最佳实践|Spring Boot 应用如何快速接入 Prometheus 监控
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最佳实践|Spring Boot 应用如何快速接入 Prometheus 监控相关的知识,希望对你有一定的参考价值。
简介:SpringBoot 微服务的开发、发布与部署只占其生命周期的一小部分,应用和系统运维才是重中之重。而运维过程中,监控工作更是占据重要位置。那么,为了对系统的状态进行持续地观测,面向Spring Boot应用我们该如何快速实现Prometheus监控接入。本文为大家详细讲解完整接入流程与接入事项!
作者:凡星
对于开发者而言,大部分传统 SSM 结构的 MVC 应用背后的糟糕体验都是来自于搭建项目时的大量配置,稍有不慎就可能踩坑。为了解决上述问题,Spring Boot 应运而生。正如其名,Spring Boot 的核心价值就是自动配置,只要存在相应 jar 包,Spring 可以自动配置。如果默认配置不能满足需求,还可以替换掉自动配置类,使用自定义配置,快速构建企业级应用程序。
但构建 Spring Boot 应用只是第一步,随着应用上线之后,我们又该如何进行监测?
基础知识及概念
首先,在正式讲解前,先向大家讲解本次分享所需要的基本知识和概念。一般来说,搭建一套完整易用的监测系统主要包含以下几个关键部分。
收集监测数据
目前,行业常见的收集监测数据方式主要分为推送(Push)和抓取(Pull)两个模式。以越来越广泛应用的 Prometheus 监测体系举例,Prometheus 就是以抓取(Pull)模式运行的典型系统。应用及基础设施的监测数据以 OpenMetrics 标准接口的形式暴露给 Prometheus,由 Prometheus 进行定期抓取并长期存储。
这里简单介绍一下 OpenMetrics。作为云原生、高度可扩展的指标协议, OpenMetrics 定义了大规模上报云原生指标的事实标准,并支持文本表示协议和 Protocol Buffers 协议,文本表示协议在其中更为常见,也是在 Prometheus 进行数据抓取时默认采用的协议。下图是一个基于 OpenMetrics 格式的指标表示格式样例。
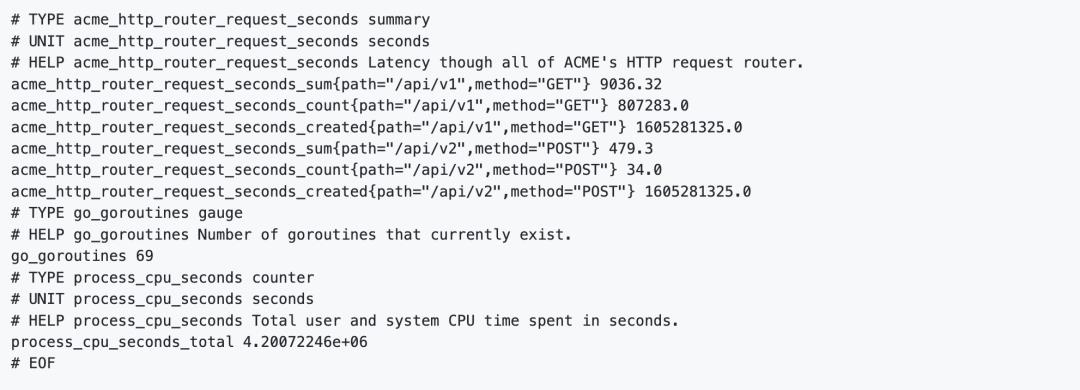
指标的数据模型由指标(Metric)名,以及一组 key/value 标签(Label)定义的,具有相同的度量名称以及标签属于相同时序集合。例如 acme_http_router_request_seconds_sumpath="/api/v1",method="GET" 可以表示指标名为 acme_http_router_request_seconds_sum,标签 method 值为 POST 的一次采样点数据。采样点内包含一个 float64 值和一个毫秒级的 UNIX 时间戳。随着时间推移,这些收集起来的采样点数据将在图表上实时绘制动态变化的线条。
目前,对于云原生体系下的绝大多数基础组件,大多能够支持以上面提到的 OpenMetrics 的文本协议格式暴露指标,对于尚未能够支持自身暴露指标的组件, Prometheus 社区也存在极其丰富的 Prometheus Exporter 供开发及运维人员使用。这些组件(或 Exporter)通过响应来自 Prometheus 的定期抓取请求来及时地将自身的运行状况记录到 Prometheus 以便后续的处理及分析。对于应用开发者,还可以通过 Prometheus 多语言 SDK,进行代码埋点,将自身的业务指标也接入到上述的 Prometheus 生态当中。
数据可视化及分析
在获取应用或基础设施运行状态、资源使用情况,以及服务运行状态等直观信息后,通过查询和分析多类型、多维度信息能够方便的对节点进行跟踪和比较。同时,通过标准易用的可视化大盘去获知当前系统的运行状态。比较常见的解决方案就是 Grafana,作为开源社区中目前热度很高的数据可视化解决方案,Grafana 提供了丰富的图表形式与模板。在阿里云 ARMS Prometheus 监控服务中,也基于 Grafana 向用户提供了全托管版的监测数据查询、分析及可视化。
及时的告警和应急管理
当业务即将出现故障时,监测系统需要迅速反应并通知管理员,从而能够对问题进行快速的处理或者提前预防问题的发生,避免出现对业务的影响。当问题发生后,管理员需要对问题进行认领和处理。通过对不同监测指标以及历史数据的分析,能够找到并解决根源问题。
接入流程概览
接下来,我们讲讲面向部署在 Kubernetes 集群上的 Spring Boot 微服务应用如何进行 Prometheus 接入。针对 Spring Boot 应用,社区提供了开箱即用的 Spring Boot Actuator 框架,方便 Java 开发者进行代码埋点和监测数据收集、输出。从 Spring Boot 2.0 开始,Actuator 将底层改为 Micrometer,提供了更强、更灵活的监测能力。Micrometer 是一个监测门面,可以类比成监测界的 Slf4j 。借助 Micrometer,应用能够对接各种监测系统,例如:AppOptics,Datadog,Elastic,InfluxDB 等,当然,也包括我们今天所介绍的 Prometheus。
Micrometer 在将 Prometheus 指标对接到 Java 应用的指标时,支持应用开发者用三个类型的语义来映射:
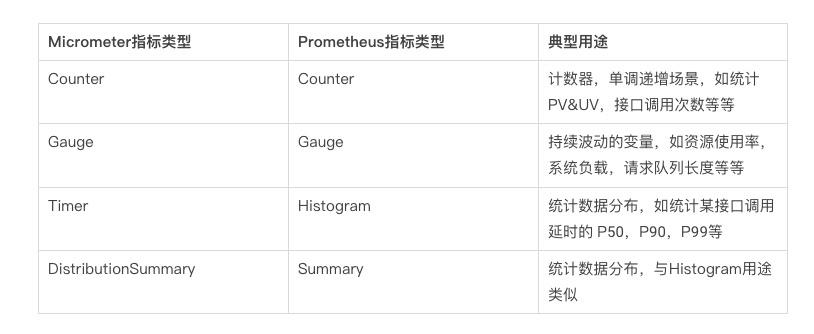
- MicroMeter 中的 Counter 对应于 Prometheus 中的 Counter,用来描述一个单调递增的变量,如某个接口的访问次数,缓存命中/访问总次数等。Timer 在逻辑上蕴含了 Counter,即如果使用 Timer 采集每个接口的响应时间,必然也会采集访问次数。故无需为某个接口同时指定 Timer 与 Counter 两个指标
- MicroMeter 中的 Gauge 对应于 Prometheus 中的 Gauge,用来描述在一个范围内持续波动的变量,如 CPU 使用率,线程池任务队列数等。
- MicroMeter 中的 Timer 对应于 Prometheus 中的 Histogram,用来描述与时间相关的数据,如某个接口 RT 时间分布等等。
- Micrometer 中的 DistributionSummary 对应 Prometheus 中的 Summary ,与 Histogram 类似,Summary 也是用于统计数据分布的,但由于数据的分布情况是在客户端计算完成后再传入 Prometheus 进行存储,因此 Summary 的结果无法在多个机器之间进行数据聚合,无法统计全局视图的数据分布,使用起来有一定局限性。
当我们需要把部署在 Kubernetes 集群中的 Spring Boot 应用接入到 Prometheus 时,需要按照代码埋点->部署应用->服务发现这个流程来进行。
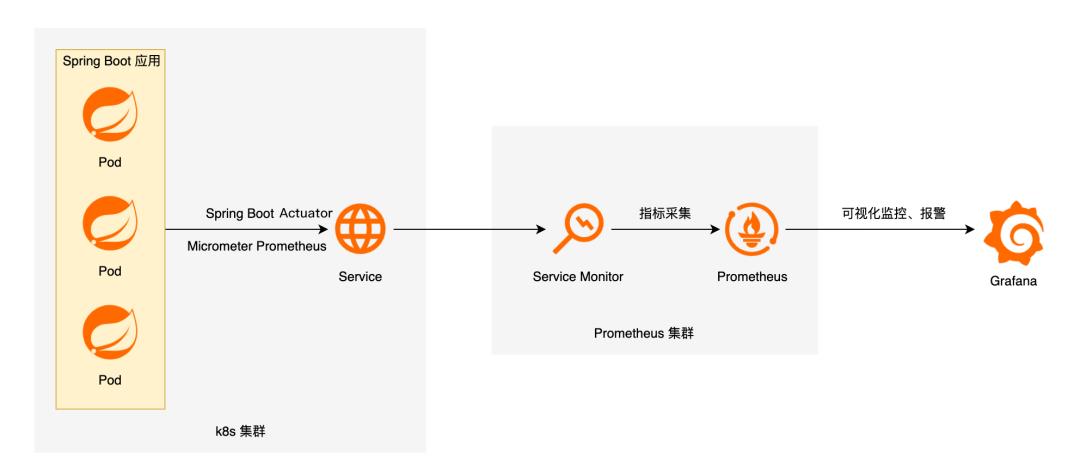
首先,我们需要在代码中引入 Spring Boot Actuator 相关 maven 依赖,并对我们需要监测的数据进行注册,或对 Controller 内的方法打上响应的注解。
其次,我们将埋点后的应用部署在 Kubernetes 中,并向 Prometheus 注册向应用拉取监测数据的端点(也就是 Prometheus 服务发现)。阿里云 Prometheus 服务提供了使用 ServiceMonitor CRD 进行服务发现的方法。
最后在目标应用的监测采集端点被 Prometheus 成功发现后,我们就可以开始在 Grafana 上面配置数据源及相应的大盘了。当然,我们同时也需要根据某些关键指标进行对应的告警配置。这些需求在阿里云 Prometheus 监控服务都能很方便地满足。
接入流程详解
接下来,我们进入实战演练环节,这里选取一个基于 Spring Boot & Spring Cloud Alibaba 构建的云原生微服务应用(https://github.com/aliyun/alibabacloud-microservice-demo)作为我们改造的基线。
我们最终目标是:
1、监测系统的入口:Frontend 服务是一个基于 SpringMVC 开发的入口应用,承接外部的客户流量,我们主要关注的是外部接口的关键 RED 指标(调用率 Rate,失败数 Error,请求耗时 Duration);
2、监测系统的关键链路:对后端服务 critical path 上的对象进行监测,如线程池的队列情况、进程内 Guava Cache 缓存的命中情况;
3、对业务强相关的自定义指标(比如某个接口的 UV 等等);
4、对 JVM GC 及内存使用情况进行监测;
5、对上述指标进行统一汇聚展示、以及配置关键指标的告警。
第一步,引入 Spring Boot Actuator 依赖,进行初始配置
首先,我们需要引入 Spring Boot Actuator 的相关依赖,在 application.properties 配置中暴露监测数据端口(这里定义为 8091)。成功后,我们即可访问应用的 8091 端口的/actuator/prometheus 路径拿到 OpenMetrics 标准的监测数据。
<!-- spring-boot-actuator依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!-- prometheus依赖 -->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
# application.properties添加以下配置用于暴露指标 spring.application.name=frontend management.server.port=8091 management.endpoints.web.exposure.include=* management.metrics.tags.application=$spring.application.name
第二步,代码埋点及改造
为了获取某个 Api 接口的 RED 指标,我们需要在对应的接口方法上打下面的 @Timed 注解。我们以演示项目中的 index 页面接口为例。注意这里,@Timed 注解中的 value 即为暴露到/actuator/prometheus 中的指标名字,histogram=true 表示我们暴露这个接口请求时长的 histogram 直方图类型指标,便于我们后续计算 P99,P90 等请求时间分布情况。
@Timed(value = "main_page_request_duration", description = "Time taken to return main page", histogram = true)
@ApiOperation(value = "首页", tags = "首页操作页面")
@GetMapping("/")
public String index(Model model)
model.addAttribute("products", productDAO.getProductList());
model.addAttribute("FRONTEND_APP_NAME", Application.APP_NAME);
model.addAttribute("FRONTEND_SERVICE_TAG", Application.SERVICE_TAG);
model.addAttribute("FRONTEND_IP", registration.getHost());
model.addAttribute("PRODUCT_APP_NAME", PRODUCT_APP_NAME);
model.addAttribute("PRODUCT_SERVICE_TAG", PRODUCT_SERVICE_TAG);
model.addAttribute("PRODUCT_IP", PRODUCT_IP);
model.addAttribute("new_version", StringUtils.isBlank(env));
return "index.html";
如果我们的应用中使用了进程内缓存库,比如最为常见的 Guava Cache 库等等。如果我们想追踪进程内缓存的运行状况,我们需要按照 Micrometer 提供的修饰方法,对待监测的关键对象进行封装。
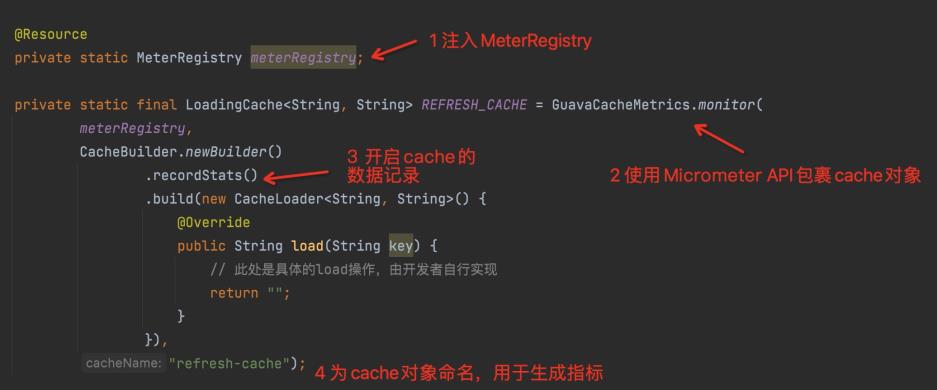
- Guava Cache 改造主要是四步骤,代码改动比较小,很容易就可以接入:
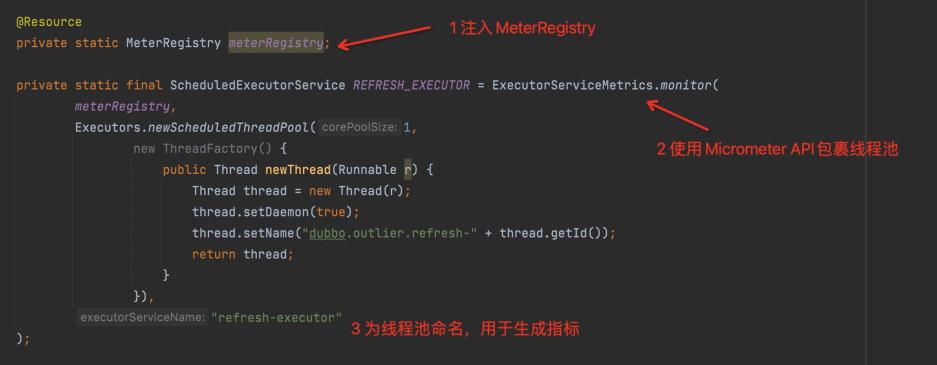
1、注入 MeterRegistry,这里注入的具体实现是 PrometheusMeterRegistry,由 Spring Boot 自行注入即可
2、使用工具类 api,即图中展示的 GuavaCacheMetrics.monitor 包装一下本地缓存
3、开启缓存数据记录,即调用一下.recordStats()方法
4、增加一个名称,用于生成对应的指标。
- 线程池改造主要是三步骤,也并不是很复杂:
1、注入 MeterRegistry,这里注入的具体实现是 PrometheusMeterRegistry;
2、使用工具类 api 包装一下线程池;
3、增加一个名称,用于生成对应的指标。
当然,我们在开发过程中一定还有许多业务强相关的自定义指标,为了监测这些指标,我们在向 Bean 中注入 MeterRegistry 后,需要按照我们的需求和对应场景构造 Counter,Gauge 或 Timer(这些类型的区别和使用场景上文有提到)来进行数据统计,并将其注册到 MeterRegistry 进行指标暴露,下面是一个简单的例子。
@Service
public class DemoService
Counter visitCounter;
public DemoService(MeterRegistry registry)
visitCounter = Counter.builder("visit_counter")
.description("Number of visits to the site")
.register(registry);
public String visit()
visitCounter.increment();
return "Hello World!";
至此,我们的应用代码改造工作到这里就全部完成了,下一步工作就是将应用镜像重新构建并重新部署到已安装 ARMS Prometheus 的 Kubernetes 集群中。之后,我们 ARMS Prometheus 控制台中配置 ServiceMonitor,进行服务发现。
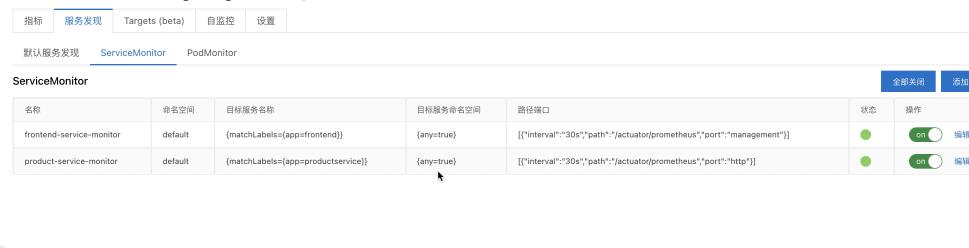
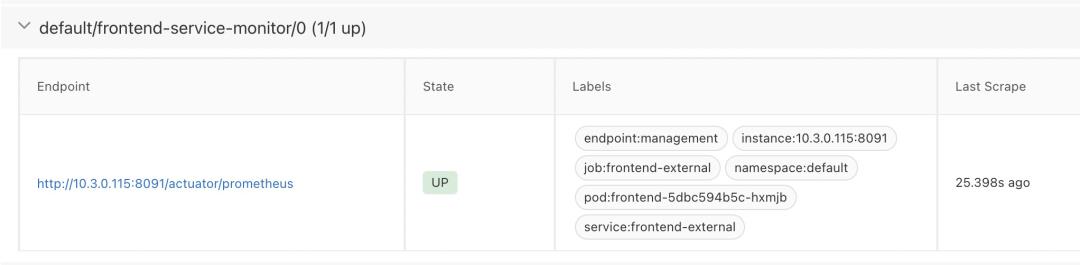
添加好 ServiceMonitor 后,我们可以在 Targets 列表中看到刚注册的应用 Service。
第三步,看板配置
应用的监测数据已成功收集并存储到 ARMS Prometheus。接下来,也是最关键的一步,就是根据这些数据,配置相应的大盘及告警。这里,我们借助 Grafana 社区中开源大盘模板来构建我们自己的业务监测模板。主要基于以下两个模板:
- Spring Boot 2.1 Statistics:
Spring Boot 2.1 Statistics dashboard for Grafana | Grafana Labs
- JVM (Micrometer):
JVM (Micrometer) dashboard for Grafana | Grafana Labs
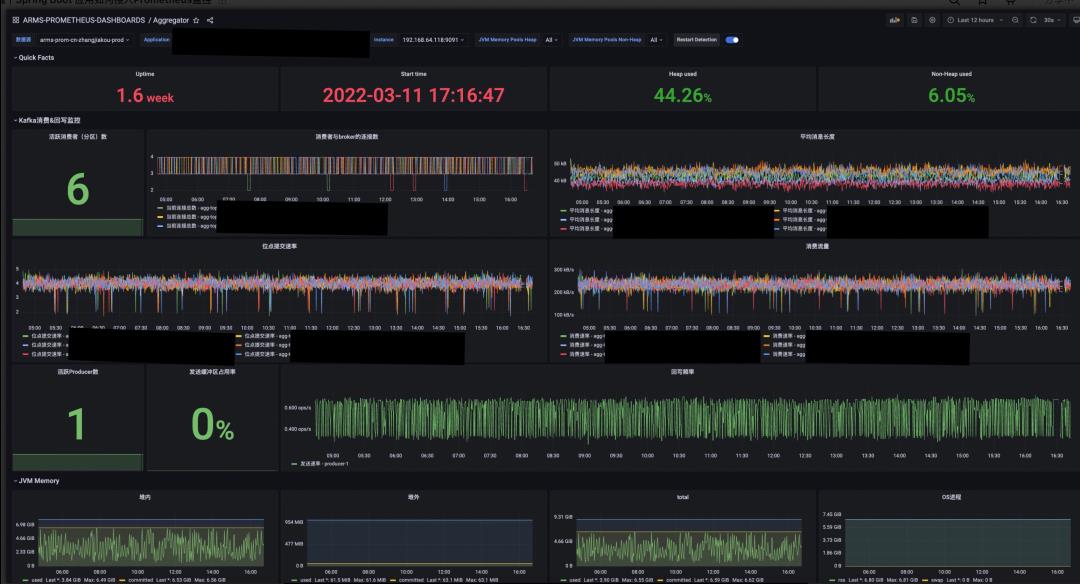
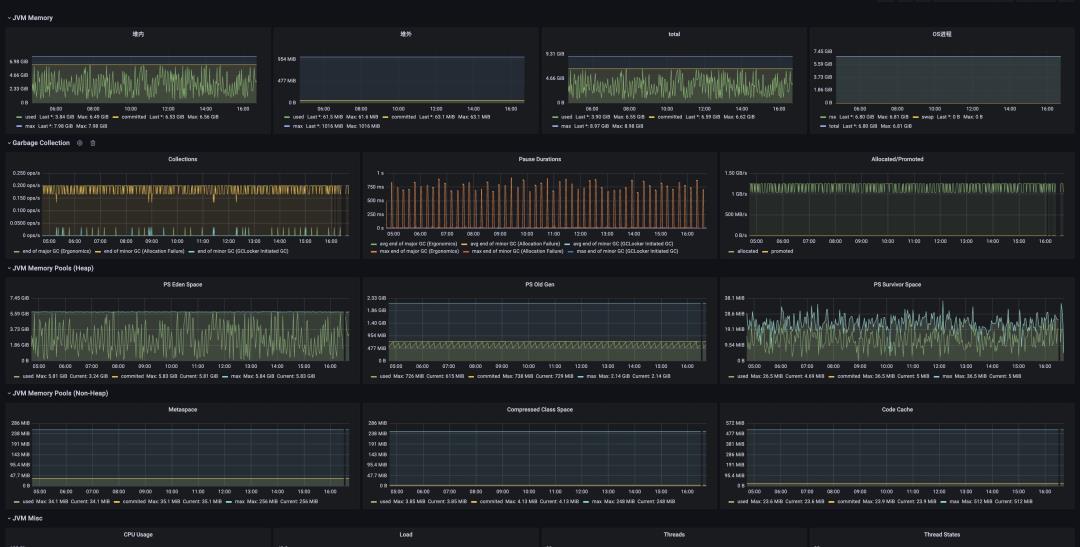
借助这些模板以及 ARMS Prometheus 内置的 Grafana 服务,我们可以很方便地将日常开发和运维过程中非常关心的指标组织在一张的 Grafana Dashboard 上。这里给大家抛砖引玉一下,放一张我们内部基于上述模板和自身业务构建的一个真实的大盘。这里面包含了一些总览,比如组件运行时间,内存使用率等等,也有一些细节指标,如堆内堆外内存,分代 GC 情况等等,还有像接口请求的 RED 等等,这里就不过多赘述了,大家可以充分发挥自己的想象力来创造独一无二的酷炫大盘~
本文为阿里云原创内容,未经允许不得转载。
以上是关于最佳实践|Spring Boot 应用如何快速接入 Prometheus 监控的主要内容,如果未能解决你的问题,请参考以下文章
Spring Boot 2从入门到入坟 | 最佳实践篇:Spring Boot应用该如何编写?
Keycloak快速上手指南,只需10分钟即可接入Spring Boot/Vue前后端分离应用实现S
Keycloak快速上手指南,只需10分钟即可接入Spring Boot/Vue前后端分离应用实现SSO单点登录