大数据 | HDFS写读数据流程
Posted JoblabX未来职业实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据 | HDFS写读数据流程相关的知识,希望对你有一定的参考价值。
HDFS写读数据流程

写数据
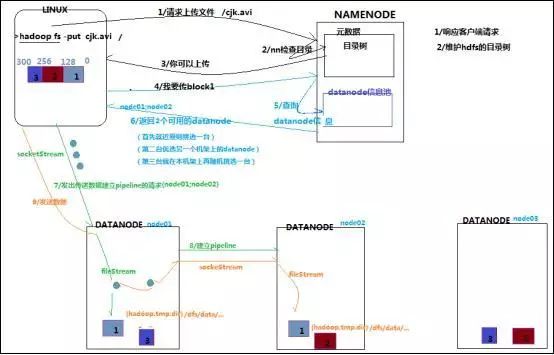
1
根namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
2
namenode返回是否可以上传
3
client请求第一个 block该传输到哪些datanode服务器上
4
namenode返回3个datanode服务器ABC
5
client请求3台dn中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将真个pipeline建立完成,逐级返回客户端
6
client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答
7
当一个block传输完成之后,client再次请求namenode上传第二个block的服务器
读数据
1
跟namenode通信查询元数据,找到文件块所在的datanode服务器
2
挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流
3
datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
4
客户端以packet为单位接收,现在本地缓存,然后写入目标文件
HDFS以流式数据访问模式来存储超大文件,运行于商用硬件集群上。
HDFS上的文件也被划分为块大小的多个分块(chunk),作为独立的存储单元。但与其他文件系统不同的是,HDFS中小于一个块大小的文件不会占据整个块的空间。
JoblabX校园科技人才俱乐部
天天留言,天天有奖
点击底部链接
申请加入JOBLABX校园科技人才俱乐部
以上是关于大数据 | HDFS写读数据流程的主要内容,如果未能解决你的问题,请参考以下文章