技术分享丨HDFS 入门
Posted 51reboot运维开发
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术分享丨HDFS 入门相关的知识,希望对你有一定的参考价值。
上周分享了 ,咱们这周来了解下HDFS,并把分享时的PPT整理出来,供大家讨论交流。
在介绍HDFS之前要说的
相关背景资料
Hadoop:一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。
Distributed:分布式计算是利用互联网上的计算机的 CPU 的共同处理能力来解决大型计算问题的一种计算科学。
File system:文件系统是操作系统用于明确磁盘或分区上的文件的方法和数据结构;即在磁盘上组织文件的方法。也指用于存储文件的磁盘或分区,或文件系统种类。
Hadoop 和 HDFS 的关系
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
对外部客户机而言,HDFS 就像一个传统的分级文件系统。可以创建、删除、移动或重命名文件,等等。很多时候,我们就叫它DFS(Distributed File System)。
Hadoop 是一个以一种可靠、高效、可伸缩的方式进行处理的,能够对大量数据进行分布式处理的系统框架。
HDFS是Hadoop兼容最好的标准级文件系统,因为Hadoop是一个综合性的文件系统抽象,所以HDFS不是Hadoop必需的。所以可以理解为Hadoop是一个框架,HDFS是Hadoop中的一个部件。

我们为什么需要HDFS
要说明需要HDFS,首先得说明一下,为什么在计算机系统中需要文件系统。操作系统中负责管理和存储文件信息的软件机构称为文件管理系统,简称文件系统。简单的理解为,只要有文件管理,就得有文件系统。
文件系统由三部分组成:与文件管理有关软件、被管理文件以及实施文件管理所需数据结构。

从系统角度来看,文件系统是对文件存储器空间进行组织和分配,负责文件存储并对存入的文件进行保护和检索的系统。
文件系统是用于存储文件的,但是我们发现现有的文件系统忙于处理什么文件呢?
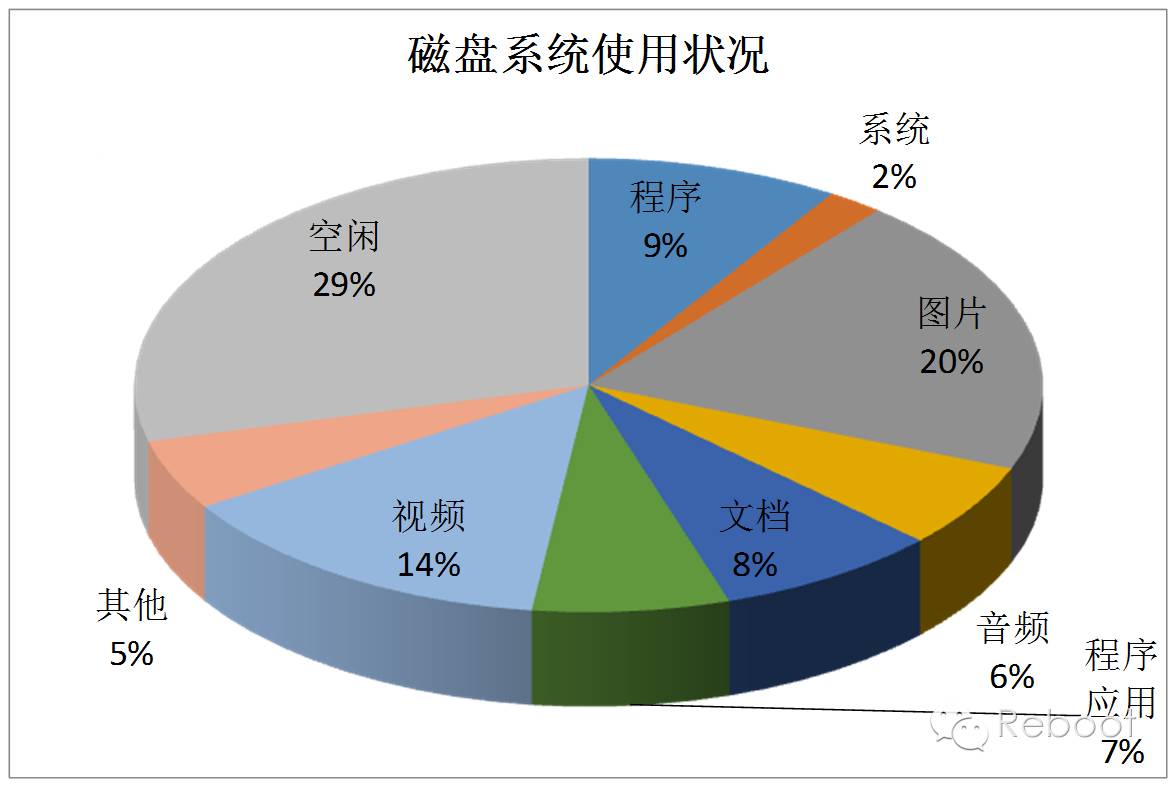
看起来现有的磁盘能够胜任目前的数据处理,但对于我们来说有一个好消息和坏消息。

磁盘面对的海量信息有证券交易所的每天1TB的信息;社交网站上2PB的图片;计算机每天产生的100GB到10TB的机器日志,缓存文件,RFID检测器等等。

既然读取一块磁盘的所有数据需要很长时间,写入更是需要更长时间(写入时间一般是读取时间的3倍)。我们需要一个巨大文件难道得换传输速度10GB/S的磁盘(现在没有这样的磁盘),而且即使有文件为1ZB,或者小点10EB时,这样的磁盘也无法做到随读随取。
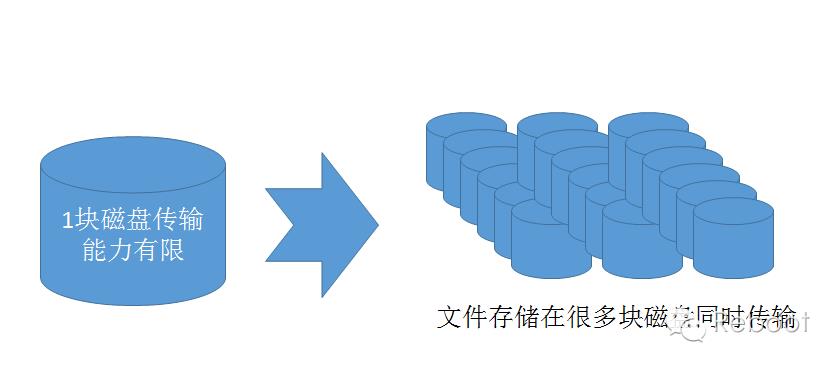
当数据集的大小超过一台独立物理计算机的存储能力时,就有必要对它进行分区并存储到若干台单独的计算机上。
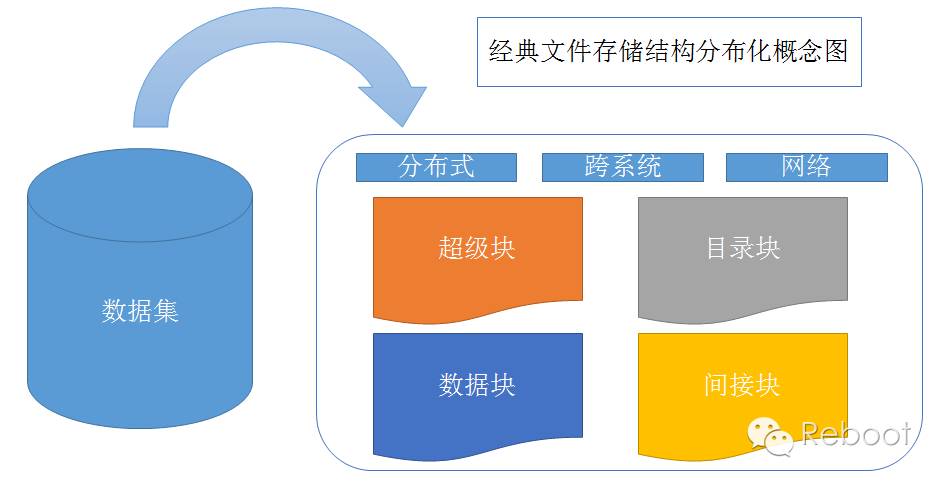
从概念图上看,分布化的文件系统会因为分布后的结构不完整,导致系统复杂度加大,并且引入的网络编程,同样导致分布式文件系统更加复杂。
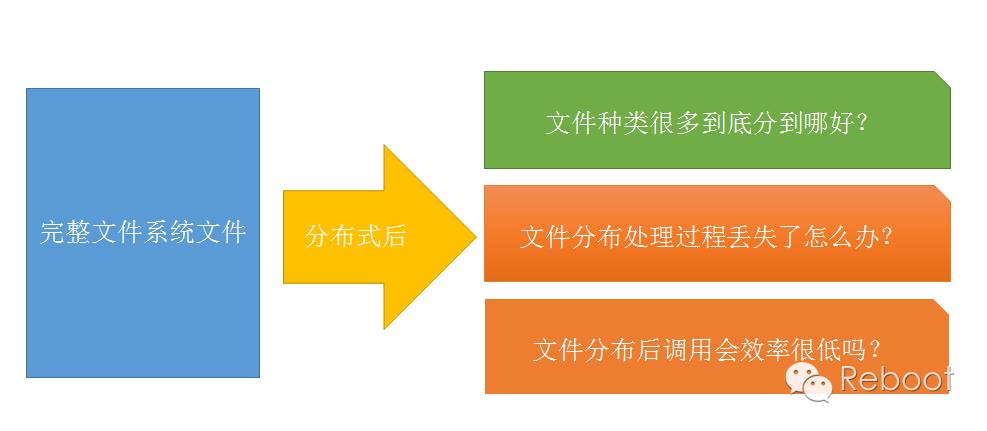
对于以上的问题我们来HDFS是如何迎刃而解的:
HDFS以流处理访问模式来存储文件的。
一次写入,多次读取。数据源通常由源生成或从数据源直接复制而来,接着长时间在此数据集上进行各类分析,大数据不需要搬来搬去。
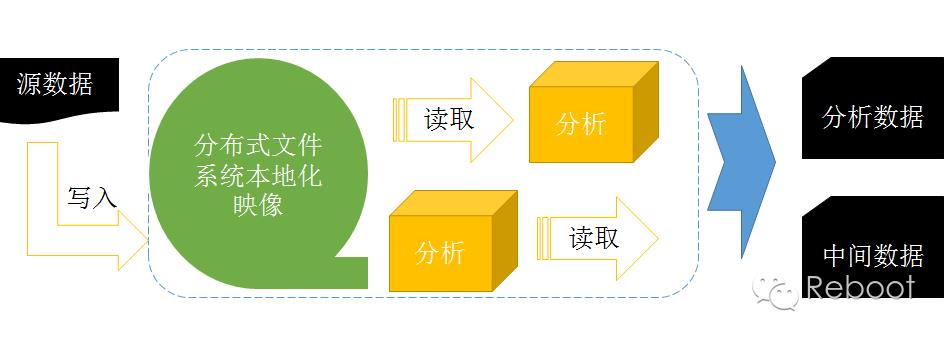
DFS是用流处理方式处理文件,每个文件在系统里都能找到它的本地化映像,所以对于用户来说,别管文件是什么格式的,也不用在意被分到哪里,只管从DFS里取出就可以了。
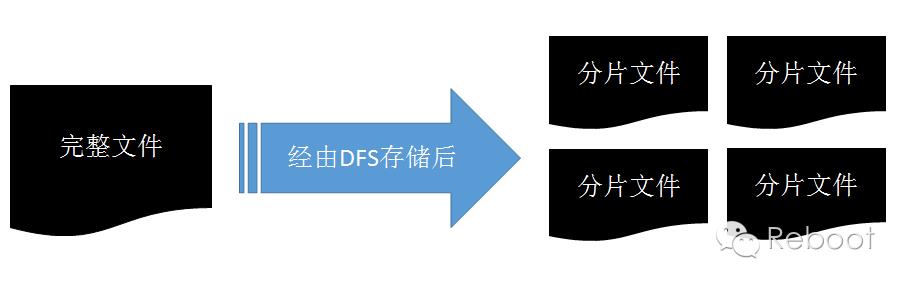
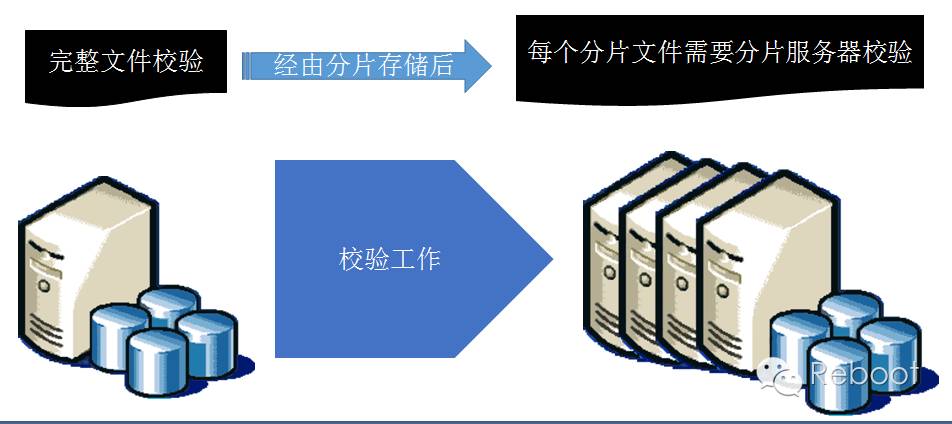
一般来说,文件处理过程中无法保证文件安全顺利到达,传统文件系统是使用本地校验方式保证数据完整,文件被散后,难道需要特意安排每个分片文件的校验码?
HDFS的回答是:NO!
分片数量和大小是不确定的,海量的数据本来就需要海量的校验过程,分片后加入每个分片的跟踪校验完全是在数满天恒星的同时数了他们的行星。
HDFS的解决方案是分片冗余,本地校验。

直观上看,我们是给文件系统添堵,文件越来越多,实际上,DFS更加喜欢这样的架构。数据冗余式存储,直接将多份的分片文件交给分片后的存储服务器去校验。
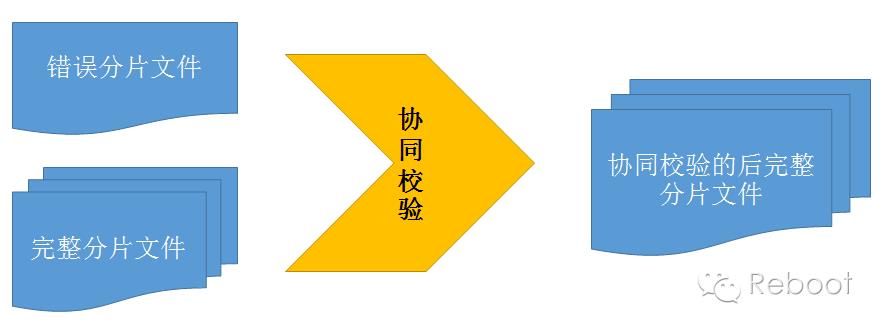
冗余后的分片文件还有个额外功能,只要冗余的分片文件中有一份是完整的,经过多次协同调整后,其他分片文件也将完整。
经过协调校验,无论是传输错误,I/O错误,还是个别服务器宕机,整个系统里的文件是完整的。
分布后的文件系统有个无法回避的问题,因为文件不在一个磁盘导致读取访问操作的延时,这个是HDFS现在遇到的主要问题。
现阶段,HDFS的配置是按照高数据吞吐量优化的,可能会以高时间延时为代价。但万幸的是,HDFS是具有很高弹性,可以针对具体应用再优化。
HDFS 的概念
通过上一节的得到的信息,我们了解了HDFS就是下面这个抽象图的具体实现:
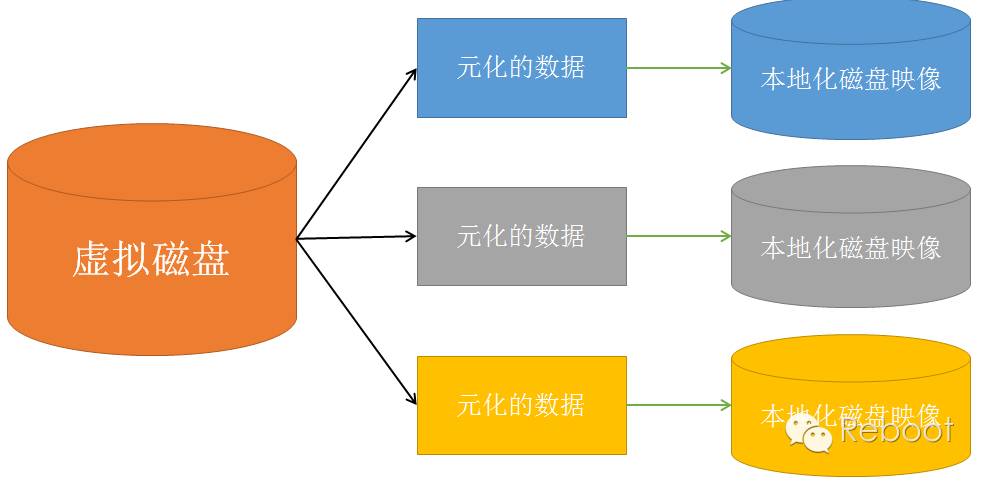
解释一下,何为元数据:
元数据是用于描述要素、数据集或数据集系列的内容、覆盖范围、质量、管理方式、数据的所有者、数据的提供方式等有关的信息。更简单的说,是关于数据的数据。
HDFS就是将巨大的数据变成大量数据的数据。
磁盘存储文件时,是按照数据块来存储的,也就是说,数据块是磁盘的读/写最小单位。数据块也称磁盘块。
构建于单个磁盘上的文件系统是通过磁盘块来管理文件系统,一般来说,文件系统块的大小是磁盘块的整数倍。特别的,单个磁盘文件系统,小于磁盘块的文件会占用整个磁盘块。磁盘块的大小一般是512字节。
在HDFS中,也有块(block)这个概念,默认为64MB,每个块作为独立的存储单元。
与其他文件系统不一样,HDFS中每个小于块大小的文件不会占据整个块的空间。具体原因在后面的介绍。下面介绍为什么是64MB一个文件块:
为什么HDFS中的小文件不会占用整个块,而且需要64MB或者更大的一个块?
在文件系统中,系统存储文件时,需要定位该数据在磁盘中的位置,再进行传输处理。
定位在磁盘的位置是需要时间的,同样文件传输也是需要时间。
T(存储时间)=T(定位时间)+T(传输时间)
如果每个要传输的块设置得足够大,那么从磁盘传输数据的时间可以明显大于定位这个块开始位置的时间。

当然不是设置每个块越大越好。
HDFS提供给MapReduce数据服务,而一般来说MapReduce的Map任务通常一次处理一个块中的数据,如果任务数太少(少于集群中节点的数量),就没有发挥多节点的优势,甚至作业的运行速度就会和单节点一样。
分布式的文件抽象能够带来的优势是:
1、一个文件可以大于每个磁盘
2、文件不用全在一个磁盘上。
3、简化了存储子系统的设计。
其实,HDFS对与用户来说,可以直接看成是一个巨大的硬盘

所以,HDFS和文件系统相似,用fsck指令可以显示块信息:% hadoop fsck / -files -blocks
HDFS 的关键运行机制
HDFS是基于主从结构(master/slaver)构件:
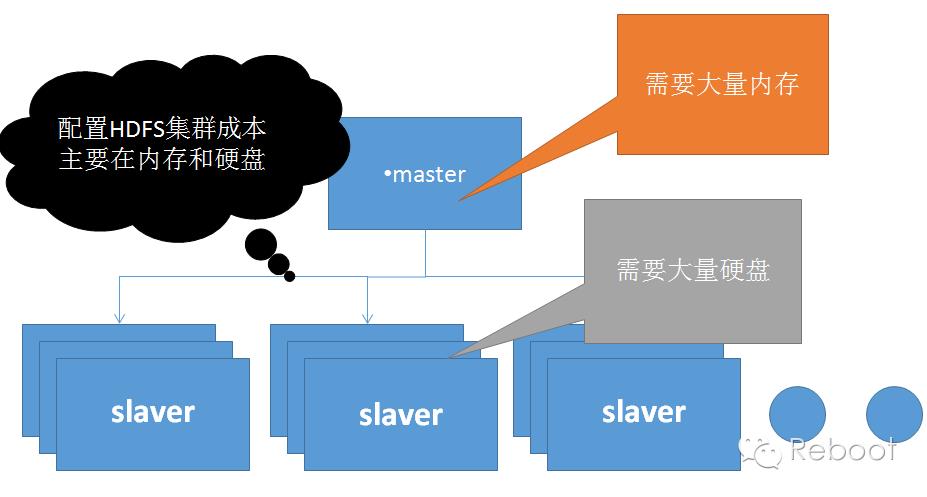
在HDFS的主从结构中,有两类节点 namenode和datanode。他们以管理者-工作者模式工作。
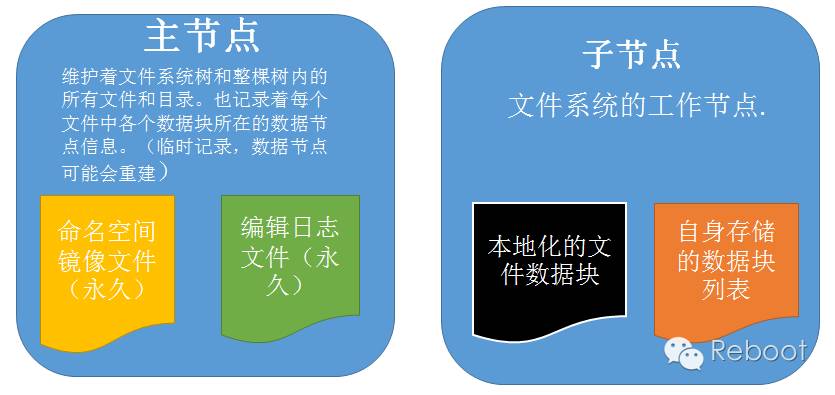
子节点才是HDFS真正的存储和检索地点,如果想在主节点做整个集群数据的索引并检索的话,请考虑可行性,毕竟HDFS不擅长做巨型索引。
客户端(client)代表用户通过与namenode和datanode交互访问整个文件系统。可以是具体程序,也可以是应用。
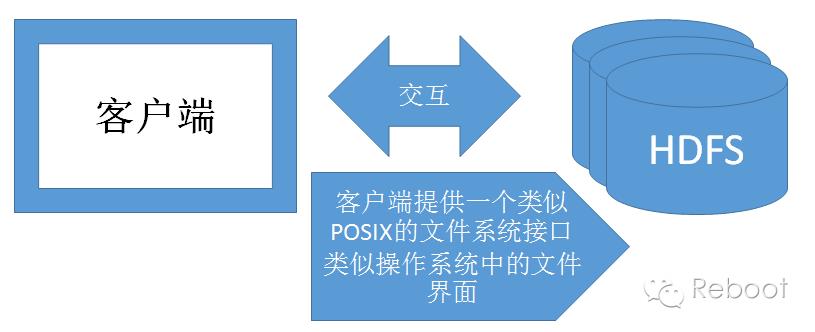
所以,用户在编程时,无需知道namenode和datanode也可以实现功能。
没有datanode,文件系统不会崩溃,文件系统只是无法存储文件,也不会丢失数据。没有namenode,文件系统会崩溃,文件系统上的所有文件将丢失(无法读出,因为无法定位元数据块的位置,也就无法根据datanode的块来重构文件)。

如何使用HDFS
HDFS是在安装并成功配置后即可使用。具体安装过程不再赘述。
无论是使用shell脚本,或者使用WEB UI进行操作,使用前必须得明白HDFS的配置。便于存储操作或者操作优化。
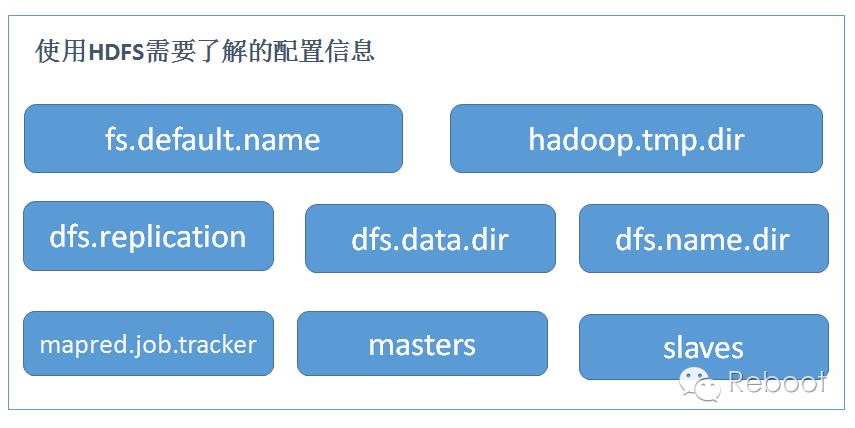
例如我们使用伪分布式配置(也就是1个namenode和1个datanode配置方式)。

说明hdfs的URI是localhost,hdfs的守护进程将通过该属性确定namenode的主机和端口。分布式文件系统将文件存储为1份备份。
常用HDFS命令

分享和交流
1、想要参加“技术沙龙-周五课堂”的小伙伴请加群:
Reboot 周五分享群 368573673
2、报名请联系:
Ada:279312229
小夏:979950755
3、微信群—大数据技术分享交流群

版权声明:本文档中涉及到Hadoop、CDH、Apache、HDFS等文字和图标皆来源于网络,其所有权归原始所有者所有。
以上是关于技术分享丨HDFS 入门的主要内容,如果未能解决你的问题,请参考以下文章