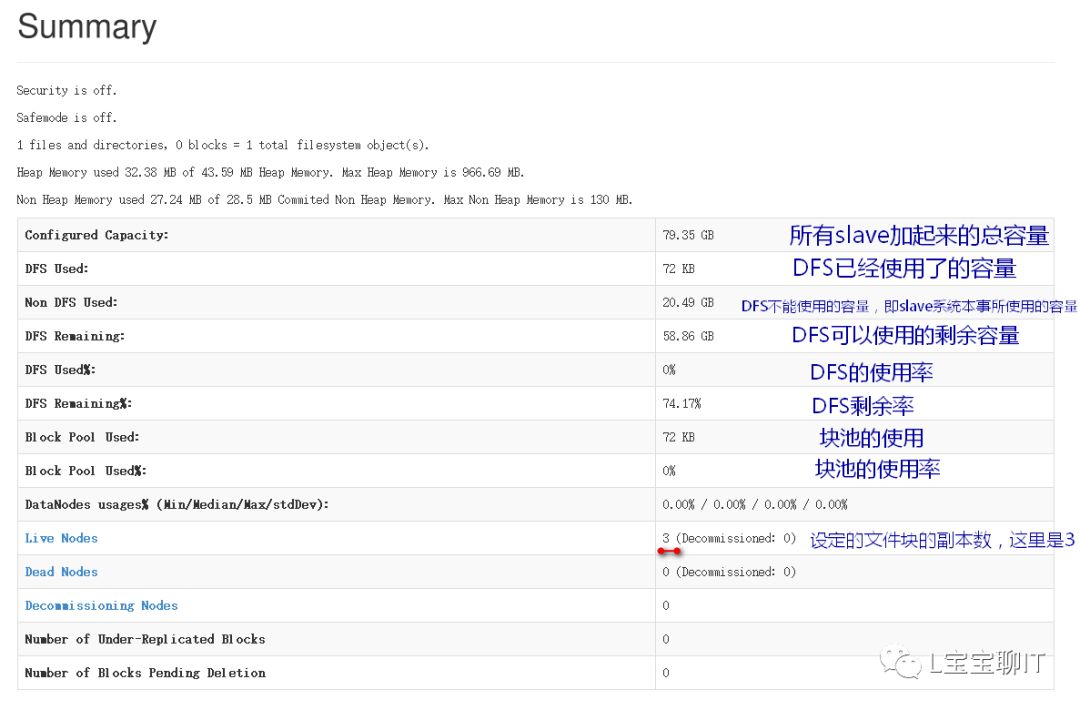
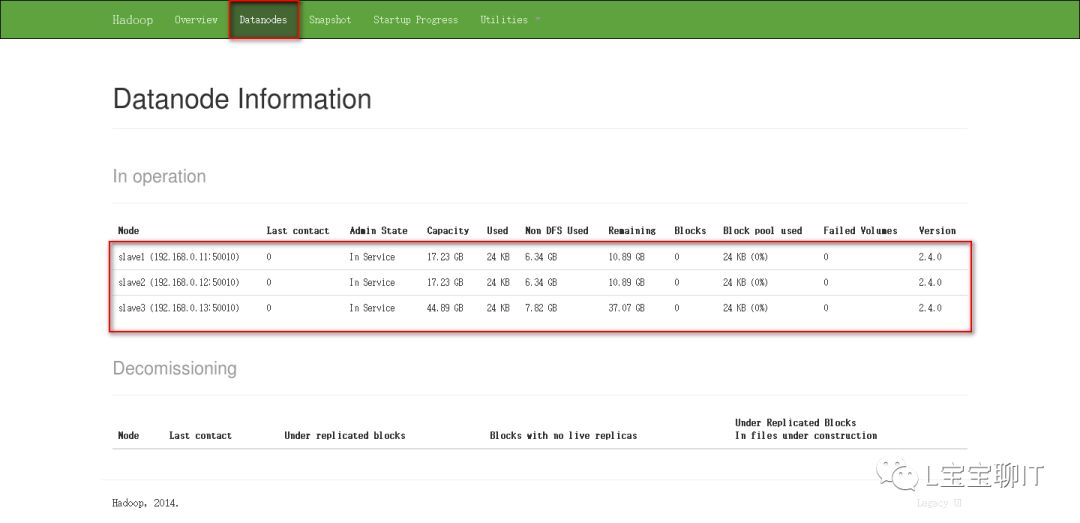
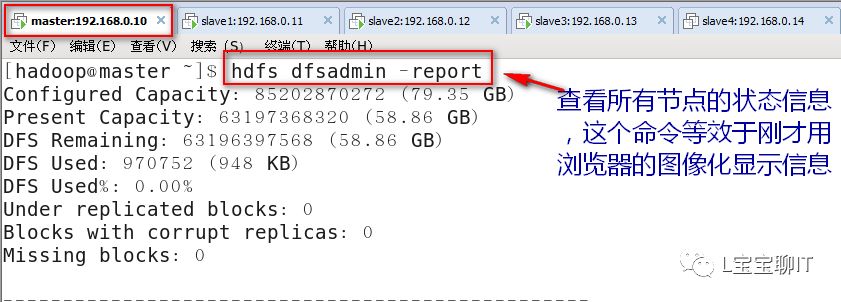
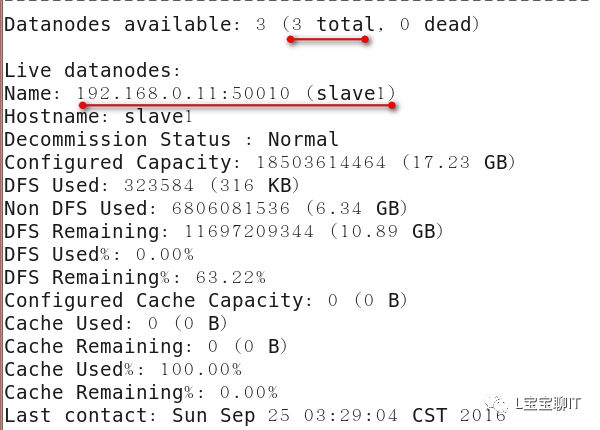
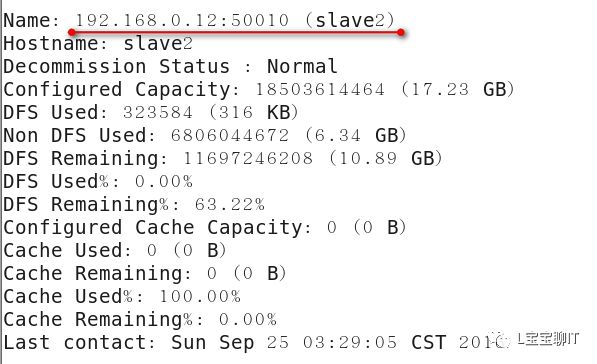
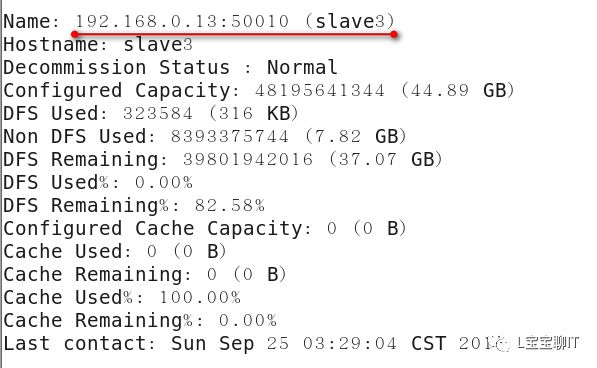
通过浏览器查看NameNode,即master,访问http://192.168.0.10:50070,可以查看视图统计信息和HDFS存储信息等。
验证之前先关闭master和所有slave的防火墙

5)hadoop基本命令
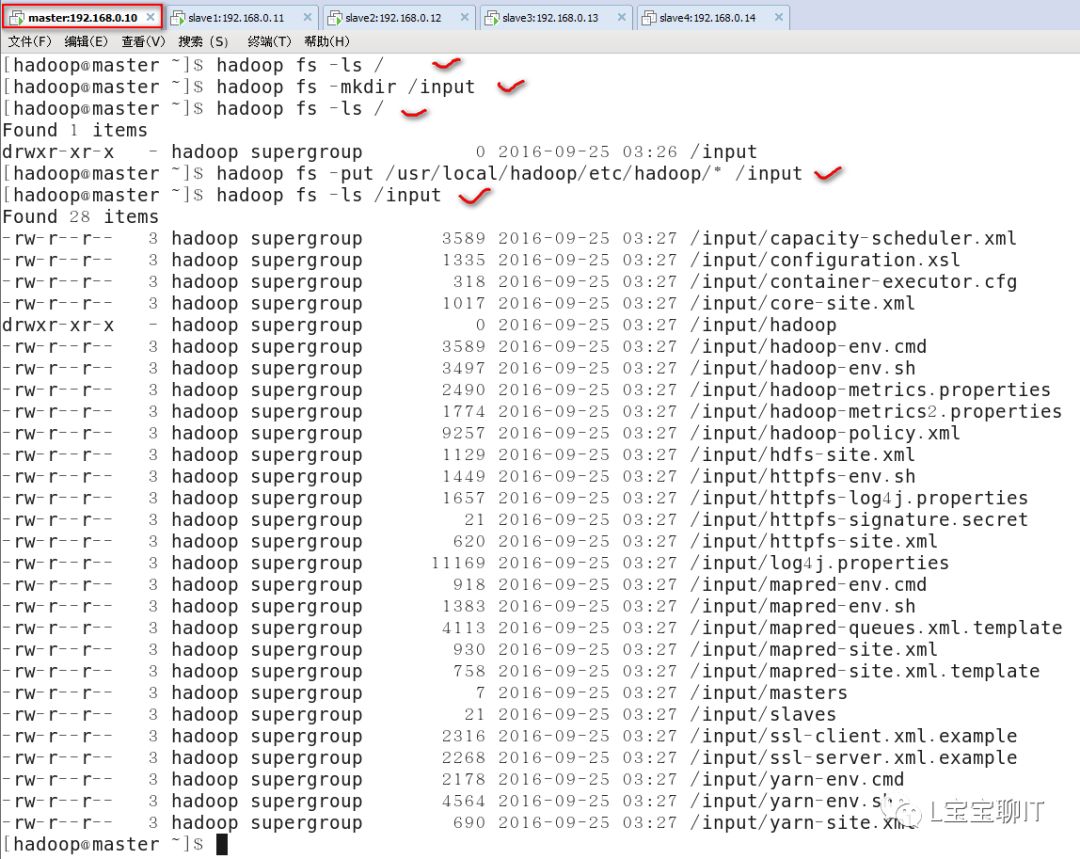
使用“hadoop fs”命令可以结合普通的文件管理命令实现很多操作,如查看、修改权限、统计、获取帮助、创建、删除、上传下载文件等,更多的用法可使用“hadoop fs -help”或“hadoop fs -usage”命令查看。
6)HDFS高级命令
⑴开机安全模式
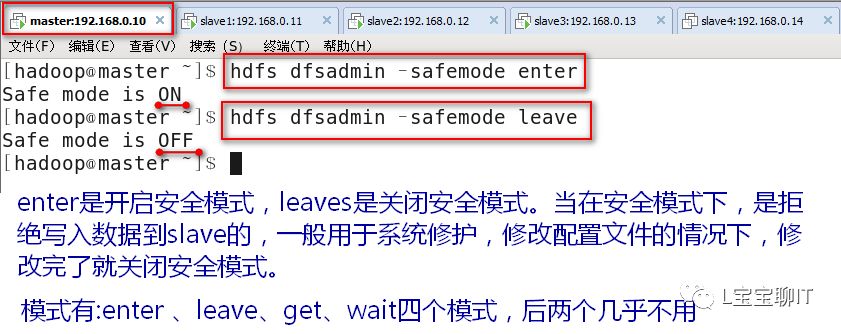
⑵复制
①将本地文件复制到HDFS上(注意不要在安全模式下)
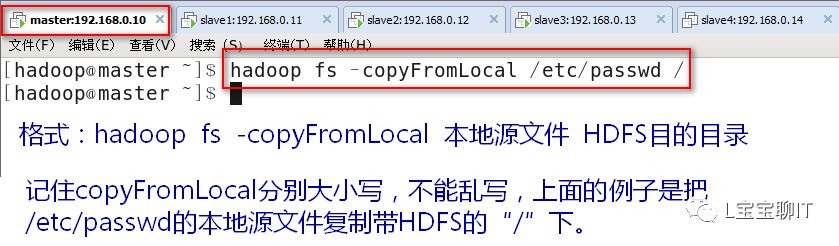
②将HDFS上的文件复制到本地
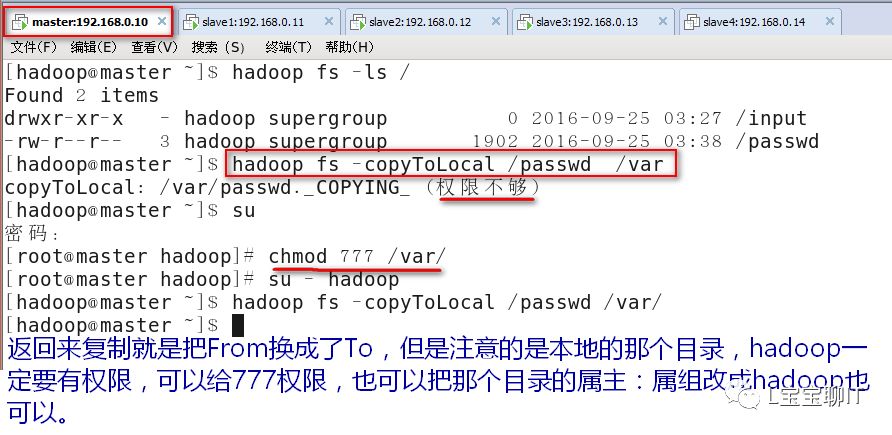
⑶权限和归属
①修改属组
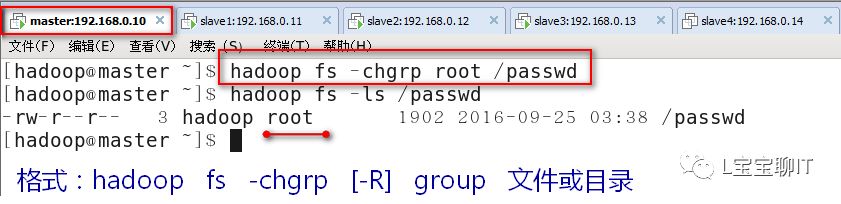
②修改权限
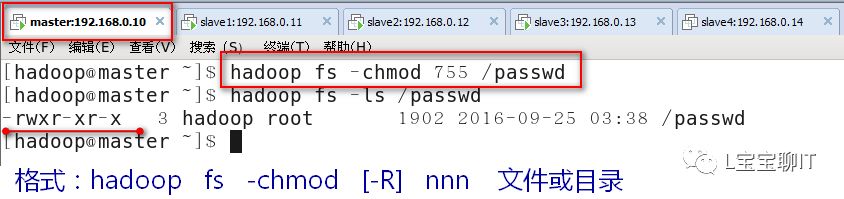
③修改所有者
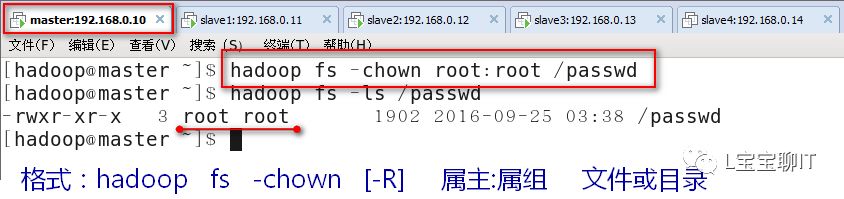
⑷统计显示目录中文件大小

⑸合并文件
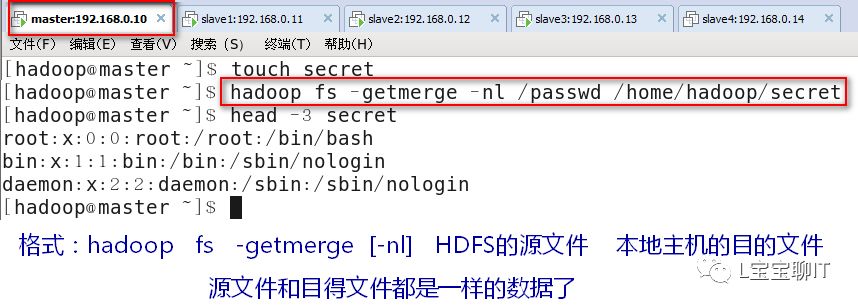
5、为HDFS集群添加节点
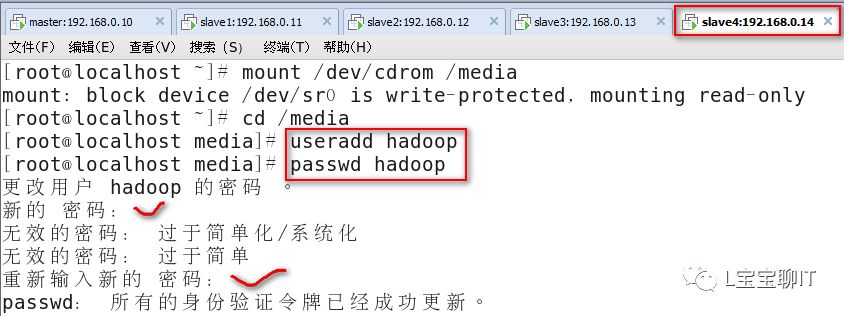
⑴slave4节点安装jdk与hadoop,配置环境变量
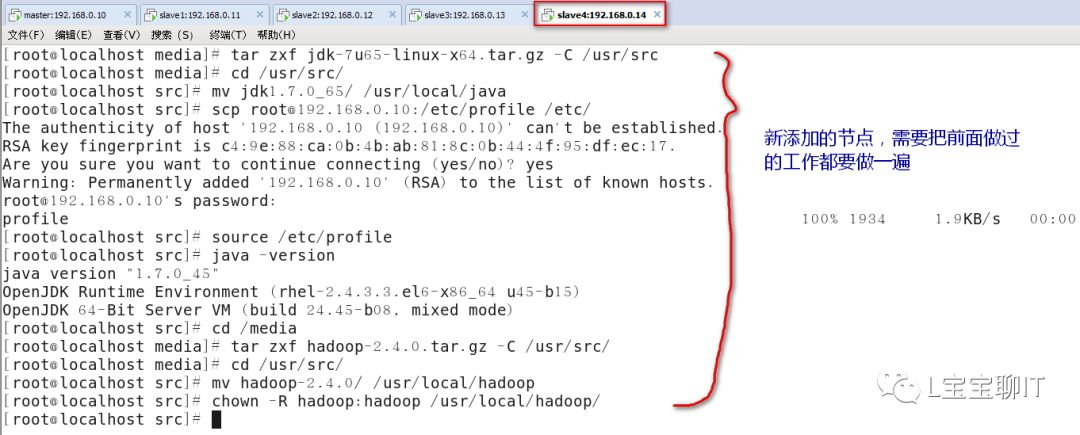
⑵配置/etc/hosts解析,NameNode与4台DataNode都要配置

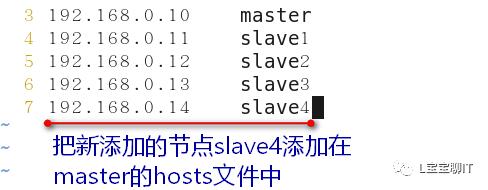






⑶配置ssh无密码连接
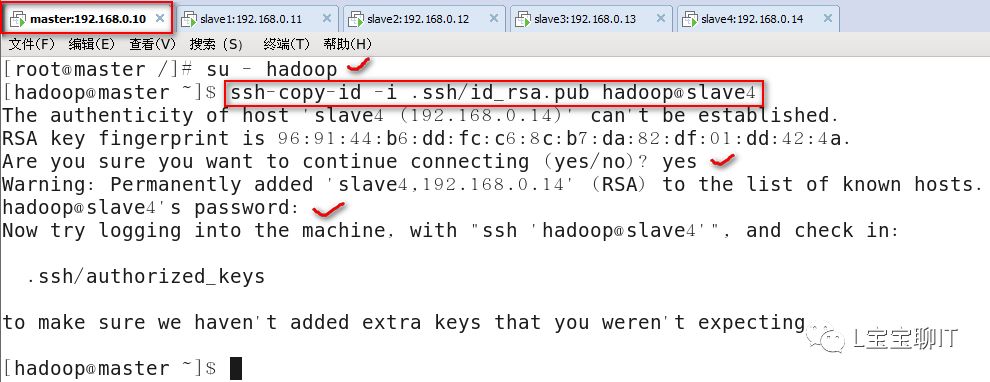
⑷在master上修改hadoop配置后,复制到其他节点






⑸新节点启动并平衡节点已经存储的数据
在slave4上
su - hadoop
之后执行下面的命令
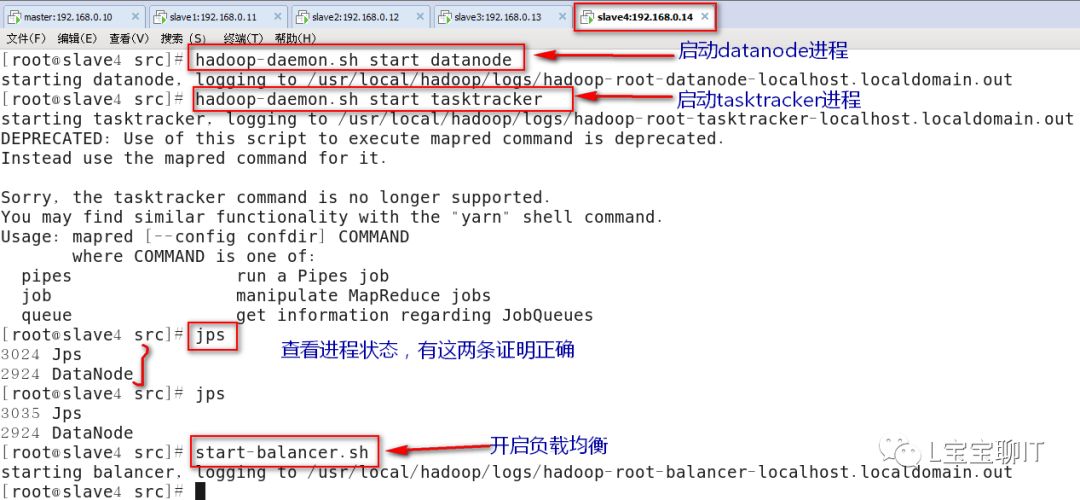
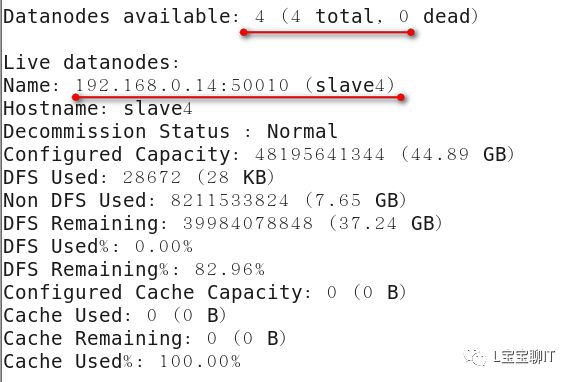
⑹查看集群信息

6、删除DataNode节点
⑴增加exclude配置,作用为存放要删除的DataNode信息。





⑵检查slave4的进程
⑶查看集群信息
以上是关于案例:HDFS分布式文件系统的主要内容,如果未能解决你的问题,请参考以下文章
独家 | 带你认识HDFS和如何创建3个节点HDFS集群(附代码&案例)