大数据的灵魂(上):HDFS
Posted 大数据weekly
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据的灵魂(上):HDFS相关的知识,希望对你有一定的参考价值。
提到大数据,我们第一个反应就是:到底有多大?100GB? 还是1TB?在真实生产环境中,我见过最大的文件是12TB的CSV TEXT。很显然,这不是一台电脑可以装下的。而且如果要是这个文件因为各种各样的原因丢失了,会对公司造成不小的损失。
那么我们今天就来看一看这是如何通过HDFS来解决以上问题的。
HDFS是什么?
HDFS是被设计成运行在普通硬件上的分布式文件系统。
什么算普通?看看国外玩家用树莓派组成的HDFS集群(这应该是最便宜的设备了吧。。。)

既然一台服务器存不下数据,就分而治之,我们将大文件进行拆分,分布式的存储在几台,乃至几百台通过Hadoop串联起来服务器上。同时为了防止数据丢失,对每一个拆分出来的文件进行备份,这样就算有一台服务器出现故障,数据还是不会被影响。
举个例子吧,假如我们有一个1G的文件,如果把这个文件传到HDFS上会发生什么样的事情呢?
这个文件根据每个HDFS文件(Block)可以存128MB大小的数据被拆分成几个小文件,这里需要注意,最后一个文件只有不到128MB也是会占用一个文件(Block)
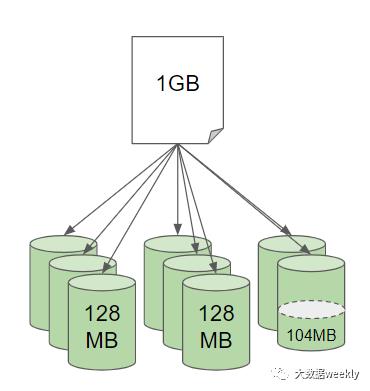
很好,我们把数据都分成一个个小文件存储到了HDFS,那么等到需要的时候怎么去读取这些文件呢?难道需要一个个去看是不是属于这个1GB的文件吗?
接下来我们要引入两位新成员Namenode和Datanode:
我们知道HDFS 把文件存在多个机器上,但是在用户看来文件在HDFS上就像普通的 Linux 文件一样。至于“在哪台机器上存的”,“如何存的”这些信息并不会暴露给用户。
我们可以无缝使用这些海量文件是靠Namenode中保存的文件系统信息包括文件存在哪里,分成了多少个文件,有多少备份。通过Namenode,我们可以对HDFS进行所有文件系统的常用操作,比如新建一个文件夹,重命名文件,查看文件内容等等。
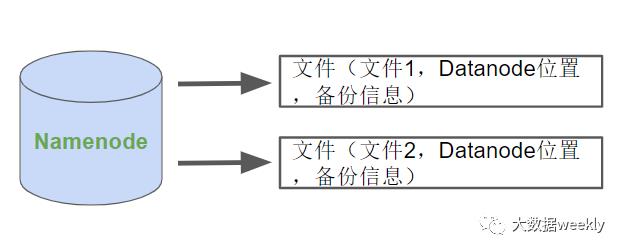
那么真正的数据都存在了哪里呢?Datanode
在用户想要获取文件时,Namenode会告诉客户端去如下几个Datanode中的具体存放位置查询,客户端将根据这个信息去联系第一个Datanode,第一个Datanode将会去联系下一个Datanode,以此类推,所有的数据都将返回给用户
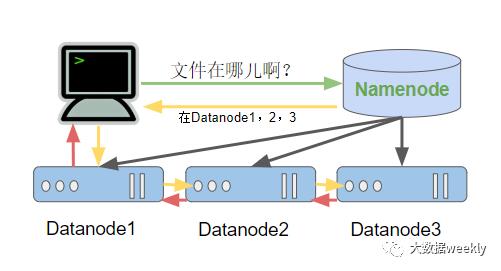
认真思考的朋友们可能会开始想,那如果一个Datanode坏了是不是整个文件都不能被获取了呢?这就回到了刚才提到过的备份了
举一个最简单的例子:我们有三份文件,1, 2, 3. 在只有三台Datanode服务器的时候我们可以做到如下简单的备份:
如果第一台服务器发生问题,所有Datanode中的文件备份将丢失,但是在还有第二及第三台服务器在线的情况下我们始终保持着文件的可读性。
预告:
综上,这篇文章为大家介绍了 大数据的灵魂之一HDFS ,下篇文章我将为大家介绍 Hadoop MapReduce 是如何实现。敬请期待
以上是关于大数据的灵魂(上):HDFS的主要内容,如果未能解决你的问题,请参考以下文章