实战|HDFS监控运维最佳实践
Posted spark技术分享
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实战|HDFS监控运维最佳实践相关的知识,希望对你有一定的参考价值。
本文转自 | 京东云
京东云
应用研发部
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。在大数据生态圈中,HDFS是最重要的底层分布式文件系统,它的稳定性关乎整个生态系统的健康。本文介绍了HDFS相关的重要监控指标,分享指标背后的思考。enjoy:
HDFS监控挑战
HDFS是Hadoop生态的一部分,监控方案不仅需适用HDFS,其他组件如Yarn、Hbase、Hive等,也需适用
HDFS API提供的指标较多,部分指标没必要实时采集,但故障时需能快速获取到
Hadoop相关组件的日志,比较重要,如问题定位、审计等
监控方案不仅能满足监控本身,故障定位涉及指标也应覆盖
Hadoop监控方案
Hadoop监控数据采集通过HTTP API,或者JMX。实际中,用到比较多的产品主要有:CDH、Ambari,此外,还有部分工具,如Jmxtrans、HadoopExporter(用于Prometheus)。
CDH为Cloudera公司开源的一款集部署、监控、操作等于一体的Hadoop生态组件管理工具,也提供收费版(比免费版多提供数据备份恢复、故障定位等特性)。CDH提供的HDFS监控界面在体验上是非常优秀的,是对HDFS监控指标深入发掘之后的浓缩,比如HDFS容量、读写流量及耗时、Datanode磁盘刷新耗时等。
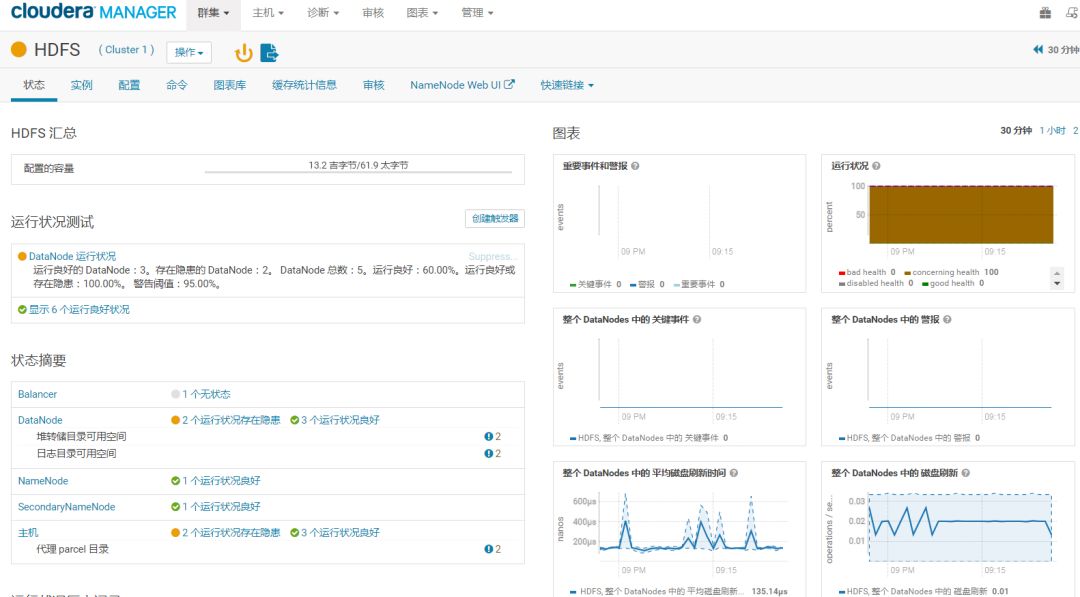
图1 CDH提供的HDFS监控界面
Ambari与CDH类似,它是Hortonworks公司(与Cloudera公司已合并)开源。它的扩展性要比较好,另外,它的信息可以从机器、组件、集群等不同维度展现,接近运维工程师使用习惯。
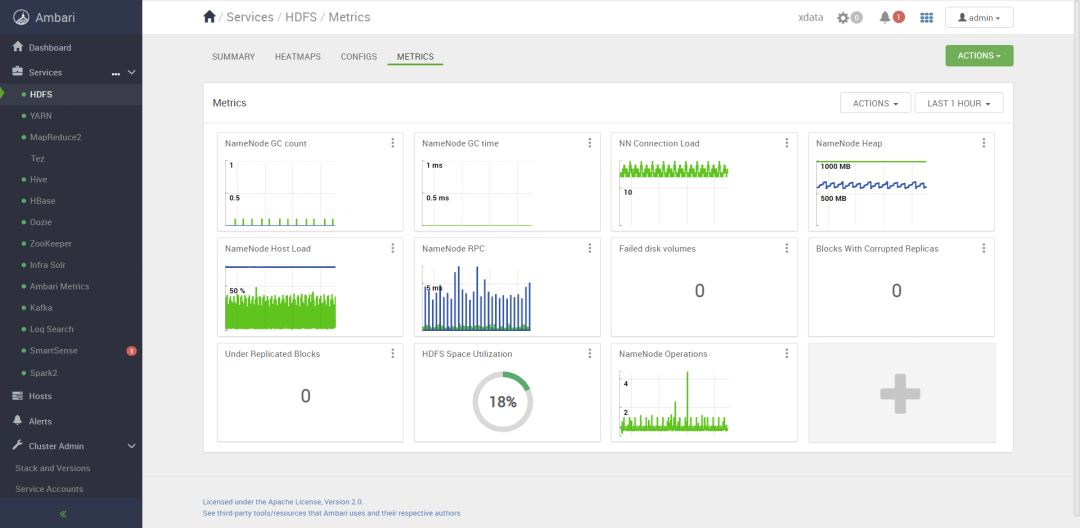
图2 Ambari提供的HDFS监控界面
如果使用CDH,或者Ambari进行HDFS监控,也存在实际问题:
对应的Hadoop及相关组件版本不能自定义
不能很好的满足大规模HDFS集群实际监控需求
其他工具,如Jmxtrans目前还不能很好适配Hadoop,因此,实际的监控方案选型为:
采集:HadoopExporter,Hadoop HTTP API(说明:HDFS主要调用http://{domain}:{port}/jmx)
日志:通过ELK来收集、分析
存储:Prometheus
展现:Grafana,HDFS UI,Hue
告警:对接京东云告警系统
HDFS监控指标
主要指标概览
表1 HDFS主要监控指标概览
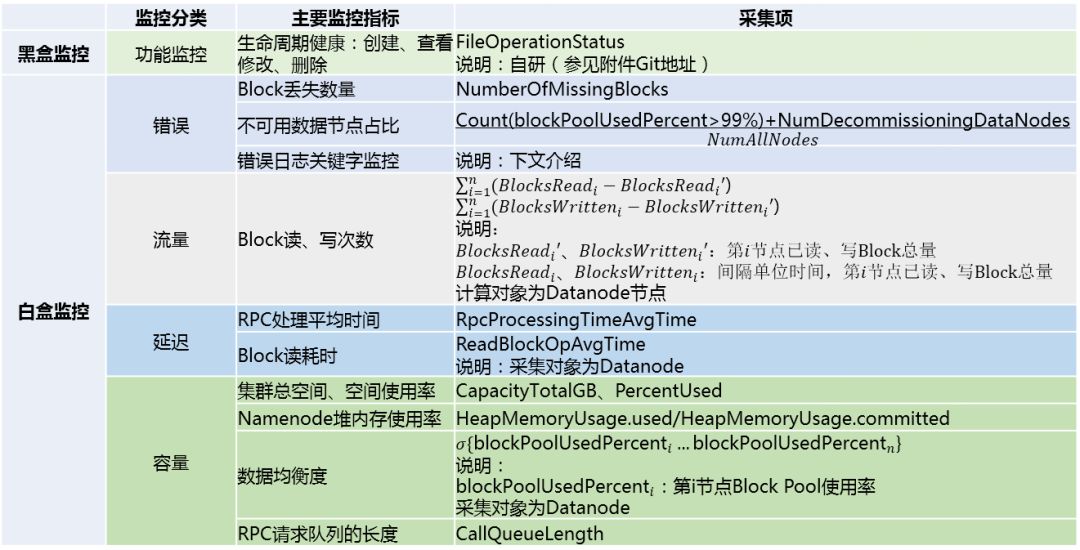
黑盒监控指标
基本功能
文件整个生命周期中,是否存在功能异常,主要监控创建、查看、修改、删除动作。
查看时,需校对内容,有一种方式,可以在文件中写入时间戳,查看时校对时间戳,这样,可以根据时间差来判断是否写超时
切记保证生命周期完整,否则,大量监控产生的临时文件可能导致HDFS集群垮掉
白盒监控指标
错误
Block丢失数量
采集项:MissingBlocks
如果出现块丢失,则意味着文件已经损坏,所以需要在块丢失前,提前预判可能出现Block丢失风险(通过监控UnderReplicatedBlocks来判断)。
不可用数据节点占比
采集项:
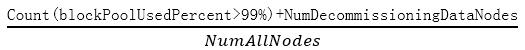
在BlockPlacementPolicyDefault.java中的isGoodTarget定义了选取Datanode节点策略,其中有两项是“节点是否在下线”、“是否有足够存储空间”,如果不可用数量过多,则可能导致选择不到健康的Datanode,因此,必须保证一定数量的健康Datanode。

图4 选取可用Datanode时部分判断条件
错误日志关键字监控
部分常见错误监控(主要监控Exception/ERROR),对应关键字:
IOException、NoRouteToHostException、SafeModeException、UnknownHostException。
未复制Block数
采集项:UnderReplicatedBlocks
UnderReplicatedBlocks在数据节点下线、数据节点故障等均会产生大量正在同步的块数。
FGC监控
采集项:FGC
读写成功率
采集项:
monitor_write.status/monitor_read.status
根据Block实际读写流量汇聚计算,是对外SLA指标的重要依据。
数据盘故障
采集项:NumFailedVolumes
如果一个集群有1000台主机,每台主机是12块盘(一般存储型机器标准配置),那么这将会是1万2000块数据盘,按照机械盘平均季度故障率1.65%(数据存储服务商Backblaze统计)计算,平均每个月故障7块盘。若集群规模再扩大,那么运维工程师将耗费很大精力在故障盘处理与服务恢复上。很显然,一套自动化的数据盘故障检测、自动报修、服务自动恢复机制成为刚需。
除故障盘监控外,故障数据盘要有全局性解决方案。在实践中,以场景为维度,通过自助化的方式来实现对此问题处理。

图5 基于场景实现的Jenkins自助化任务
流量
Block读、写次数
采集项:
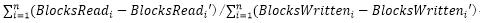
采集Datanode数据进行汇聚计算。
网络进出流量
采集项:
node_network_receive_bytes_total/ node_network_transmit_bytes_total
没有直接可以使用的现成数据,需要通过ReceivedBytes(接收字节总量)、SentBytes(发送字节总量)来计算。
磁盘I/O
采集项:node_disk_written_bytes_total/ node_disk_read_bytes_total
延迟
RPC处理平均时间
采集项:RpcQueueTimeAvgTime
采集RpcQueueTimeAvgTime(RPC处理平均时间)、SyncsAvgTime(Journalnode同步耗时)。
慢节点数量
采集项:SlowPeerReports
慢节点主要特征是,落到该节点上的读、写较平均值差距较大,但给他足够时间,仍然能返回正确结果。通常导致慢节点出现的原因除机器硬件、网络外,对应节点上的负载较大是另一个主要原因。实际监控中,除监控节点上的读写耗时外,节点上的负载也需要重点监控。
根据实际需要,可以灵活调整Datanode汇报时间,或者开启“陈旧节点”(Stale Node)检测,以便Namenode准确识别故障实例。涉及部分配置项:
dfs.namenode.heartbeat.recheck-interval
dfs.heartbeat.interval
dfs.namenode.avoid.read.stale.datanode
dfs.namenode.avoid.write.stale.datanode
dfs.namenode.stale.datanode.interval
容量
集群总空间、空间使用率
采集项:PercentUsed
HDFS UI花费了很大篇幅来展现存储空间相关指标,足以说明它的重要性。
空间使用率计算包含了处于“下线中”节点空间,这是一个陷阱。如果有节点处于下线状态,但它们代表的空间仍计算在总空间,如果下线节点过多,存在这样“怪象”:集群剩余空间很多,但已无空间可写。
此外,在Datanode空间规划时,要预留一部分空间。HDFS预留空间有可能是其他程序使用,也有可能是文件删除后,但一直被引用,如果“Non DFS Used”一直增大,则需要追查具体原因并优化,可以通过如下参数来设置预留空间:
dfs.datanode.du.reserved.calculator
dfs.datanode.du.reserved
dfs.datanode.du.reserved.pct
作为HDFS运维开发人员,需清楚此公式:Configured Capacity = Total Disk Space - Reserved Space = Remaining Space + DFS Used + Non DFS Used。
Namenode堆内存使用率
采集项:
HeapMemoryUsage.used/HeapMemoryUsage.committed
如果将此指标作为HDFS核心指标,也是不为过的。元数据和Block映射关系占据了Namenode大部分堆内存,这也是HDFS不适合存储大量小文件的原因之一。堆内存使用过大,可能会出现Namenode启动慢,潜在FGC风险,因此,堆内存使用情况需重点监控。
实际中,堆内存使用率增加,不可避免,给出有效的几个方案:
调整堆内存分配
建立文件生命周期管理机制,及时清理部分无用文件
小文件合并
使用HDFS Federation横向扩展
尽管这些措施可以在很长时间内,有效降低风险,但提前规划好集群也是很有必要。
数据均衡度
采集项:
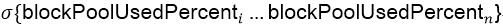
HDFS而言,数据存储均衡度,一定程度上决定了它的安全性。实际中,根据各存储实例的空间使用率,来计算这组数据的标准差,用以反馈各实例之间的数据均衡程度。数据较大情况下,如果进行数据均衡则会比较耗时,尽管通过调整并发度、速度也很难快速的完成数据均衡。针对这种情况,可以尝试优先下线空间已耗尽的实例,之后再扩容的方式来实现均衡的目的。还有一点需注意,在3.0版本之前,数据均衡只能是节点之间的均衡,不能实现节点内部不同数据盘的均衡。
RPC请求队列的长度
采集项:CallQueueLength(RPC请求队列长度)。
文件数量
采集项:FilesTotal
与堆内存使用率配合使用。每个文件系统对象(包括文件、目录、Block数量)至少占有150字节堆内存,根据此,可以粗略预估出一个Namenode可以保存多少文件。根据文件与块数量之间的关系,也可以对块大小做一定优化。
下线实例数
采集项:NumDecommissioningDataNodes
HDFS集群规模较大时,实时掌握健康实例说,定期修复故障节点并及时上线,可以为公司节省一定成本。
其他
除上述主要指标外,服务器、进程JVM、依赖服务(Zookeeper、DNS)等通用监控策略也需添加。
HDFS监控落地
Grafana仪表盘展现:主要用于服务巡检、故障定位(说明:Grafana官方提供的HDFS监控模板,数据指标相对较少)
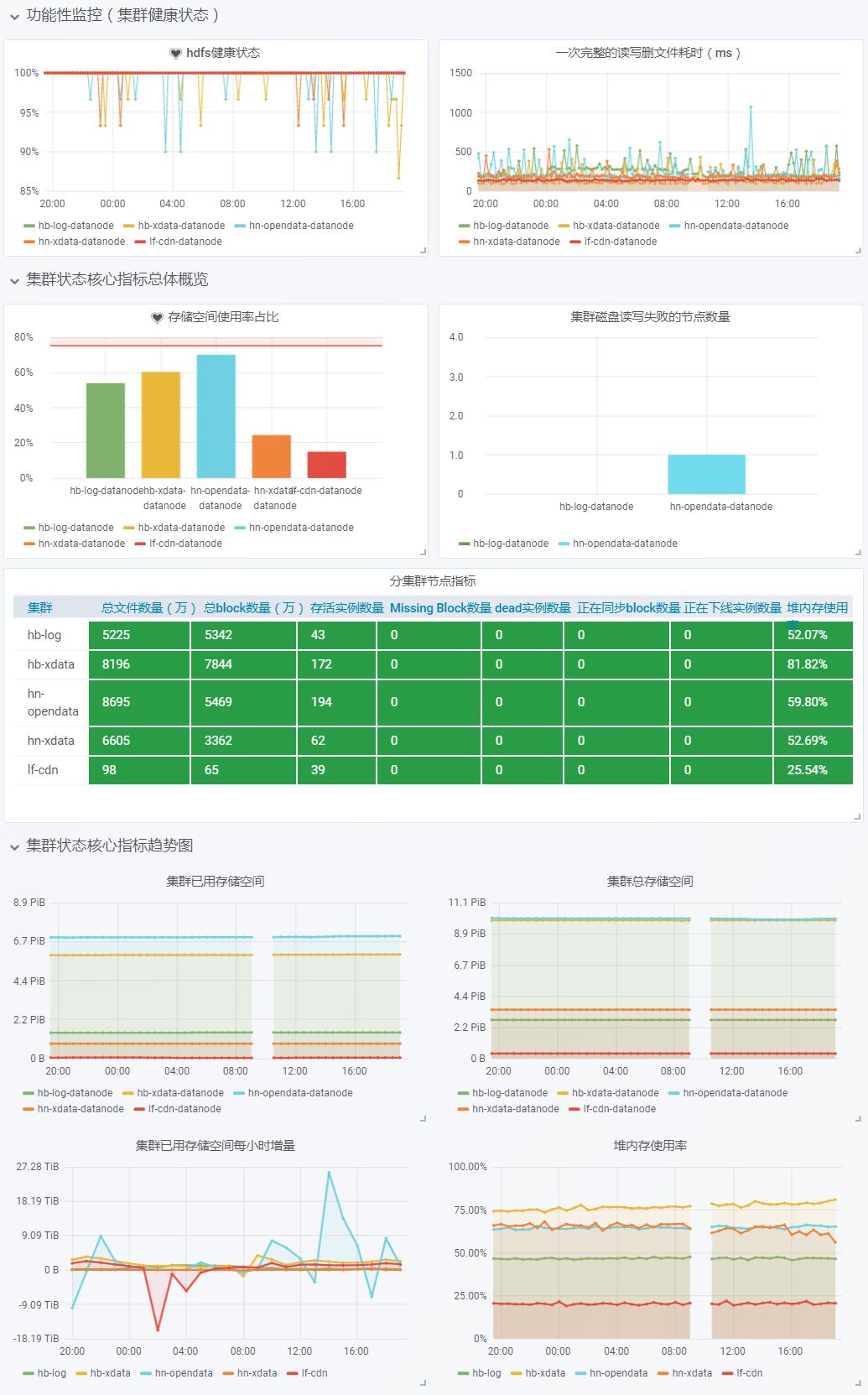
图6 HDFS部分集群Grafana仪表盘
ELK-Hadoop:主要用于全局日志检索,以及错误日志关键字监控
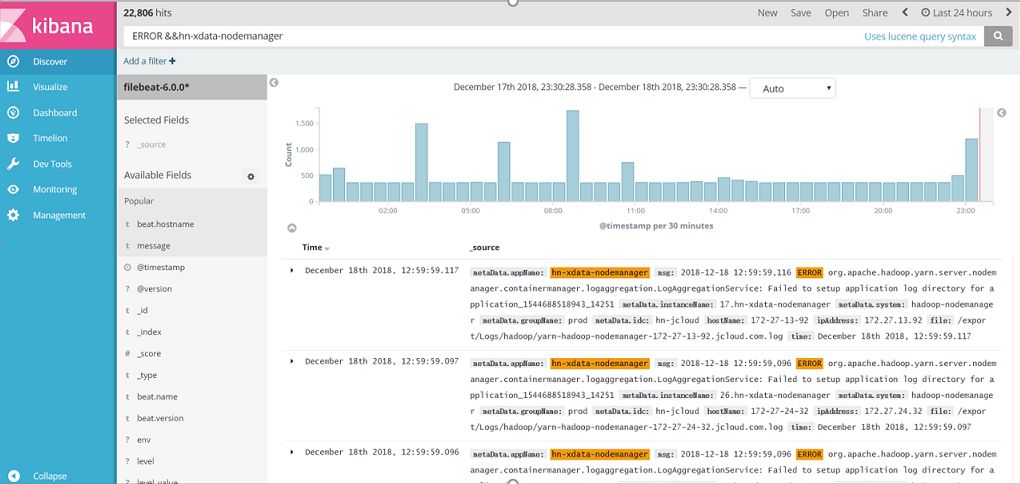
图7 ES中搜索HDFS集群日志
图8 日志服务搜索HDFS集群日志
Hue、HDFS UI:主要用于HDFS问题排查与日常维护
HDFS案例
案例1
DNS产生脏数据,导致Namenode HA故障
发现方式:功能监控、SLA指标异常
故障原因:DNS服务器产生脏数据,致使Namenode主机名出错,在HA切换时,因找到错误主机而失败
优化建议:DNS作为最基础服务,务必保证其数据正确与稳定,在一定规模情况下,切忌使用修改/etc/hosts方式来解决主机名问题,如果没有高可用的内部DNS服务,建议使用DNSMasq来搭建一套DNS服务器
案例2
机架分组不合理,导致HDFS无法写入
发现方式:功能监控写异常偶发性告警
故障原因:HDFS开启机架感知,不同分组机器资源分配不合理,部分分组存储资源耗尽,在选择Datanode时,找不到可用节点
优化建议:合理分配各机架上的实例数量,并分组进行监控。在规模较小情况下,可用考虑关闭机架感知功能
附:
HDFS监控自定义任务:
https://github.com/cloud-op/monitor
大家都在看
▼
spark sql源码系列:
structured streaming 系列:
spark streaming 系列:
spark core 系列:
spark 机器学习系列
关注【spark技术分享】
一起撸spark源码,一起玩spark最佳实践
以上是关于实战|HDFS监控运维最佳实践的主要内容,如果未能解决你的问题,请参考以下文章
最佳实践|从Producer 到 Consumer,如何有效监控 Kafka
最佳实践|从Producer 到 Consumer,如何有效监控 Kafka